 夜雨聆风
夜雨聆风💡 痛点导语
你有没有经历过这种窒息场景:运营说"我要推一波高价值用户",结果数据团队翻遍5张表、写了两百行SQL,最后给出一批"可能大概也许"是高价值的名单——因为"高价值"的定义全靠运营拍脑袋,"消费>1000元"就是高价值?那月消费999但每周复购3次的用户呢?
更扎心的是,90%的用户标签要么过期要么没人用。客服对话里藏着"宝宝皮肤敏感需要温和配方"这样的金矿,但你的画像系统只有"28岁女性北京"这种冷冰冰的静态属性。画像做完往那一扔,运营还是凭感觉选人群,推荐系统还是推热门款。
2026年,AI驱动的用户画像已经从"贴标签"进化到"读心术"——LLM能从一条客服咨询里推断出用户的肤质偏好、价格敏感度和购买意图,整个画像更新从T+1压缩到秒级。本文整合全网10+篇爆款教程精华,覆盖标签体系3层架构、4种标签生成方法横评、Dify+n8n画像工作流5步搭建法、避坑对照,帮你从"拍脑袋运营"升级到"精准制导"。
🏗️ 一、标签体系3层架构——画像不是贴标签,是盖房子
用户画像的标签体系就像盖房子:标签是砖块,标签体系是户型图,AI是智能砌墙机。砖块乱堆叫废墟,按图纸砌才叫大厦。
第一层:属性标签——"你是谁"
人口属性、设备信息等静态标签,长期稳定,变化频率低。比如:28岁、女性、北京、宝妈、月收入1.5万-2万。
生成方法:规则驱动法,直接从注册信息、CRM数据提取。缺失字段可用XGBoost基于购买历史和App安装列表预测补全。
第二层:行为标签——"你在做什么"
消费频次、浏览路径、品类偏好等动态标签,持续更新。比如:月均购买母婴用品3次、平均客单价180元、偏好温和不刺激配方、近7天浏览家电类10次。
生成方法:聚类分析法,K-Means/DBSCAN自动发现隐藏群体。某电商平台用RFM模型聚类,发现了"价格敏感-高复购"这个人工规则根本想不到的群体。
第三层:意图标签——"你想要什么"
价格敏感度、流失风险、购买意愿、价值观等预测标签,具备前瞻性。比如:3天内可能流失、价格敏感型、品质追求者、环保主义者。
生成方法:机器学习建模法,XGBoost/LSTM预测。某社交平台深度学习模型预测购买意向准确率达90%。LLM还能从评论"这个面霜太油了"推断肤质偏好,从"下周想去上海迪士尼"提取出行意图。

🎯 二、4种标签生成方法横评——选错方法等于白干活
| 维度 | 核心逻辑 | 适合标签 | 优势 | 陷阱 |
|------|---------|---------|------|------|
| 规则驱动法 | 人工定义阈值:"近30天登录≥7天=高频" | 消费活跃/新注册/高客单价 | 逻辑透明、解释性强、开发成本低 | 过度依赖经验→刻板划分,需定期回溯验证 |
| 聚类分析法 | K-Means/DBSCAN自动发现相似群体 | 价格敏感族/品质追求者/内容浏览型 | 无需预设标签,发现人工想不到的细分 | 需特征标准化+轮廓系数评估质量 |
| 机器学习建模法 | 有监督训练XGBoost/LightGBM | 流失风险/购买概率/偏好倾向 | 具备前瞻性,支持动态更新 | 需标注数据、可解释性弱、需定期重训 |
| LLM驱动法 | 大模型语义理解非结构化文本 | 情绪倾向/价值观/MBTI/深层意图 | 从评论/对话/搜索词挖掘金矿 | 需Prompt工程+幻觉控制+隐私合规 |
融合策略才是正解:规则驱动打基础(属性标签)→聚类分析挖隐藏(行为标签)→ML预测做前瞻(意图标签)→LLM解读非结构化(深层洞察)。三层标签体系+四种方法组合,比单一方法覆盖率提升40%以上。

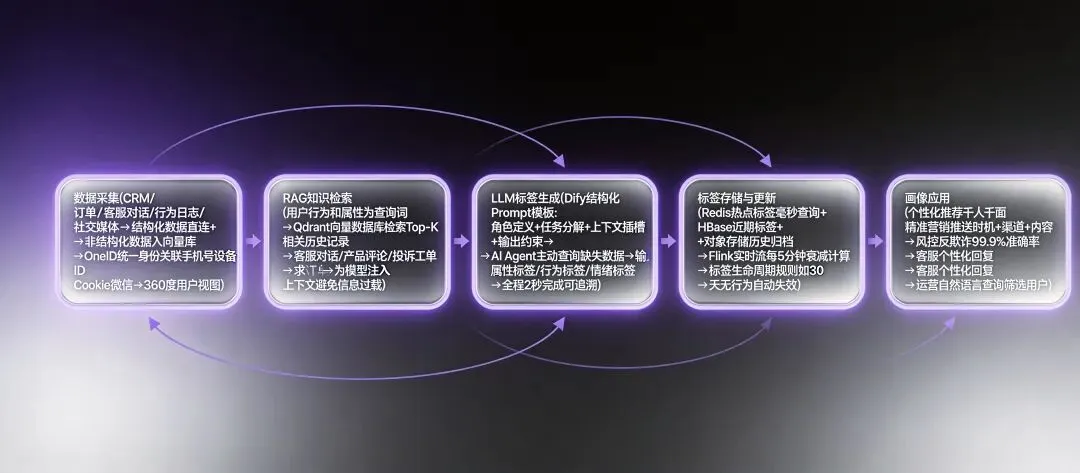
⚡ 三、Dify+n8n画像工作流5步法——2秒出画像,全程可追溯
这是本文的核心实操部分。用Dify搭AI大脑,n8n做自动化四肢,5步搭建端到端的用户画像流水线。
步骤1:数据采集与OneID统一身份
最大痛点:用户数据散落在CRM、订单系统、客服对话、行为日志、社交媒体5+个系统里,手机号、设备ID、Cookie、微信号互不相认。
解决:通过ID-Mapping技术,将碎片化身份关联到同一个UID下,形成360度用户视图。某新零售平台通过手机号+会员卡+小程序多维匹配,线上线下身份匹配准确率达95%以上。
- 结构化数据(注册信息/订单/会员等级)→直接注入Prompt模板
- 非结构化数据(客服对话/评论/搜索词)→存入Dify向量知识库,按需RAG检索
步骤2:RAG知识检索——为模型注入上下文
传统做法把所有用户数据拼接进Prompt,受上下文长度限制只能保留片段。RAG改变了这一点:
将客服对话记录、产品评论、投诉工单等文本数据编码为向量存入Qdrant数据库,运行时按需检索Top-K相关条目。既保证上下文相关性,又避免信息过载。
关键配置:以用户行为和属性为查询词,从知识库检索该用户过去三个月的历史行为摘要、投诉记录和偏好标签。
步骤3:LLM标签生成——2秒出结构化画像
这是AI画像的杀手环节。Dify接收输入后启动多阶段工作流:RAG检索历史→Agent调用CRM/订单API拉最新数据→汇总注入Prompt模板→大模型综合分析→输出结构化画像JSON。
Prompt模板核心结构:
```
你是一名资深客户分析师,请根据以下信息生成客户画像:
【基本信息】{{profile.name}} | {{profile.age}} | {{profile.city}}
【近期行为】浏览:{{behavior.browsing_top3}} | 搜索:{{behavior.search_keywords}}
【历史订单】(RAG检索){{retrieved_orders}}
【服务记录】{{retrieved_tickets_summary}}
请输出:
- 兴趣标签:(3个,含置信度)
- 消费能力:(高/中/低+依据)
- 当前需求:(1句话描述)
- 情绪状态:(积极/中性/消极+关键词)
- 服务建议:(1条可执行建议)
```
实操要点:Dify支持Agent自主决策——当模型发现"缺少最近一次购买详情",会主动调用预注册的`get_user_last_order`工具获取数据,ReAct模式打破被动响应局限。
步骤4:标签存储与动态更新
画像不是做完就完事的,用户行为瞬息万变,标签必须持续更新:
- Flink实时流:监听Kafka用户行为事件,每5分钟执行活跃度衰减计算,降低7天前行为权重
- 标签生命周期规则:"母婴品类兴趣"连续30天无相关浏览→自动失效;"高客单价"需90天内至少3次≥500元订单→才持续有效
- 多级存储:热点标签→Redis毫秒查询;近期标签→HBase;历史归档→对象存储。某电商平台采用分层存储后,响应时间提升3倍,存储成本降低40%
步骤5:画像应用——四场景落地
画像不做应用就是自嗨,必须对接业务场景才能释放价值:
- 个性化推荐:基于深度兴趣标签+意图标签,千人千面。某社交平台画像驱动推荐,用户使用时长提升37%
- 精准营销:识别消费周期和偏好,最合适的时间推最相关的信息。某电商平台营销转化率提升2.5倍
- 风控反欺诈:画像驱动的风控模型,欺诈识别准确率达99.9%
- 自然语言查询:运营直接输入"筛选最近一个月对价格有负面情绪的户外运动爱好者",LLM自动转化为查询指令
📝 可直接复制的AI指令词模板
【指令词1】AI用户画像标签生成
适用场景:给定用户多源数据,自动生成结构化画像标签
请根据以下用户数据生成标准化画像标签:
【原始数据】
{{user_raw_data}}
请按4类输出:
1. 属性标签:格式"维度-值"(如"年龄段-25-30岁")
2. 行为标签:格式"行为类型-特征"(如"购买频率-月均3次")
3. 需求标签:格式"需求类型-具体需求"(如"功能需求-温和配方")
4. 意图标签:格式"意图类型-判断依据"(如"购买意愿-高,搜索+加购+比价")
每个标签附带置信度(高/中/低),标注推断依据,禁止臆测无数据支撑的标签。
【指令词2】Dify用户画像工作流Prompt
适用场景:在Dify的LLM节点中生成客户画像叙事描述
你是一名资深消费者心理分析师,请根据以下信息为客户生成一段专业且具象的画像描述。
用户基础信息:{{basic_info}}
近期关键行为:{{recent_actions}}
相关市场洞察(来自知识库):{{rag_retrieved_context}}
请按以下步骤思考并输出:
1. 特征提炼:总结不超过3个最显著的用户特征
2. 动机推断:结合行业常识,推断特征背后的动机或偏好
3. 叙事合成:整合分析,用150字描述该用户画像,像一个真实人物的故事片段
注意:所有结论需基于给定信息,禁止臆测。
【指令词3】n8n用户标签自动打标工作流
适用场景:n8n工作流中Webhook触发自动打标签
当接收到用户行为事件({{event_type}})时:
1. 判断事件类型:浏览/点击/加购/购买/搜索/客服咨询
2. 根据行为权重(购买5/加购3/点击2/浏览1)计算品类偏好分
3. 归一化偏好分(每个用户总偏好分=1)
4. 取最高品类作为"核心兴趣品类"标签
5. 若偏好分>0.6,同时打上"高兴趣-{{品类}}"标签
6. 若连续30天无该品类行为,标记标签为"待衰减"
7. 输出:{{user_id}}, {{标签列表}}, {{偏好分}}, {{标签状态}}

💬 实操小贴士
- 先用规则驱动打基础,再用AI做增量
:不要上来就搞深度学习,先把"近30天购买3次=活跃用户"这类规则标签跑通,验证数据质量,再逐步叠加聚类和ML预测标签。
- LLM画像的杀手锏是非结构化数据
:你的客服对话、用户评论、搜索关键词里藏着80%的用户洞察,传统标签系统完全覆盖不到。用RAG+LLM从"这款面霜太油了"里提取"肤质偏好-油性皮肤",从"出差带方便"推断"便携需求-小规格",这才是AI画像的核心价值。
- 标签生命周期管理比标签生成更重要
:一个连续30天没搜过"装修"的用户,"装修刚需"标签必须自动衰减或失效。否则你的画像系统会变成"标签垃圾场"——标签越积越多,有效比例越来越低。用Flink每5分钟做一次活跃度衰减计算,是生产环境的底线。
- Dify的Agent功能让画像从被动变主动
:传统画像是"喂什么算什么",Dify的Agent可以主动发现数据缺口并调用工具补全——"缺少最近一次购买详情?我调一下CRM接口"。某企业实测整个画像生成过程不到2秒,且全程可追溯可审计。
- A/B测试验证画像有效性
:随机抽取1%用户作为对照组,屏蔽画像驱动的推荐和触达,对比实验组的点击率、转化率、LTV差异。用SHAP值分析各特征对预测的边际贡献,检查是否存在地域或性别偏差超过15%的情况。
⚠️ 避坑指南:用户画像系统的4大致命陷阱
坑1:拍脑袋定标签,凭经验定义"高价值用户"
"消费>1000元=高价值"这种规则忽略了月消费999但每周复购3次的忠实用户。解决:规则驱动+聚类+ML三层标签体系,用数据发现隐藏群体,科学验证可迭代。
坑2:只做静态标签,画像做完就不管了
28岁女性北京——这个标签3个月前打的,用户早就不在北京了。解决:Flink实时流+标签生命周期规则动态更新,30天无行为自动衰减,90天无验证自动失效。
坑3:数据孤岛,CRM/订单/客服各系统互不互通
5个系统的数据各管各的,同一用户在CRM是"张女士"在订单系统是"UID_8837"。解决:OneID统一身份关联+向量库RAG检索,手机号/设备ID/Cookie/微信号关联到同一个UID,构建360度用户视图。
坑4:画像做完没人用,运营还是凭感觉决策
花3个月搭了画像系统,运营说"太复杂不会用",最后还是Excel筛人群。解决:自然语言查询+API服务层+营销/推荐/风控/客服四场景落地。运营直接输入"筛选对价格敏感的户外爱好者",LLM自动生成查询,画像从技术资产变成业务武器。
🌟 关注星网AI
学会了吗?赶紧试试吧!
关注星网AI,每天分享AI实用技巧和提效干货。
下期教你用AI搭建智能推荐系统,别错过哦~
