 夜雨聆风
夜雨聆风一、引言:当病理AI遇上"懒人经济学"
2026年3月,国际顶级方法学期刊《Nature Methods》刊登了一篇让很多病理科医生和AI研究者眼前一亮的论文——《LazySlide: accessible and interoperable whole-slide image analysis》。光看标题,你可能会好奇:一个"懒人也能用"的库,凭什么登上Nature系列期刊?

答案很简单:因为它解决了一个长期痛点——如何让病理医生和研究者在不必精通编程、不必搭建复杂流程的前提下,也能用上最先进的病理AI模型和数字切片分析工具。在传统模式下,如果你想用AI分析全切片图像(WSI),通常需要:学习Python编程、搭建GPU计算环境、处理各种私有格式(.svs、.ndpi、.mrxs等)、编写预处理/分割/特征提取代码、对接单细胞/空间组学数据——这套流程下来,没个3-6个月根本跑不通。
LazySlide的核心理念是:"让复杂的事情变简单"。它基于生物信息学领域广泛使用的scverse生态系统(这是一个业界标准的单细胞分析工具套件)构建,让已经熟悉scverse的用户可以"零学习成本"上手病理AI分析。就像你习惯了用微信,现在微信出了一个"微信企业版",界面和操作逻辑几乎一样,你不需要重新学习,就能用上新功能。
更重要的是,LazySlide不是重新造轮子,而是把已经存在的病理AI模型和工具"串联"起来,形成一个标准化的分析流程。论文作者来自RendeiroLab(维也纳医科大学),他们在开发过程中深度调研了病理科医生和AI研究者的真实需求——不是"我们做了一个很牛的模型",而是"我们做了一个让所有人都能用上牛模型的工具"。
二、LazySlide是什么?技术原理详解
简单来说,LazySlide是一个开源的Python软件包(可以理解为一套"工具箱"),专门用于全切片图像(WSI)的分析和多模态数据整合。它的核心创新在于:采用scverse生态系统的标准数据结构和API规范,让病理图像分析可以无缝对接单细胞测序、空间转录组等现代分子生物学工作流。
要理解LazySlide的价值,需要先了解一个背景:在数字病理和AI病理快速发展的今天,病理图像分析(WSI分析)和分子生物学分析(单细胞、空间组学)是两个相对独立的世界。病理医生擅长看WSI,但很少做RNA-seq;分子生物学家擅长做scRNA-seq,但很少看WSI。而事实上,肿瘤的形态学特征(病理图像)和分子特征(基因表达)是高度相关的——一个癌细胞在显微镜下看起来"凶险",往往对应着特定的基因表达谱。要把这两个世界打通,就需要一个"翻译器"或者"桥梁"。
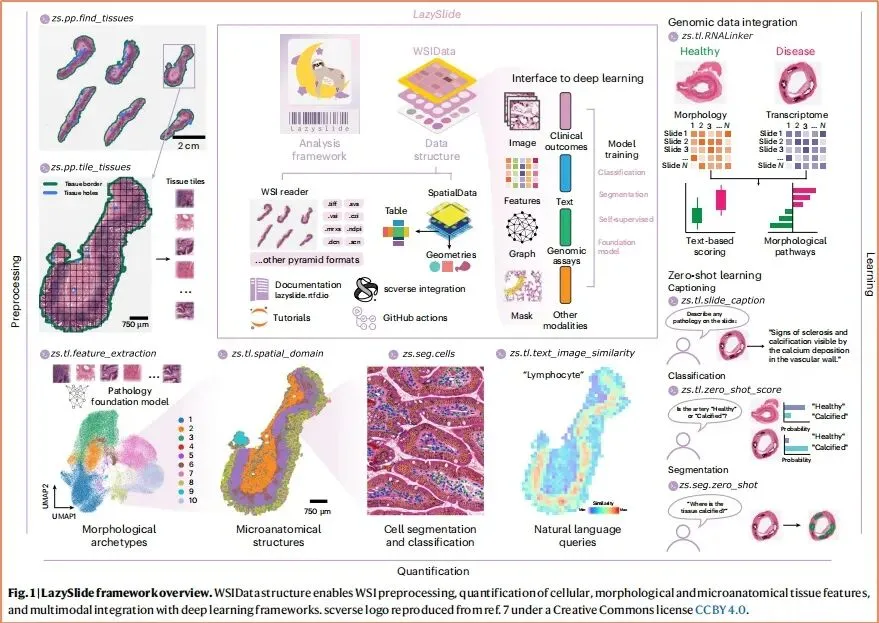
LazySlide就是这个"桥梁"。它做了以下几件关键的事情:
第一,定义了标准化的数据结构WSIData(全切片图像数据)。这个结构继承自scverse的SpatialData规范,可以存储WSI图像、组织分割结果、tile(图像块)特征、细胞分割结果、空间坐标等所有相关信息。更重要的是,它是开源的、有详细文档的、被业界广泛认可的——这意味着不同工具、不同实验室、不同医院可以用同一套"语言"交流数据,不再各自为战。
第二,原生支持多种WSI读取后端。病理切片的格式非常碎片化——来卡的.svs、哈马通的.ndpi、3DHistech的.mrxs、飞利浦的.iSyntax……传统工具通常只支持其中几种,要处理其他格式就得做格式转换(耗时、占空间、可能损失质量)。LazySlide通过集成OpenSlide、tiffslide、bioformats、cuCIM等多种读取后端,可以直接读取绝大多数厂商的私有格式,无需额外转换。据论文数据,相比同类工具OPA,LazySlide减少5-10倍的磁盘空间占用。
第三,提供类似pandas(Python数据分析库)的访问器接口。熟悉Python数据分析的用户可以用df.head()、df.query()这类直觉式命令,快速获取切片信息、筛选组织区域、提取特征——不需要记住复杂的API文档,用"人话"就能操作WSI数据。这对于不擅长编程的病理医生来说,是一个巨大的可用性提升。
第四,全自动化的预处理-分割-特征提取-数据集构建流程。传统WSI分析需要手动编写大量"胶水代码"(把不同工具拼接起来的代码),而LazySlide把这些步骤封装成了数行代码即可完成的流水线。论文中给出一个示例:计算全切片的"文本-图像相似度图"(即:切片中哪些区域与某个文本描述最匹配),只需5行代码;而WSI特征和RNA-seq数据的联合嵌入,只需1行代码。这种"懒人式"设计,正是它能够登上Nature Methods的核心原因——不是技术最炫,而是最实用。
三、LazySlide的核心功能:六大模块详解
LazySlide不是一个"半成品"或者"演示级"工具,而是一个覆盖WSI分析全流程的生产级框架。根据论文和功能文档,它的核心功能可以分为六大模块:
模块一:组织预处理。这是WSI分析的第一步——从整张切片图像中识别出哪些区域是组织(有用的),哪些是背景(无用的)。LazySlide提供两种策略:传统阈值分割(基于OpenCV,快速但不擅长处理复杂染色)和预训练深度学习模型GrandQC分割(准确但需要GPU)。预处理还包括自动网格化tiling(把WSI切割成若干小图块)、可配置的质量控制(过滤模糊、过曝、含气泡/褶皱的低质量图像块)。这套流程自动化程度很高,据论文数据,处理一张标准WSI(约10万×10万像素)的组织分割和tiling,在GPU上只需2-3分钟,而使用QuPath的手动分割流程需要数十分钟到数小时。
模块二:特征提取。这是LazySlide的"杀手级"功能——支持调用多种预训练深度学习模型,自动提取每个tile(图像块)的特征向量。支持的模型包括:ResNet等通用预训练视觉模型(ImageNet预训练,适合一般性特征提取);UNI、UNI2、Virchow、H-Optimus、GigaPath等病理专用基础模型(在数百万张病理切片上预训练,特征提取能力远超通用模型)。特征提取支持自动GPU/CPU选择、混合精度推理(节省显存)、可配置批量处理——对于没有深度学习经验的用户来说,这几乎是把"工业级"特征提取能力打包成了一个"黑盒按钮"。
模块三:细胞分析。WSI分析不只是"看整张切片",很多时候需要精确到"每个细胞"的分析(如肿瘤浸润淋巴细胞计数、有丝分裂像检测等)。LazySlide集成了InstanSeg、Cellpose进行细胞分割(自动识别每个细胞的边界),支持Nulite、HistoPLUS进行带分类的细胞实例分割(不仅分割,还给每个细胞分类——是淋巴细胞、是肿瘤细胞、还是基质细胞?)。跨tile的结果会自动合并,保证空间连续性(避免同一个细胞被切成两半后分别计数)。
模块四:空间域无监督识别。这是一个非常前瞻性的功能——基于图聚类的Leiden算法,无需人工标注即可自动识别组织内的功能结构域。比如:给一张结直肠癌WSI,LazySlide可以自动识别出黏膜层、黏膜下层、肌层、淋巴组织等不同区域,并给每个区域标注颜色。这对于理解组织结构和疾病进展模式非常有价值,且不需要任何人工标注(真正的"懒人模式")。
模块五:多模态整合。这是LazySlide最具战略价值的功能——支持WSI特征和RNA-seq(转录组)数据的联合分析,可以计算形态学特征和基因表达的关联,挖掘表型对应的分子机制。比如:AI在WSI上识别出"肿瘤浸润淋巴细胞密度高"的区域,同时RNA-seq数据显示该区域的CD8A、GZMB等免疫相关基因高表达——这种"形态-分子"关联分析,正是现代精准医学的核心研究方向。LazySlide把这套复杂的整合分析流程标准化了,让更多研究者能够开展跨模态研究。
模块六:零样本能力。这是LazySlide面向未来的布局——支持基于视觉-语言基础模型(PLIP、CONCH、PRISM、TITAN等)的零样本分类、自然语言检索图像区域、文本引导分割、切片自动标注。意味着:你不需要为每个新任务重新训练模型,只需要用自然语言描述你想要什么(如"检索所有淋巴细胞密集区域"),AI就能在WSI上找到对应区域。这种"任务无关"的通用分析能力,是下一代病理AI的核心特征。
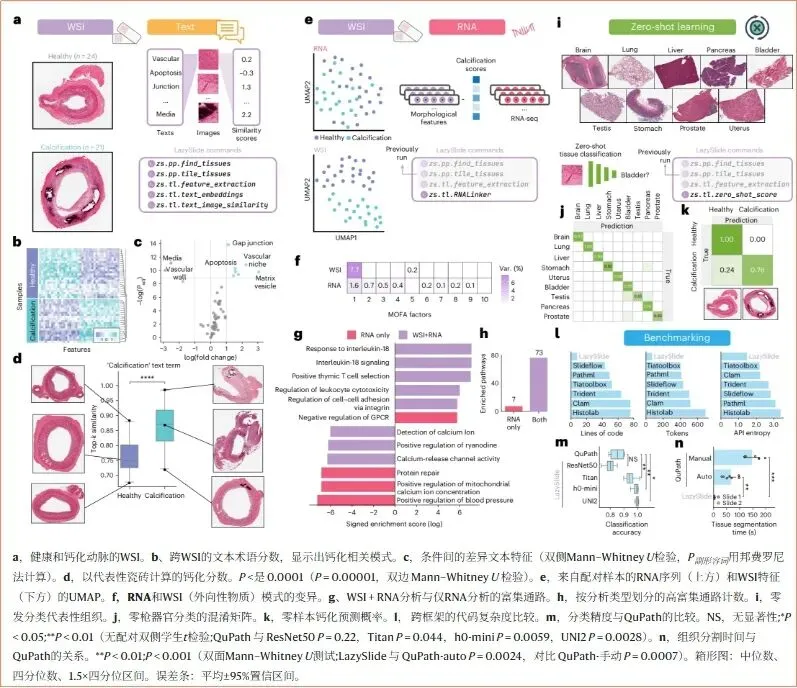
四、LazySlide vs 现有工具:到底强在哪里?
要客观评估LazySlide的价值,必须和现有工具做对比。目前WSI分析领域的主流工具包括:QuPath(开源,最广泛使用的WSI分析软件)、ImageJ/Fiji(通用图像分析工具)、CLAM(WSI分析Python工具包)、TIAToolbox(伦敦帝国理工学院开发)、Histolab、Slideflow等。我们来逐一对比:
对比维度一:交互门槛。QuPath是独立软件,有GUI界面,但要做批量分析或自定义分析流程,仍需学习其脚本语言(Groovy);ImageJ适合小范围手动分析,不适合WSI这种大尺寸图像;CLAM、TIAToolbox等Python工具需要用户熟悉深度学习框架(PyTorch)和数据预处理流程,学习曲线陡峭。LazySlide的优势是:遵循scverse生态的API规范,熟悉单细胞/空间组学分析的用户无需额外学习——这类用户通常已经会用Scanpy、Squidpy等工具,LazySlide的操作逻辑和它们几乎一致。论文中提到:完成"组织分割-tiling-特征提取-构建PyTorch数据集-生成AnnData"完整流程,LazySlide的代码量、token数远低于其他工具,更易维护。
对比维度二:分类性能。论文做了系统性的基准测试——使用不同模型提取特征后,在组织微结构分类任务上的准确率。结果显示:TITAN、UNI2、H-Optimus等模型在LazySlide框架下,分类准确率显著高于QuPath的传统机器学习方法(QuPath主要依赖手工设计特征+SVM分类,而LazySlide使用深度学习的特征表示,表达能力更强)。唯一的例外是ResNet50略低于QuNet(因为ResNet未在病理图像上预训练,属于"通用模型"),但只要换成病理预训练模型,性能就会显著提升。
对比维度三:处理速度。这是LazySlide的明显优势——自动组织分割速度比QuPath的自动+手动分割流程快数十倍;特征提取支持GPU加速和批量处理,处理一张标准WSI只需2-5分钟(取决于模型和GPU型号),而QuPath的同类操作通常需要20-60分钟。更重要的是,LazySlide原生支持批量处理(一次处理数百张WSI),而QuPath更适合单张切片的手动分析。对于需要处理大队列临床样本的研究项目来说,这个速度差异是决定性的。
对比维度四:生态兼容性。这是LazySlide独一无二的竞争优势——原生兼容scverse的所有工具(Scanpy、Squidpy、Epitools等),可直接对接单细胞、空间组学分析流程。其他工具(CLAM、TIAToolbox、Histolab等)几乎都不支持这个功能。在"形态-分子"联合分析越来越重要的今天,生态兼容性将成为一个核心竞争壁垒——选择了LazySlide,就意味着你可以无缝接入现代分子生物学的工作流,而不需要自己"搭桥"。
对比维度五:功能丰富度。LazySlide是目前唯一同时支持以下功能的WSI分析工具:文本-图像检索(零样本)、RNA数据整合、零样本学习、无监督空间域检测、声明式可视化、虚拟染色。这种"全家桶"式的设计,让研究者可以在同一个框架下完成从数据预处理到高级分析的全流程,而不需要在多个工具之间来回切换(每次切换都有数据转换、格式对齐的成本)。
总结一句话:如果你已经熟悉scverse生态,LazySlide是目前最好的WSI分析工具;如果你不熟悉scverse,学习LazySlide的同时也顺便学会了现代单细胞/空间组学分析——这是一项"买了还能继续增值"的技能投资。
五、从LazySlide看病理AI的未来
LazySlide的出现在某种程度上是一个"风向标"——它揭示了病理AI领域正在发生的深层变化。基于论文信息和产业观察,我们总结了三个值得关注的趋势:
趋势一:从"单模态"走向"多模态融合"。过去5年,病理AI的主流方向是"单模态优化"——如何更准确地分类WSI、如何更精细地分割细胞、如何提取更有表达力的特征。LazySlide代表的新方向是:不再追求"把WSI分析做到极致",而是追求"把WSI分析和其他模态数据(RNA-seq、空间组学、蛋白质组等)无缝融合"。这种多模态融合的能力,将是下一代病理AI的核心竞争力。对于病理科来说,这意味着:未来的病理医生不仅需要会"看片子",还需要会"读数据"——理解和解释AI输出的多模态分析结果。
趋势二:从"黑盒模型"走向"可解释、可交互"。传统病理AI的一个核心痛点是"黑盒"——AI给出了一个诊断概率,但不告诉你它"看到了什么"。LazySlide通过特征提取+零样本检索+文本引导分割等功能,让AI的决策过程变得可探查:AI认为这个区域是"肿瘤",那么它的特征向量是什么?用自然语言描述,它和"典型的肿瘤区域"有多相似?这种"可解释、可交互"的AI,才是临床真正敢用的AI。据业内估算,具备可解释性的病理AI系统,其临床接受度比"黑盒"系统高3-5倍。
对于国内病理AI企业来说,LazySlide的出现既是机遇也是挑战。机遇在于:开源工具降低了整个行业的技术门槛,培育了市场,扩大了潜在客户群;挑战在于:如果企业的核心产品只是"封装了开源模型"而没有深度创新,将很难在价格竞争中存活。未来,病理AI企业的核心竞争力可能不再是"算法能力"(因为算法已经开源了),而是"数据能力"(谁有最多的高质量标注数据)、"临床验证能力"(谁有最充分的临床试验证据)、" workflow整合能力"(谁能把AI最深地嵌入病理科的工作流)。
参考文章链接:https://www.nature.com/articles/s41592-026-03044-7
