 夜雨聆风
夜雨聆风
图1:璨辰科技围绕 Novaeve-Enhance / Novaeve-Anno / Novaeve-Dev / Novaeve-Agent 四个模块推进 AI Virtual Brain 构建。
引言
长期以来,人类对大脑的研究,大多停留在“静态观察”阶段。研究者可以看到脑组织切片、测量部分细胞状态,却很难真正连续追踪细胞如何随发育、疾病和药物干预发生变化。过去脑科学更像是在看静态照片,而虚拟大脑尝试让研究者第一次看到“会变化的大脑系统”:研究者能够看到不同细胞在空间中的位置,理解它们的细胞类型和状态,追踪它们可能如何随发育或疾病进程发生变化,并进一步为药物作用机制和干预策略评估提供计算线索。这样的系统听起来像科幻,但它正是璨辰科技长期努力追寻的方向。
不过,真正要把“虚拟大脑”从想象变成可实现的系统,难点并不是数据够不够多、显卡够不够多、模型参数够不够大。生命系统不是互联网文本,也不是自然图像;大脑更不是一张可以被完整扫描、一次性读懂的照片。这意味着,过去的大多数脑组学分析,本质上仍停留在“静态切片”和“离线统计”阶段,很难真正形成一个能够持续推演发育、疾病和药物响应过程的系统级数字模型。它的每一次测量都带着实验技术的边界:
空间转录组能够保留细胞在组织中的位置,却往往只能测到有限的基因面板;
单细胞测序可以揭示细胞状态,却常常受到测序深度、技术噪声和Dropout 操作的影响;
脑细胞类型并不是简单的几个大类,而是存在复杂的层级结构、空间分布和微环境相互作用,越往细处差异越微妙;
发育和疾病进程更不是一段可以连续观测的录像,更多时候只是不同时间点、不同疾病状态留下的“快照”。
因此,构建 AI 驱动的虚拟大脑,不能简单理解成“把更多数据倒进更大的模型里”。它更像是在搭建一条从原始观测到智能推演的技术链条:
第一步,面对稀疏、缺失和低深度的组学数据,尽可能增强数据质量,恢复被实验技术遮住的分子信号。
第二步,在数据变得更可用之后,为每个细胞建立清晰、稳定、层级化的身份标注,知道它属于哪一类细胞、处在什么状态。
第三步,进一步把这些静态细胞图谱放进时间和疾病进程中,建立能够描述细胞状态变化的动态模型。
第四步,让 Agent 把数据增强、细胞标注、动态建模等能力组织起来,形成一个可审查、可追踪、可调度的分析流程。
沿着这一长期目标,璨辰科技团队近期在四个模块上取得了阶段性进展:
Novaeve-Enhance:面向数据增强,尝试从稀疏、低深度或部分观测的组学数据中恢复更多分子信号。
Novaeve-Anno:面向脑细胞层级标注,利用生物分类结构提升复杂脑细胞类型识别能力。
Novaeve-Dev:面向细胞动态建模,尝试从离散时间点的单细胞快照中推演群体状态变化。
Novaeve-Agent:面向智能调度与证据审查,在多模型、多参考图谱、多分析路线并存的情况下,帮助系统判断哪些路线可执行、哪些结果更可信、哪些不确定性应该被保留下来。
在现有行业中,大多数 AI for Biology 系统仍聚焦于单点任务,例如单一数据补全、单一细胞分类或单一预测模型。璨辰科技则尝试把这些能力连接成连续技术链,让 AI 不只是回答一个问题,而是逐步具备“理解—推演—辅助决策”的系统能力。
这些工作并不意味着“虚拟大脑”已经建成,但它们展现出一条清晰路线:先让细胞数据更可靠,再让细胞身份更清楚,再让细胞状态能够被建模和推演,最后让 AI Agent 把模型、证据和分析流程组织起来。
Novaeve-Enhance,让大脑组学数据更接近真实
Novaeve-Enhance 对应的是数据增强这一环。对于虚拟大脑来说,第一步不是让模型立刻去“理解大脑”,而是先让它看到更可靠的大脑组学数据。现实中的空间转录组常常只能检测有限基因,scATAC-seq 也会因为技术 Dropout 丢失大量染色质开放信号。Novaeve-Enhance 的目标,就是从这些稀疏、低深度或部分观测的数据中,尽可能恢复被实验技术遮住的分子信息。
这项工作的核心不是简单平滑数据,而是把基因或 Peak 按生物先验组织成有意义的序列,再用 Mamba 结构捕捉长距离依赖,并通过 Flow Matching 学习从“模糊观测”走向“更完整分子状态”的恢复路径。通俗地说,它不是把所有信号都抹得更均匀,而是判断哪些信号值得恢复,哪些噪音应该去除。
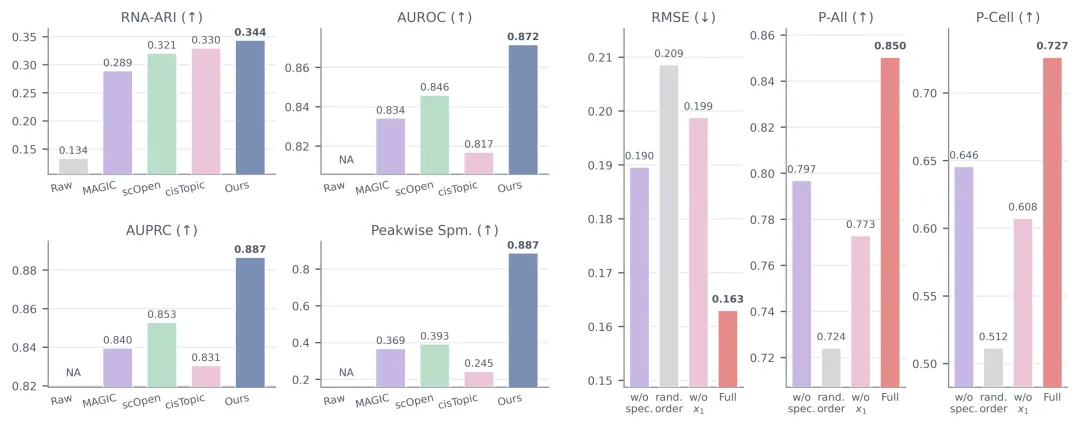
图2:Novaeve-Enhance 在空间基因补全和染色质开放信号恢复任务中,相比最强对照取得更好的核心指标。
在大脑相关任务中,Novaeve-Enhance 表现出明显优势。小鼠脑 Visium 空间基因补全任务中,RMSE 从最强基线的 4.1398 降到 3.2691,降低约 21.0%;全局 Pearson 相关性从 0.3303 提升到 0.6058,相对提升约 83.4%;在小鼠胚胎脑 scATAC 补全任务中,AUPRC 达到 0.8867,Peakwise Spearman 从最强基线的 0.3928 提升到 0.8871,相对提升约 125.8%。
在真实临床与科研场景中,高质量、多模态、完整测序的数据往往极其昂贵,甚至难以获得。如果 AI 能够从有限观测中恢复更多可靠分子信号,就意味着研究者未来有机会在更低实验成本下,更早识别疾病相关细胞状态,并提升药物筛选与机制研究效率。
Novaeve-Anno,给脑细胞建立层级身份
Novaeve-Anno 对应的是脑细胞标注这一环。大脑细胞并不是几个简单标签就能概括的,神经元、胶质细胞只是最粗的层级,继续往下还有 Subclass、Supertype 等更细分类型。同一个大类内部,很多细胞表达模式相对接近,但功能、空间分布和疾病相关性可能有明显差异。传统分类方式容易把这些层级关系打散,粗分类还可以,细分类就容易混淆。
Novaeve-Anno 尝试把脑细胞天然存在的“层级关系”直接写进模型中,让 AI 能够像生物学家一样,从大类逐步理解到细粒度亚型。这样,模型在判断 Supertype 时,不是从零开始猜,而是在已经理解大类和 Subclass 背景的基础上继续细分。
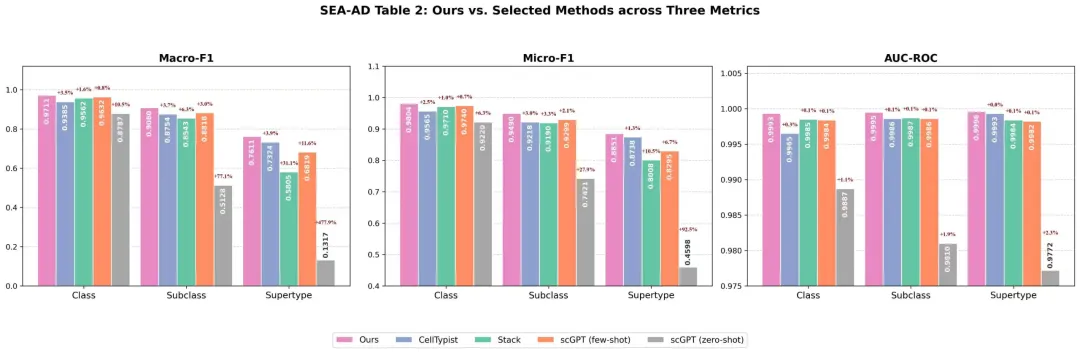
图3:Novaeve-Anno 在细粒度标注能力基准上展示出稳定的能力。
在 SEA-AD MERFISH 供体拆分测试中,Novaeve-Anno 在最细的137类Supertype 标注上取得 Macro-F1 0.7611、Micro-F1 0.8851、AUC-ROC 0.9996。在 Subclass 层级,模型达到 Macro-F1 0.9080、Micro-F1 0.9490。
外部大脑炎症数据也验证了这一点。在 Kukanja MS数据上,Novaeve-Anno 在 Level-3 细粒度标签上取得 Macro-F1 0.8551;在更困难的 Kukanja EAE 数据上,Annotation High 层级达到 Macro-F1 0.6971、Micro-F1 0.8006。消融实验进一步显示,Feature Residual 相比独立解码器,让 SEA-AD Supertype Macro-F1 提升约 6.4 个百分点,说明真正起作用的是“从粗到细”的层级特征传递。这意味着,AI 开始不仅能“看见细胞”,还开始能够更稳定地理解细胞在复杂脑组织中的真实身份。
脑科学领域长期存在的挑战之一:模型往往能识别“大类细胞”,却难以稳定区分真正与疾病、药物响应和功能区域相关的细粒度脑细胞亚型。尤其在神经退行性疾病、自身免疫疾病等复杂场景中,这种细粒度差异往往决定了研究结论是否具有真实生物学意义。
Novaeve-Dev,让大脑发育快照动起来
过去,大多数单细胞系统只能回答“现在细胞是什么状态”。Novaeve-Dev 则开始尝试回答另一个更困难的问题:“这些细胞未来会如何变化?”大脑发育过程本质上是动态的,但单细胞测序通常只能提供离散时间点的快照。测完一个细胞,它就不能再被继续追踪,因此研究者看到的不是同一个细胞的连续命运,而是不同时间点细胞群体的状态分布。Novaeve-Dev要解决的,就是如何从这些不连续的群体快照中,推演细胞状态随时间变化的趋势。
这项工作的核心不是只预测一个抽象速度,而是直接预测目标时间点的细胞表达状态,再从目标状态反推出流动方向。这样一来,模型输出本身就是一个可比较的细胞群体,可以直接和真实目标时间点的细胞分布对齐。
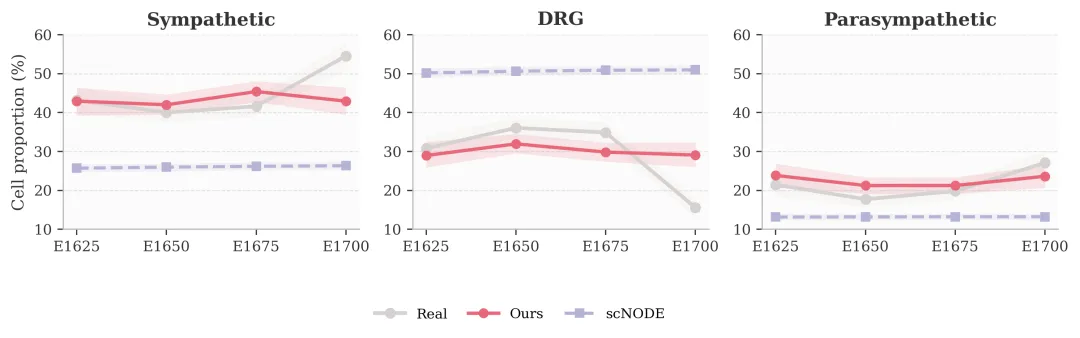
图4:Novaeve-Dev 生成分布更接近真实目标状态。
在大脑发育相关的 Mouse Neural Crest 数据上,Novaeve-Dev 的表现尤其突出。在近距离外推任务中,它将 Mean WD 从最强对照的5.536 降到 2.991,降低约 46.0%;在远距离外推中,从 9.283 降到 7.482,降低约19.4%;在插值任务中,也从 5.498 降到 3.673,降低约33.2%。这些指标说明,模型生成的细胞群体分布更接近真实发育时间点。
更有生物意义的是,Novaeve-Dev 更好地恢复了 Neural Crest 晚期的细胞组成变化,例如 Sympathetic 细胞比例上升、Dorsal Root Ganglion 细胞比例下降等趋势。对虚拟大脑来说,这意味着系统不只是拥有静态细胞图谱,还开始具备推演大脑发育状态变化的能力。从长期看,这种能力有望进一步延伸到疾病进展预测、药物干预模拟以及数字孪生器官建模等方向。
过去器官数字建模领域最难解决的问题之一:生物实验通常只能获得离散时间点的数据,而无法像电影一样连续观察细胞命运。因此,大多数现有系统只能描述“现在是什么”,却难以回答“未来会怎样变化”。
Novaeve-Agent,让系统会选择,也会克制
Novaeve-Agent 对应的是智能调度与证据审查这一环。当前面已经有数据增强、脑细胞标注和动态建模之后,真正落到科研分析时,还会遇到一个很现实的问题:同一批大脑数据,可能有多个参考图谱、多个基础模型、多个分析路线可选,结果也可能并不完全一致。系统如果只是把所有模型简单投票,反而可能把不确定性包装成“看起来很确定”的答案。
Novaeve-Agent 的思路,是把单细胞注释拆成一个可审查的多智能体流程。它不是让一个模型直接给最终标签,而是先判断哪些参考和模型路线可执行,再按规则完成 Label Transfer,最后根据不依赖真实标签的诊断信息决定是否融合结果,或者保留 Unknown。换句话说,它更像一个“分析调度员”,负责把不同工具组织起来,同时提醒系统在证据不足时不要过度自信。
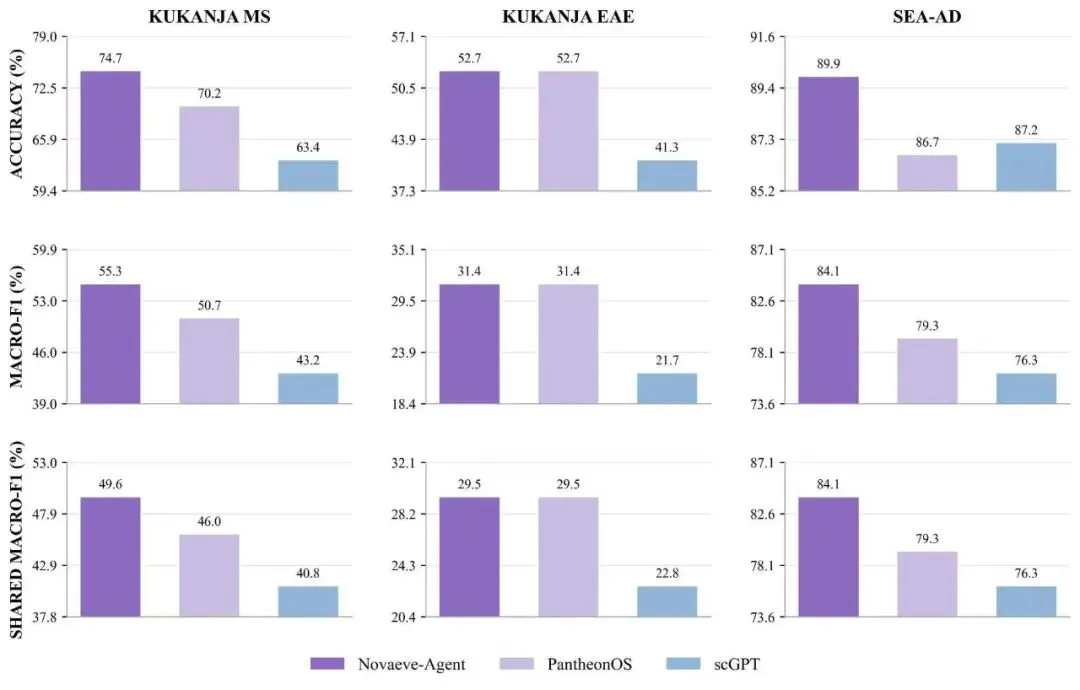
图5:Novaeve-Agent在对比生信智能体系统和单细胞大模型都有领先的性能表现。
从目前结果看,Novaeve-Agent 在 SEA-AD 和 Kukanja MS 上带来了一定提升。例如在 SEA-AD 数据中,Macro-F1 从 0.7934 提升到 0.8409;在 Kukanja MS 中,Macro-F1 从 0.5068 提升到 0.5530。不过,这一模块更适合理解为系统层探索,而不是已经完全成熟的自动科研平台。它真正重要的地方,不只是分数提升,而是尝试把“路线选择、结果融合和不确定性保留”变成一个可追踪、可审查的流程。
AI 在生命科学中的角色,正在从“单次工具调用”逐步演化为“可审查、可追踪、可协同”的科研基础设施。对于未来大规模自动化生物研究而言,这类系统可能成为连接模型、实验与科学证据的重要中枢。
从四个模块看虚拟大脑的技术路线
把这四项工作放在一起看,它们并不是彼此孤立的模型,而是璨辰科技围绕 AI 驱动虚拟大脑所推进的一条连续技术链。对璨辰科技来说,虚拟大脑不是短期内训练一个“超级模型”,而是一项需要长期 Scale Up 的系统工程:数据要更完整,标注要更准确,动态模型要更接近真实生物过程,Agent 调度也要更稳健。
这条路线也体现了璨辰科技对虚拟大脑的理解:不是先追求一个包打天下的大模型,而是把宏大目标拆成更符合生命科学实际的几个层次。先改善观测,让脑细胞数据更可靠;再理解身份,让每个脑细胞在复杂层级中找到位置;再建模变化,让静态快照变成动态推演;最后管理模型与证据,让系统知道该调用什么、相信什么,以及什么时候保留不确定性。
因此,璨辰科技这组工作更像是一张清晰的技术路线图,而不是一句“虚拟大脑已经实现”的宣言。它回答的是一个更基础的问题:如果未来要构建一个可以查询、标注、干预、推演的大脑数字系统,今天应该先把哪些底层能力做扎实?
从目前的探索看,璨辰科技正沿着这个方向,把 AI 在脑科学中的作用从单点工具,逐步推进到可持续扩展的研究基础设施。
接下来,璨辰科技要做的,是把这条技术链上的每一个环节继续Scale Up,并且做得更深、更稳、更好:让数据增强覆盖更大规模、更复杂模态的大脑数据;让细胞标注适应更多脑区、疾病和物种;让动态建模能够处理更长时间尺度和更复杂的状态转移;也让 Agent 系统在真实科研流程中更可靠、更可审查。
虚拟大脑的长期目标不会由某一个模型单独完成,而是在这些基础模块不断升级、连接和验证的过程中逐步逼近。
关于我们
璨辰科技由来自 清华、斯坦福、港中文 等全球顶尖高校的科学家与工程师共同创立,致力于构建全球领先的新一代生命科学基础能力,让计算模型及人工智能成为探索生命规律、指导药物研发与精准医疗的核心能力。
璨辰科技团队正在尝试构建全球首批面向“可查询、可推演、可干预”的 AI 虚拟大脑技术链,通过数据增强、细胞层级标注、动态状态建模与 Agent 调度系统,推动脑科学研究从“静态观察”走向“动态推演”。
诚邀全球跨学科英才,共建“生命科学世界模型”
探索生命规律的无形地图,离不开全球顶尖智慧的协同演化。伴随核心技术的突破与业务形态的纵深拓展,璨辰科技现面向海内外,正式启动人工智能与生命科学交叉领域的高端人才招募。
招募对象:我们寻找深谙大模型架构、多智能体协同的AI算法专家,以及专注单细胞多组学、空间转录组学、结构生物学等前沿领域的生命科学学者。
以计算科学攻克生命科学壁垒,是一场造福人类的伟大远航。璨辰科技诚邀海内外青年才俊加入我们,共同洞察生命本源,为改善人类健康贡献力量。
简历投递:hr@novaeve.ai
合作联系:bd@novaeve.ai
