 夜雨聆风
夜雨聆风最近有篇关于 AI Agent 的论文,拿玩宝可梦做实验。
一听到这里,很多人第一反应可能是:这也能发论文?
一个 AI,对着二十多年前的像素游戏,按 A、B、上下左右,在草丛、山洞和道馆里来回折腾。听起来有点像技术圈的整活。
但我越看越觉得,这个实验很适合拿来观察今天的 AI Agent。
因为宝可梦不是一个“回答对就结束”的任务。它很长,很碎,很容易走偏。
你要记住自己在哪,要知道下一步去哪,要跟 NPC 对话,要穿过迷宫,要管理背包,还要打回合制战斗。前面漏一句话,后面可能绕半天。前面做错一个判断,后面可能一直在补锅。
💡这不就很像现实里的很多工作吗?
- ▸帮你改一个老项目,不是生成一段代码就完了。
- ▸帮你处理一个复杂售后,不是写一句客服话术就完了。
- ▸帮你做一轮市场调研,也不是搜几条信息拼起来就完了。
真正麻烦的地方,永远是长期任务里的记忆、反馈、修正和不跑偏。
是它怎么失败。
有一次,AI 想去宝可梦里的发电厂。
老玩家知道,在初代宝可梦里,发电厂不是一个可以直接“飞过去”的地点。但 AI 不知道,或者说,它没有真正确认。
于是它打开菜单,准备用“飞翔”。
菜单不好操作,它就开始给自己写工具。它写了一个小工具,叫 fly_menu_navigator,看名字像是专门帮自己在飞翔菜单里找目的地的导航器。
这一步其实挺像今天很多 Agent 的工作方式:不会的地方,不只是继续硬做,而是给自己加工具。
问题是,它写出的工具调用格式错了。
系统需要它明确按一个特殊的 "tool" 按钮,才会真的执行这个工具。但它一直以为自己已经在调用工具,于是反复输出“Down”。
结果,它按了 842 次向下。
更荒诞的是,它在这个过程中还在认真反思。
它会写类似“我正在测试发电厂是不是可以飞过去,我会注意确认偏误”这样的话。
也就是说,它不是完全没思考。
- ▸它在思考。
- ▸它不是完全没复盘。
- ▸它在复盘。
- ▸它甚至不是没有工具。
- ▸它自己写了工具。
但它还是在原地绕了三个半小时。
💡这就是长期 Agent 最真实、也最危险的地方:它可能看起来一直在努力,实际上没有推进。

AI Agent真正难的,不是“会想”,是“做错后能不能改”
今天很多人聊 Agent,喜欢用很大的词。
自主规划、工具调用、长期记忆、自我改进。
这些词都没错,但放到真实任务里,会立刻遇到一堆很小、很硬的问题。
- ▸工具调用格式会错。
- ▸记忆会过时。
- ▸目标会漂移。
- ▸复盘会变成自我安慰。
更麻烦的是,AI 有时候会把“我在分析”误以为“我在进步”。
那个按了 842 次 Down 的 AI,就卡在这里。
它的文字层面很像一个认真工作的员工:会写计划,会写反思,会提醒自己不要确认偏误。
但环境层面,它一寸没动。
这件事让我想到很多现实里的“假进展”。
- ▸项目周报写得很完整,但关键问题没解决。
- ▸会议纪要整理得很漂亮,但下周还是同样的人在同样的地方卡住。
- ▸一个人说自己复盘了半天,结果下次照样踩同一个坑。
所以判断一个 Agent 靠不靠谱,不能只看它会不会说“我反思了”。
要看它的反思有没有改变下一步动作。
这也是这篇论文真正想解决的问题。
所谓 Harness,其实就是给AI搭一张会变的工作台
论文里有个核心词,叫 Harness。
这个词不太好翻。你可以先把它理解成“工作台”或者“脚手架”。
一个大模型本身像大脑。
但只给它一个大脑,它干不了太多长期活。
你还得给它工具、记事本、任务分工、操作规范、失败记录。
这就像你让一个新人去装修房子。你不能只说“把房子装好”。你要给图纸、工具、预算表、验收标准,还要告诉他哪面墙不能砸。
如果干到一半发现水管位置不对,真正重要的不是让他写一句“我下次注意”,而是要改施工方案,改检查流程,改工具使用方式。
Agent 也是一样。
这篇论文提出的 Continual Harness,大概就是想让 AI 在长期运行中,一边做任务,一边改自己的工作台。
它会让一个“复盘员”定期看 AI 最近一段时间的行为,判断它是不是在绕圈、是不是工具调用失败、是不是目标停住了、是不是错过了关键线索。
然后它不只是提醒一句。
它会改四类东西:
- ▸提示词,告诉 AI 接下来该更注意什么。
- ▸子 Agent,相当于给不同问题配不同小助手。
- ▸技能库,把成功动作沉淀成可复用工具。
- ▸记忆,把重要信息留下,把过时信息降权。
这个思路很朴素,但很关键。
因为真正长期运行的 Agent,不能每犯一次错就重开一局。
现实工作没有“重置按钮”。
你处理线上事故,不能说我刚才学到了,我们把事故重新来一遍。
你跟客户推进项目,也不能让客户忘掉前面发生过什么。
长期 Agent 必须学会在残局里修正自己。
但别急着吹,它不是魔法
我喜欢这篇论文的一个地方,是它没有把事情讲得太满。
Continual Harness 对强模型有帮助,但对弱模型不一定有帮助。
在宝可梦 Emerald 的实验里,更强的 Gemini 3 Pro 加上这套机制,成本明显下降,完成度也更好。
但换成更弱的 Flash-Lite,效果反而可能比最简单的基线还差。
这点特别重要。
因为很多 Agent 产品现在容易犯一个毛病:把“加了工具”讲成“能干活”,把“有记忆”讲成“会成长”,把“能写计划”讲成“能执行”。
中间差得很远。
一个模型如果连基本观察、反馈理解和工具调用都不稳,你给它更多工具、更多记忆、更多子 Agent,它可能不是变强,而是更会把自己绕进去。
就像一个人看不懂图纸,你给他十本施工手册,他不会突然变成老师傅。
他只会更乱。
所以,Agent 的关键不是无限加功能。
而是要有能力门槛,也要有失败检测。
它得知道什么时候自己真的推进了,什么时候只是看起来很忙。
宝可梦实验给我们的启示,其实很现实
AI 玩宝可梦这件事,听起来猎奇。
但它暴露的问题一点都不猎奇。
未来我们让 Agent 做的很多事,都会长得像宝可梦。
- ▸路径不清楚。
- ▸反馈不及时。
- ▸任务很长。
- ▸中途会有很多小误差。
- ▸前面漏掉一句信息,后面可能花很久补救。
这时候,一个好 Agent 不该只是“更会说”。
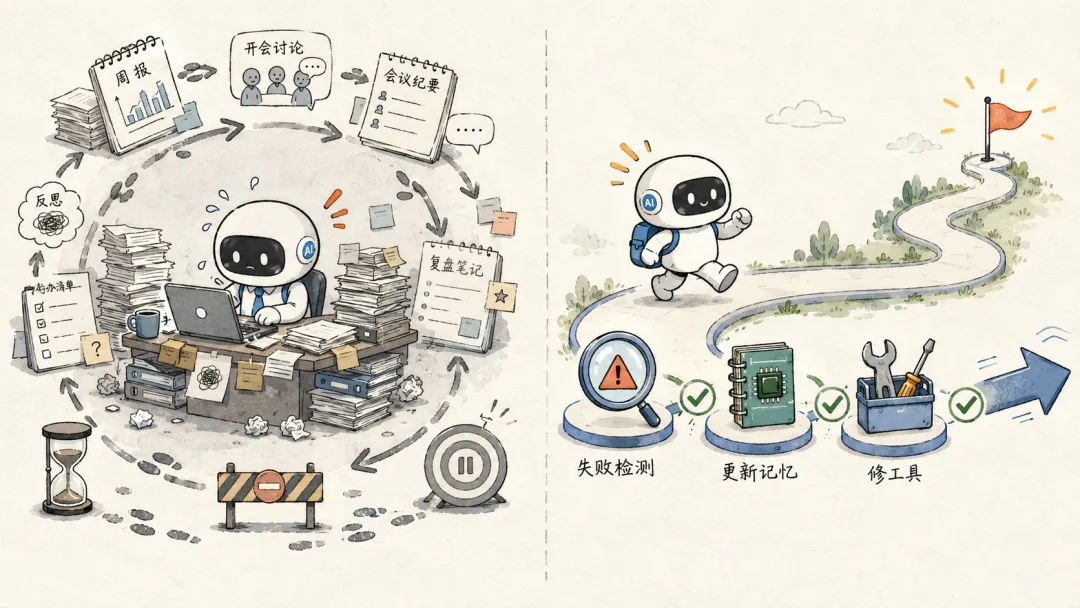
它应该能留下轨迹,检查失败,更新记忆,修工具,必要时停下来承认自己不行。
我现在越来越觉得,长期 Agent 最怕的不是笨。
笨一点可以补。
最怕的是假装没出事。
- ▸明明工具没执行,它以为执行了。
- ▸明明目标没推进,它以为自己在探索。
- ▸明明已经重复失败,它还在写漂亮的反思。
这比单纯犯错更危险。
因为它会制造一种很像工作的错觉。
最后还是回到那842次“向下”
那个 AI 在宝可梦里按了 842 次 Down。
这当然有点好笑。
但笑完之后,我反而觉得它挺有价值。
因为它提醒我们:Agent 不是因为会写计划就可靠,也不是因为会调用工具就成熟,更不是因为会反思就真的能自我改进。
真正有用的 Agent,应该能在第十次、第一百次重复失败时停下来。
它要能意识到:
💡我不是在探索。 我是在原地打转。
然后,它要能改掉让自己打转的东西。
宝可梦里的发电厂不能直接飞过去。
现实里的很多目标,也不能靠一句提示词直接飞过去。
中间那段会迷路、会犯错、会修正、会重新搭工具的路,才是 Agent 真正要学会走的地方。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
