夜雨聆风
夜雨聆风上周我做了一件可能有点疯狂的事。
我把 OpenClaw 的核心源码,从 Agent Loop 到 System Prompt,从 Memory 系统到 Context Engine,一行一行读完了。不是看文档,不是读博客,是直接啃 TypeScript 源码。
你问为什么?其实吧,我最近一直在研究 Agent 框架的架构设计。看了 LangGraph、AutoGen、CrewAI 各种框架的设计文档,总觉得隔靴搔痒。文档告诉你「怎么用」,但不告诉你「为什么这么设计」。而 OpenClaw 作为一个 367K Star 的项目,它的架构选择一定经过了大量用户场景的验证。
所以我决定,直接看源码。
结果这一看,还真看出了一些让我挺震撼的东西。
🔬 五个模块 · 二十一个知识缺口 · 一个贯穿始终的洞察
我先说结论,然后再一个一个展开。
我读完整个代码库之后,脑子里冒出来的第一个念头是,这玩意不是一个 AI 应用框架,这是一个操作系统。
不是比喻,是真的在结构上高度同构。
Agent Loop 的三层嵌套循环,和 OS 的进程调度如出一辙。Memory 的三层架构,和你手机里的内存层级一模一样。Prompt 的六层组装,像极了网络协议的 OSI 模型。甚至连错误恢复的 Failover 策略,都和 Kubernetes 的 Pod RestartPolicy 几乎一一对应。
你要是做过系统架构,看到这些映射关系的时候,真的会有一种「原来如此」的感觉。
好,一个一个聊。
大部分人对 Agent 的理解是,用户说一句话,Agent 回一句话,一来一回。
坦率的讲,我之前也是这么想的。
但 OpenClaw 的 Agent Loop 完全不是这个结构。它是一个三层嵌套循环,每一层处理不同粒度的故障。
L1: for(;;) ← Provider 级别故障转移(换 API Provider)
L2: while(true) ← Model 级别重试(换模型/Profile)
L3: runEmbeddedAttemptWithBackend() ← 单次 API 调用L3 是最内层,负责一次具体的 API 调用。如果调用失败了,L2 会决定要不要换一个 API Key 重试,或者切换到备用模型。如果 L2 的所有重试都用完了,L1 会尝试切换到完全不同的 Provider。
这个结构让我想到了什么?
CFS 调度器。
Linux 内核的 CFS(完全公平调度器)也是类似的嵌套结构。最外层是 CPU 级别的负载均衡,中间是调度域内的任务迁移,最内层是单个 CPU 上的时间片分配。每一层处理不同粒度的「故障」,失败了就上升一层处理。
💡 Agent Loop 的三层嵌套 = OS 调度器的三级调度。不是巧合,是同一个问题的同一个解法。
但最让我觉得有意思的,不是这个结构本身,而是 OpenClaw 的重试策略。
它不是简单地「再来一次」。
每次重试,它会往 Prompt 里追加一条新的「修正指令」。第一次失败,追加 ackExecutionFastPath 修正。第二次失败,追加 planningOnlyRetry。第三次,reasoningOnlyRetry。每一轮的 Prompt 都比上一轮多了一条「上次你做错了什么」的反馈。
反直觉 重试不是 ctrl+z 重来,而是每次带着新的诊断信息重试。
这让我想到了 TCP 的拥塞控制。TCP 也不是丢包了就原样重发,它会根据丢包的模式调整窗口大小。慢启动、快重传、快恢复,每一次重传都带着对网络状态的新认知。
OpenClaw 的重试策略,就是 Agent 世界的拥塞控制。
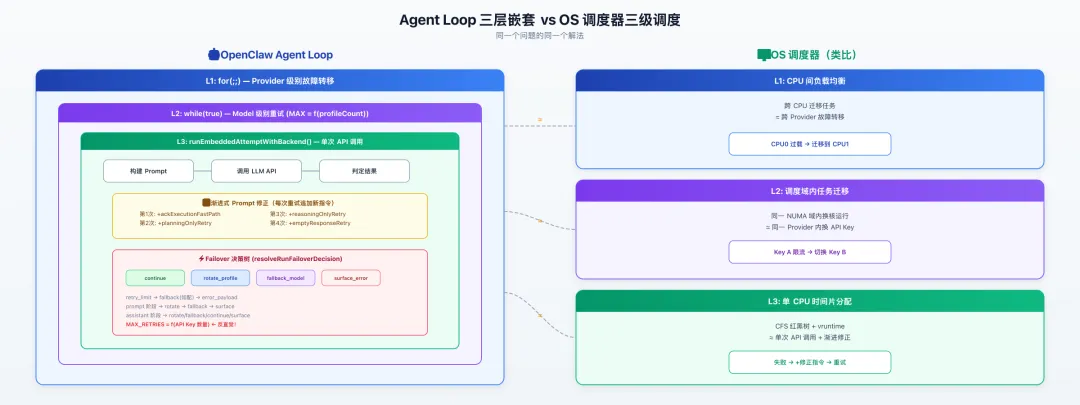
顺着这个再聊聊 Failover 的决策逻辑。OpenClaw 有一个函数叫 resolveRunFailoverDecision,它是一棵三阶段五出口的决策树。
| 决策 | 含义 |
|---|---|
continue_normal | 没事,继续 |
rotate_profile | 换一个 API Key |
fallback_model | 切换备用模型 |
surface_error | 放弃,告诉用户 |
return_error_payload | 返回错误但不崩 |
你看这五个出口,是不是特别眼熟?
continue_normal ≈ K8s Pod Running,rotate_profile ≈ 换 Node 重调度,fallback_model ≈ 降级到 BestEffort QoS,surface_error ≈ CrashLoopBackOff 最终放弃。
还有一个反直觉的设计,重试次数上限不是固定常量。它是 resolveMaxRunRetryIterations(profileCandidates.length),你配了多少个 API Key,上限就有多高。多配 Key 不只是提高可用性,还能增加容错空间。就像 RAID 阵列,磁盘越多,冗余度越高。
🧠 三层记忆,和你手机的内存一模一样
说真的,这是整个拆解过程中让我最兴奋的部分。
OpenClaw 的记忆系统分三层。
| 层级 | 名称 | 容量 | 速度 | 持久性 |
|---|---|---|---|---|
| L1 | ContextEngine(工作记忆) | ~100K tokens | 即时 | 会话级 |
| L2 | MEMORY.md(长期记忆) | 无限 | 较慢 | 永久 |
| L3 | MemorySearchManager(语义检索) | 无限 | 最慢 | 永久 |
L1 是当前对话的上下文,相当于你手机的 RAM。容量有限,速度最快,掉电就没了。
L2 是持久化的 Markdown 文件,相当于 Flash 存储。容量无限(磁盘能有多大就有多大),但读写需要额外操作。
L3 是基于向量的语义搜索,相当于搜索引擎。你不需要记住信息在哪,描述一下你要找什么,它帮你检索。
你看,L1 ≈ RAM,L2 ≈ Flash,L3 ≈ 搜索引擎。容量从小到大,速度从快到慢,持久性从弱到强。这就是经典的存储金字塔。
💡 计算机科学 70 年反复验证的存储层级设计,Agent 框架又重新发明了一遍。
但更有意思的是 compact(压缩)机制。
当 L1 的对话历史太长,快要超出 token 预算的时候,OpenClaw 不是简单地截断旧消息。它会把整个对话发给 LLM,让 LLM 生成一份摘要,然后用摘要替代原始历史。
这个过程有个名字叫 compactEmbeddedPiSessionDirect。我读到这个函数的时候愣了一下,因为它复用了完整的 System Prompt 来做压缩。不是一个精简的「请总结以下对话」的提示词,而是带着完整的角色定义、工具列表、行为规范的 System Prompt。
为什么?
因为如果 LLM 在压缩时不知道自己是谁、能做什么,它生成的摘要就会「跑偏」。就像你让一个不知道自己是医生的人总结一段医疗对话,他可能会漏掉关键的诊断信息。
反直觉 压缩操作比正常对话更贵(需要完整 System Prompt + 全部历史),但这是正确的设计。用短期成本换长期质量。
这跟 PostgreSQL 的 VACUUM 是同一个道理。VACUUM 清理死元组的时候,也需要完整的表结构信息才能正确工作。
📦 六层 Prompt 组装,就是 AI 版的 OSI 模型
每次 OpenClaw 调用 LLM API,它发出去的 Prompt 不是一个简单的字符串。
它是一个精心组装的六层结构。
L1: System Prompt (~8-15K tokens) ← 身份+规则+工具,类比 OSI 物理层
═══ CACHE BOUNDARY ═══
L2: Memory Addition (~2-5K tokens) ← 注入长期记忆
L3: Bootstrap Files (~3-10K tokens) ← SOUL.md/AGENTS.md/CLAUDE.md
L4: Context Files (~5-15K tokens) ← 项目代码快照
L5: Conversation History (~30-80K tokens)← 最大层,compact 管理
L6: User Message (~0.5-5K tokens) ← 当前用户输入每一层都有自己的来源、自己的预算管理、自己的牺牲策略。
中间那个 CACHE BOUNDARY 是 OpenClaw 的一个精妙设计。它在 System Prompt 中间画了一条线,线以上的内容是「稳定的」,可以被 LLM API 的 prompt cache 命中。线以下的内容是「动态的」,每轮都会变化。
你想想看,每次 API 调用都要发送 50-130K tokens。如果每次都从头计算,成本会非常高。通过把稳定内容放在前面,OpenClaw 能让 API Provider 缓存大约 40-60% 的 Prompt,显著降低延迟和成本。
这跟 HTTP 的 Cache-Control 是完全一样的思路。stablePrefix 是 public, max-age=forever,动态部分是 no-cache。
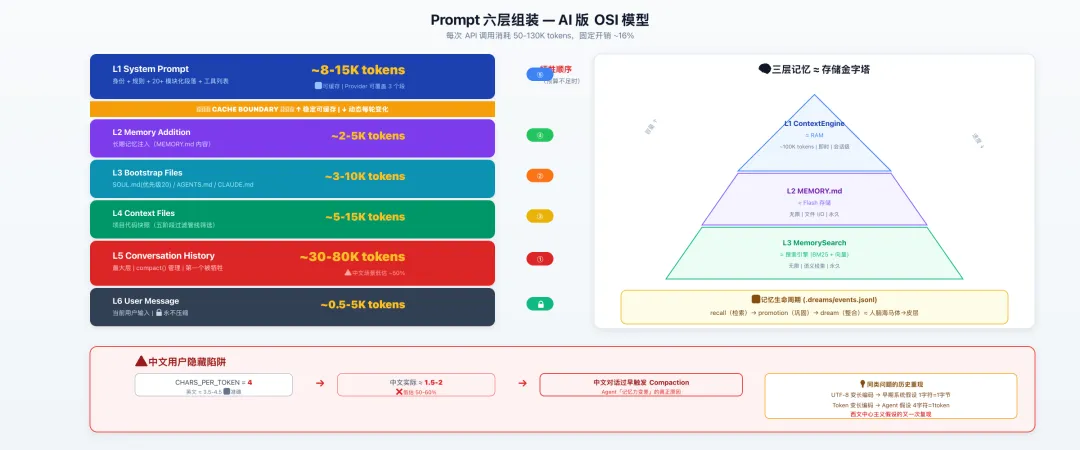
💡 每次空对话就要消耗 21K tokens,固定开销占总预算的 16%。这解释了为什么 OpenClaw 要在提示词中精打细算每一行文字。
然后是牺牲顺序。当 token 预算不够的时候,谁先被砍?
L5 对话历史 → L3 Bootstrap Files → L4 Context Files → L2 Memory → L1 System Prompt → L6 用户消息用户消息永远不被压缩,System Prompt 几乎不被压缩,对话历史第一个被牺牲。
反直觉 这个顺序不是一个统一的「优先级调度器」控制的。每一层都有自己独立的预算管理机制。牺牲顺序是各层独立响应资源压力「涌现」出来的。像经济学的价格机制,没有中央计划者,但宏观上形成了有序的退出序列。
⚠️ 中文用户的隐藏陷阱
这个发现让我有点不舒服,但我觉得必须说出来。
OpenClaw 的 token 计数用的是字符估算法。核心参数是这样的。
CHARS_PER_TOKEN_ESTIMATE = 4 // 每 4 个字符 ≈ 1 个 token
SAFETY_MARGIN = 1.2 // 安全系数 1.2 倍对英文来说,这个估算是偏保守但基本准确的。英文平均大约 3.5-4.5 个字符一个 token。
但对中文呢?
中文的 token 密度完全不一样。一个中文字通常是 1-2 个 token,也就是说 chars/token 大约是 1.5-2,而不是 4。
所以实际情况是什么呢?
OpenClaw 会低估中文对话的 token 使用量,大约低估 50-60%。
后果是,中文用户的对话会比系统预期更快地逼近 token 上限,触发 compaction 的频率更高。你可能聊了没几轮就发现 Agent 的「记忆力」变差了,那不是 LLM 的问题,是 token 预算被低估导致过早压缩了。
⚠️
CHARS_PER_TOKEN = 4是一个西文中心主义的假设。对中文、日文、韩文等 CJK 语言,这个数字应该是 1.5-2。但代码里没有语言检测逻辑,一刀切用 4。
这让我想到了 Unicode 的变长编码(UTF-8)。英文 1 字节,中文 3 字节。很多早期系统假设 1 字符 = 1 字节,导致中文处理一堆 bug。现在 Agent 框架又在 token 层面犯了同样的错误。
我觉得这不是故意的忽视。大概率是因为开发团队主要处理英文场景,测试数据也以英文为主。但作为一个中文用户,这个数字差异带来的体验退化是实实在在的。
🎯 我的判断
读完这些源码之后,我有几个比较确定的判断。
第一,Agent 框架正在不可避免地走向操作系统化。
你看 OpenClaw 的架构,三层循环是调度器,记忆系统是存储层级,ContextEngine 是 MMU(内存管理单元),Prompt Cache Boundary 是 Cache Line 对齐。这些不是巧合,是因为 Agent 框架和操作系统面对的是同一类问题,在有限的资源(token 预算 ≈ 内存/CPU)上,管理多个并发任务(工具调用 ≈ 系统调用),同时保持状态的一致性和可恢复性。
第二,ContextEngine 是 Agent 框架里最被低估的组件。
OpenClaw 目前的 ContextEngine 实现(叫 Legacy)几乎是空壳,assemble() 直接 pass-through 返回所有消息,ingest() 是 no-op。真正的 token 管理逻辑分散在 compaction、bootstrap 等调用方。
但这个「空壳」其实是最值得关注的扩展点。未来如果有人实现一个基于重要性评分的 ContextEngine,能根据对话内容的语义权重智能选择保留哪些消息、丢弃哪些消息,而不是简单粗暴地做 LLM 摘要,那 Agent 的「智慧感」会有质的飞跃。
第三,Heartbeat 的设计范式值得深思。
OpenClaw 的 Heartbeat 不是定时器。它没有 setInterval,没有 watchdog 线程。它就是在 System Prompt 里加了一段话,告诉 LLM「你需要定期汇报进度」。
用语言控制行为,而不是用代码控制行为。这是 Agent 框架特有的设计范式。传统系统用硬件中断驱动心跳,Agent 用「提示词中的行为契约」驱动心跳。
💡 当你的「CPU」(LLM)能理解自然语言时,很多传统的控制流机制都可以「上移」到提示词层面。这不是偷懒,这是新的设计空间。
第四,Agent 记忆隔离和 Android 进程模型几乎一模一样。
每个 Agent 的记忆空间按 agentId + workspace 隔离。父 Agent 的 MEMORY.md 对子 Agent 不可见。信息传递不通过共享文件系统,而是通过 prepareSubagentSpawn() 时显式传递的 context。
agentId ≈ Linux UID,workspace ≈ /data/data/<package>/,显式 context 传递 ≈ Binder IPC。
连安全模型都是一样的,默认隔离,需要共享就走显式的通信通道。
还有一个细节很有意思。OpenClaw 的记忆生命周期通过 events.jsonl 记录了三种事件。
memory.recall.recorded 是每次检索记忆。memory.promotion.applied 是从短期记忆提升到长期记忆。memory.dream.completed 是周期性的记忆整理。
recall → promotion → dream,检索 → 巩固 → 整合。
你不觉得这和人脑的记忆巩固过程惊人地相似吗?工作记忆中的信息被反复检索(recall),重要的被海马体标记并转移到皮层(promotion),然后在睡眠期间重组整合(dream)。
OpenClaw 甚至把这个文件叫 .dreams。我不确定起名的人是不是故意的,但这个命名也太贴切了。
回到最开始的那个判断,Agent 框架正在重新发明操作系统。
这句话听着像是批评,但其实不是。
计算机科学的历史就是在不同的抽象层级上反复解决同一类问题。硬件层解决了进程调度,数据库层解决了事务管理,网络层解决了可靠传输。现在 Agent 层在解决「如何在有限 token 预算上管理多任务 AI 会话」,用到的解法和前辈们一脉相承。
说真的,我觉得这恰恰说明了这些设计模式的生命力。它们不是过时的东西,是经过几十年验证的、解决资源约束下任务编排问题的最优解。
如果你是做 Agent 开发的,我建议你去翻翻操作系统的教科书。不是为了考试,是为了少走弯路。OpenClaw 的架构师们显然读过这些书,所以他们的设计才这么优雅。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。