 夜雨聆风
夜雨聆风同步和异步:说白了就是等和不等的事
如果你是搞技术的,这两个词一定不陌生。
面试会问,文档里要写,技术群里天天有人吵。但大多数人能说出来的还是那句话:同步就是等,异步就是不等。
这个回答很对,但经不起追问,比如:为什么项目用了异步还是卡?为什么代码写着写着就掉进了回调地狱?std::async 和真正的异步是不是一回事?
这篇文章,咱就把同步和异步这件事说清楚。
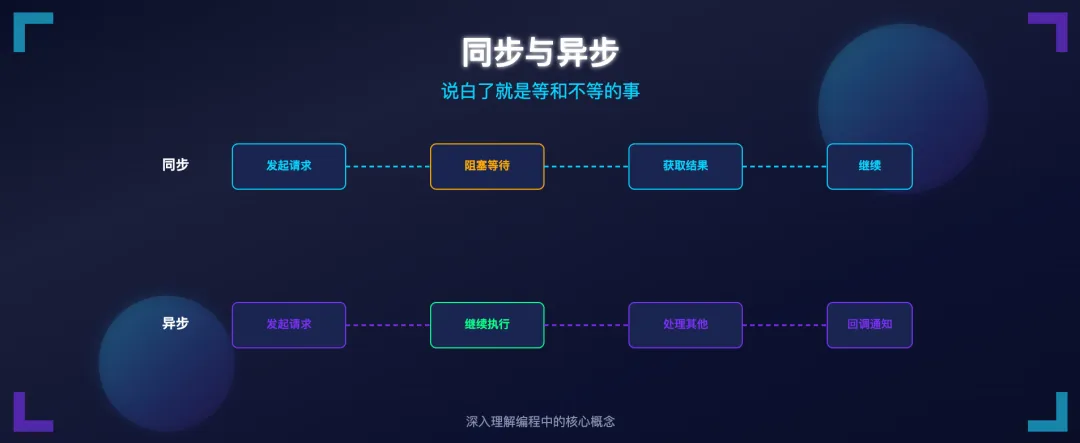
一、同步和异步,就是等和不等
先从最简单的说起。
同步:你发起一件事,站在原地不动,等事情办完、拿到结果,才继续下一件事。
异步:你发起一件事,不站在原地等,接着去做别的,事情办完了,系统来通知你。
拿点餐来比,比较好懂。
你去一家餐厅,点了一份红烧肉。服务员说稍等,你会怎么做?
两种做法。第一种:你站在取餐口盯着,等着厨师做好你端走,才去干别的,这是同步。你哪也没去,就在那等。
第二种:你回到座位上刷手机,厨师做好了,服务员端着盘子送到你桌上,这是异步。你在这段时间里干了别的事,是厨师那边搞定了主动来找你。
这程序里的情况一模一样:
// 同步:程序在这里停住,等数据库返回才往下走auto result = db.query("SELECT * FROM orders");process(result);// 异步:发起查询后程序继续往下走,查完了通知你autofuture = db.query_async("SELECT * FROM orders");do_other_work();auto result = future.get(); // 需要的时候再来取就这点区别,不难。
二、为什么你写的异步只是换了个地方等?
很多人觉得自己的代码是异步的,其实只是把同步代码扔到另一个线程里跑,看起来没卡住,但那不是异步,那是并发,两个完全不是一回事。
比如:
你写了一段程序,要查数据库、拿结果、处理结果。正常写的话,程序在查数据库那一步停住,等返回才继续往下走。
你想了个办法:把查数据库这件事扔到一个新线程里,主线程不就不卡了吗?
// 这不是异步,这是并发std::thread t([]() {auto result = db.query("SELECT * FROM orders"); process(result);});do_other_work();t.join();主线程确实没卡,它在跑 do_other_work(),查询在后台跑着。
但你仔细看:发起查询的那个线程,在等数据库返回的整个时间段里,它什么都干不了,只能等着。线程换了个,等待的行为没有变。
真正的异步是另一回事:发起查询后,线程彻底空出来了,可以去处理其他事情,不是换到别的线程去等。等数据库返回了,系统来叫你去取。
这个区别在有些场景下会变得非常关键。比如你的程序只有一条执行流,如果你写了假的异步,整个程序就卡死了,别的事情也没法推进,因为发起请求的代码还在那里同步等着。
三、代码写多了,异步是要付出代价的
你写一个功能,要依次调用三个接口:A 拿用户信息、B 拿这个用户的订单、C 把结果整理好发出去。
同步写很简单,顺序写下来就行:
auto user = call_user_service();auto orders = call_order_service(user.id);auto result = combine(user, orders);send_to_front(result);四行,清晰。
但如果这三个接口本身是异步的,不能直接等着拿结果。最直接的方式是用回调,把一个函数传进去,接口跑完了调这个函数:
call_user_service([&](User user) { call_order_service(user.id, [&](std::vector<Order> orders) {auto result = combine(user, orders); send_to_front(result, [&](bool ok) {// 发送完成 }); });});这才三层,已经有点难看了。如果业务再复杂一点,八层九层都不是开玩笑,那叫回调地狱。代码嵌套越来越深,错误处理每层都要写,逻辑全揉在一起,看一眼就头疼。
后来几乎所有语言都在语法上加了一个叫 async/await 的东西,就是为了解决这个问题。它让你把异步代码写成看起来像同步的样子:
// 用 C++20 协程,异步代码看起来像同步task<Result> get_user_combined(){ User user = co_await call_user_service_async();std::vector<Order> orders = co_await call_order_service_async(user.id);auto result = combine(user, orders);co_awaitsend_to_front_async(result);co_return result;}看起来和同步代码一样,四行顺序写下来,没有嵌套。
但三个 co_await 一个接一个等,这跟同步有什么区别?
区别不在函数内部,在线程。同步执行时,线程在等数据库返回的那几毫秒里什么都干不了,干坐着。co_await 执行时,函数在这里暂停,线程被释放回去了,它可以跑去执行别的协程、处理别的请求。等这个异步操作完成了,线程再回到这个函数,从暂停的地方接着往下走。
打个比方:你在银行柜台办业务,柜员说「你这个需要后台审批,你先回座位等,办好了我叫你」。你离开柜台,柜员去叫下一个号。你回来的时候,从上次停的地方继续办,你没站在柜台前干等,柜员也没闲着。
所以这段代码函数内部是顺序的,但线程没被绑死,这就是它和同步的本质区别。
如果几个操作之间没有依赖关系,你还可以让它们同时跑,最后一起等结果:
// 三个独立的异步操作同时发起,最后一起等task<void> fetch_all(){auto t1 = call_user_service_async();auto t2 = call_config_service_async();auto t3 = call_log_service_async();auto user = co_await t1;auto config = co_await t2;auto logs = co_await t3;// 三个请求同时发起,但按顺序等结果// t1 先完成才等 t2,t2 完成才等 t3// 真正"谁先回谁先拿"需要 when_all 之类的工具}这比回调好,但 co_await 按顺序等结果,不是「谁先回来谁先拿到」。要真正做到「谁先完成谁先处理」,得靠 when_all 这类组合工具,那是更进阶的话题了。
但有个前提:被 co_await 的那个函数本身必须是异步感知的,不是普通函数。普通函数直接 co_await,程序会在那同步跑完,不会带来任何异步效果。这一点搞不清楚,写出来的代码表面上漂亮,实际上还是假异步。
四、任务完成后,怎么通知你?
这个问题是异步的核心,最常见的方案有三个。
回调:最直接,任务完成后调你给的那个函数来通知你。你传一个函数进去,它跑完了调你。简单,但回调多了容易嵌套,就是前面说的回调地狱。
Future:任务发起后返回一个凭证,你拿着这个凭证随时可以来问:结果出来了吗?
std::future<std::string> f = std::async(std::launch::async, []() {return fetch_user_data();});do_other_work();std::string data = f.get(); // 结果没出来就等,出来了直接拿走真正的异步 I/O 靠的是操作系统层面的通知机制,不是靠多开线程。但 Future 的好处在于:发起请求和等待结果可以分开了。在 C++ 标准库没有提供真正的异步 I/O 之前,这是你能拿到的最方便的工具。
消息队列:任务发起后不是等结果,而是把结果放到一个队列里,下游的代码自己从队列里取。适合那种任务发起方和最终处理方互相不知道对方的系统。对大多数业务开发来说,Future 这套已经够用了,消息队列是更复杂的场景才用的。
五、同步和并发,到底什么区别?
并发是同时做多件事,每件事还是在等;异步是不等了,切换到别的事继续跑,等做完了来叫你。
有点绕,举个例子。
你今天有五件事要处理:洗碗、倒垃圾、洗衣服、等外卖、等快递。
同步做法:先洗碗,洗完倒垃圾,倒完洗衣服,洗完等外卖,外卖到了等快递。一件事做完才做下一件,全部干完需要所有事情排队的时间加起来那么久。
并发做法:你和你老婆一块干,你洗碗,她倒垃圾,同时推进。多个人同时干活,总时间比一个人排队短。
异步做法:外卖点了,你不等了,接着洗碗。洗到一半外卖到了,你去取。你没有任何时候在干等着,哪件事有进展你就去处理哪件。
并发和异步不是非此即彼的,可以同时用:用并发来利用多核 CPU,用异步来消除 I/O 等待。但它们解决的是不同的问题,知道这个区别,才能在写代码时做出正确的选择。
同步和异步,说到底是控制权归谁的问题。同步时,你卡住,等它完,才继续。异步时,你发起任务,不等结果,任务完了系统来叫你。
回调、Future、async/await、goroutine、协程。搞清楚了控制权归属,剩下的全是工具选择问题。
知道「是什么」能让你用工具,知道「为什么」才能让你真正驾驭它。
