 夜雨聆风
夜雨聆风摘要:构建RAG原型只是第一步,真正的挑战在于生产环境的部署与运维。本文带你掌握RAG系统生产化的核心技能:可观测性建设、评估策略设计、成本与延迟的权衡,以及多模态RAG的前沿探索。
当RAG走出实验室
你已经掌握了设计和构建RAG系统所需的所有技能。原型在本地跑得行云流水,检索精准、回答流畅。但当你要把它投入真实生产环境时,一切都会变得不一样。
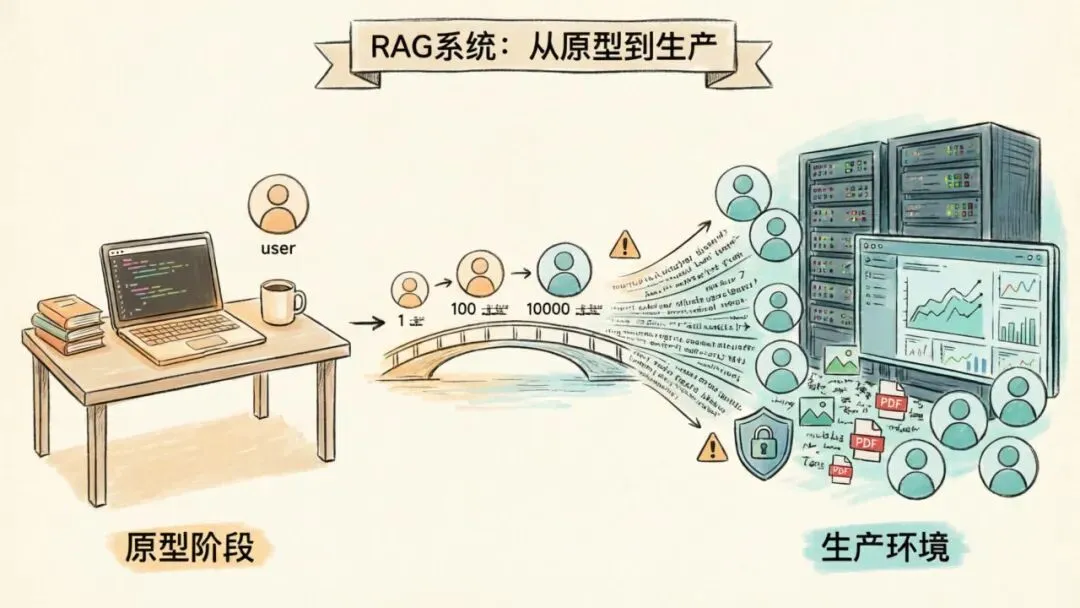
生产环境的第一个挑战来自流量规模。更多用户意味着更高的吞吐压力、更长的响应延迟、更大的内存和计算消耗,最终体现为成本的直线上升。第二个挑战是提示的多样性和不可预测性。测试集再完备,真实用户的输入总会带来惊喜。第三个挑战是数据的复杂性。现实数据往往是混乱的,格式不统一、缺少元数据,大量信息并非纯文本,而是存在于图像、PDF和演示文稿中。
更麻烦的是,生产环境中的错误会直接产生业务影响。谷歌AI搜索摘要上线时,有用户问"应该吃多少岩石",系统一本正经地建议食用岩石以获取营养益处。航空公司聊天机器人向客户承诺过不存在的折扣。恶意行为者会试图诱骗RAG系统免费出售产品,或泄露机密信息。
一句话:建立能够预见问题发生的系统、在问题出现时及时定位和遏制,并验证每项调整是否带来实际改进——这是每一个RAG工程师必须掌握的技能。
构建可观测性系统:你的RAG系统"驾驶舱"
应对生产挑战的第一步,是构建一个强大的可观测性系统。它需要追踪以下几类信息:
软件性能指标。你需要知道系统处理了多少请求、响应需要多长时间、消耗了多少计算和内存资源。这些是RAG系统最基础的健康指标。
质量指标。除了跑得快,你还需要知道跑得好不好。用户满意度、最终回复的召回率、检索文档的相关性——这些决定了你的RAG系统是否真正有用。
详细日志与追踪。可观测性系统应记录详细日志,追踪每个提示在RAG管道中的完整流程。当某个请求产生低质量响应时,你可以像侦探一样顺着日志回溯,定位问题根源。
实验与A/B测试。如果你想切换新的语言模型、调整系统提示,或优化检索器的设置,理想的可观测性系统应支持在安全环境中运行实验,或在生产中进行A/B测试,用数据说话。
开源利器:Phoenix平台
市面上有许多针对LLM应用的可观测性平台,我们来看看一个叫Phoenix的开源工具,由Arize AI公司开发。
Phoenix提供了追踪功能,可以记录提示在整个RAG流程中的路径:初始文本变成提示内容,然后发送给检索器查询,检索器返回文档片段,经过重排序器处理,最终发送给核心语言模型,生成响应。每个步骤的延迟等信息也能一目了然。
Phoenix还能与RAGAS库集成,计算检索器相关性、验证LLM是否正确引用来源,甚至每日生成关键指标报告——从检索器准确率到模型的幻觉率。
当然,没有工具是万能的。Phoenix不适合监控向量数据库的计算和内存使用,这时你需要结合Datadog和Grafana等传统监控工具。
自定义数据集:用真实流量优化你的系统
良好的可观测性管道最终会形成系统改进的飞轮效应:通过观察系统处理真实流量的方式,识别漏洞或改进目标区域,实施修改后观察变更的影响,如此循环往复。
这个过程中最有价值的工具之一,就是创建自定义提示数据集。简单来说,就是将系统之前处理过的提示集合保存下来,连同你选择的上下文信息——包括检索到的文档、排序前后的变化、重排序器处理过程、查询重写的输出等。
举个例子:你在构建一个客服聊天机器人。通过问题主题过滤,你发现退款相关问题的高质量回复率很高,但产品延迟相关问题的表现极差。深入分析日志后发现,检索器根本无法为这些提示找到相关文档。你补充了知识库内容,问题迎刃而解。这就是可观测性的威力。
RAG评估策略:衡量系统的"体检表"
评估是RAG系统生产化的核心环节。你需要从两个维度来设计评估体系:
评估范围:组件级 vs 系统级
系统级评估用于总结整体性能——端到端的延迟、整体响应质量,给团队一个宏观状态概览。组件级评估则帮助定位具体问题的根源:是检索器没找到相关文档?重排序器排序不当?还是LLM本身产生了幻觉?
评估方式:代码评估、LLM裁判、人工反馈
基于代码的评估最便宜、最简单。从记录每秒请求数,到运行单元测试确保LLM输出有效JSON——这些评估完全自动化、具有确定性,成本几乎为零。
人工反馈成本最高,但能捕捉代码评估遗漏的信息。用户点赞/点踩是最常见的形式,而人工预编的测试数据集则能精确计算精度和召回率。
LLM-as-a-Judge(LLM作为裁判)是成本和灵活性之间的折中。让一个LLM来评估检索器获取的文档是否相关,或判断响应的质量——这比代码评估更灵活,比人工标注更便宜。但需要注意,LLM裁判可能有偏见——更偏好同源模型生成的响应。它们在离散评分标准(如相关/不相关)下表现最佳。
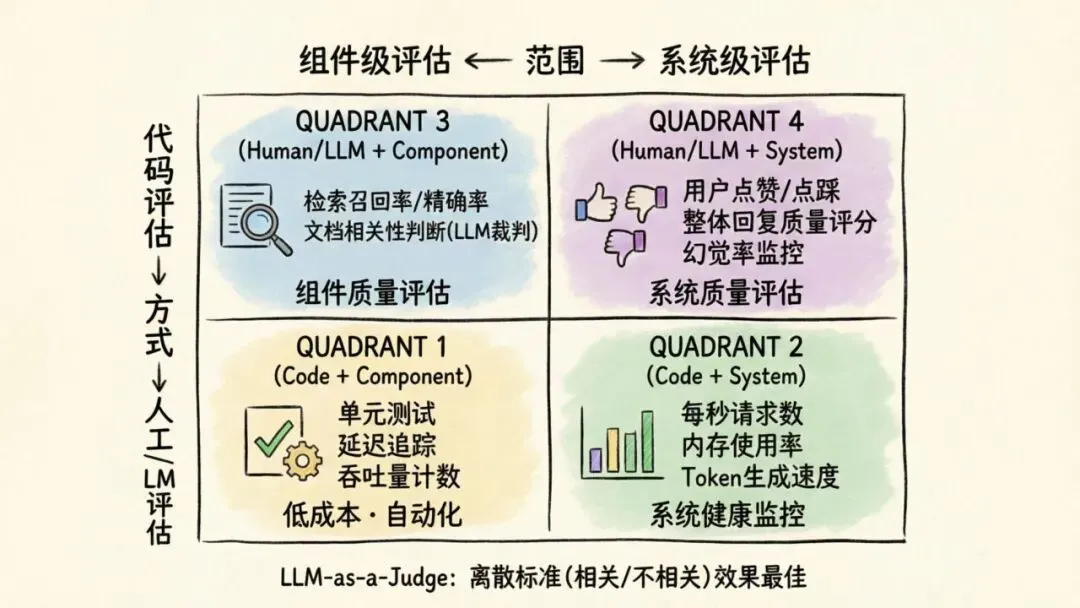
推荐的评估指标体系
建议从各主要组件的软件性能与质量指标开始收集,然后补充系统级指标。在实践中,这意味着:
• 代码评估以低成本捕获组件和系统级的性能数据(延迟、吞吐量、内存、Token生成速度) • 人工标注或LLM裁判负责质量评估(用户点赞/点踩 → 整体回复反馈;人工标注测试集 → 检索器召回率和准确率;LLM评估 → 响应相关性、引用质量、抗干扰能力)
模型量化:让RAG系统更小、更快、更便宜
量化是针对语言模型和嵌入模型的一种压缩技术。它用压缩后的低精度数据类型替换模型权重或嵌入向量的值,使模型变得更小、运行更便宜、更快——通常不会显著牺牲性能。
拿图像压缩来类比:24位图像色彩丰富但存储庞大;12位图像已经不如原图美观;6位图像则有明显的颜色伪影。但根据使用场景,质量下降可能换来巨大的内存节省,这笔交易可能是划算的。
量化的工作原理
以8-bit整数量化为例。先找到每个维度在向量数据中的最小值和最大值,确定该维度值的范围,然后将该范围划分为256个等距区间。原始向量中的每个浮点数被分配到所属区间的编号(0-255)。你只需要存储这些整数值和每个区间的最小值和宽度,就能重建原始32位浮点数——但仅用了四分之一的数据。
在实际基准测试中,8-bit量化仅导致几个百分点的性能下降,却带来巨大的空间节省。更前沿的1-bit量化(二进制量化)将向量压缩到极致——每个值仅为0或1,表示该维度值的正负。在这个压缩级别下,检索性能可能明显下降,但你可以用1-bit量化做快速初筛,再用完整32位向量对候选结果重新评分。
Matryoshka嵌入(套娃式嵌入模型)
另一种精巧的压缩方法是让向量维度按信息密度从高到低排列。你可以仅使用前100维进行初步检索(速度快、空间小),必要时再用完整向量精确排序。这种灵活性使其特别适合动态环境。
成本、延迟与质量的"不可能三角"
成本 vs 质量
降低成本的几个实用策略:
• 使用更小模型。无论是参数更少还是量化后的模型,小模型的表现往往令人惊喜,尤其是当LLM执行有限任务时 • 限制Token数量。减少检索文档数量(降低top-k值)、鼓励简洁响应 • 专用硬件部署。当请求量达到数千甚至数百万时,按小时租用GPU比按Token付费更经济
延迟 vs 质量
几乎所有延迟都来自Transformer模型调用。优化延迟的最佳起点是核心语言模型本身:
• 使用更小的LLM或量化模型 • 构建路由器:简单查询使用小模型快速响应,复杂推理路由到大模型 • 缓存:维护常用提示及其响应的缓存,新提示到来时先匹配缓存 • 测量每个组件的延迟贡献,移除收益不大的组件
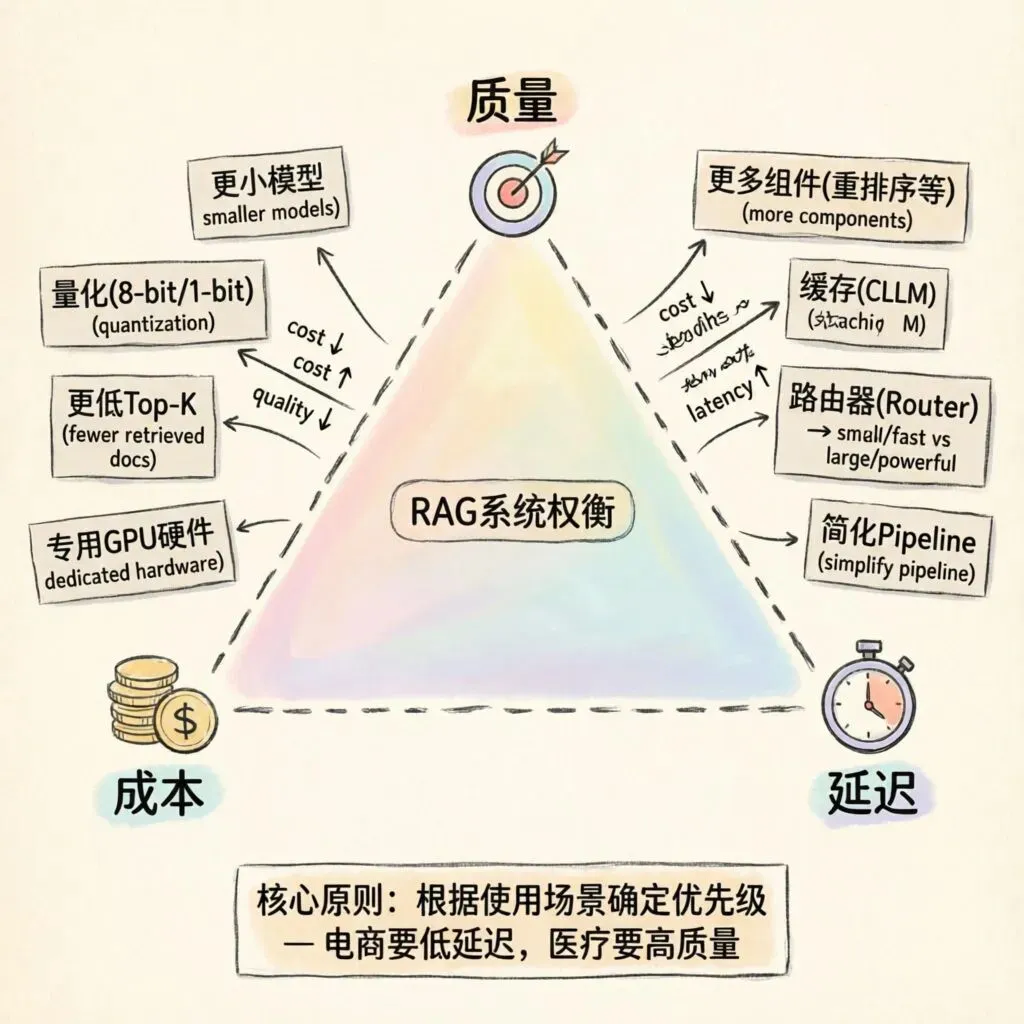
核心原则:了解你的使用场景对延迟的敏感程度。电商网站需要极低延迟,可能牺牲推荐精度。医疗诊断RAG更关注回答质量,可以接受较长延迟。
RAG系统安全:保护你的知识库
RAG系统面临独特的安全挑战。你最初选择构建RAG的原因之一,往往是因为拥有私有或专有信息——而保护这些信息恰恰是最棘手的问题。
信息泄露的风险路径
提示注入攻击。用户通过精心设计的提示,可能说服LLM直接引用知识库检索到的文本片段。
第三方LLM调用。当你的增强提示发送给外部LLM提供商时,其中包含的知识库文本片段将脱离你的安全控制。对于高安全等级的信息,你可能需要完全本地部署——将LLM和向量数据库部署在自有硬件上。
向量数据库逆向攻击。与传统数据库不同,向量数据库面临一个独特的安全弱点:文档的密集向量表示需要以明文形式存储在内存中,才能使算法正常运行。近期研究表明,攻击者可以从密集向量中重建原始文本。
应对策略
• 身份验证与多租户。确保只有授权用户能访问检索系统,按角色和权限隔离数据 • 加密。文本块可加密存储和检索,虽然会引入额外延迟 • 本地部署。完全掌控知识库在整个RAG流程中的流转 • 前沿研究。向密集向量添加噪声、向量变换、保留距离的同时降维模糊语义
多模态RAG:突破文本的边界
整个课程中,我们主要讨论基于文本的RAG。但现实世界的信息以多种格式存在:演示文稿、PDF、图像、音频、视频。
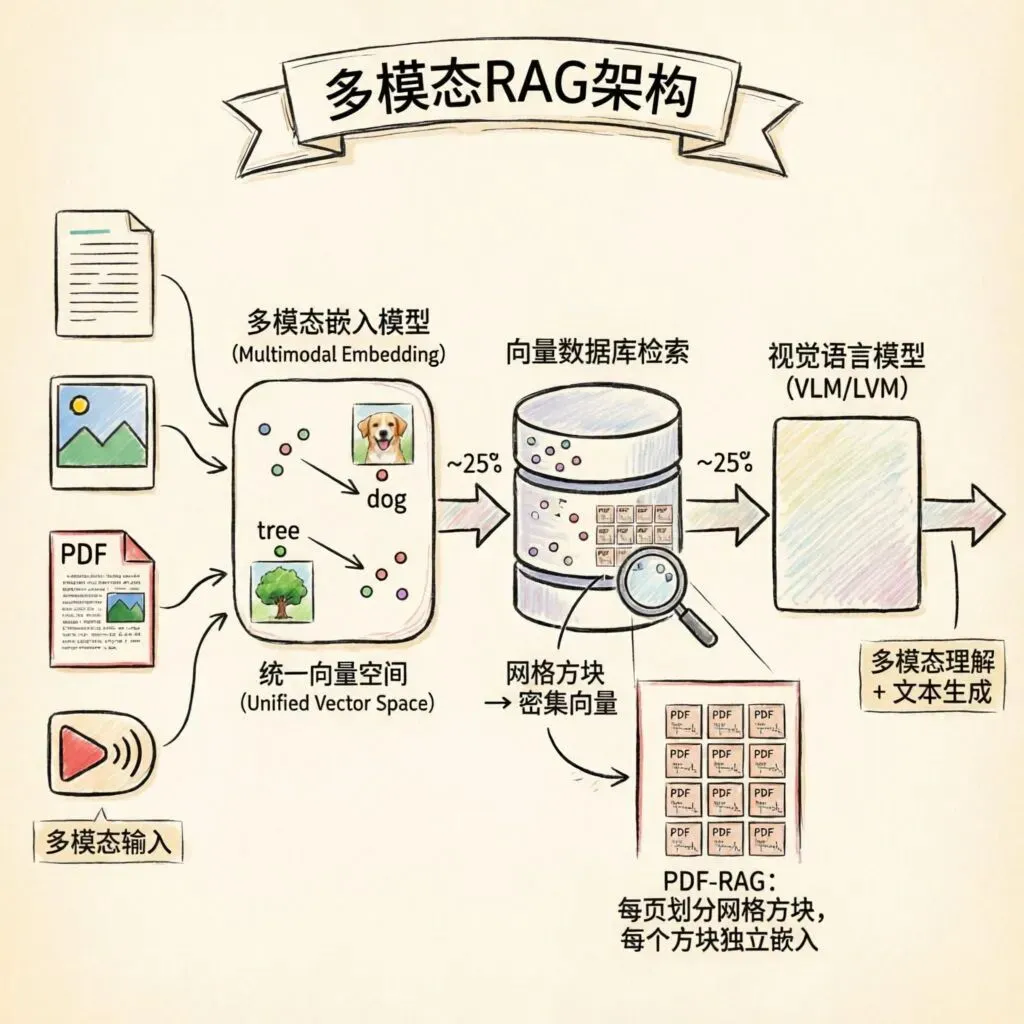
多模态RAG的核心是多模态嵌入模型——它能够将多种数据格式嵌入到同一向量空间。一张狗的图片和单词"dog"会在向量空间中彼此靠近,一张树的图片和单词"tree"则在另一个区域彼此靠近。
要处理PDF和幻灯片等复杂格式,就需要图像分块(Image Chunking)。新方法将每页划分为网格方块,每个方块由多模态嵌入模型生成密集向量,然后像ColBERT一样,每个查询词元找到页面上最匹配的图像块。这种方法灵活且表现出色,但需要数据库存储大量向量。
结语
从原型到生产,RAG系统的旅程才刚刚开始。你现在已经知道怎么构建可观测性系统追踪问题和性能、设计多维度评估体系、在成本/延迟/质量之间做权衡、保护知识库安全,以及向多模态领域拓展能力边界。
希望这门课程能为你未来的AI项目带来新的思路。无论你的AI旅程将走向何方,感谢一路同行。
