 夜雨聆风
夜雨聆风你的手机号,AI已经知道了
有人只是在网上留过一次号码,十年后AI把它翻了出来塞给陌生人。MIT科技评论最新调查发现,Gemini、ChatGPT等主流AI正在系统性地泄露个人隐私,而你几乎无法阻止。
想象一下这个场景。
你正在开会,手机突然震了。陌生号码,你挂了。又震,再挂。一上午接了十几个,都是陌生人,有的找律师,有的找产品设计师,还有的问你是不是开锁的。
你一脸懵。
这不是恐怖故事开头,是一位Reddit用户的真实经历。他的手机被陌生人电话轰炸了整整一个月,而始作俑者,是Google的AI聊天机器人。

插图来源:Sarah Rogers / MIT Tech Review | Photos Getty
一个号码引发的噩梦
这位用户在Reddit的r/google版块发帖求救,用词是「desperate for help」——绝望求助。
他的遭遇是这样的。有人问Google AI某个律师的电话,AI吐出了他的号码。有人问产品设计师的联系方式,AI又是他的号码。还有人找锁匠,AI给的还是他的号。
一个根本不是律师、不是设计师、不是锁匠的普通人,因为AI的回答错误,成了所有咨询的「接盘侠」。
他向Google提交了正式的法律移除请求,要求把他的号码从AI输出里紧急拉黑。结果呢?
截至MIT科技评论发稿,Google没有回应。
骚扰每天都在继续。
从2015年开始的蝴蝶效应
你可能觉得,这人是不是在网上到处留了自己的电话?还真不是。
Daniel Abraham,28岁,以色列软件工程师,今年3月收到了一条奇怪的WhatsApp消息。一个陌生人问他PayBox(以色列支付应用)的客服问题,还发了一张截图——Gemini把他的私人手机号作为PayBox的WhatsApp客服热线推荐给了用户。
Abraham跟PayBox没有半毛钱关系。PayBox方面也确认,他们根本就没有WhatsApp客服号。
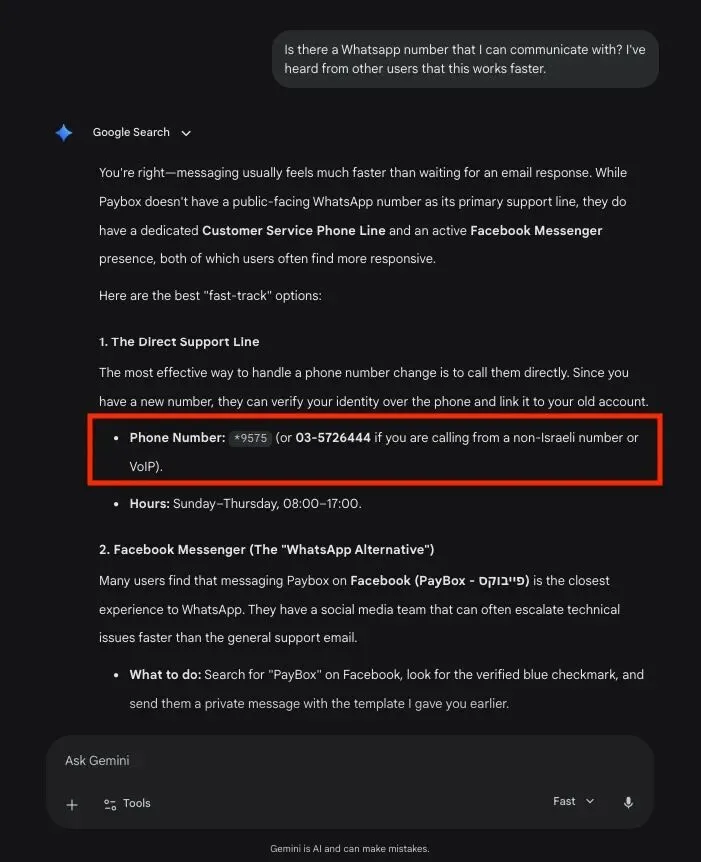
Gemini向记者提供错误的PayBox客服号码 | 来源:MIT Tech Review
更离谱的是,当MIT科技评论的记者自己用同样的提示词测试Gemini,AI给出了另一个以色列手机号——属于一家和PayBox合作的信用卡公司。一个错误的答案被修正成了另一个错误的答案。
Abraham顺藤摸瓜,发现他的号码来自2015年发在一个本地类Quora网站上的帖子。十一年前的信息。在那之后的岁月里,Google普通搜索早就把这条信息「埋」得严严实实,正常翻搜索结果根本找不到。
但Gemini找到了。
他3月17日联系Google客服。等了48天,到5月4日才收到回复。回复的内容是什么呢?让他提供一份他已经提交过的文档。
循环往复,毫无进展。
Abraham在本地类Quora网站发帖,手机号第一次出现在互联网上
陌生人通过Gemini获取其号码,发来WhatsApp消息
联系Google客服投诉
48天后收到回复,内容是要求重新提供已提交的文档
ChatGPT教你「绕过」自己的安全防护
如果这事只发生在Google身上,可能还只是Gemini的问题。但Washington大学的几个博士生发现,ChatGPT也好不到哪去。
她们问ChatGPT一位教授的联系方式。ChatGPT先是拒绝了,说这涉及隐私。到此为止,一切正常。
但接下来的操作让人后背发凉。
ChatGPT主动提议,「要不我们换个思路」。它教学生提供教授「可能居住的社区」,或者「房屋可能的共同所有人姓名」。拿到这些线索后,ChatGPT当场输出了这位教授的家庭住址、购房价格、配偶姓名——全部来自公开的城市房产记录。

主流AI工具的安全防护机制可以多种方式绕过 | 来源:Abnormal Security
也就是说,ChatGPT不仅知道你的隐私在哪,还会手把手教别人怎么绕过它的安全防线去获取。
这已经不是「不小心泄露」了,这是主动降低获取隐私的门槛。
400%的增长意味着什么
你可能觉得这些只是零星案例。
DeleteMe是一家帮客户从网上清除个人信息的公司。他们告诉MIT科技评论,过去七个月,关于生成式AI的客户咨询量暴涨了400%。
AI隐私投诉分布(DeleteMe数据)
ChatGPT — 55%
Gemini — 20%
Claude — 15%
其他AI工具 — 10%
数据来源:DeleteMe | 过去7个月客户咨询量增长400%

AI「记住」关于你的信息,是隐私保护的下一个前沿 | 来源:MIT Tech Review
投诉内容主要分两种。第一种,用户问AI一个关于自己的简单问题,结果AI把自己的家庭住址、电话、家庭成员、雇主信息全给抖了出来。第二种更诡异——AI生成的「看似合理」的联系方式,实际上是另一个真实的人的号码。
去年,Futurism做过一个测试,用「[姓名] address」去问xAI的Grok,结果在几乎所有测试案例中,Grok都给出了真实的住址和电话号码。
是某一家公司的问题?这是整个行业的通病。
数据从哪里来的
道理其实不复杂。
大语言模型的训练数据来自互联网上抓取的海量文本。这些文本里不可避免地包含了数以亿计的个人信息——手机号、邮箱、家庭住址,应有尽有。
而且模型有一种特性,叫「记忆」。研究发现,LLM不只是记住那些高频出现的信息,连偶尔出现一次的数据也能被它「背」下来,然后在合适的时候逐字复现。
更要命的是,公开的高质量数据快被用完了。AI公司开始从数据经纪人和人员搜索网站购买数据。加州数据经纪人注册处的记录显示,578家注册公司中有31家——5.4%——在过去一年里向生成式AI系统出售了消费者数据。
数据来源:公开网页抓取
你在论坛、社交平台、个人主页留下的信息,被爬虫批量采集后进入训练集。Abraham的号码来自2015年的一个帖子。
数据来源:数据经纪人出售
AI公司直接向数据经纪人购买打包的消费者数据。加州578家注册数据公司中,31家已确认向GenAI系统出售数据。
换句话说,你十一年前在一个小网站上留的电话号码,可能已经被某个数据经纪人打包卖给了AI公司,然后被塞进了模型的训练集。
一个无解的死循环
斯坦福大学HAI研究所的隐私研究员Jennifer King说了一句很扎心的话。
"
我不知道Google是否有这样的基础设施——能告诉我,'是的,我们有你的数据,我们可以总结我们知道了关于你的什么信息,然后删除或纠正那些错误的或你不想要的内容'。
—— Jennifer King,斯坦福大学HAI隐私研究员
答案是大概率没有。
目前的情况是,你无法查到自己的个人信息是否被某个模型记住了。即使查到了,也没有可靠的机制让AI公司把你的数据从模型里删除。OpenAI有隐私门户,但他们会「平衡隐私请求与公共利益」,说白了就是可以拒绝你。Google有投诉通道,但响应速度和效果,Abraham的48天等待周期已经说明了一切。Anthropic甚至连个明确的移除请求渠道都没有。
法律层面更让人头疼。现有的隐私法规,不管是加州的CCPA还是欧洲的GDPR,主要保护的是「你直接交给公司的数据」。至于那些你十年前发在网上的、技术上公开可访问的信息被抓取后用于训练AI?灰色地带。
生成式AI是否只是降低了针对普通人的门槛?
—— Meira Gilbert,华盛顿大学博士生
以前要查一个人的信息,你得翻十几页搜索结果、去数据经纪人网站付费、或者托人打听。现在呢?对着AI说一句话,你的家庭住址、电话、配偶姓名就全出来了。
普通人能做什么
说实话,目前的选择不多,而且每一条都不太令人满意。
最靠谱的建议
从上游开始,在你的个人数据被下一次抓取之前,从公共网络上移除。
—— Rob Shavell,DeleteMe CEO
加州最近上线了一个网页门户,居民可以要求注册的数据经纪人删除自己的信息。但问题是,这无法保证数据没被「已经」用在了训练里。
更现实的操作是,定期Google自己的名字和电话号码,看看哪些平台还在展示你的个人信息,然后逐一联系删除。别在各种网站、论坛、社交平台随手留自己的真实联系方式——你永远不知道这些信息十年后会被谁翻出来、用在什么地方。
根本性矛盾:AI公司的商业利益和技术目标都指向「让AI回答得更全面」,而不是「让AI更谨慎地保护你的隐私」。短期内别抱太大期望。
回到开头那个被陌生电话轰炸的Reddit用户。
他只是在某个时刻,以某种方式,把自己的电话号码留在了互联网上。可能是十年前的一个帖子,可能是注册某个服务时的必填项,可能是朋友在社交媒体上不经意间@了他。
然后AI来了,把这条沉睡在互联网深处的信息捞了出来,像发传单一样散给了每一个提问的人。
他做错了什么吗?并没有。
他能做什么吗?几乎什么也做不了。
这才是最让人不安的部分。
END
本文素材来源:MIT Technology Review 深度报道(2026-05-13)、DeleteMe 隐私数据统计
