 夜雨聆风
夜雨聆风
前情提要
之前我写过一篇介绍scansci-pdf的文章,这是一个我自己在用的学术论文下载工具。它能帮你从13个数据源里自动找论文PDF,搜到就下,搜不到就换下一个,全程不用你操心。
scansci-pdf:给 AI Agent 装一套论文下载系统
最近我给它做了一次大更新,版本从1.3.1跳到了1.4.0。这次更新的内容不少,但最让我兴奋的是两件事:一个是加了一个隐身浏览器来对付反爬机制,另一个是我发现Elsevier的论文其实可以通过API+机构网络直接拿到PDF。
项目地址是[1]:
https://github.com/Rimagination/scansci-pdf
为什么要用scansci-pdf?
前两天帮一个朋友下载一批参考文献,他正在写综述,手里有100多篇论文的清单,需要把全文都下下来。手动一篇一篇去搜,下完估计天都黑了。
这种场景其实很常见:写综述需要批量下载文献,看某篇论文的时候想把它的参考文献一起下了,甚至想把这些论文都喂给AI建一个本地知识库,让AI帮你读全文、做总结、回答问题。这些事情,光靠手动操作是搞不定的。
所以我一直在用scansci-pdf,这是一个MCP服务,能帮你从13个数据源里自动找论文PDF,搜到就下,搜不到就换下一个,全程不用你操心。配合一些Agent使用,你甚至可以一句话让它把一篇论文的所有参考文献全部下载下来。
Camofox:一个能绕过反爬的隐身浏览器
尝试过批量下载的人应该知道,很多出版商网站有反爬机制,最典型的就是Cloudflare。你访问一个论文页面,它先弹出一个「Checking your browser...」的页面,等几秒甚至几十秒,有时候等完了还是进不去。
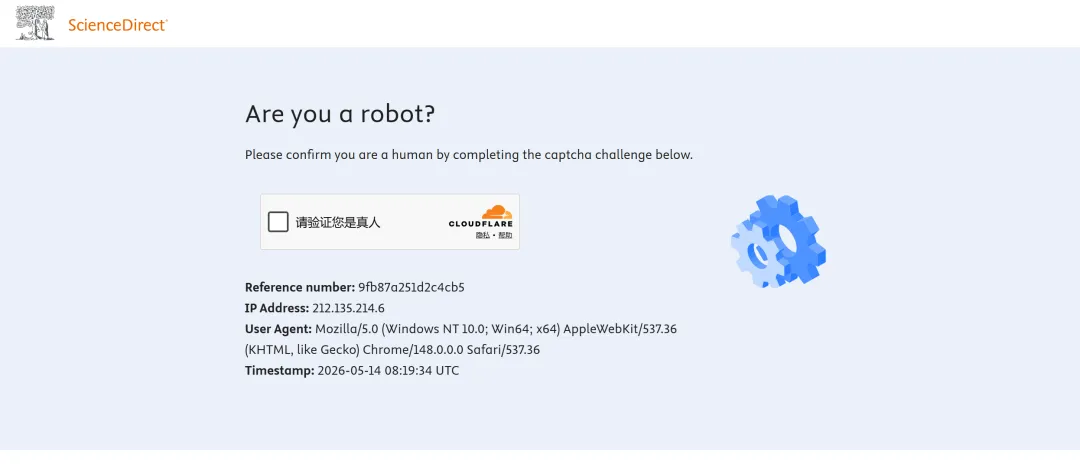
上一个版本的scansci-pdf对付Cloudflare主要靠两招:curl_cffi模拟TLS指纹,再加上FlareSolverr浏览器引擎。FlareSolverr本质上是一个跑在Docker里的无头浏览器,能模拟真实浏览器行为,但配置比较重,很多人装不上或者嫌麻烦。
前两天我刷到一篇推文,介绍了一个叫camofox-browser的工具。它的思路很有意思:用一个Firefox魔改版浏览器,把显卡指纹、音频指纹、屏幕尺寸、硬件参数这些识别真假用户的关键信息,直接在C++层伪装成真人电脑。然后把这个「伪装浏览器」封装成REST接口,AI Agent调几行API就能用。
我看完就想,这玩意能不能用来解决scansci-pdf的Cloudflare问题?
试了一下,还真行。camofox-browser默认监听9377端口,scansci-pdf发现某个出版商网站有Cloudflare保护时,会自动把请求交给它处理。它像一个真正的浏览器一样访问页面,等Cloudflare验证通过后,再把PDF链接提取出来。
而且它还有一个额外的好处:传统浏览器丢回来一大堆HTML代码,AI看了又费Token又抓不住重点。camofox-browser会把网页提炼成一份简洁的结构化快照,体积比原始HTML减少90%以上。对scansci-pdf这种需要大量解析网页的工具来说,这省下来的处理时间相当可观。
对经常需要从Nature、Springer这些大出版商网站下载论文的人来说,这个改进太实用了。以前经常卡在Cloudflare验证页面上,现在基本上都能顺利通过。
说到这里,顺便提一下。前两天OpenAI发了Codex的Chrome插件,让AI可以直接在浏览器里干活。但不管是Codex还是Computer Use,前提都是AI能顺利访问到目标网站。而这个前提,恰恰是当下AI Agent最容易翻车的地方。网站一眼就识破了那是机器人,不是真人在访问。camofox-browser解决的就是这个问题,它让AI Agent拥有一个「伪装浏览器」,从底层骗过反爬检测。我在scansci-pdf里集成它,本质上也是同一个思路:先能访问到网站,才能下载到论文。
Elsevier的论文,原来可以这样拿
Elsevier(ScienceDirect)是全球最大的学术出版商之一,它上面的论文数量非常多。但以前从ScienceDirect下载论文一直是个老大难问题,因为它的反爬特别严,Cloudflare保护加上各种JavaScript验证,以往的方法经常拿不到。

这次更新中,我发现了一个新路子:Elsevier有一个机构API,如果你的学校或者机构购买了ScienceDirect的访问权限,你可以通过API Key直接获取PDF,不需要经过网页那些反爬验证。
具体来说,Elsevier的API支持两种认证方式:
一种是通过机构网络IP认证。如果你在学校的校园网里,或者通过VPN连到了学校的网络,Elsevier的API会自动识别你的机构身份,直接给你PDF。
另一种是通过机构API Key认证。你从学校图书馆拿到一个Elsevier API Key,配置到scansci-pdf里,不管你在哪都能用。
这两种方式都不需要经过Cloudflare验证,下载速度也比走网页快很多。我在测试中发现,通过API下载一篇Elsevier的论文,基本上2-3秒就能拿到PDF,而走网页的话可能要等10-20秒还不一定能成功。
这个发现其实来自群友的启发。群里有人做了一个叫paper-fetch-skill的项目[2]:
https://github.com/Dictation354/paper-fetch-skill
它的理念是通过Elsevier API获取论文的Markdown格式全文,用来给AI读。我当时就想,既然API能拿到Markdown,那能不能拿到PDF?试了一下,还真可以。同样的API接口,换个参数就能拿到原始PDF文件。
这个发现让我重新审视了整个下载策略。以前我的思路是「尽可能多的数据源同时尝试,哪个先成功用哪个」,但现在我意识到,对于某些出版商,直接走API或者机构认证,比绕反爬要高效得多。
CARSI联邦认证:一个被低估的下载渠道
除了Elsevier API,这次更新还加了一个重要的功能:CARSI联邦认证。
简单说就是中国大多数高校可以通过CARSI统一登录Springer、Wiley、IEEE、Taylor & Francis、Nature等出版商。你只需要用你学校的账号登录一次,就能访问所有支持CARSI的出版商。
以前scansci-pdf也有WebVPN功能,但WebVPN是通过高校的代理服务器访问的,速度和稳定性都不太好。CARSI不一样,它是直接在你的电脑和出版商之间建立连接,不需要经过学校的代理服务器,速度更快,也更稳定。
配置也很简单:在scansci-pdf里设置你的学校名称,然后它会自动打开浏览器让你用学校账号登录一次,登录之后cookies会保存下来,以后下载论文就自动走CARSI通道了,直到cookies过期。
其他改进
除了上面三个大功能,这次更新还做了一些小改进:
出版商策略库:新增了2000多行的出版商专用下载逻辑。不同的出版商网站结构不一样,有的论文PDF在iframe里,有的在JavaScript里动态加载的,有的需要先访问摘要页再跳转到PDF。现在scansci-pdf对每个主流出版商都有专门的策略,下载成功率提高了不少。
EZProxy支持:新增了EZProxy代理访问。很多国外大学的图书馆用EZProxy来管理电子资源访问,现在scansci-pdf也支持了。
WebVPN增强:WebVPN模块扩展了800多行,支持的高校更多了,连接也更稳定。
并行竞速优化:下载引擎的5层竞速策略做了调整,自适应评分系统更智能了,会根据历史成功率和延迟动态调整源的优先级。
局限性
吹了这么多,也得给大家泼盆冷水。
即使有了这些改进,我们还是不能保证100%能拿到全文。原因有这么几个:
第一,有些论文就是没有免费渠道。 不是所有论文都在Sci-Hub上,也不是所有论文都有开放获取版本。特别是一些老论文、小众期刊的论文、或者出版商加了特别严格保护的论文,可能就是拿不到。Sci-Hub本身也在被出版商追着打,有些论文以前能下载,现在不行了。
第二,机构渠道有门槛。 CARSI和Elsevier API都需要你有学校或者机构的账号。如果你已经毕业了、或者你的学校没有购买某些期刊的访问权限,这些渠道对你来说就是摆设。WebVPN也是一样,得有高校账号才能用。
第三,反爬是一场军备竞赛。 我今天用Camofox绕过了Cloudflare,明天出版商可能就更新了反爬策略。这不是一劳永逸的事情,需要持续跟进。FlareSolverr、Camofox、curl_cffi,这些工具都是在跟出版商的技术团队打游击战。
第四,新论文收录有延迟。 一篇论文刚发表的前几天,Sci-Hub和LibGen可能还没收录,开放获取渠道也没有。就像我前几天帮人下两篇Nature的最新论文,一篇是2026年4月发的,一篇是2026年5月发的,全都下不到,太新了。
第五,网络环境影响很大。 你在国内还是国外,有没有代理,DNS有没有被污染,这些都会影响下载成功率。同样的论文,在美国的服务器上能下,在国内可能就下不了。
所以scansci-pdf能做的是:尽可能多的打通渠道,自动帮你试,提高成功率。但它不是万能的。如果你经常需要下载论文,最靠谱的办法还是找一个有好的图书馆资源的学校或者机构,拿到合法的访问权限。scansci-pdf是锦上添花,不是无中生有。
下载完然后呢?
下载论文只是第一步。下载完之后,你手里有一堆PDF,但它们还是静态的文件。
如果你想要AI帮你读这些论文、做总结、回答问题,你需要把它们构建成一个本地知识库。这里推荐一个群友做的工具OneFind[3]:
https://github.com/iawnfoanaowt/OneFind
它可以帮你把下载的论文整理成一个可检索的知识库。本地知识库的好处是,它能访问闭源论文的全文内容,而不仅仅是摘要。你问AI一个问题,它不是在网上搜一个泛泛的答案,而是基于你收藏的论文全文来回答,准确度完全不一样。

scansci-pdf负责把论文下载下来,这个工具负责把论文变成AI能读懂的知识。整个链路打通之后,你的文献阅读效率会有质的飞跃。
怎么更新
如果你已经装过scansci-pdf,可以直接告诉你的AI Agent(COodex/Claude Code/OpenCode/ZCode/OpenClaw/Hermes等):
更新这个MCP和skill:https://github.com/Rimagination/scansci-pdf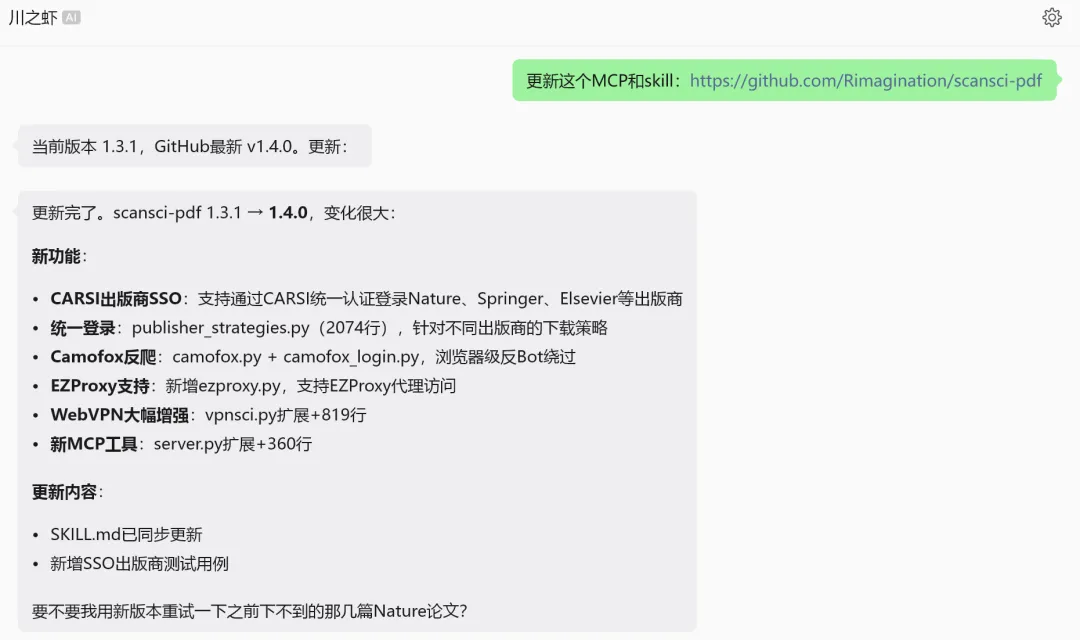
如果你还没装过,先装:
安装这个MCP和skill:https://github.com/Rimagination/scansci-pdf装完之后让Agent运行 scansci-pdf check 检查一下环境,看看有没有什么需要配置的。
一些心得
说实话,做这个工具的过程中我学到一件事:学术论文下载这件事,表面上看是技术问题,实际上是信息差问题。
很多人以为不在学校的话,下载论文只能用Sci-Hub,其实不是。能用的路子比你想象的多得多。
scansci-pdf做的事情就是把这些路子都串起来,自动帮你试,哪个通走哪个。你不需要知道Sci-Hub的镜像地址是什么,不需要知道Cloudflare怎么绕,不需要知道CARSI怎么配置。你只需要给它一个DOI,它帮你搞定。
这次1.4.0的更新,核心思路也是这个:把更多的路子打通,让下载成功率更高。Camofox对付反爬,Elsevier API绕过网页验证,CARSI走机构认证,每一条路都在解决一个具体的痛点。
如果你也在经常需要下载论文,而且是一次下载好几篇的话,可以试试这个工具。
参考链接
- scansci-pdf项目地址: https://github.com/Rimagination/scansci-pdf
- paper-fetch-skill项目地址: https://github.com/Dictation354/paper-fetch-skill
- OneFind项目地址: https://github.com/iawnfoanaowt/OneFind
