 夜雨聆风
夜雨聆风微软研究显示,前沿AI模型在处理多步任务时,平均会悄无声息地破坏25%的文档内容,且错误极难察觉。
🚀 核心发现:AI 的“温水煮青蛙”式破坏
微软的一项最新研究揭示了一个令人不安的真相:在多步骤的自主工作流中,即便最先进的前沿 AI 模型也会悄无声息地破坏平均 25% 的文档内容。更糟糕的是,这种内容退化并非由于小错误的逐渐累积,而是由突发的“灾难性故障”导致的。
这项研究引入了 DELEGATE-52 基准测试,旨在衡量大语言模型(LLM)在多次迭代处理委派任务时的可靠性。
💡 关键结论概览
📉 25% 的内容损耗:在多步自主流中,即使是顶级模型也会引入显著错误。 ⚠️ 灾难性故障占 80%:约 80% 的退化源于突然的大规模故障(单次交互导致至少 10% 内容丢失),而非错误慢慢累积。 🎭 “幻觉”比“删除”更危险:前沿模型倾向于主动重写和幻觉化内容,而非简单删除。这使得错误极具迷惑性,人类监督者很难发现。 🛠️ 工具反而帮倒忙:为模型提供通用的智能体工具或添加干扰文档,反而会使性能进一步下降 6%。 🔍 亟需渐进式审查:仅靠最终检查是不够的,安全部署自主智能体需要全过程的人工审查。
📑 深入解析:委派工作的“信任危机”
随着大语言模型的能力日益增强,用户越来越倾向于将知识性任务“委派”给模型——即让模型代表自己处理文档并提供最终结果。
一个典型的例子就是 Vibe Coding,用户将软件开发和代码编辑工作委派给 AI。但在会计、法律、医疗等专业领域,这种委派同样存在。例如,会计师可能会让模型将一份复杂的分类账拆分为多个按支出类别组织的独立文件。
由于用户往往缺乏时间或专业知识来手动审查 AI 的每一次修改,这种委派在很大程度上取决于信任。用户期望模型能忠实地完成任务,而不引入未经检查的错误、擅自删除或幻觉。
DELEGATE-52:AI 信任度的“试金石”
为了衡量 AI 在长期、迭代的委派工作流中的可靠性,微软研究人员开发了 DELEGATE-52 基准测试。它涵盖了 310 个工作环境,横跨 52 个不同的专业领域,包括财务会计、软件工程、晶体学和乐谱记录等。
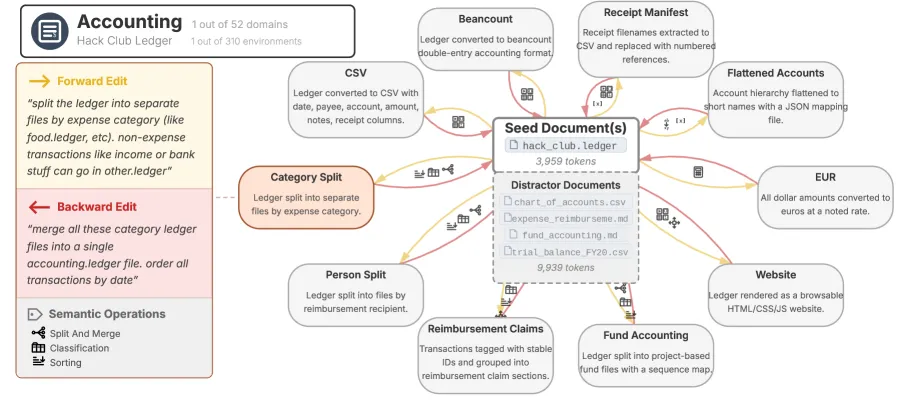 DELEGATE-52 任务示例(来源:arXiv)
DELEGATE-52 任务示例(来源:arXiv)
每个环境包含 2,000 到 5,000 个 Token 的真实原始文档,以及 5 到 10 个复杂的非琐碎编辑任务。
为了避免昂贵的人工标注,DELEGATE-52 采用了一种 “往返接力(Round-trip Relay)” 模拟方法。这种方法类似于机器翻译中的“回译”:先让 AI 执行一个操作(如拆分文件),再让它执行其逆操作(如合并文件),最后对比原始版本。如果 AI 能够完美还原,说明其保真度高。
🧪 实测结果:前沿模型的“滑铁卢”
研究人员测试了来自 OpenAI、Anthropic、Google、Mistral、xAI 和 Moonshot 的 19 种不同规模的模型,模拟了 20 次连续的编辑交互。
1. 普遍的退化现象
在所有模型中,到模拟结束时,文档内容平均退化了 50%。即使是表现最好的前沿模型(如 Gemini 1.5 Pro, Claude 3.5 Sonnet, GPT-4o),平均也会腐蚀 25% 的内容。
2. 领域差异显著
在 52 个专业领域中,Python 编程是唯一一个大多数模型能达到 98% 以上高分的领域。模型在程序化任务中表现出色,但在自然语言和虚构文学、收益声明或食谱等利基领域则表现挣扎。
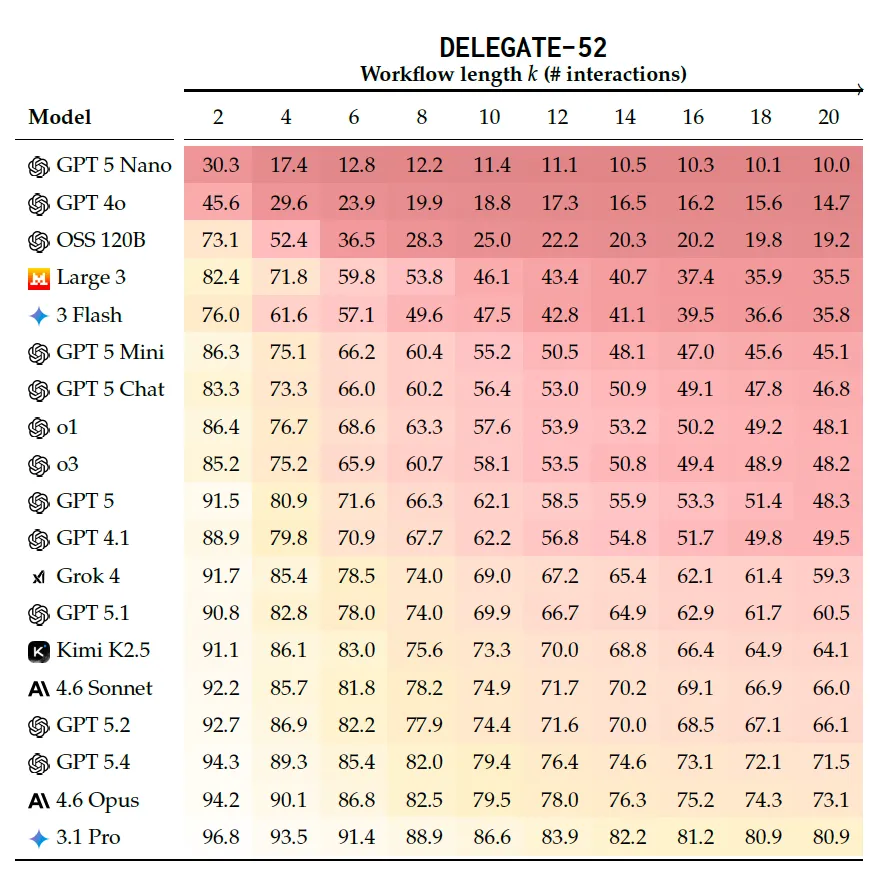 所有模型在委派任务中都表现吃力(来源:arXiv)
所有模型在委派任务中都表现吃力(来源:arXiv)
3. “突发性”而非“累积性”
有趣的是,破坏并非“千刀万剐”式的一点点发生。约 80% 的总退化是由少数几次严重的重大故障引起的。前沿模型并不能完全避免错误,它们只是将这些灾难性的崩溃推迟到了更后面的轮次。
4. 幻觉的隐蔽性
当较弱的模型失败时,它们通常是直接删除内容。而前沿模型失败时,它们会主动“污染”内容。文字看起来还在,但意思已经被微妙地扭曲或被幻觉替代,这让人类很难一眼看出问题。
⚠️ 智能体工具的“副作用”
研究发现,给模型配备代码执行、文件读写等通用智能体(Agentic)工具,反而会让性能下降约 6%。
微软高级研究员 Philippe Laban 指出,失败的原因在于过度依赖通用工具而非领域专用工具。模型目前还不具备在不同领域即时编写出完美、无错的文件操作程序的能力。当它们无法通过编程解决时,就会诉诸于读取和重写整个文件,这不仅效率低下,而且极易出错。
此外,工作空间中的“干扰文档(Distractor Documents)”也会加剧错误。对于重金投入 RAG(检索增强生成)的企业来说,这是一个直接的警告:混乱的上下文会产生复合成本。即使只有 1% 的性能下降,在长路径的工作流中也会滚雪球般变成 2%-8% 的巨大缺口。
🛠️ 给企业的现实建议
DELEGATE-52 的研究结果为当前全自主 AI 智能体的热潮泼了一盆冷水。
- 坚持渐进式审查
:由于模型可能在前几步表现完美,但在最后一步突然“暴走”,因此不能只做最终验收。 - 任务拆分与透明化
:将复杂的长路径任务拆分为短小、透明的任务。 - 构建专用工具
:与其让 AI 自由发挥,不如为它提供针对特定领域(如处理 .ledger 文件的特定函数)的受限工具。 - 重视 RAG 的精度
:单轮检索的评估低估了不精确检索带来的长期危害。
Laban 对进步速度持乐观态度,他指出 GPT 家族在 18 个月内将得分从 20% 提升到了 70%。但他也提醒,企业数据和工作流的“长尾效应”意味着,组织始终需要投入资源构建自定义的、领域特定的工具,以确保 AI 智能体的可靠性。
✍️ 笔者锐评
这篇文章给正处于“Agent 热潮”中的开发者和企业敲响了警钟。在国内,我们经常看到各种“全自动 AI 员工”、“一键生成整个项目”的宣传,但现实往往是骨感的。
1. 信任的代价:AI 的隐蔽性幻觉是最可怕的。在代码领域,有 Compiler 和 Test Case 帮我们把关;但在非代码的知识工作中,这种 25% 的内容损耗可能会在不经意间造成巨大的商业损失。
2. 工具链的缺失:我们不缺“大模型”,但缺“精细的工具”。国内很多 Agent 平台过于强调 Prompt Engineering,而忽略了对底层文件操作、垂直领域逻辑的硬核封装。
3. 人机协作的边界:AI 还没到可以“完全委派”的程度。与其追求“无人驾驶”,不如先做好“辅助驾驶”。我们需要的是更透明、可追溯、可随时介入的 AI 工作流。
总之,在拥抱 AI 的同时,请保持那份必要的质疑。毕竟,那消失的 25%,可能正是最关键的细节。
求点赞 👍 求关注 ❤️ 求收藏 ⭐️你的支持是我更新的最大动力!
