 夜雨聆风
夜雨聆风作为与影像数据日夜打交道的从业者,我对“真实临床场景”这五个字的敬畏,远超过对任何SOTA数字的迷恋。 今天咱们不聊某篇单点的影像分割论文,而是把视野拔高,深入解读《npj Digital Medicine》上的三篇最新研究。
它们从三个不同的技术视角——构建连续多模态数据供应链、利用大语言模型挖掘非结构化文本、以及通过“伪注记”将表格数据转化为语言模型通用接口——共同回应了“如何让AI真正理解医疗数据”这一核心命题。
我整理了50篇“医疗AI"相关论文(包括本章论文),供大家学习了解这个方向,找到课题,挖掘创新点。

扫码回复“医疗AI"
免费领取&进交流群

当我们在谈论医学人工智能时,常常被其“超越人类”的单一指标所吸引。但作为在医院影像科和信息科之间反复磨合过的过来人,我必须指出一个冷酷的现实:一个在标准测试集上表现出色的模型,一旦部署到真实、混乱、多源且充满不确定性的临床环境中,其性能可能断崖式下跌。 这其中的核心挑战,并非模型本身的“智商”不足,而在于其能否真正理解、整合并转化来自电子病历(EHR)的异构数据。
从离散的实验室指标到非结构化的医师笔记,从影像报告到基因组序列,医疗数据是典型的多模态、多尺度存在。构建一条从原始数据到可信临床决策的“高速通路”,是当前医疗AI从实验室走向床旁必须翻越的大山。这不是一个算法问题,而是一道系统工程命题。
1、论文名称:Continuous multimodal data supply chain and expandable clinical decision support for oncology作者与机构:Jee Suk Chang, Sang Joon Shin 等,韩国延世大学医学院发表平台:npj Digital Medicine (IF: 15.1)
2、创新点拆解:
第一,构建了“YCDL”多模态数据供应链框架。这是一个端到端的自动化数据集成框架,能够持续、实时地从医院信息系统中抽取、转换、加载临床、影像和基因组学数据。咱们做影像分析的都深有体会——传统数据收集方式耗时、零散且更新滞后,常常等你数据准备好了,研究灵感已经凉了一半。YCDL的这套ETL流程恰恰解决了这个痛点。
第二,引入包含143条规则的逻辑质量控制系统,超越了简单的数据完整性检查,通过一系列基于人类临床逻辑的规则(如“放疗完成日期不能早于开始日期”、“月经初潮年龄应在8-20岁之间”)来识别数据中的冲突、异常和时间谬误,显著提升了数据可靠性。
第三,开发面向患者的交互式CDSS仪表盘,设计了一个四面板可视化系统,不仅能展示三维肿瘤负荷和纵向生长曲线,还能在一条时间轴上完整呈现患者的治疗历程,让医生一键获取患者全貌,极大减轻了从碎片化EMR中梳理病情的认知负担。
方法/实验设计:研究基于韩国一家大型癌症中心2006-2022年间超过17万名患者的EHR数据,覆盖11种癌症。核心流程是从源数据到数据仓库,再到按癌症类型和主题分组的数据集市,最终加载到YCDL数据库,整个过程通过每日自动运行的ETL流程实现更新。
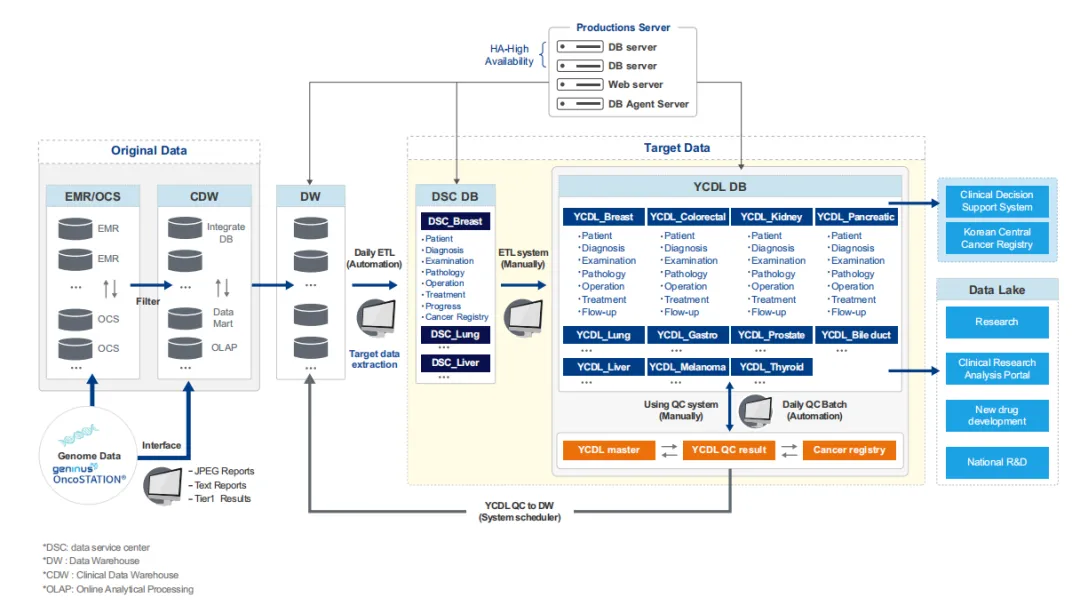
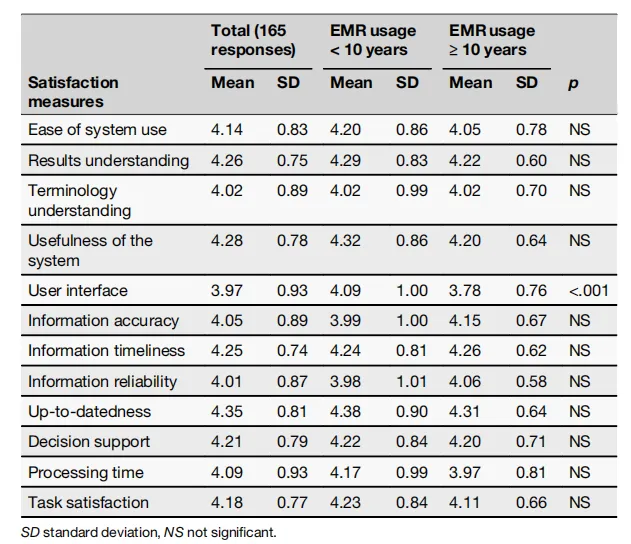
研究成果:手术病理和分子病理报告的中位准确率分别达到92.6%和98.7%。临床医生使用满意度调查显示,在“系统易用性”、“信息准确性”、“决策支持”等几乎所有维度上,平均得分均超过4分(满分5分)。
我的点评:这项研究最让我欣赏的一点是——它不追求单一模型的炫技,而是夯实了AI在临床应用的“数据地基” 。从医学影像技术的角度看,我们日常处理的CT、MRI、PET等模态数据,本质上就是多模态医疗数据供应链中最核心的一环。影像数据天然具有标准化程度高、定量特征丰富的优势,但若不能像YCDL这样将影像与临床、病理、基因组学数据实现时序对齐和逻辑校验,再好的影像AI模型也只能在沙地上建城堡。 数据治理不是“脏活累活”,而是让影像AI获得临床话语权的入场券。

扫码回复“医疗AI"
免费领取&进交流群

论文名称:Development and prospective implementation of a large language model based system for early sepsis prediction作者与机构:Supreeth P. Shashikumar, Shamim Nemati 等,美国加州大学圣地亚哥分校发表平台:npj Digital Medicine代码链接:https://github.com/NematLab/COMPOSER-LLM
创新点拆解:三项设计都透着一股“工程美学”的味道。
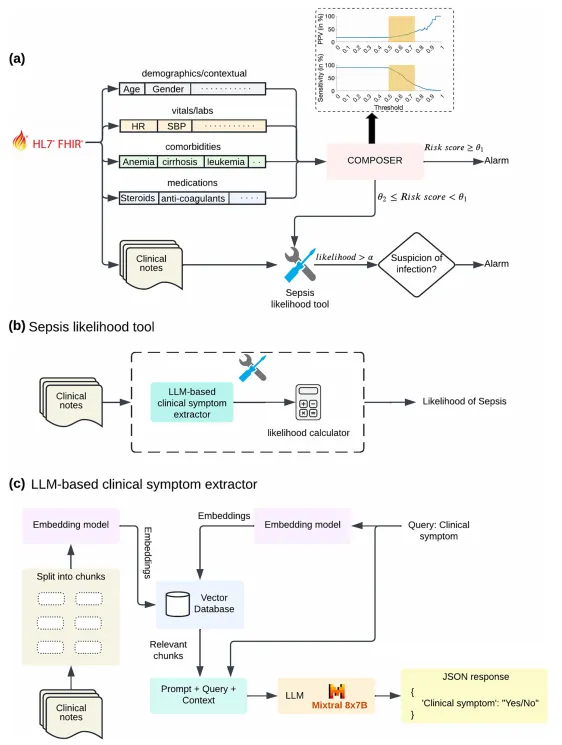
第一,“AI协同诊断”式双阈值触发机制。研究团队创新性地将LLM用作不确定性区域的“专家会诊”工具——当传统模型的预测分数处于高不确定性区间(如0.5-0.75)时,才调用LLM分析临床笔记进行鉴别诊断;对于高置信度预测则直接报警。这在提升性能与控制计算成本间取得了优雅平衡。这种设计思路对影像AI领域极具启发——我们的CAD系统同样面临“到底什么时候该让医生再确认一下”的阈值困境。
第二,利用LLM进行信息检索与概率推理,而非直接诊断。避免让LLM“硬猜”是否败血症,而是设计提示词令其从临床笔记中提取特定症状和体征,随后将这些证据输入一个贝叶斯似然计算器,生成包含败血症及其mimics(如心源性休克、肺栓塞)的排序鉴别诊断列表,大幅提升了可解释性和可靠性。让LLM做擅长的事(文本挖掘),让统计学做擅长的事(概率推理)——这才是AI+临床的正确打开姿势。
第三,基于FHIR/HL7标准的云平台前瞻性部署,通过医疗互操作性标准实时获取数据并回写预警,完成了从回顾性研究到真实世界“静默部署”验证的完整闭环。
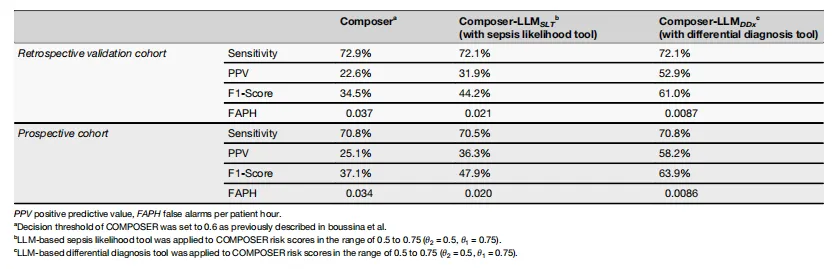
研究成果:在前瞻性验证中,COMPOSER-LLM达到了70.8%的敏感性和58.2%的PPV。
我的点评:这项研究为影像AI领域提供了一个极有价值的范式参考。当下医学影像领域正在经历从“task-specific架构”向“通用基础模型”的范式跃迁,但LLM在影像中的角色定位一直存在争议。COMPOSER-LLM给出的答案是:LLM是临床决策链条中的“推理增强层”,而非替代层。这让我们不得不重新思考——在影像报告中,大量非结构化文本(如放射科医师的“印象”和“建议”段落)蕴含着影像特征之外的关键上下文。未来的影像CDSS,或许正应该是“结构化影像特征提取器 + LLM文本上下文挖掘 + 贝叶斯概率推理”的三层架构。 MICCAI 2026已经将“从理论到实践的临床转化”列为核心议题,COMPOSER-LLM的设计范式正好回应了这一趋势。这恰恰是当前“从task-specific到foundation model”范式转变中,一个极具发刊潜力的交叉方向。

扫码回复“医疗AI"
免费领取&进交流群

论文信息
论文名称:Clinical decision support using pseudo-notes from multiple streams of EHR data
作者与机构:Simon A. Lee, Jeffrey N. Chiang 等,美国加州大学洛杉矶分校(UCLA)等
发表平台:npj Digital Medicine
论文链接:https://doi.org/10.1038/s41746-025-01777-x
代码链接:https://github.com/Simonlee711/MEME
创新点核心:这项研究解决了医学AI中一个长期被忽视的结构性问题——非结构化的自由文本(临床笔记、影像报告)和结构化的表格数据(实验室检验、生命体征)是两类截然不同的数据形态,传统多模态模型很难在同一个语义空间中统一表征它们。SHM-LLaVA通过设计“伪注记”机制,将表格数据转化为语言模型能够理解的通用接口格式,实现了两种数据形态的无缝融合。
我的点评:从影像技术的视角看,这一思路直接对标了当前医学影像组学研究中的一个关键瓶颈。影像组学本质上就是从医学图像中提取“结构化表格特征”的过程——几百个手工设计的形态学、纹理、小波特征,本质上不就是一张关于“这个病灶长什么样”的表格吗?
然而当前影像组学的主流做法仍然是:从影像中提取特征形成表格 → 用传统机器学习模型做分类预测。SHM-LLaVA的范式启发我们,或许影像组学特征完全可以通过类似的“伪注记”机制,与文本报告的语义特征在LLM的潜在空间中对齐,实现“影像语义+文本语义”的真正多模态融合。影像组学 + LLM = 可解释性影像决策支持?这个交叉方向正在打开一扇新的发刊窗口。
从文献计量学的角度看,当前AI影像组学的研究热点确实集中在深度学习驱动的医学图像分割和癌症预测,但临床转化面临的模型泛化能力不足和医工协同欠缺等挑战,恰恰需要SHM-LLaVA这类“数据形态桥梁”式的工作来破解。

扫码回复“医疗AI"
免费领取&进交流群

行业视角:医学影像AI的三重趋势交汇
将这三篇论文放在整个医学影像技术发展的坐标系中审视,它们不是在解决彼此孤立的问题,而是共同指向了一个更宏大的行业趋势:医学影像AI正从“看图说话”走向“多模态融合决策”。
第一重趋势:影像数据的标准化与持续供给。正如YCDL框架所展示的,医学影像的DICOM标准虽然让图像数据本身具有极高的互操作性,但只有将影像数据与EHR、病理、基因组学数据通过自动化ETL管道和逻辑质控体系整合在一起,才能真正释放影像AI的临床价值。
第二重趋势:从“替代医生”到“增强医生”的定位转型。COMPOSER-LLM的双阈值触发机制完美诠释了这一点——AI的使命不是拍板诊断,而是在不确定性区间提供推理增强。影像AI作为“诊断增强层”的定位,正在成为行业共识。
第三重趋势:多模态融合的基础模型时代。当前医学影像领域正在经历一场从“单模态专病模型”向“多模态通用基础模型”的范式跃迁——MedVersa、Merlin、M-IDoL等工作的涌现,标志着AI正在学习同时理解CT的体素、MRI的驰豫参数、病理切片的染色特征和临床文本的语义空间。从文献计量学的分析来看,AI影像组学研究热点恰好聚焦于深度学习驱动的医学图像分割、影像诊断和报告生成技术,尤其在癌症预测中应用广泛——但临床转化面临模型泛化能力不足和医工协同欠缺等挑战,这三篇论文正是从三个不同的工程维度回应了这些挑战。
一场科研征途的三重修行
拆解完三篇顶刊论文,我想和屏幕前的你聊几句掏心窝的话。这三项研究的共同底色,其实是一部科研人的“渐进式通关史”——从浩如烟海的原始数据中理出头绪、在模型的能力边界上反复试探、把不同形态的信息编织成一张可用的网络。无论你是初入科研的新手,还是正在冲击顶会的老兵,抑或是为博士学位论文焦头烂额的准博士,你此刻面临的困境,本质上与这三篇论文的作者们并无二致。
🎁 双重福利
1️⃣精准方向:医疗AI”方向 50+篇 论文
2️⃣CCF/SCI论文全流程避坑清单:从idea到Accept
👉 扫码回复“医疗AI”👉全部免费领取 + 进群交流
扫码添加学长回复医疗AI

如果你发CCF/SCI论文,但是遇到了难题
比如初入科研根本不知道怎么学——
如何快速找到idea,如何正确的选择模型,怎么避免与其他工作重复,什么样的实验计划省时效果显著,一边实验一边出论文初稿技能,针对不同的期刊会议绘图方法,终稿完善,投稿策略,期刊/会议选择,rebuttal等每个环节都是挑战已经发过B会要挑战A会(顶会) 的,想要从选题、创新点设计,到实验设计与验证、到论文逻辑,公式图表绘图都有一个质的提升。
硕博大论文要融入已发表论文工作,但是一直没办法跳出单篇论文的创作模式的同学,想要以宏观视角,把之前长达四年单篇论文细节的研究成果,整合成一部逻辑自治、体系完整的博士学位论文。
扫码咨询CCF/SCI论文1v1辅导

科研经验丰富的导师手把手带你
研梦非凡与来自海外QStop50、国内华五、C9、985高校的教授/博士导师/博士后,世界500强公司算法工程师,以及国内外知名人工智能实验室研究员合作。
这是一支实力强大的高学历导师团队,在计算机科学、机器学习、深度学习等领域,积累了丰富的科研经历,研究成果也发表在国际各大顶级会议和期刊上,在指导学员的过程中,全程秉持初心,坚持手把手个性化带教。





<<< 左右滑动见更多 >>>

有了导师的经验加持,能少走80%的弯路!
科研从来不是单打独斗,善用导师资源,才能让每一步都走得更稳、更准~Accept才能是你的!
(部分学员好评图)

<<< 左右滑动见更多 >>>

研梦非凡
正规机构保障:背靠研途考研,深耕教育十余年,重交付、重口碑是我们一贯的理念,大公司将为你的科研之路和自身权益全程保驾护航!担心机构不正规?扫码联系学长,可查看公司完整资质,放心选择。


滑动查看更多公司信息
