OpenHuman 值得看的地方,不是又多了一个聊天窗口,而是它把“个人上下文”放在第一位:先接入你的工具和资料,持续整理成记忆,再让 AI 助手真正带着背景来工作。
OpenHuman 封面我今天看到一个挺有代表性的开源项目:OpenHuman。它在 GitHub 上的定位很直白:OpenHuman is your Personal AI super intelligence. Private, Simple and extremely powerful.翻成普通话就是,它想做一个更贴近个人工作流的 AI 助手,而且重点不只是“能聊天”。这个项目目前大约有 3.9k stars,主语言是 Rust,许可证是 GPL-3.0,最新版本已经发到 v0.53.35。先提醒一句,README 里也明确标了 Early Beta,所以它更适合尝鲜和观察方向,不适合直接当成熟生产工具押上去。
它想解决的不是聊天,而是上下文
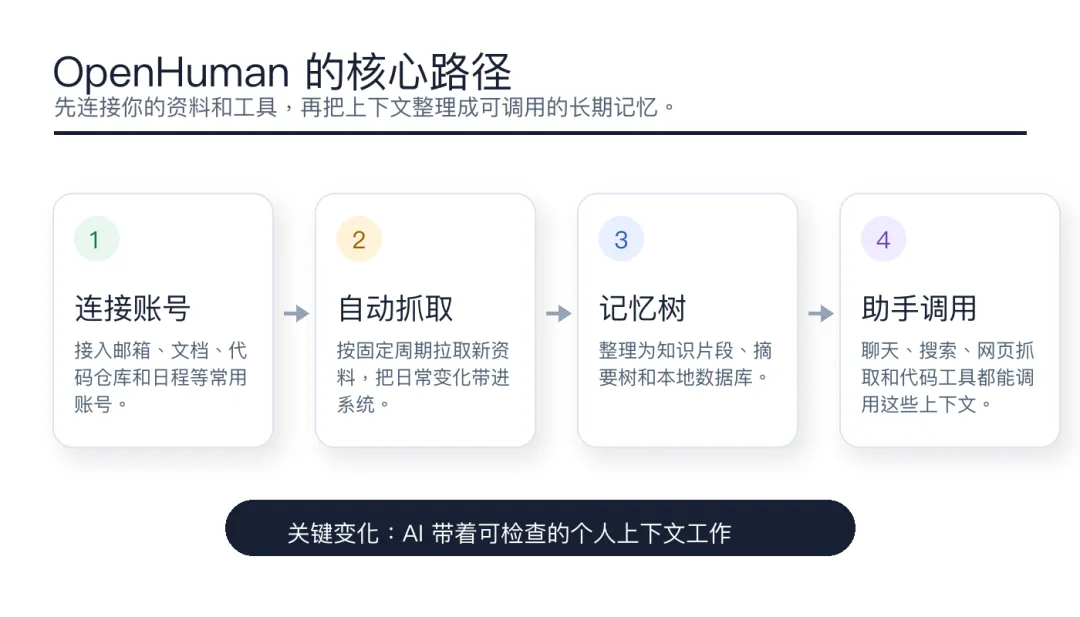
现在很多 AI 助手都有一个老问题:每次打开都像新同事入职。你要重新解释项目、文件、日程、邮件和会议背景,最后大半时间不是在让 AI 干活,而是在给它补课。OpenHuman 的思路是反过来:先让助手接进你的日常工具,再把信息变成长期记忆。README 里提到的几个点很关键:118+ 第三方集成、OAuth 连接、20 分钟一轮自动抓取、Memory Tree、Obsidian Wiki、本地 SQLite、内置搜索和网页抓取工具。听起来功能很多,但合起来其实是一件事:让助手不再只依赖当前聊天框里的几句话。OpenHuman 工作流示意
如果只看功能清单,OpenHuman 会显得有点“什么都要做”:桌面端、吉祥物、语音、Google Meet、网页搜索、网页抓取、代码工具、模型路由、TokenJuice 压缩、消息渠道。但把这些能力放在一起看,它其实是在做一个个人 AI 工作台。你可以把 Gmail、Notion、GitHub、Slack、Calendar、Drive、Linear、Jira 这类工具接进去,让系统持续收集上下文。然后,助手再用搜索、抓取、文件系统、git、lint、test、grep 等工具去完成任务。这和很多“先开一个聊天框,再慢慢装插件”的产品不太一样。OpenHuman 的卖点是:我先把个人资料、工具和记忆接好,再让你和助手交互。
但也别忽略风险
这类产品天然会碰到两个问题。第一是授权边界。你把邮箱、文档、日程、代码仓库接进去,换来的确实是更强的上下文,但也意味着授权范围必须看清楚。它说本地优先、加密、本机存储,这些是好方向,不过真正使用前仍然要按自己的风险承受能力来决定接哪些账号。第二是成熟度。OpenHuman 现在还处在 Early Beta,open issues 也不少。对普通用户来说,现阶段更适合拿来观察“个人 AI 助手会往哪里走”;对开发者来说,可以重点看它怎么处理本地记忆、工具调用、桌面端和跨平台发布。
我的判断
OpenHuman 最值得关注的地方,不是它又包了一层模型,也不是它说自己能接很多工具。真正的变化是:个人 AI 助手正在从“会回答问题”转向“长期理解一个人的工作现场”。如果这个方向成立,未来助手之间的差异不会只看模型多强,而会看谁更会整理你的上下文、谁更透明、谁更能让你控制自己的数据。这也是 OpenHuman 这个项目值得被拿出来聊的原因。它还不一定成熟,但问题抓得很准:AI 助手要真正有用,不能每次都从零开始认识你。热点来晚了,但瓜更熟。梦飞帮你补错过的全网热事。
基本文件流程错误SQL调试
请求信息 : 2026-07-18 16:52:54 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/622567.html
 夜雨聆风
夜雨聆风