 夜雨聆风
夜雨聆风拿到技嘉AI TOP ATOM那几天,工作室里最常听见的一句话是:“这玩意儿真能跑千亿模型?”
不怪大家质疑,这台机器比巴掌大不了多少,150mm见方,50.5mm厚,银灰色铁壳子,没灯没线条,往显示器旁边一搁很容易被当成外置硬盘。但就是这个不起眼的小盒子,让工作室几个平时在云端租卡的开发同事动了换设备的心思。

讲个真实场景。有同事之前跑GLM-4.5的量化版本,得在本地搭环境、配驱动、解决各种依赖冲突,折腾半天还没跑通。但是技嘉AI TOP ATOM开箱后,浏览器输个IP端口,账号密码一填,模型已经在里面等着了。从通电到第一次对话,前后不到五分钟。这种体验上的差距,比参数表上的数字差更有说服力。
为什么能做到?核心在于技嘉这次没只堆硬件,而是跟趋境科技把软件链路打通了。机器出厂就预装了AIMA管理平台和智问应用系统,GLM-4.5-Air 106B模型已经部署好,你不需要懂容器、不用管CUDA版本、不用纠结Python环境。就连后台的管理界面都是图形化的,GPU占用、显存消耗、Tokens用量直接看图表,谁在大量消耗算力一目了然。换模型也简单,下载后放到指定文件夹,系统自动识别导入,我们试了Qwen 2.5 7B,几分钟就切换过去了。
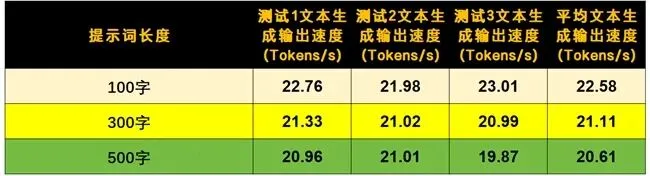
硬件的定位其实也很清晰。NVIDIA GB10芯片采用3纳米制程,CPU是20个Arm v9.2核心,GPU有6144个CUDA核心,搭配128GB统一内存。这些数字的背后是一个实用逻辑:FP4精度下1000 TOPS的算力,刚好够流畅跑千亿参数模型。实测GLM-4.5-Air在500字提示词下,文本生成速度保持在20 TPS以上,106B模型跑起来没有卡顿。同时跑对话、向量化、重排序三个实例,系统自动分配资源,互不干扰。这意味着单台设备就能搭起RAG全链路,不用多台服务器拼凑。
还有个细节容易被忽视,但实际很管用:背面的ConnectX-7接口。如果你觉得单台不够,拿另一台AI TOP ATOM连过来,算力和显存直接池化,可以支撑4000亿参数以上的模型。这种拼接式扩展比一次性买大型服务器灵活得多,预算可以分步走。

散热和噪音控制做得也不错:TDP压在140W,金属外壳加栅格风道设计,跑满负载时机身温热,但风扇声不明显。这对于要长时间跑推理任务的场景很重要,毕竟没人想在办公桌上放一台直升机。
现在回过头看技嘉对这款产品的定位——个人AI超级电脑。这个说法不夸张,但我想换个表述:它把以前需要专业技术团队才能在数据中心做的事,压缩到了桌面上,而且压缩到了小白也能用的程度。
云端租卡按小时计费,长期跑下来成本不低,数据还要上传。自己组工作站,配双卡甚至四卡,电源、散热、主板、机箱一套下来,成本高不说,噪音和功耗也是麻烦。技嘉AI TOP ATOM工作站把这两个痛点都回避了:一次性硬件投入,数据本地留存,功耗控制在240W适配器就能喂饱。
对于AI开发者、科研人员、小型工作室,或者只是想本地跑大模型的个人用户,这台设备提供了另一种选择——不是云端,不是暴力堆料的台式工作站,而是一个刚好够用且不用操心的桌面盒子。

AI本地化的趋势已经很明显了,但硬件和软件之间一直有个断层。技嘉这一次把断层接上了。值不值得入手,我的看法很简单:如果你是那个不想再折腾环境、不想再等云端排队、想把自己的数据留在本地的人,这台机器值得认真考虑。它不是什么未来概念,是今天就能用上的东西。
