 夜雨聆风
夜雨聆风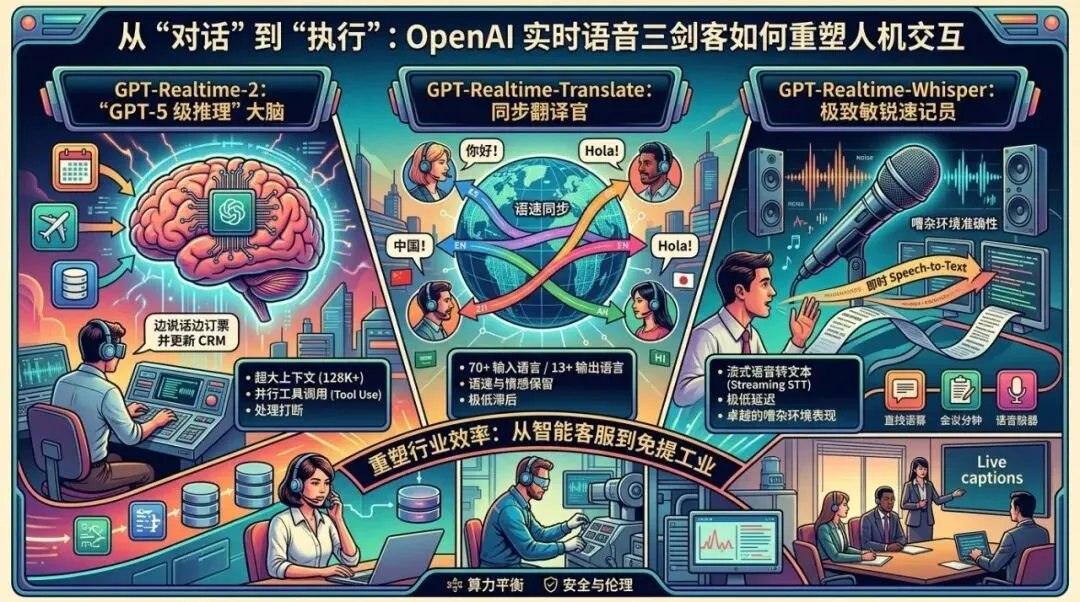
如果说 GPT-4 开启了“文字智能”的巅峰,那么 OpenAI 近期发布的实时音频模型系列,则标志着 AI 正式从“离线思考”跨入“实时响应”的音频优先时代。通过 GPT-Realtime-2、GPT-Realtime-Translate 和 GPT-Realtime-Whisper 这三款模型的组合,OpenAI 正在构建一个集聆听、理解、翻译与行动于一体的智能语音操作系统。
1、三款模型的职能分工
为了实现低延迟、高智能的语音体验,OpenAI 并没有采用“一刀切”的方案,而是通过三个专业化模型形成了技术矩阵。
GPT-Realtime-2:具备“GPT-5 级推理”的大脑这是该系列中的核心推理引擎。与传统的语音助手不同,它首次具备了 GPT-5 级别的推理能力,能够处理逻辑极其复杂的请求。其核心突破在于 128K 的超大上下文窗口(甚至支持扩展至 256K),这意味着它在长达数小时的对话中,依然能清晰记得最初的细节和复杂的业务约束。此外,该模型支持“并行工具调用”,能够边说话边查日历、订机票或更新 CRM 系统,并妥善处理用户在中途的打断与纠正,让交流更接近真人之间的自然流转。 GPT-Realtime-Translate:打破壁垒的同步翻译官这款模型专注于解决跨语言沟通的实时性问题。它支持超过 70 种输入语言与 13 种输出语言的互译。其最显著的特点是“语速同步”,翻译输出能够紧跟说话者的节奏,几乎消除了传统翻译软件中常见的严重滞后感。它不仅在翻译文字,更在尝试保留原说话者的语境、重音甚至情感色彩,力求实现接近同声传译的无缝体验。 GPT-Realtime-Whisper:极致敏锐的实时速记员作为流式语音转文本(STT)工具,GPT-Realtime-Whisper 将延迟降到了极致。它能在说话者发音的同时即刻生成准确文本,特别是在嘈杂环境、多样化口音及快速语速下,其表现远超前代 Whisper 模型。它是实时字幕、会议自动记录以及“语音触发工作流”等场景的关键基石。
为了更直观地理解这三者的协作关系,可以参考以下针对其核心功能的逻辑对比:
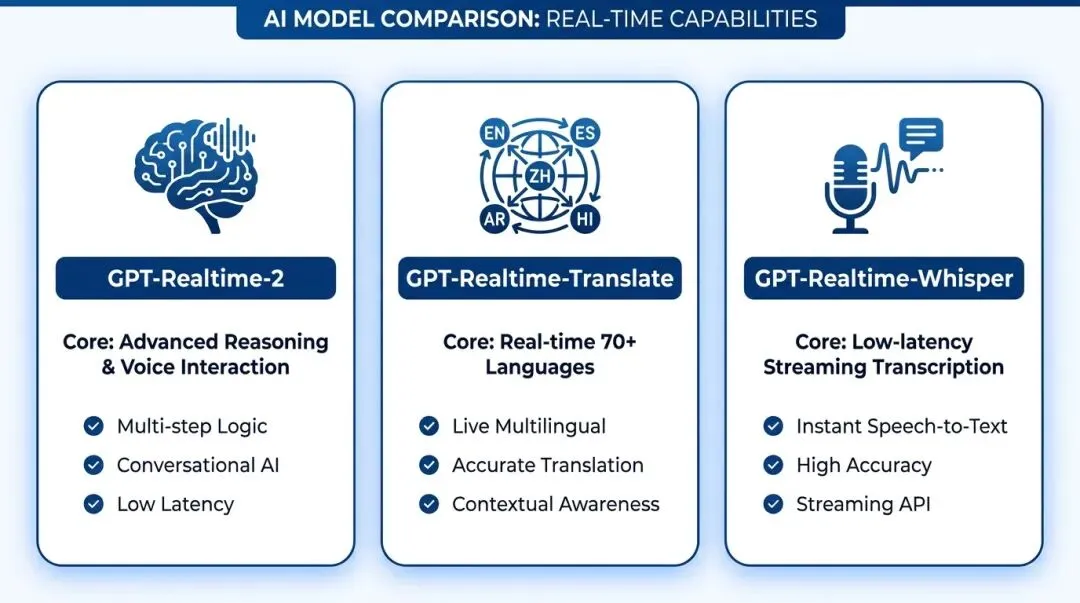 引用自 task_id: generate_comparison_image
引用自 task_id: generate_comparison_image
2、从屏幕主导向音频优先的范式转移
这套音频模型矩阵的发布,不仅仅是技术参数的提升,更是在多个行业引发了深层的效率变革。
在智能客服与支持领域,传统的“按键式”或“弱智文本式”客服正在消亡。Zillow 等房产平台和 Priceline 等旅游巨头已经开始利用这些模型构建语音代理。这些代理不再是简单的问答机器,而是能够理解“我想找一个避开主干道、带院子且在预算内的房子”这种复杂指令,并直接在系统中安排看房。这种从“回复”到“行动”的转变,极大地缩短了企业的转化路径。
在全球贸易与专业协作中,实时翻译模型正在降低跨国沟通的门槛。德国电信等企业通过这些工具提供多语言支持,使客户能用母语解决技术问题。这对于需要高度准确性和实时性的全球供应链协调、跨国商务谈判而言,意味着沟通成本的指数级下降。
在工业生产效率方面,音频优先的交互释放了劳动者的双手。在复杂的制造或物流环境中,技术人员可以一边维修设备,一边通过语音实时查询维护历史或调用技术手册,无需停下手头工作去查看平板电脑。这种“免提式”智能极大提高了操作的安全性和生产连续性。
3、意义、挑战与边界
OpenAI 这一系列模型的推出,其核心意义在于证明了语音可以成为比屏幕更自然、更高效的软件接口。它将 AI 语音从一种“昂贵的点缀”变成了“普适的基础设施”,大幅降低了开发者构建复杂音频应用的门槛。
然而,技术依然存在局限性。首先是算力成本与延迟平衡,尽管已达实时级别,但在极高并发下的稳定性仍需市场检验。其次是安全与伦理风险,极高仿真度的声音合成能力如果被滥用,可能导致 Deepfake 欺诈、身份冒用等社会问题。此外,过度自然的语音交互可能引发用户的情感依赖,这也是技术在商业化路径上需要关注的人文课题。
总的来说,音频 AI 正在进入一个“不仅能听清,更能听懂并去执行”的新阶段。随着开发者生态的介入,我们或许很快就会迎来一个不再需要反复点击屏幕,只需通过自然交谈就能调动全球资源的新时代。
*本文依据网络搜集数据整理,由AI工具辅助完成
All rights reserved. Copyright © 2026


