 夜雨聆风
夜雨聆风
合规事故复盘题
上一课讲完文档权限能不能靠 prompt。这课换一道真事故题——AI 答了 7 天前合规已下架的费率,监管点名。复盘翻出 187 条已下架文档,向量库一条都没删。先重训模型,还是先查文档治理?
先把术语翻成人话
trace :一次问答的完整记录
CMS :合规系统,文档源头
metadata :向量库的状态标签
孤儿向量 :源头删了、向量库没删
黑名单 :命中关键词强制走人工
一、面试现场
面试官提问
"金融客服 AI 把一条已下架的费率口径答给用户,被监管点名。你来主导复盘——是先重训模型,还是先翻文档治理?"
蚂蚁 · 合规事故复盘面。候选人答了三分钟,思路是"模型幻觉,加 RLHF 微调"。面试官追了一句:"你看过这条 chunk 在 CMS 里的状态字段吗?"候选人卡住了。
这道题表面问"重训还是改文档",实际在考你能不能区分模型问题和数据问题——把责任推给模型,监管 1 小时止不了血;找对断点,1 小时就能下架。
直接回答 · 9 成是文档治理事故,不是模型幻觉。
二、大多数人怎么答的
典型翻车回答
"合规答错就是大模型幻觉,加 RLHF 微调或在 prompt 里写一句'请遵守合规'就行。"
这个回答错在方向。把过期口径还能召回的事故归到"模型幻觉",等于绕过了真正的责任人——文档生命周期没同步。截至 2026-05-15,主流监管口径仍要求 24 小时内能看到的系统层面动作;RLHF 微调周期长、不可逆、对监管不可解释,靠它修合规口径相当于用大锤砸钉子。
还有一层失误:"加一句 system prompt '请遵守合规' 就能避免"也不行。prompt 是建议不是约束,模型有概率"听话"。合规要的是确定性——已下架的内容物理上不能进入 retrieval 候选集,这是 metadata 状态过滤的事,不是 prompt 的事。
三、深度解析
把合规答错按"责任归属、链路断点、止血手段、长期防线"四个判断拆开看——这四个判断决定了你是 1 小时止血还是 1 周还在重训。
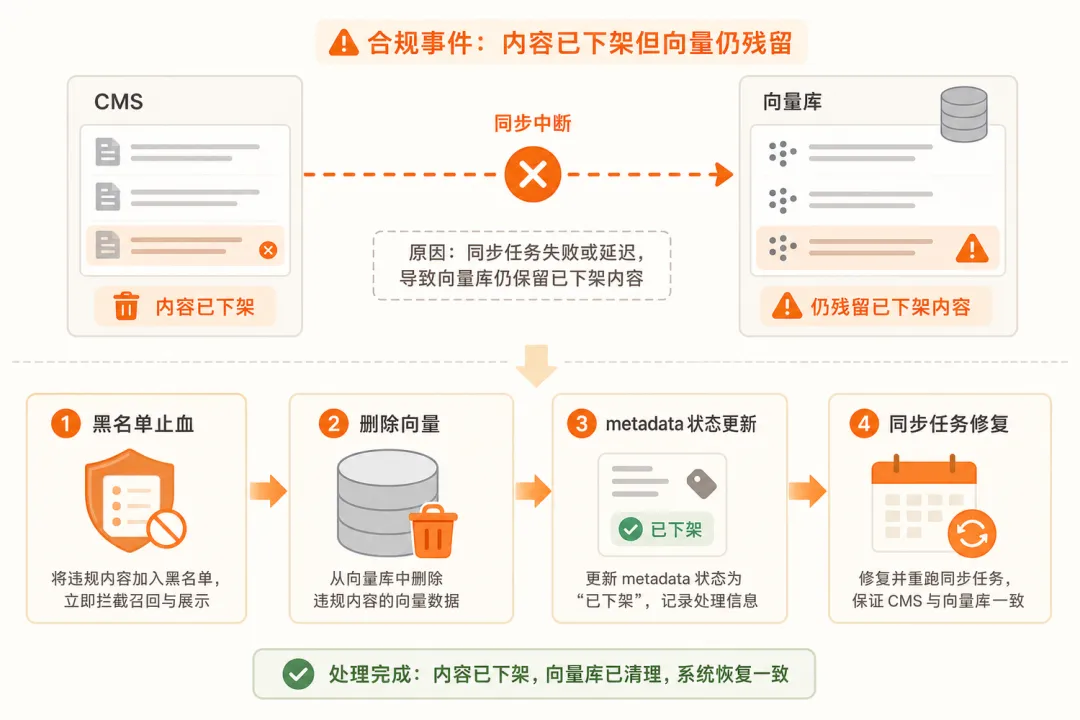
判断 1:合规答错 9 成不是模型幻觉,是文档治理事故
一句话:看 trace 里召回的 chunk 是不是真文档——是真文档而且原文里就有这句话,模型没编,是文档不该出现在候选集。
本次事故 trace 里:相似度 0.82 排第一、prompt 装配正常、答案直接复述了 chunk 原文。模型完全没幻觉,但内容已经过期 7 天。
我认为 · 把责任推给模型是绕开真正责任人——文档生命周期没同步,模型无非把它老实念了出来。
判断 2:CMS→向量库的"下架链路"必须接,光接"上架"是裸奔
一句话:大多数 RAG 项目只接了"上架同步",下架靠人工通知——人一忙就漏,监管不会等你想起来。
本次事故里翻 200 条已下架文档:187 条在 CMS 都标了"已下架",向量库一条都没删,metadata 里既没"是否生效"字段、也没"失效时间"字段。
关键在于 · 下架同步必须事件驱动 + 每小时定时兜底,不能依赖任何"人记得"的环节。
判断 3:黑名单兜底是事中止血、不是事前清理
一句话:query 命中"费率/合规口径"等高敏关键词,强制走人工或固定话术——改一份配置就全量铺开,1 小时上线监管能看到你在动。
但黑名单只挡得住"已知敏感词"的 query,挡不住用户换个问法绕过去,所以是兜底不是终局。
我的优先顺序是 · 第一小时黑名单止血、第一天清孤儿向量、第一周补状态字段、第一个月接反向工作流——越靠前越粗暴、越靠后越长效。
判断 4:metadata 必须带状态字段,检索时默认过滤
一句话:向量库不能只存 chunk 和 embedding,必须带三个状态字段——是否生效、生效时间、失效时间。
检索语句默认拼一句"只查生效中"——物理过滤模型根本看不到下架内容,prompt 劝阻模型看得到只是被建议。
我认为 · 合规要的是确定性,不是概率。能用 metadata 过滤的事,绝不交给 prompt。
四、面试官追问链
追问 1
"怎么证明这次真的是文档问题,不是模型自己编的?"
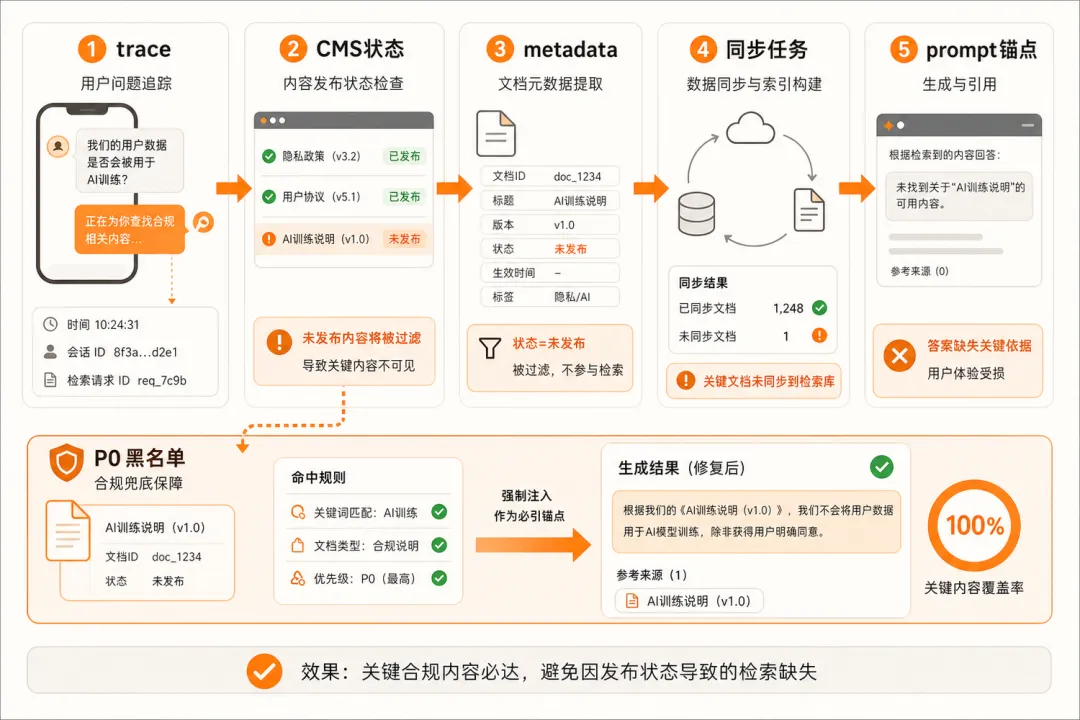
看 trace 里召回的文档来源就够。
如果 AI 引用的是真实文档而且原文里就有这句话,模型没编——是文档不该出现在候选里。反过来,如果检索根本没召回这条文档、答案却出现了这个口径,那才是模型幻觉。
判断方法 · trace 必须留 5 件东西——用户问题、召回的文档 id、文档片段原文、拼出来的 prompt、最终回答。少一项都没法定位。
追问 2
"黑名单兜底和 prompt 写'请遵守合规',哪个更可靠?"
黑名单可靠得多,三个理由:
① 位置——黑名单在检索之前判断,命中关键词的 query 根本不进 RAG 链路;prompt 是模型输入,模型有概率忽略。
② 可审计——黑名单命中率是确定性数字;prompt 是否生效只能靠抽样审。
③ 速度——黑名单 1 小时上;prompt 改完要跑回归才能上线。
定位方法 · 黑名单 + metadata 状态过滤 + prompt 时间锚点("以下材料截至 X 时间,以最新合规口径为准")三件套并行。
追问 3
"怎么向监管证明,这次事故不会再发生?"
三个数字盯每天:
① 下架到失效的延迟——CMS 标了下架到向量库不再召回,平均要几分钟(目标 5 分钟以内)。
② 孤儿向量数——源头已下架、向量库还在的,每小时核对一次(目标 0)。
③ 合规回归集通过率——准备 50 条"已下架文档对应的高危 query",每天跑一遍,必须 100% 不召回过期内容。
修复路径 · 三个数接到日报、阈值告警走值班;指标稳定 30 天,防线才算立住。
五、合规事故 4 步扛压实战
场景 · 金融客服 AI 周一上午 9:47 被监管点名,单条 trace 触发全链路复盘。下面是从止血到长效防线的完整 4 步动作。
第一步 · 第一小时上黑名单止血 · 把"费率""合规口径""利率"等高敏关键词丢进黑名单,命中的 query 强制走人工或固定话术。改一份配置就全量铺开。1 小时内监管能看到你在动。
第二步 · 第一天清孤儿向量 · 拉一份 CMS 已下架文档清单(这次是 187 条),反向到向量库批量删除对应向量。这一步把事故的物理根源消掉。4 小时内可以清完。
第三步 · 第一周补 metadata 状态字段 · 给向量库加三个字段——是否生效、生效时间、失效时间,把历史数据回填一遍。检索时默认拼一句"只查生效中"。这是结构性修复,不靠任何人记得。
第四步 · 第一个月接反向工作流 · 跟合规部门约定,他们在 CMS 下架文档时直接调一个接口触发"向量库删除"——事件驱动,不依赖人工通知,再加每小时定时核对兜底。真正的长效防线。
↳ 复盘数字
本次事故时间线(数据来源:内部事故复盘):监管反馈到根因定位 90 分钟,黑名单全量上线 1 小时,孤儿向量批量清理 4 小时,metadata 加字段 + 同步任务上线 2 周。事后 60 天,孤儿向量数稳定为 0,无重复事故。
六、本课总结
一句话总结
合规答错 9 成是文档治理事故、不是模型幻觉;第一小时黑名单止血、第一天清孤儿向量、第一周补 metadata 状态字段、第一个月让合规反向触发——四档动作做完,防线就立住。
面试锦囊
先说 · 排查顺序是文档治理在前、模型行为在后;90% 事故停在 CMS→向量库下架链路没接。
再说 · 时间窗顺序——第一小时黑名单、第一天清孤儿、第一周补字段、第一个月接反向工作流;越靠前越粗暴、越靠后越长效。
最后补 · 三个数字证明防线立住——下架到失效 5 分钟内、孤儿向量数 0、合规回归集每日 100% 通过。
判断清单
□ trace 里有没有留全 5 件东西(问题/文档 id/原文/prompt/回答)?
□ 向量库 metadata 是否有 是否生效/生效时间/失效时间 三个字段?
□ 检索语句默认是否过滤掉"非生效"的文档?
□ CMS 下架时是否有事件触发到向量库?是否还有定时核对兜底?
□ 下架延迟、孤儿向量数、合规回归通过率,三个数是否进了日报?
□ 黑名单兜底是否能 1 小时内全量铺开?
别再踩的坑
□ 把合规答错归到"模型幻觉"——错过文档治理这个真正责任人。
□ 只删 CMS 不删向量——孤儿向量是定时炸弹。
□ 用 prompt"请遵守合规"代替 metadata 过滤——建议不是约束。
□ 黑名单当唯一防线——它是兜底,不是事前清理。
下一道面试题
快手面试官:换 embedding 模型,旧向量怎么办?
