 夜雨聆风
夜雨聆风
先说我的真实感受
上周我在用 Claude Code 重构一个遗留 API,项目里有个历史决策让我纠结了很久——之前为什么选 jose 而不是 jsonwebtoken?Edge 浏览器的兼容性问题?还是单纯图轻量?我翻了好几个 commit 记录才找到答案。
如果那时候有 agentmemory,这个时间就省了。
这不是在吹它——我的意思是,这个问题确实存在,而且每个天天用 AI 编程的人多少都碰到过。agentmemory 做的事很简单:让 AI 记住它做了什么,以及为什么这么做。 听起来理所当然,但做起来其实挺难的。
这个项目解决什么问题
所有主流 AI 编程工具(Claude Code、Cursor、Codex 等)有一个共同的致命缺陷:会话结束,一切归零。
你跟 Claude Code 花 20 分钟对齐了项目上下文,下次新建会话,它完全不记得你们聊过什么。技术栈选了啥、哪个文件动过、为什么排除某个方案——全丢了。然后你又要花 5-10 分钟重新解释一遍。
agentmemory 的核心思路是:做一个后台服务,自动捕获每一次工具调用,把它们压缩成结构化记忆,等下次会话开始时自动注入上下文。 整个过程不需要你手动操作任何东西。
Session 1:
"给 API 加 auth"
→ Claude Code 写代码、跑测试、修 bug
→ agentmemory 后台静默捕获每个工具调用
→ 会话结束 → 压缩为结构化记忆
Session 2:
"现在加限流"
→ Claude Code 已知:auth 用了 JWT 中间件,
测试覆盖了 12 个 case,选了 jose 而非 jsonwebtoken(Edge 兼容性)
→ 直接开始干活,不需要重复解释这个项目 2026 年 2 月 25 日创建,到今天(5月14日)刚好 11 周,已经积累了 7,657 Stars、34 个 release——这个速度确实有点疯狂。
核心技术架构
记忆四层架构
这套系统借鉴了人类大脑的记忆巩固机制,分了四个层次:
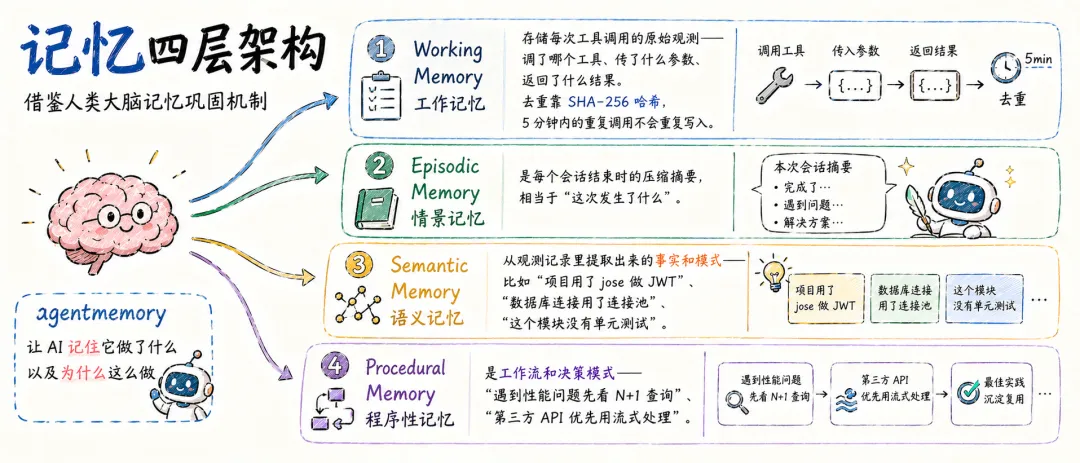
Working Memory(工作记忆) 存储每次工具调用的原始观测——调了哪个工具、传了什么参数、返回了什么结果。去重靠 SHA-256 哈希,5 分钟内的重复调用不会重复写入。
Episodic Memory(情景记忆) 是每个会话结束时的压缩摘要,相当于"这次发生了什么"。
Semantic Memory(语义记忆) 从观测记录里提取出来的事实和模式——比如"项目用了 jose 做 JWT"、"数据库连接用了连接池"、"这个模块没有单元测试"。
Procedural Memory(程序性记忆) 是工作流和决策模式——"遇到性能问题先看 N+1 查询"、"第三方 API 优先用流式处理"。
有意思的是,这套系统还引入了艾宾浩斯遗忘曲线——频繁访问的记忆会被强化,长期不用的记忆会自动衰减或被驱逐出场。如果你问了一个之前存过的上下文,系统会悄悄给它加权重,下次更容易被召回。
三种检索

查记忆的时候不是单纯靠向量搜索,而是三种方式同时跑:
BM25 负责关键词匹配(始终启用),向量搜索负责语义相似度(需要配置 embedding provider),知识图谱负责实体关系推理(比如问"上次修那个 API 问题用了什么方案",图谱能推理出相关的上下文)。
三种结果通过 Reciprocal Rank Fusion 算法融合排序,每轮最多返回 3 条,避免上下文溢出。
12 个自动 Hook
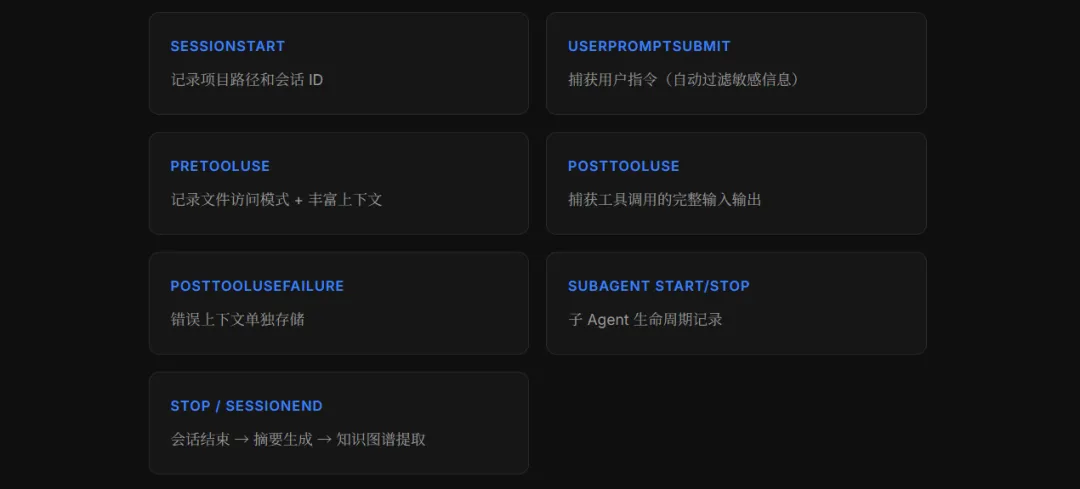
对比一下竞品 mem0 需要手动调 add() 接口,agentmemory 在 Agent 的整个生命周期里埋了 12 个钩子:
SessionStart 记录项目路径和会话 ID,UserPromptSubmit 捕获用户指令(自动过滤敏感信息),PreToolUse 记录文件访问模式,PostToolUse 捕获工具调用的完整上下文,Stop 和 SessionEnd 触发会话摘要生成……整个过程对用户完全透明,不需要改 prompt、不需要手动触发,装上就能用。
MCP Server:51 个工具开箱即用
项目自带一套完整的 MCP Server,分 Core(8 个始终可用)和 Extended(开启全部 51 个)两档。
核心工具覆盖检索(memory_smart_search、memory_recall、memory_profile)、写入(memory_save、memory_compress_file)、管理(memory_sessions、memory_export、memory_import)、图谱查询(memory_relations、memory_graph_query)、多 Agent 协作(排他锁 memory_lease、消息传递 memory_signal_send)。
另外还有 4 个斜杠命令:/recall(语义召回)、/remember(主动存入)、/session-history(查看会话历史)、/forget(主动遗忘)。
零外部依赖
这是我觉得它最有诚意的一点。
运行时依赖 iii-engine(一个轻量级 KV 状态引擎),存储用 SQLite,向量嵌入可以选本地免费的 all-MiniLM-L6-v2,也可以接 OpenAI/Gemini/Voyage/Cohere 的付费 API。
不需要 Postgres、不需要 Qdrant、不需要 Redis、不需要 Docker——装完直接跑。实测 Windows 上用 PowerShell 安装也就几分钟的事。
性能数据
项目在 LongMemEval-S 基准测试上跑出了 R@5(Recall@5)95.2% 的成绩。作为参考:
- mem0 同期基准为 68.5%
- Letta/MemGPT 为 83.2%
95.2% 这个数字确实很漂亮,但我得提醒一句:基准测试是项目方自己跑的,目前还没看到第三方独立测评机构复现的数据,所以这个数字看看就好。
Token 消耗方面,默认配置每会话约 1,900 tokens(相比全量注入节省约 92%)。如果用本地 embedding 模型做压缩,年均成本大约 $10;接 API embedding 的话按实际用量计费。
安装体验
最快上手(30秒)
# Terminal 1:启动服务器
npx @agentmemory/agentmemory
# Terminal 2:注入示例数据并演示搜索
npx @agentmemory/agentmemory demo
# 浏览器打开实时查看器
open http://localhost:3113demo 命令会种子 3 个真实会话(JWT auth 实现、N+1 查询修复、rate limiting 添加),然后演示语义搜索——你搜"database performance optimization",它能找到"N+1 query fix",纯 BM25 是做不到这点的。
实时查看器 (:3113) 挺有意思,能看到会话流、记忆注入记录、搜索结果——调试的时候很实用。
Claude Code 集成
Install agentmemory: run `npx @agentmemory/agentmemory` in a separate terminal,
then run `/plugin marketplace add rohitg00/agentmemory`
and `/plugin install agentmemory`插件注册会自动完成 12 个 hook、4 个斜杠命令、以及通过 .mcp.json 接入 51 个 MCP 工具。目前支持的 Agent 包括 Claude Code、Cursor、Cline、Roo Code、Windsurf、OpenClaw、Codex CLI、OpenCode、Kilo Code 等 32+ 个,而且支持 MCP 的新 Agent 可以直接接入,不需要等待项目方适配。
其他配置项
# 用中文分词器(需要额外安装)
npm install @node-rs/jieba
# 开启完整工具集
export AGENTMEMORY_TOOLS=all
# 指定 embedding provider
export AGENTMEMORY_EMBEDDING_PROVIDER=openai
export OPENAI_API_KEY=sk-...和同类项目的真实对比
这块我多说几句,因为今天 GitHub Trending 上有几个类似定位的项目一起在涨。
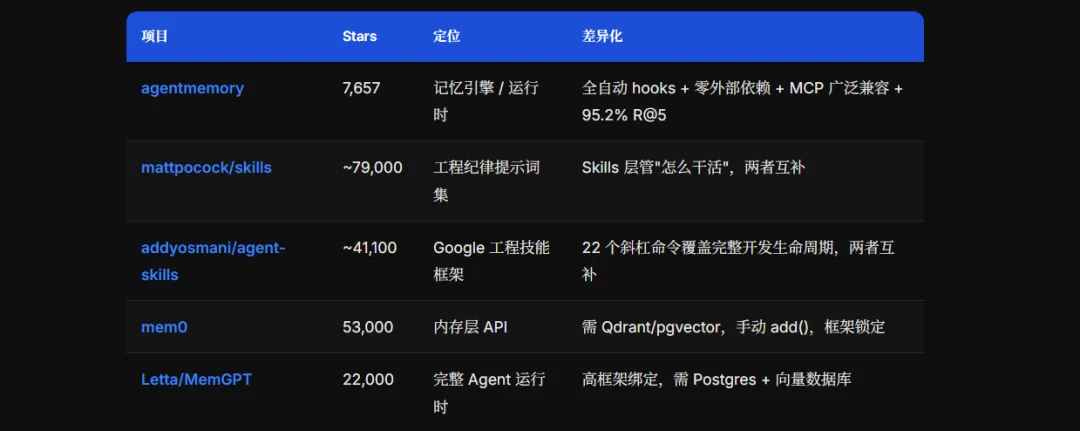
vs mattpocock/skills(已评测,2026-05-13)
mattpocock/skills 做的是"怎么干活"——TDD 流程、极简沟通(caveman 模式)、需求拷问(grill-me)、六阶段调试。它的本质是一套工程纪律的提示词模板,装到 Claude Code 里让 AI 遵守规则。
agentmemory 做的是"记住什么"——跨会话的上下文持久化,不管你用什么规范干活,它负责让你下次不用重复解释。
这两个不是竞争关系,是互补关系。skills 约束 AI 的行为方式,agentmemory 负责上下文连续性。一起用效果更好:skills 管工程纪律,agentmemory 管项目记忆。
vs addyosmani/agent-skills(已评测,2026-05-08)
addyosmani/agent-skills 是 Google 工程师 Addy Osmani 把二十年工程实践编码成 22 个斜杠命令,覆盖从 PRD 到发布的完整生命周期。anti-rationalization 机制很有意思——它预置了 AI 常用来跳步的借口和反驳话术,让 AI 像老工程师一样拽住你。
同样和 agentmemory 不冲突。agent-skills 定义工作流规范,agentmemory 提供跨会话上下文基础。
vs mem0 / Letta
这两个是更直接的竞品。
mem0(53K Stars)是内存层的 API 服务,需要 Qdrant 或 pgvector 做向量存储,手动调 add() 接口,没有自动 hooks。
Letta/MemGPT(22K Stars)是完整的 Agent 运行时,框架绑定较高,需要用 Postgres + 向量数据库。
agentmemory 和它们的核心差异:全自动捕获 + 零外部依赖 + MCP 广泛兼容 + 更高的基准测试分数。但这俩项目更成熟、issue 数更少、生态更完整——选哪个取决于你的具体需求。
适合谁用
如果你每天用 Claude Code/Cursor 超过 2 小时、项目代码库超过 1 万行、经常在多个会话里推进同一个项目——agentmemory 值得一试。它解决的是真实痛点,安装成本很低(npx 一条命令),不需要任何外部服务。
如果你的项目代码主要是中文注释、或者你在找一个生产就绪的企业级记忆系统——目前阶段可能还要等等,或者先在非关键项目上试水。
综合评分
| 维度 | 评分 | 说明 |
| 痛点定位 | 9.0 | 真正戳中了 AI 编程的上下文丢失问题 |
| 技术实现 | 8.5 | 四层记忆+三流检索架构完整,SQLite 零依赖很加分 |
| 开发者体验 | 8.0 | 安装简单,demo 体验直观,CJK 支持是短板 |
| 性能数据 | 7.5 | 基准数字好看但缺第三方验证,保守看待 |
| 社区生态 | 7.5 | 增长极快,但项目年轻,单人维护有风险 |
| 竞品差异化 | 9.0 | 全自动 hooks + 零依赖 + MCP 广泛兼容,护城河清晰 |
| 文档完整性 | 7.0 | 核心文档清晰,但进阶配置(embedding、CJK、多 Agent)文档不足 |
| 综合 | 8.4 / 10 | |
一句话总结
agentmemory 解决了 AI 编程工具最烦人的问题之一:每次新建会话都要重新解释上下文。它用 12 个自动 hooks + 四层记忆巩固 + 三流检索做到了"无感知的上下文连续性",零外部依赖,MCP 协议广泛兼容。
项目很年轻(11 周),增长很快(7,657 Stars),但也存在单人维护、CJK 支持弱、基准数据缺第三方验证等现实问题。适合个人开发者或小型团队在非关键项目上试验,如果是企业级部署,建议持续关注 Roadmap(v1.0 计划 Q1 2027)和 iii-engine 的社区健康度。
License: Apache-2.0(可免费商用)
官网: https://github.com/rohitg00/agentmemory
相关评测: [mattpocock/skills 评测(2026-05-13)](/) · [addyosmani/agent-skills 评测(2026-05-08)](/)
