 夜雨聆风
夜雨聆风
Kimi K2.6的Agent模式
如果你这两天体验了Kimi K2.6的Agent模式,很可能已经被那种“一句话交付整个应用”的顺滑感刷新了认知。它不像从前那样只吐出一堆代码让你自己去调试部署,而是直接丢给你一个立即可用、功能完备的网站——有前端界面、有后台逻辑,还有独立数据库和一套完整的用户账号体系。就像你跟助手说:“帮我搭个读书笔记网站,能登录、能搜索、能导出。” 五分钟后,它已经为你准备好了一切,你直接就能开始记录和分享。
这种体验的背后,藏着一个更大的故事——那是一个关于数据库如何被AI“颠覆重塑”的故事,也是一个关于下一个十年技术基础设施变革的强烈信号。
从交付代码到交付服务:
Agent时代的新“基建”
Kimi K2.6的Agent模式不仅仅是帮你写代码,它全面接管了从开发、托管到数据库运维的完整链路。这意味着每有一个用户让AI生成了一个应用,系统就必须为这个用户分配一个独立的数据库,而且从创建、配置到长期运维都必须由AI自动完成,全程无需人类工程师介入。
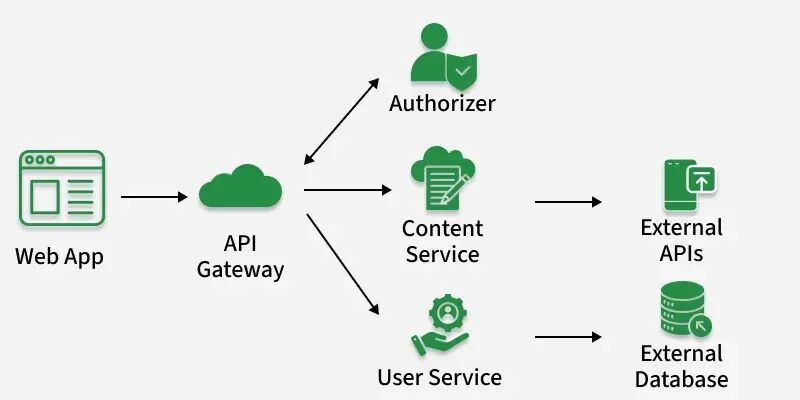
Tools-Data-Orchestration三层结构
表面上看,这是一个应用交付方式的升级;深层里,这给底层数据基础设施提出了前所未有的工程难题。Kimi工程团队要直面的,是一个典型的“不可能三角”:极致的低成本、海量的多租户规模、以及隔离稳定的性能,三者必须同时满足。而传统的任何数据库方案,在这个三角面前都出现了裂缝。
三大挑战:
当百万用户每人需要一个数据库
要理解这场挑战的严峻性,我们不妨做一个类比。如果未来每个用户都像拥有一个Excel文件一样,拥有一个独立的、功能齐全的在线数据库,而用户量可能达到百万级别,传统云数据库的世界会发生什么?
第一个挑战,是成本的雪崩。在传统云数据库方案里,哪怕是最便宜的托管PostgreSQL或MySQL实例,每个月也要十几到二十美元。如果按这个单价乘以数百万用户,成本会瞬间失控。更致命的是,绝大多数由AI生成的网站访问量极低,可能长期处于闲置状态,但成本却一分不少。这就好比为每户家庭建了一座发电厂,哪怕全家出门旅行,电厂空转的账单也得照付。

第二个挑战,是动态schema带来的数据风险。与传统软件开发中由人类仔细设计表结构不同,Kimi的数据库表结构完全由LLM根据用户的自然语言指令实时生成,而且后续还可能因为用户一句“再帮我加个收藏功能”而在线修改。这种对生产数据库进行高频、自动化、不可预知的DDL操作,极易引发数据损坏或丢失。任何一丝不小心,都可能让用户的数据付诸东流。
第三个挑战,是“零-峰两极”的极致负载。大多数AI生成的小应用流量长期为零,但偶尔某个站点可能因为一条社交分享,流量瞬间暴涨百倍以上。数据库必须能瞬间从“近乎沉睡”弹到“满负荷运转”,而且这种陡增绝不能干扰到其他用户的平稳运行。就像一栋住着百万住户的大楼,平时安静得落针可闻,可某一家突然要开摇滚演唱会,整栋楼的承重和隔音都必须扛得住。
传统的“单实例多Schema”方案(比如PostgreSQL的多Schema模式)在隔离性和扩展性上存在瓶颈;而“一用户一实例”的Serverless PG方案又因为冷启动时间和成本结构,难以满足亚秒级就绪的要求。这片“无人区”,需要的是一种全新范式的数据库。
破局思路:用AI的方式
为AI重建数据库
Kimi最终的选择是分布式数据库TiDB Cloud,并且通过三项极具针对性的技术决策,把“不可能三角”拆解得干脆利落。这背后蕴含的思维,远比选型本身更耐人寻味。
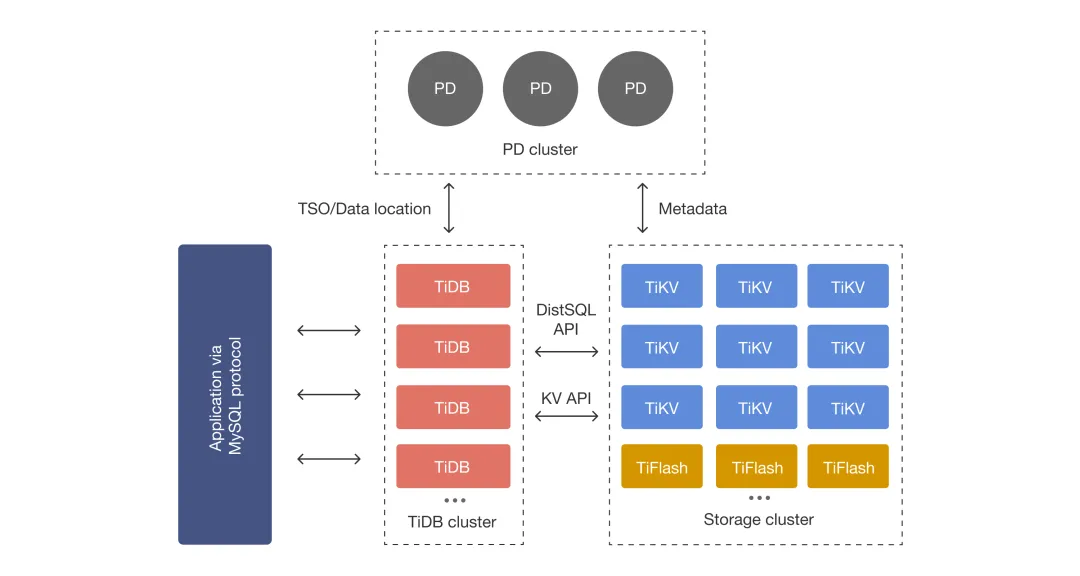
TiDB官方架构图
1. 极致低成本:虚拟数据库与“不叫醒装睡的人”
为了不负担海量闲置用户的成本,Kimi利用了TiDB Cloud的Serverless多租户能力,构建了一种“虚拟数据库”层。它不为闲置的长尾用户分配真实的独立实例,只有当用户发起请求时,连接网关才在瞬间弹性配给资源,完成服务后又可彻底缩容。这就好比让所有住户共享一个巨大的发电厂,用电时才接通线路,不用时完全没有空转成本。这让“人手一个数据库”在经济上第一次变得可行。
2. 降低LLM的开发复杂度:让数据库学会说AI的语言
过去,一个AI Agent要完成一个稍微复杂的查询,可能需要同时协调关系型数据库、JSON处理引擎、向量数据库等多个客户端。这不仅增加了代码出错的风险,也让LLM在执行任务时容易“分心”。而TiDB用统一技术栈解决了这个问题——它允许用一条SQL语句,同时进行传统过滤、JSON字段筛选和向量相似度排序。这就大幅简化了AI Agent的工作,让它能以更低的认知负荷准确完成任务。换句话说,数据库终于开始“说AI听得懂的话”了。
3. 瞬间就绪的流畅体验:Warm Pool与一秒交付
为了让用户感觉不到等待,Kimi利用了TiDB Cloud的“Warm Pool”(预热池)和scale-to-zero能力。系统预先准备了一组随时可用的计算资源,当新用户需要一个数据库时,1秒内就能完成分配和就绪。这种近乎瞬时的体验,让AI交付应用的过程变得像打开手机应用一样自然,完全没有传统云资源供给时漫长的冷启动感。
超越个案:
一个行业信号的深水区
Kimi的选择并非孤例,而是一个重要的行业转向。数据揭示了一个惊人的事实:目前在TiDB Cloud上,超过90%的新增集群是由AI Agent创建,而非人类工程师手动完成。Dify、Manus等头部AI平台,此前也都因为在成本、隔离或运维压力上撞墙,最终纷纷转投TiDB作为数据基座。
这清晰地说明了一件事:当AI Agent开始大规模、自动化、低成本地创建和管理应用时,数据库的设计哲学必须发生根本转变。过去,数据库是给人用的——由人类规划schema,由DBA运维,由工程师调优;而在AI时代,数据库的第一用户变成了AI本身,它需要的是一种能够被程序化创建、瞬间伸缩、无限分裂且成本近乎为零的数据基座。

我们可以大胆预判,下一代的“AI原生数据库” 不再是简单地在原有架构上做加法,而是从内核出发,为Agent的大规模协同工作、数据的自动分级存储和动态schema的绝对安全而设计。它会把成本曲线、隔离性能与开发者体验重新平衡,让每一个AI生成的微应用都拥有世界级的数据底座。
这也给了我们一个启示:未来的技术竞争,前端看模型,后端看数据基础设施。谁能先搞定这种“为AI而生”的数据库,谁就能在应用爆炸的时代占据地基。Kimi和TiDB Cloud的这次联手,不过是序幕拉开的那一刻。
如果你也在打造AI驱动的下一代应用,不妨留意一下,你的数据库准备好迎接“Agent洪水”了吗?
