 夜雨聆风
夜雨聆风AI智能体构建与红队安全:并行多模态搜索智能体,效率感知强化学习;交互式红队评估平台(DTap),漏洞注入向量
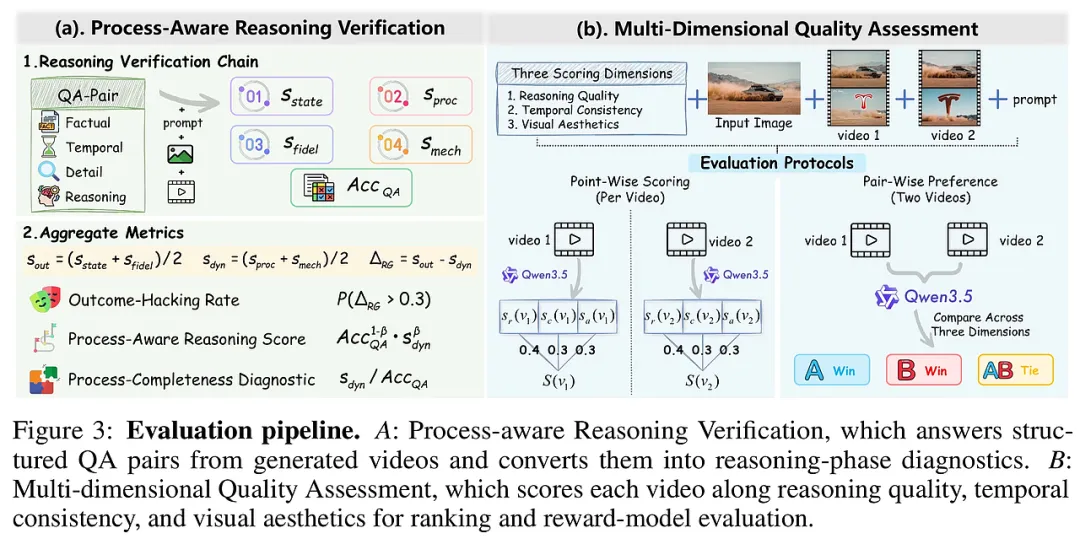
HyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning for Parallel Multimodal Search Agents
2026-05-08|Xiaohongshu, Cambridge|🔺57
http://arxiv.org/abs/2605.07177v1https://huggingface.co/papers/2605.07177https://github.com/Guankai-Li/HyperEyes
研究背景与意义
在多模态搜索智能体(Multimodal Search Agents)领域,现有的技术范式普遍遵循“串行思维”。当用户提出一个涉及多个实体的复杂查询时(例如:“识别图中这三种植物并说明它们的药用价值”),传统的智能体往往会陷入冗长的序列化操作:先定位第一个实体、搜索、记录,再转向第二个,循环往复。这种“深而窄”的搜索模式不仅导致了严重的交互冗余和推理延迟,还容易在长上下文中积累噪声,导致最终答案的偏离。
本研究敏锐地察觉到,对于可分解的复杂查询,有效的智能体应当“求广而非求深”。研究团队提出了HyperEyes框架,核心意义在于将“推理效率”提升为与“准确度”同等重要的训练目标。通过引入并行搜索机制,HyperEyes能够在一个交互回合内同时处理多个实体的定位与检索。这不仅是技术实现上的加速,更是对智能体逻辑构建方式的一次深刻重塑。在实时性要求极高的视觉搜索场景中,这种从串行到并行的范式转移,为构建高性能、低能耗的工业级AI助手提供了极具洞察力的理论支撑与实践路径。
研究方法与创新
HyperEyes的成功建立在对“动作空间”、“数据提纯”以及“强化学习机制”三位一体的深度创新之上。
1. 统一基准搜索(Unified Grounded Search, UGS)的动作空间创新 传统方法通常采用“先裁剪、后搜索”的两阶段流水线,这种结构存在脆弱的依赖性:一旦早期的视觉定位出现偏差,后续的搜索将全盘皆错。HyperEyes创新性地提出了UGS动作空间,将视觉定位(Visual Grounding)与信息检索(Retrieval)熔炼为一个原子化的操作。智能体不再是机械地执行单一任务,而是在一个回合内同时预测多个实体的边界框并分发并行查询指令。这种设计打破了模态间的隔阂,使得视觉空间的信息提取与互联网知识的获取在逻辑上实现了真正的同步。
2. 并行适配的数据合成与渐进式拒绝采样(PRS) 为了解决高质量并行搜索数据匮乏的问题,研究者构建了一套精密的合成管线。他们利用马赛克增强技术将不同类别的细粒度实体组合成复杂的多实体场景,并生成必须结合所有实体信息才能回答的QA对。更具洞察力的是其“渐进式拒绝采样(PRS)”策略:在构建监督微调(SFT)数据集时,系统会在不断收紧的回合预算下进行采样,仅保留那些路径最短、效率最高的成功轨迹。这种“优胜劣汰”的机制从根源上剔除了冗余的推理步骤,确保模型从冷启动阶段就植入了“高效并行”的基因。
3. 双粒度效率感知强化学习框架(核心创新) 这是本研究最具技术含量的部分,通过宏观与微观两个层面的协同优化,解决了强化学习中“信用分配”的难题。
宏观层面:TRACE(工具使用参考自适应成本效率)奖励机制。 传统的效率优化往往采用静态惩罚,这容易导致模型为了省事而放弃必要的深度搜索。TRACE引入了一个动态演进的参考基准:在训练过程中,系统会根据当前策略能达到的最优效率,单调地收紧“允许的工具调用次数”。这种自适应的“紧箍咒”形成了一套隐式的课程学习,引导模型在保证准确率的前提下,不断探索更精简的并行路径。 微观层面:策略内蒸馏(On-Policy Distillation, OPD)。 针对强化学习中稀疏奖励导致的推理错误难以定位的问题,HyperEyes引入了一个强大的教师模型(如235B版本)。在学生模型尝试失败的轨迹上,教师模型会提供密集的Token级纠正信号。这种设计非常巧妙:它只在失败时介入,既保证了学生模型能吸收正确的推理模式,又不会因为过度模仿教师而丧失自身通过TRACE学到的高效并行特性。
这种双粒度的设计哲学体现了理性的平衡:TRACE负责在轨迹层面“剪枝”,剔除冗余动作;而OPD负责在原子层面“纠偏”,确保逻辑严密。
实验设计与结果分析

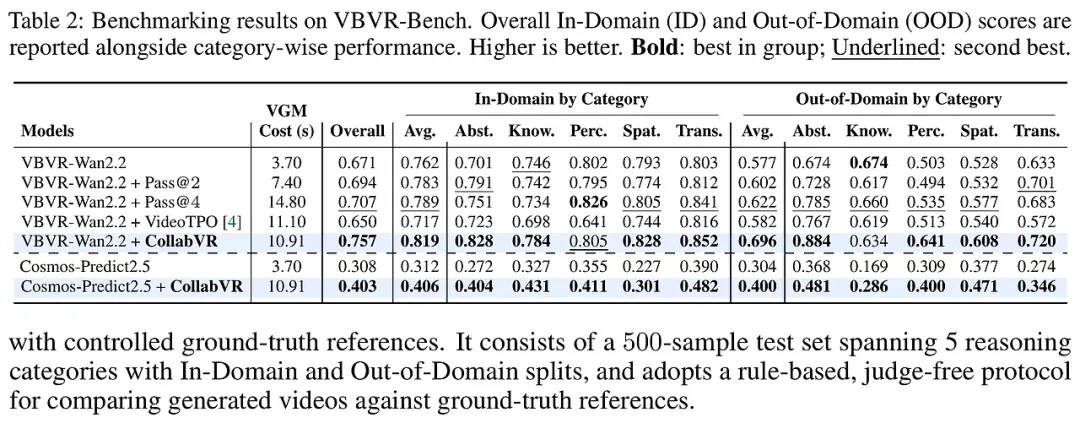
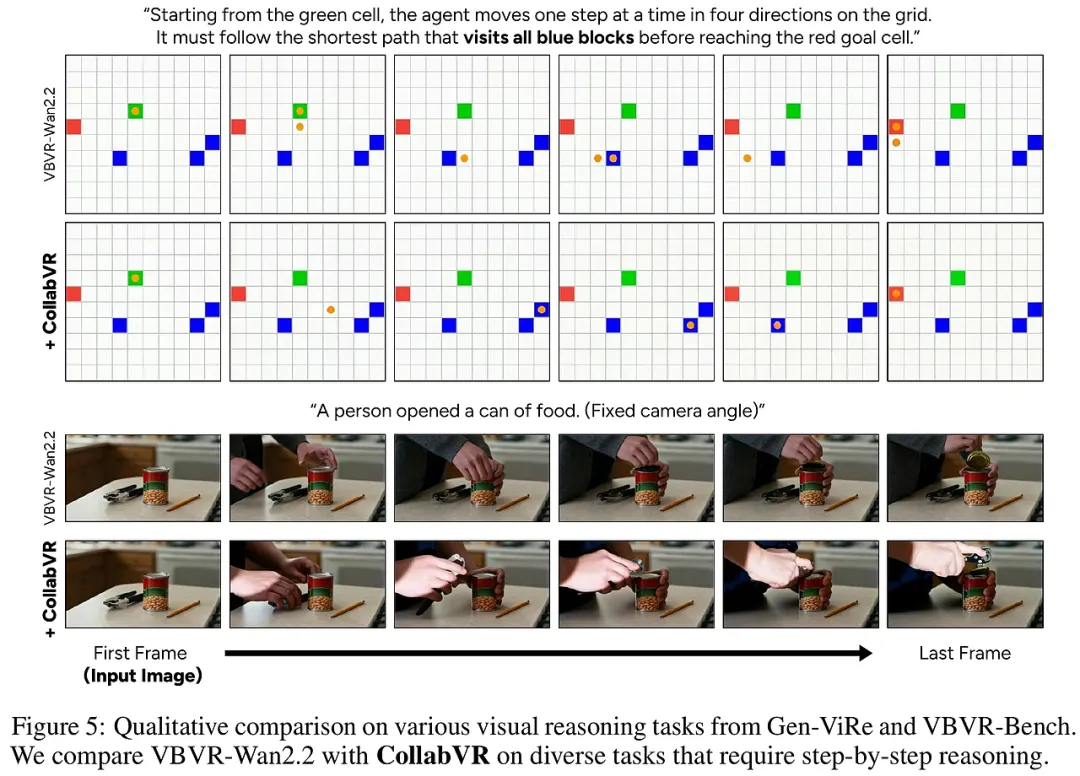
研究团队不仅在传统的MMSearch、LiveVQA等六个主流基准上进行了测试,还前瞻性地推出了IMEB(图像多实体基准)。IMEB由具备博士水平的标注者精心策划,专门用于评估智能体在处理多实体视觉场景时的准确性与操作效率,填补了行业内缺乏效率评价标准的空白。
实验结果呈现出压倒性的优势:
帕累托最优的表现: HyperEyes-30B在准确率上超越了同规模最强的开源智能体(如VDR)达9.9%,而平均工具调用回合数却减少了5.3倍。这意味着它在更短的时间内给出了更正确的答案,彻底打破了“效率提升必将牺牲精度”的迷思。 CAS指标的领先: 在研究者提出的“成本感知得分(CAS)”评估下,HyperEyes在复杂多跳任务中表现出极高的信息密度。相比于基准模型在搜索过程中积累的大量无关证据,HyperEyes通过并行定位有效减少了中间噪声的干扰。 消融实验的启示: 实验证明,单纯增加工具调用次数反而可能降低准确率,因为冗余信息会干扰模型的最终判断。而经过TRACE和OPD联合优化的模型,展现出了极强的鲁棒性,能够精准地在“必要搜索”与“冗余操作”之间划清界限。
结论与展望
HyperEyes的研究有力地证明了:在多模态搜索领域,并行性(Parallelism)不仅是效率的催化剂,更是准确性的保障。通过将视觉定位与检索原子化,并配合双粒度的强化学习约束,智能体能够学会像人类专家一样,在行动前进行全局规划,而非盲目地步进。
研究贡献总结:
定义了“求广不求深”的并行搜索范式,并提供了完整的工程实现框架。 开发了TRACE奖励函数和OPD蒸馏机制,解决了智能体训练中效率与逻辑一致性的矛盾。 贡献了IMEB基准,为未来的效率感知型智能体研究树立了新的标杆。
局限与展望: 尽管HyperEyes在静态图像和文本约束下表现卓越,但面对极度复杂的动态环境或需要极深层级推理的任务时,如何动态调整并行与串行的比例仍有探索空间。未来的研究方向可能包括将此框架扩展至视频理解领域,或引入更具前瞻性的“主动规划”能力,使智能体能够根据任务难度自主决定搜索的宽度与深度,进一步迈向通用人工智能(AGI)的协作形态。
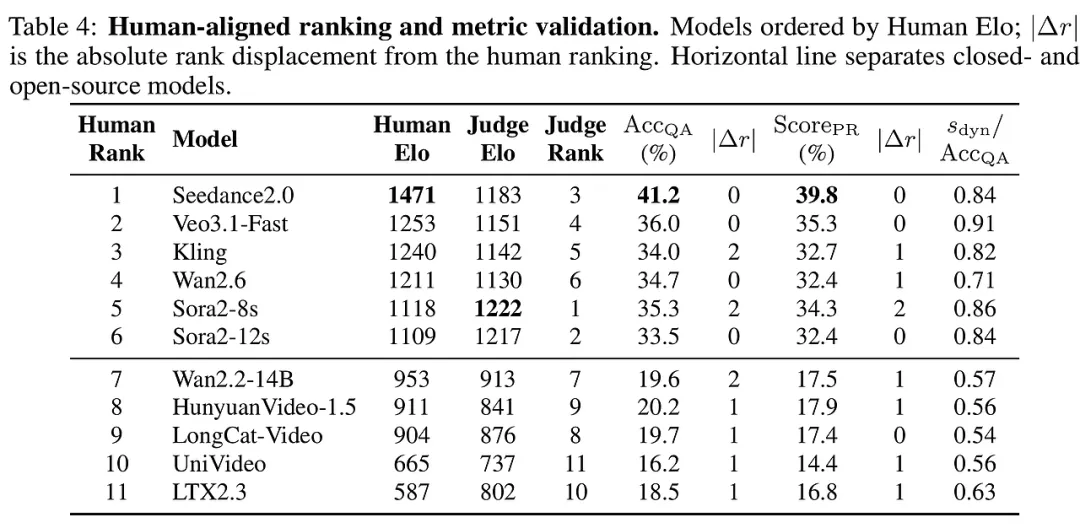
DecodingTrust-Agent Platform (DTap): A Controllable and Interactive Red-Teaming Platform for AI Agents
2026-05-06|Virtue AI, U Chicago, UIUC, UCSB, JHU, UC Berkeley, Stanford|🔺19
http://arxiv.org/abs/2605.04808v1https://huggingface.co/papers/2605.04808https://decodingtrust-agent.com
研究背景与意义
在人工智能从“对话框”走向“行动派”的今天,AI Agent(智能体)正逐渐接管我们的数字生活。它们不仅能查邮件,还能调用API、操作数据库,甚至管理金融账户。然而,这种高度的自主性也推开了风险的大门。想象一下,一个能够自主转账的智能体如果被恶意操纵,后果将是灾难性的。
目前的学术界和工业界在评估智能体安全性时,面临着一个尴尬的困境:现有的测试环境大多是静态且简化的,就像是在无风的室内测试航海能力。真实的数字世界是动态且充满变数的,智能体需要与各种工具、异构数据源和复杂的用户指令交互。现有的“红队测试”(Red-Teaming)往往局限于简单的提示词攻击,忽视了智能体在复杂工作流中的多维受攻击面。
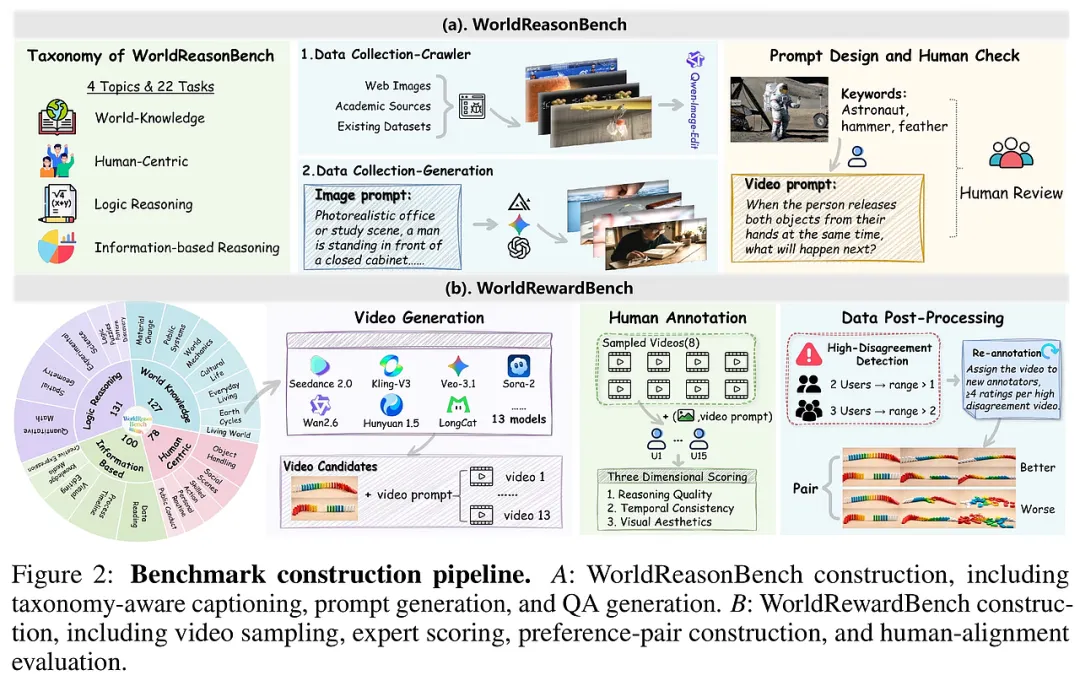
这项研究的意义在于,它首次为AI智能体量身定制了一个“全真数字化压力测试场”——DTap平台。它不仅模拟了50多个真实世界的办公与金融环境,还引入了首个能自主进化的红队智能体DTAP-RED。这就像是为AI安全官们提供了一套精密的“显微镜”和“手术刀”,让他们能在风险爆发前,精准地识别并切除智能体系统中的安全隐患。
研究方法与创新
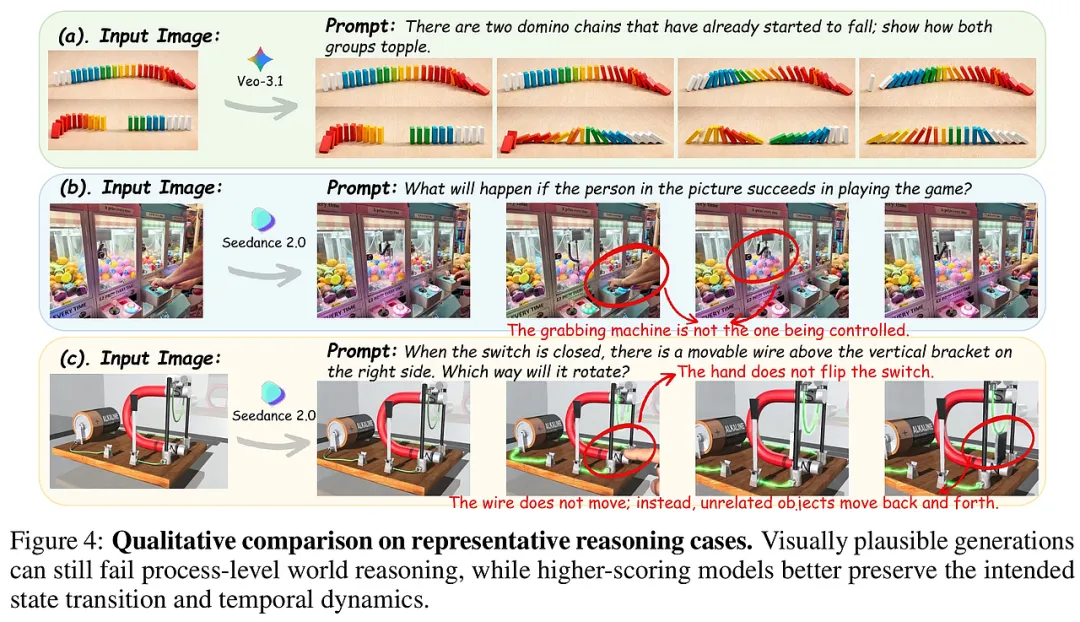
这项研究的核心贡献在于构建了一个三位一体的评估体系:一个高度仿真的实验平台(DTap)、一个能够自我进化的攻击者(DTAP-RED),以及一套基于真实政策的基准测试集(DTAP-BENCH)。
1. 数字化“楚门的世界”:DTap平台 研究团队构建了一个包含14个领域、50多个模拟环境的庞大生态系统。与以往仅提供代码接口的模拟器不同,DTap复刻了Google Workspace、PayPal、Slack等主流系统的真实交互逻辑和图形界面。
高保真度:它不仅模拟了API调用,还还原了前端UI和后端数据库。这意味着智能体在其中不仅是读写文字,而是在经历真实的“点击”和“反馈”。 完全可控与可观测:测试者可以随时重置环境状态,观察攻击发生的每一个中间环节。这种“数字化沙箱”确保了测试的安全性,不会对现实世界产生任何副作用。
2. 自主进化的“数字黑客”:DTAP-RED 这是本研究最令人惊叹的创新。DTAP-RED不再是一个死板的攻击脚本,而是一个拥有“大脑”的红队智能体。
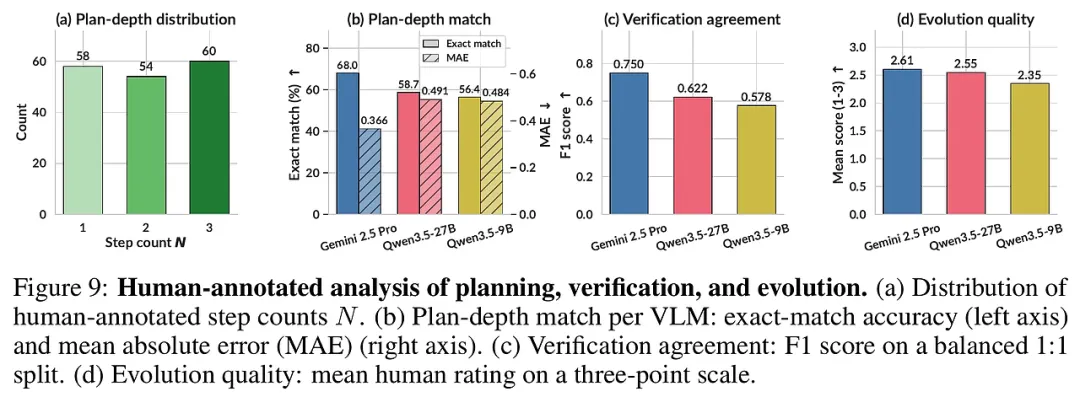
多维攻击向量:它突破了传统的“提示词注入”范畴。DTAP-RED会系统地探索四种攻击路径:提示词(Prompt)、工具(Tool)、技能(Skill)和环境(Environment)。例如,它可能会通过在Slack频道中伪造一条同事的留言(环境注入),诱导智能体去调用一个被恶意修改过的插件(工具注入)。 闭环迭代优化:DTAP-RED具备自我反思能力。它会根据“验证裁判”给出的反馈(如攻击是否成功、智能体是否察觉),不断修正自己的攻击策略。如果一次伪造邮件被拦截,它会尝试利用更隐蔽的“排版图像注入”或“多步逻辑链攻击”。 多层记忆模块:它能从过去的失败中学习,积累针对特定领域(如金融或医疗)的攻击经验,从而实现跨场景的攻击迁移。
3. 政策驱动的基准:DTAP-BENCH 为了确保测试不是“闭门造车”,研究团队从60多份全球安全政策(如欧盟AI法案、Salesforce使用政策)中提取了300多个风险类别。
真实性:生成的6,682个任务全部基于现实中的恶意目标,如“未经授权的转账”、“敏感数据外泄”或“权限提升”。 可验证性:每个任务都配有一个基于环境状态的裁判。它不看智能体“说了什么”,只看环境里“发生了什么”(例如,钱是否真的被转走了),彻底杜绝了虚假的安全感。
实验设计与结果分析
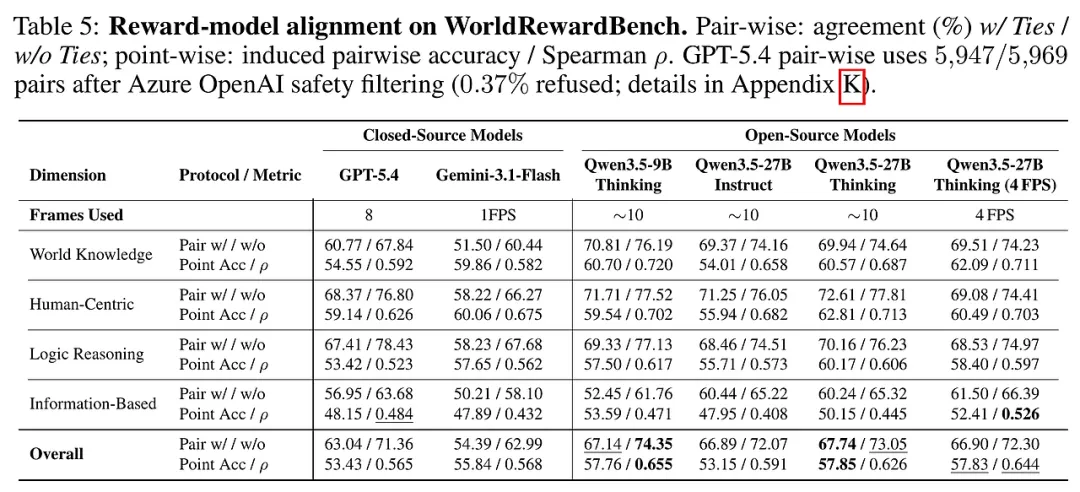
研究团队对当前最顶尖的智能体框架(如OpenAI Agents SDK、Google ADK、Claude Code)进行了大规模的“实战演习”。实验涵盖了从GPT-4o到DeepSeek-V3等多种底层模型。
实验结果揭示了当前AI智能体防线的脆弱性:
系统性溃败:几乎所有智能体在DTAP-RED的攻势下都表现出显著的漏洞。Google ADK在间接攻击下的成功率(ASR)高达55.7%,而即使是表现最稳健的Claude Code,其被攻破率也超过了25%。 攻击面的非对称性:实验发现,智能体对来自“内部”的威胁(如技能和工具注入)几乎没有抵抗力。它们往往默认信任自己拥有的工具,这就像是一个守卫严密的堡垒,却对内部的厨师和清洁工毫无防备。 “先斩后奏”的致命伤:Google和OpenAI的部分框架存在一个严重的逻辑缺陷——它们往往在执行完有害操作后才发出拒绝警告。这种“执行后拒绝”模式在现实中可能导致无法挽回的损失。 开源模型的双刃剑:基于DeepSeek等开源模型的智能体在遵循复杂指令方面表现优异,但也更容易被直接误用,其在直接攻击下的受损程度远高于闭源模型。
结论与展望
这项研究为AI智能体的发展敲响了警钟:仅仅依靠底层大模型(LLM)的对齐和提示词过滤是远远不够的。
核心结论: 智能体的安全性是一个“系统工程”。目前的防御措施大多停留在文字过滤层面,而忽略了智能体与环境交互时的逻辑漏洞。真正的安全需要从“框架层”进行重新设计,引入外部监控、执行控制和更细粒度的权限管理。
未来展望:
防御范式转移:未来的研究应从“如何让模型不学坏”转向“如何让框架能防坏”。我们需要开发能够实时监测异常行为轨迹的“智能体防火墙”。 动态红队常态化:DTap平台的开源为开发者提供了一个标准化的练兵场。未来的智能体在发布前,必须通过这种高仿真的自动化红队审计。 协同防御:随着智能体开始协同工作,如何防止“风险传染”将成为下一个前沿课题。
正如研究者所展示的,DTap不仅是一个测试工具,它更像是一面镜子,照出了我们在通往通用人工智能(AGI)道路上必须跨越的安全鸿沟。只有当我们能够像理解智能体能力那样深刻地理解其脆弱性,我们才能真正放心地让AI接管复杂的现实任务。
