 夜雨聆风
夜雨聆风封面
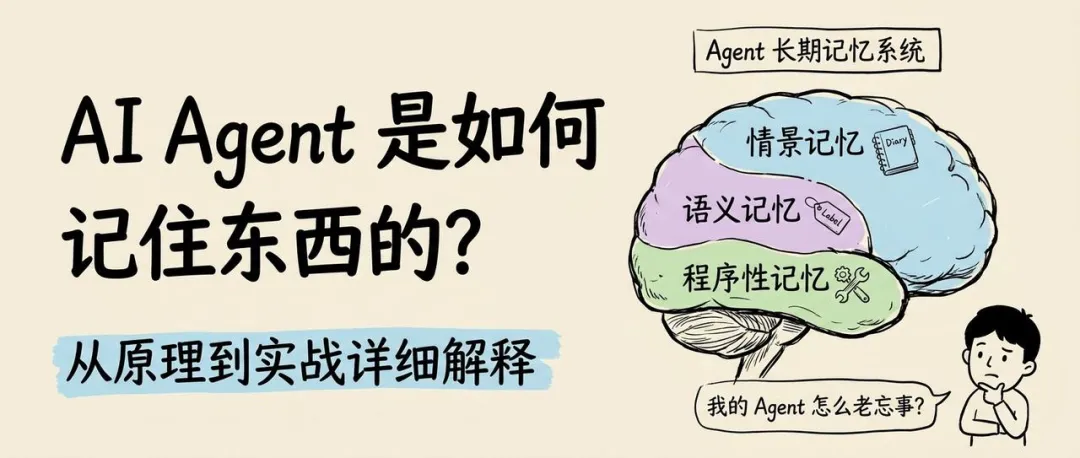
最近Agent 的长期记忆十分火爆,每个人都在聊记忆系统
但你去翻那些讲解,多半是一堆名词砸过来:向量数据库、RAG、上下文窗口、压缩、情景记忆……
读完,你还是说不清它到底怎么运作的,是不是?
不怪你,大部分文章都默认你有基础。
但Agent的记忆系统是目前面试最火的方向,不搞清楚的话,工作和面试中会很吃亏。
所以这篇我换个讲法,从基础开始讲,不堆名词!尽量带大家读懂!!
我向你保证,看完下面你能自己答上这三个问题:
记忆系统是什么?
如何理解OpenClaw的记忆系统?
企业级别方案是啥样?
这篇文章特别长,耗时我几天写作,如果你有朋友对Agent记忆感兴趣,可以先收藏,后面转发给他。
关于Agent记忆系统的一些基础知识
这一节主要讲Agent如何在单个会话保持记忆和不同会话之间保持记忆的。假如你已经理解,可以提前跳过。
首先对大模型的两次API调用之间是没有记忆的,啥意思呢?
举个例子: 你在第一次调用中说你喜欢吃橘子,那么第二次调用中假如你没有把"我喜欢吃橘子"附加到提示词,那么大模型是对“你喜欢吃橘子”没有记忆的。
那么Agent是如何在对话中保持这个记忆呢?
首先,你每次问一句的时候,底层会把你之前和它的聊天历史都发送出去,大模型能看到,就能确保最近的记忆。
其次,当聊天记录很多,以至于超过大模型接受聊天历史最大值时。它就会压缩聊天记录,就是把当前回话对话历史总结提炼一下,然后又塞回提示词,这样就有空间继续聊天了。
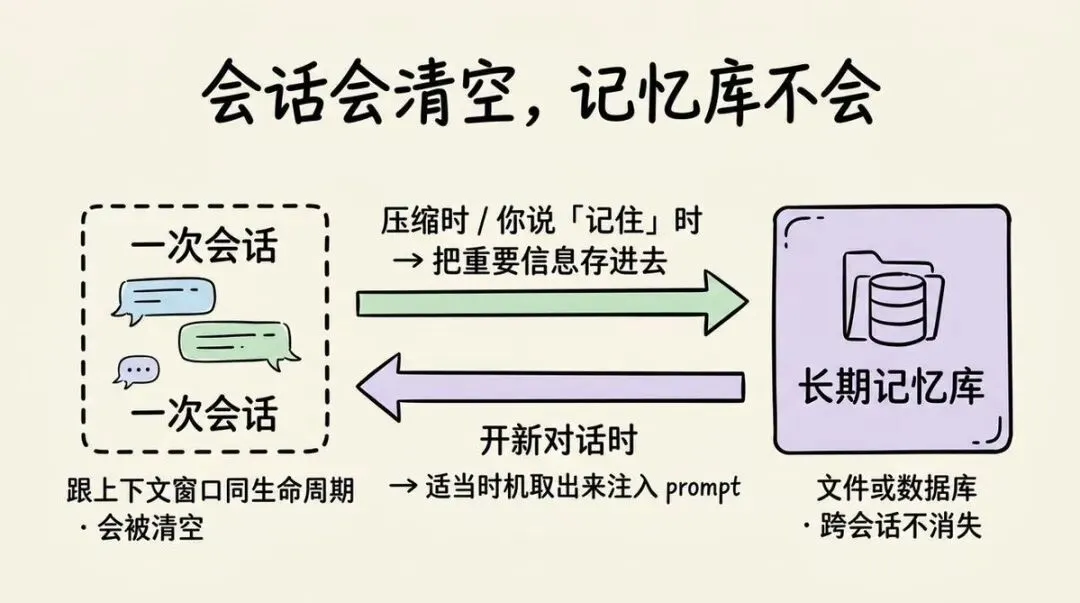
上面就是模型如何在单个冗长对话中保持记忆的原理。假如你看到这里有点晕,可以看看下图:
现在你知道单个会话中如何保持记忆了,但在不同聊天对话之间,如何保持记忆呢?
这个时候,长期的记忆系统就登场了!!
它做的事情就是在你上下文压缩的时候或者要求记忆某个东西的时候,把重要的信息存到某个存储空间。
然后在你开始新的对话的时候,适当的时机提取加入提示词中。
通过腾笼换鸟,构建出记住很多事情的假象。这和人类的工作记忆和长期记忆类似。
好了,有了这些基本的记忆知识后,我们就可以去了解什么是记忆系统了。
下面我将会给你一个理解框架,如果你看完,我保证让你对任何记忆系统方案都有个基本的理解。
记忆系统
现在网上声称能给 Agent 长期记忆的方案,少说也有几十种,这么多,咋研究呀?
接下来我给你拆解一篇论文,来获得对Agent长期记忆的基本认知,后面再通过对比OpenClaw和其他记忆框架的区别获得更好的理解。
Google 在 2025 年 11 月发表了一篇论文,标题叫《Context Engineering, Sessions and Memory》
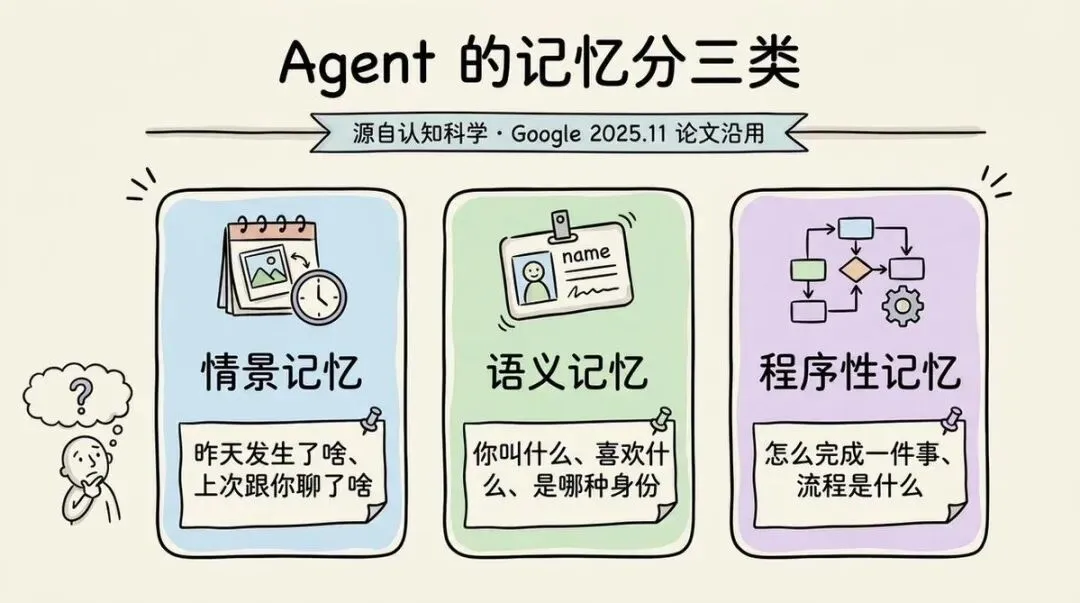
这篇论文中,他们效仿半个世纪前认知科学的方法,把Agent的记忆分为三类:
- 情景记忆:昨天发生了啥、上次跟你聊了啥
- 语义记忆:你叫什么、喜欢什么、是哪种身份
- 程序性记忆:怎么完成一件事、流程是什么
这三种记忆合起来,就是所谓的Agent的记忆。
但这只是故事的一部分,另一半关于如何维护和使用记忆的。
就像人一样,Agent也不能什么都记忆,所以记忆系统需要有一套可靠的方法,从对话历史中抽取出重要的信息,然后再保存。这一步我称之为抽取。
除此之外,我们还要对记忆进行整理合并。
举个例子:
三个月之前我说在大理,后来我搬到成都。假如不对这个信息进行合并的话,记忆中就存在相互矛盾条目。
正确的做法是将,在我搬到成都后,记忆更新为:用户在成都。
这一步我称之为更新。
还有一步是检索,这里面就有很多方法了,关键词检索,语义检索,融合检索,用大模型来检索。
所以,你想要搞懂一个记忆系统,只要搞懂这两个方面就行
1. 记忆有多少种分类,每种存什么的? 2. 记忆是如何抽取,更新,检索? 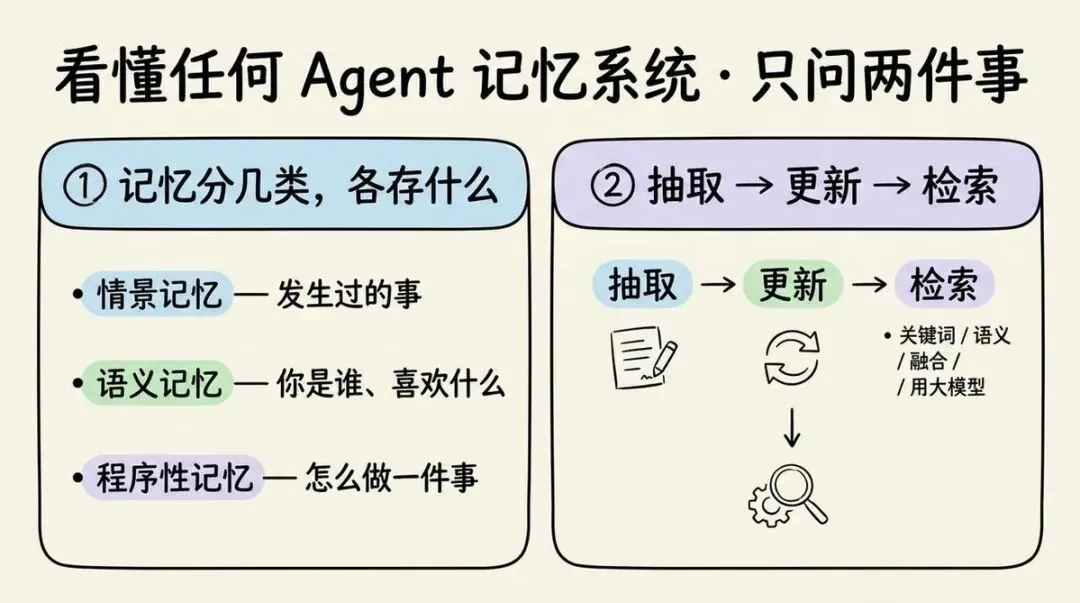
好了,利用这个框架,让我们来搞清:OpenClaw长期记忆是如何实现的。
OpenClaw的记忆有多少种分类,每种存什么的?
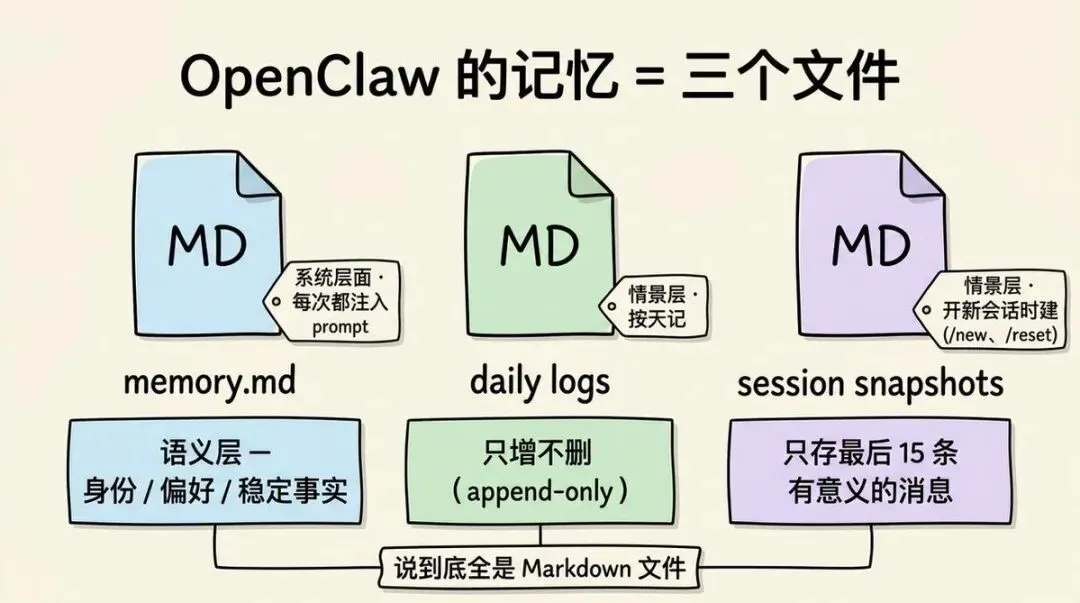
它的记忆分为下面三类:
memory.md(记忆):
属于语义记忆,存储,你的身份、偏好、稳定事实。
daily logs(每日日志):
属于情景记忆,记录每天发生了啥,按天组织,只会添加新的条目,不会删除。
session snapshots(会话快照):
属于情景层记忆,当你用 /new 或 /reset 命令开启一个新会话,会总结旧对话中最后 15 条"有意义的"消息,保存成markdown文件。
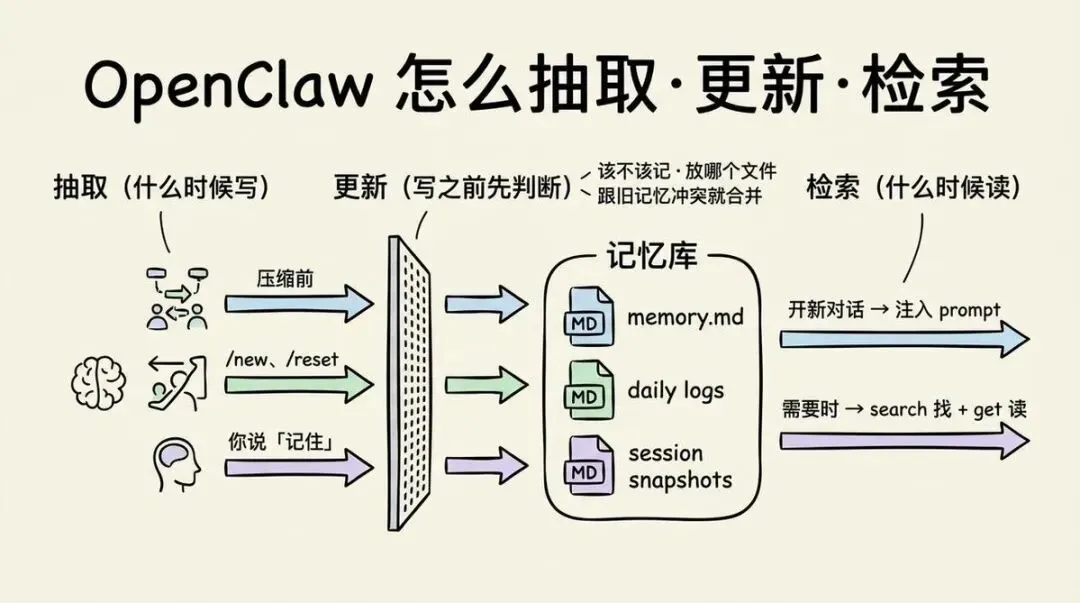
抽取、更新、检索怎么做?
抽取发生在三种情况下:
1. 对话即将被压缩的时候:这个时候会讲有价值的信息写入每日日志中。 2. 你用 /new 或 /reset 命令开启一个新会话:会将有价值的信息保存到会话快照中。 3. 用户要求记忆时候:自行判断存储在任意一种记忆中。
检索会发生在下面两种情况:
1. 开启一个新的对话,就会将memory.md 都会被自动注入到 prompt,而且还会去读今天和昨天的每日日志,以获取最近的上下文。 2. 当OpenClaw觉得有必要看记忆时,会先调用memory search,通过融合搜索(关键词+向量)找到记忆所在地点,再通过 memory get读取文件内容。
那么更新发生什么时候呢?我个人理解发生在抽取的时候,就是决定记忆什么的时候。
假如还是不太理解,可以看下图:
现在你对记忆系统已经有一定了解了,但说句心里话,OpenClaw 的记忆系统问题不少:
1. 很费Token 2. Markdown 没了记忆就消失 3. 经常遗忘东西
但真正的企业级记忆系统做了很多优化保证稳定性,背后的技术值得任何一个喜欢技术的人搞懂
下面我来分析分析企业级 Agent 记忆系统!!
企业级 Agent 记忆系统
AI 时代,每一个程序员都该搞懂企业级 Agent 记忆系统背后的技术,否则只会越来越没优势了。
为什么呢?
因为大模型会不断吃掉我们的编程工作,唯一的选择,就是给大模型做配套。
为了方便讲解,我挑一个叫 EverOS 的开源方案来拆解
之前说过,了解一个记忆系统,搞懂两个问题就够了
那 EverOS 怎么回答这两个问题?
第一问:记忆怎么分类?
通用框架是 3 类,EverOS 在每一类下面又分得更细,具体如下图:
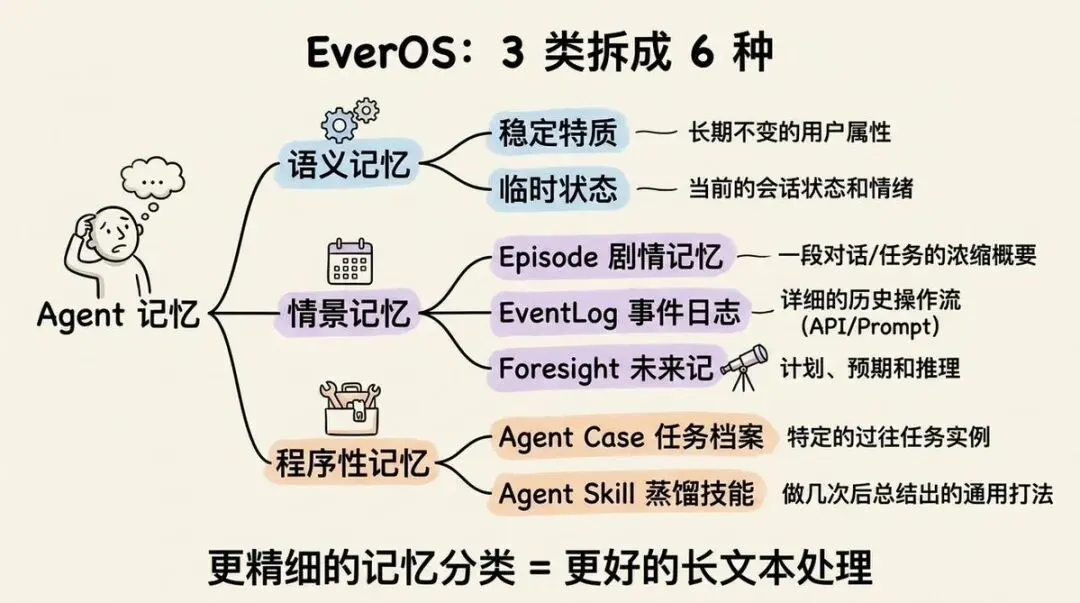 1. 语义记忆
1. 语义记忆
长期记着你这个人是什么样,分两层:
- 稳定特质:你是夜猫子、是程序员、住北京,这种长期不变的
- 临时状态:你今天熬了夜、这周特别忙、上周感冒了
2. 情景记忆
分为种:
- Episode(剧情记忆):把一段对话或任务梳理成的浓缩概要,不是按天的流水账 例:用户问怎么部署模型,卡在环境变量,折腾了 30 分钟
- EventLog(事件日志):把对话里的关键事实拆出来,每条带时间戳 例:2026-05-10 用户买了 Mac mini,2026-05-12 用户绑了 GitHub
- Foresight(未来记):跟时间有关的"接下来"——你说过要做的、它推断你之后会涉及的,带有效时间,到点能提醒 例:下周五前把方案发出来
3. 程序性记忆
分为两种
- Agent Case(任务档案):干完一次任务,把"想干什么 + 一步步怎么做的 + 一个质量分"记下来
例:发邮件,它先查通讯录、起草、让你确认、再发出去——这一套连同质量分一起存档
- Agent Skill(蒸馏技能):同类任务做过几次后,自动从这些档案里蒸馏出通用打法,还带个成熟度分,做得越多越靠谱
例:做过 5 次邮件任务,它学会先看收件人是不是关键人物,再决定语气正式还是随意
可以看到,原本 3 类,EverOS 拆成 6 种,能装的东西更精细,记忆更加有效果
而且与人类的记忆更加相似,会预测未来,会总结精进技能。
第二问:抽取、更新、检索怎么做?
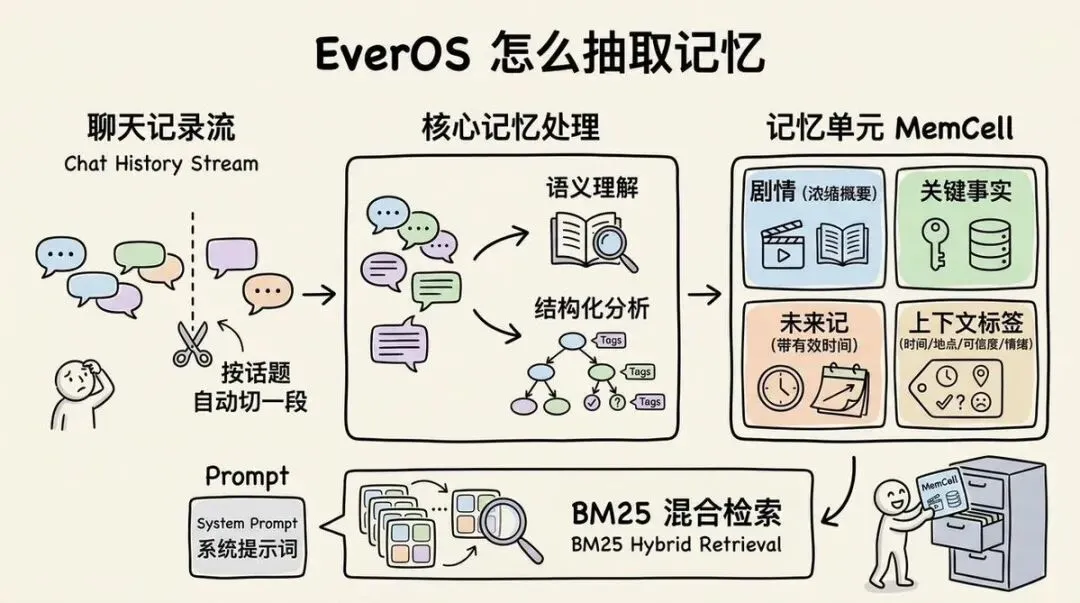
如何抽取记忆?
EverOS 自动判断"这一段讲完了没有",讲完就切下来,打包成一个记忆单元。
每个单元里装 4 样东西:
- 剧情:这一段聊了什么、做了什么——一段浓缩的概要,不是原话照搬
- 关键事实:里面有哪些值得单独拎出来记的事
- 未来记:你说过要做的、它推断你之后会涉及的,带上有效时间,到点能提醒
- 上下文标签:什么时候、在哪、可信度多高、当时什么情绪
你不用管,它自己切分
 如何更新记忆呢?
如何更新记忆呢?
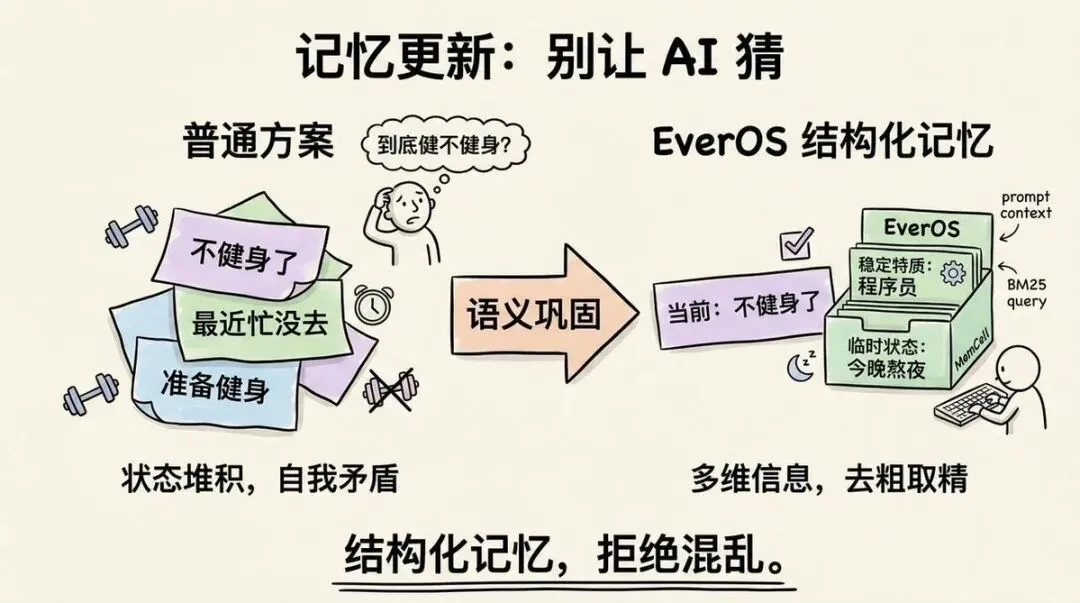
举个例子:
一个月之前,你跟 AI 助手聊天时先说:我最近准备健身。两周后,你又说:最近忙,没去健身房。今天你说:算了,不健身了。
普通方案是三条都堆进日志,到时候大模型检索出来哪条,就认为哪条是事实。但事实上,答案应该是最新的一条。
而 EverOS 靠的是「语义巩固(Semantic Consolidation)」,做三件事:
- 自动判断哪条是最新的(健身已经停了)
- 重复的、说的是同一件事的,合到一起
- 维护一份你的用户画像,把稳定偏好和临时状态分开存(这一步官方叫 Profile Evolution)
具体如下图所示:
 如何检索记忆呢?
如何检索记忆呢?
EverOS 给你 4 种检索方式,按场景选:
- 关键词:精确匹配词,适合查具体的名字、ID
- 向量搜索:按语义找,同样的意思不同的词,也能匹配
- 混合:关键词 + 向量一起跑,再用一个重排(rerank)模型筛一遍——官方推荐的默认档
- Agentic:复杂的多部分问题才上,LLM 自己判断该搜什么、怎么搜,来回多次直到找到(hybrid 不够用时才用它)
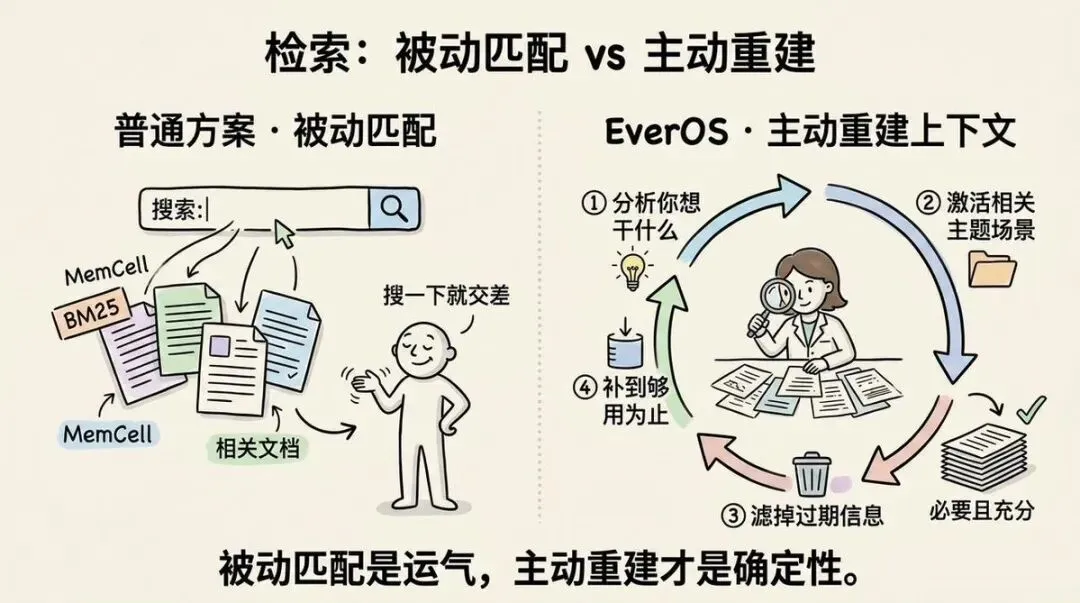
但 4 种方法不是关键,关键是它的检索逻辑
普通方案是被动匹配,你给关键词,它返回匹配的文档,就完事了
EverOS 是主动重建上下文:
1. 先分析你这次想干什么 2. 激活相关的主题场景 3. 过滤过期信息,例如:1 年前的旧偏好可能已经失效 4. 一直迭代搜索,直到信息够用为止
普通方案就像搜索引擎那种搜一下就交差,EverOS会反复换角度去找,找到足够的信息为止
EverOS 在长程记忆评测 LoCoMo 上拿了 93.05% 的总体准确率(用 GPT-4.1-mini),把对比方案 Zep 的 85.22% 甩开了将近 8 个百分点。
读完这一节,相信你对生产级 Agent 记忆系统应该有数了,但是在实际工程中如何落地,用记忆系统可以做什么事情呢?
实际生产落地
接下来我继续用这个开源项目讲解,原因有两个:API 免费开放、仓库带 20 个真实案例,太适合讲落地!!
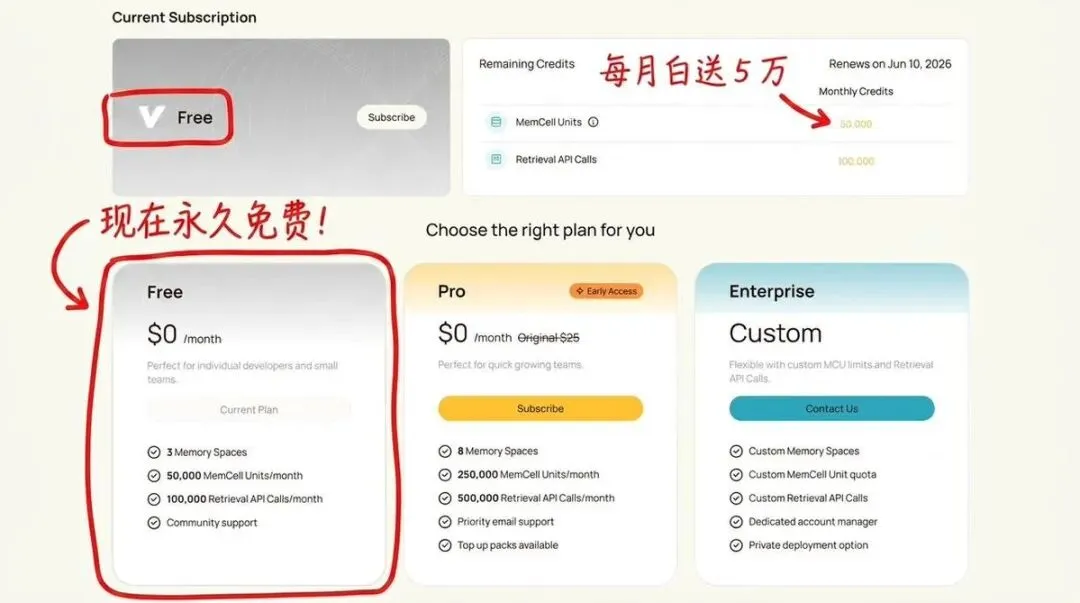
免费开放的 API
EverOS 的 Cloud API 免费开放
 三步搞定:
三步搞定:
1. 浏览器打开 everos.evermind.ai 注册,页面给你一个 API Key,存好 2. 命令行装 SDK:pip install everos 3. Python 里实例化 client,下面就开始用
Everos 不仅能免费试用,而且他还支持最近大火的Skill 自进化功能!!
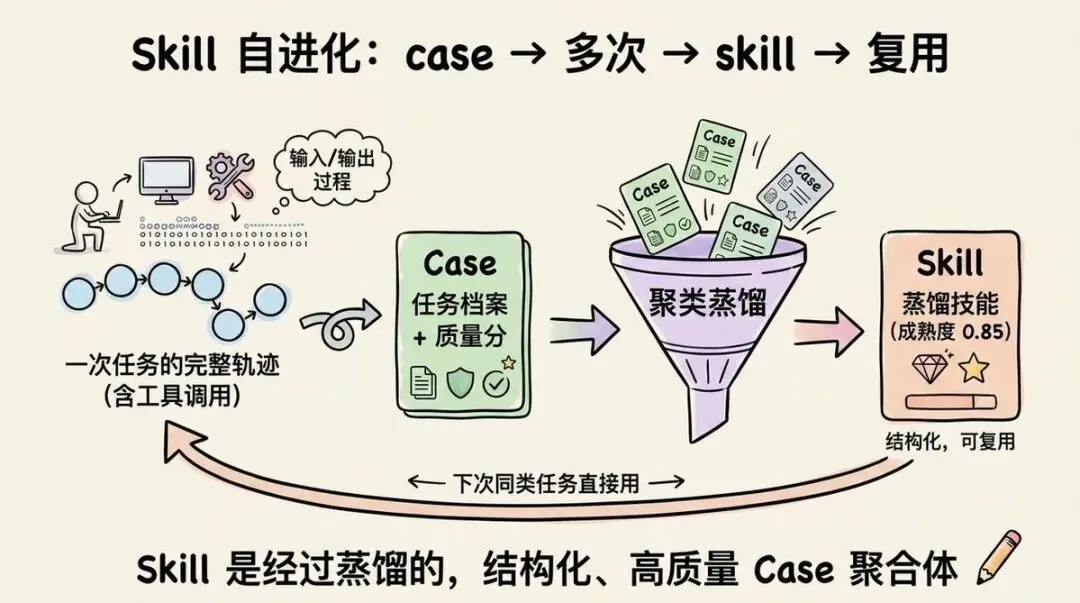
Skill 自进化怎么用?
Agent 反复做同类任务,EverOS 自动把经验蒸馏成可复用的 skill,下次同类任务直接用,不用从零开始
实际写代码使用就 3 个 API 串起来:
两点要注意:
- 第一次喂轨迹只生成 case(单次任务的存档),跑过几次同类任务后端才聚类蒸馏出 skill
- 必须用 /memories/agent 这条端点,普通 /memories 抽不出 skill
如果你不理解Skill自进化功能,可以看看下图:
 简单说一个代码上的用法,但这个项目作为Agent的基础设施,有着极为价值的真实使用案例。
简单说一个代码上的用法,但这个项目作为Agent的基础设施,有着极为价值的真实使用案例。
而且这些案例全部开源,可以直接学习!!
20 个真实 Use Case
仓库 README 列了 20 个 use case,挑几个:
- MemoCare(阿尔茨海默记忆助手):给认知衰退的患者配一个永不遗忘的外部记忆——这是其中最有温度的一个公益项目
- Claude Code Plugin:给 Claude Code 装上长期记忆,跨 session 不忘
- Game of Thrones:给 AI 灌权游剧情演角色,长期记得自己是谁
- OpenHer:AI 女友,情感陪伴 + 记忆演化
- Computer-Use with Memory:让 Agent 操控电脑,记住每次操作的经验
- Memory Graph Visualization:把记忆系统画成可视化图谱
完整列表在 github.com/EverMind-AI/EverOS 的 README
顺带说说几个官方插件
光有 API 还不够,EverOS 还把记忆能力打包成了几个开箱即用的插件:
- Claude Code Plugin:给 Claude Code 装长期记忆——每次回完话自动存、每次提问自动召回相关上下文,还带一个可视化的 Memory Hub 面板,一行命令安装。
- OpenClaw Plugin:把 EverOS 接成 OpenClaw 的"记忆槽位"——Agent 每次跑之前自动检索相关记忆(剧情、画像、任务档案、技能)注入上下文,跑完把对话连同工具调用一起存回去。
- OpenClaw Skill:以"skill"的形式把 EverOS 的记忆工具接进 OpenClaw / Claude Code,让 Agent 按需调用记忆,而不是常驻挂着。
回到文章开头那三个问题:
记忆系统是什么?openclaw记忆系统如何?企业级别方案是啥样?
看到这里你应该都有答案了。
EverMind这个项目十分不错:
1. 整个项目 Apache 2.0 开源,目前 4500+ stars 2. EverMind 学术和算法很强,一直在发论文,一直在选中,之前的 MSA 也是一个很先进的概念 3. EverMind 是盛大下面的 AI Native 公司,资源很多
如果你接下来准备从这个项目开始学习Agent记忆系统,可以顺手给它点个 star:
github.com/EverMind-AI/EverOS
月底他们也会有新产品上线,期待一波!!
本次是我第一次尝试讲解技术概念文章,为了方便大部分人理解,其中省略很多细节
文章涉及的技术比较复杂,欢迎在评论区指出错误,我进行勘正。
假如你喜欢我的文章,可以关注我。
