 夜雨聆风
夜雨聆风
编者按:近日,中关村两院信息智能团队联合中国科学技术大学、南开大学、中国科学院、清华大学等多家高校与科研机构,围绕“让AI Agent从真实世界反馈中学会预测未来”推出两篇工作:FutureWorld 与Milkyway。前者把Live Future Prediction(实时未来预测)任务做成可持续运行的强化学习环境与daily benchmark(每日评测基准);后者进一步利用待预测事件结果揭晓前的时间演化信号,让 Agent 在等待最终结果的过程中也能改进自己的预测。
FutureWorld 论文网址:https://arxiv.org/abs/2604.26733
Milkyway 论文网址:https://arxiv.org/abs/2604.15719
Live Future Prediction(实时未来预测)
所谓Live Future Prediction(实时未来预测),是指在真实世界事件尚未发生、答案尚不存在时,让智能体基于公开信息作出预测;等事件随后发生并有公开结果后,再用真实结果检验预测是否准确。这里的 “Live” 指的是一套真正随现实世界动态变化而推进的预测流程:智能体不是在固定题库中回答已有答案的问题,而是在事件尚未发生、答案尚不存在时,实时联网搜索公开信息并作出判断;等真实结果公布后,再用这些结果检验预测表现。
举例来说,可以在2026年5月上旬提出一个问题:“中央广播电视总台是否会在2026年世界杯开幕前,与国际足联就中国大陆地区转播权达成协议并公开宣布?”当问题被提出时,结果还没有发生,最终答案也尚不存在。智能体需要实时联网搜索国际足联公告、央视公开信息、体育媒体报道以及相关市场分析,在转播权价格、谈判进展、赛事临近程度等公开信息基础上作出判断。
从评测预测能力,到训练预测型智能体
已有研究已经推动了未来预测评测基准的发展,也开始探索利用历史已知结果的问题训练预测模型。但在论文看来,现有方法还没有真正形成一个完整的训练闭环:问题要持续来自真实世界,反馈要直接来自最终结果,智能体如何搜索信息、分析证据、作出判断,都应成为训练过程的一部分。FutureWorld 要做的,正是把这一整套过程变成一个可以持续运行的训练环境。
FutureWorld:让智能体从真实结果中学会预测
论文《FutureWorld: A Live Reinforcement Learning Environment for Predictive Agents with Real-World Outcome Rewards》把“预测未来”变成了一个可以持续训练智能体的真实环境。系统会持续从公开网络来源中获取真实世界里的待预测事件,把它们整理成预测问题,并要求智能体判断相关事件发生的概率。智能体在作答前必须先进行网页搜索,基于公开信息完成分析,再给出自己的概率预测。整个过程中,系统会记录它搜索了什么、看到了什么、如何推理,以及最终给出了怎样的判断。等到事件结果公布后,FutureWorld会根据真实结果计算奖励,并把完整预测轨迹用于强化学习训练。

实验一:连续多天训练带来稳定预测性能提升
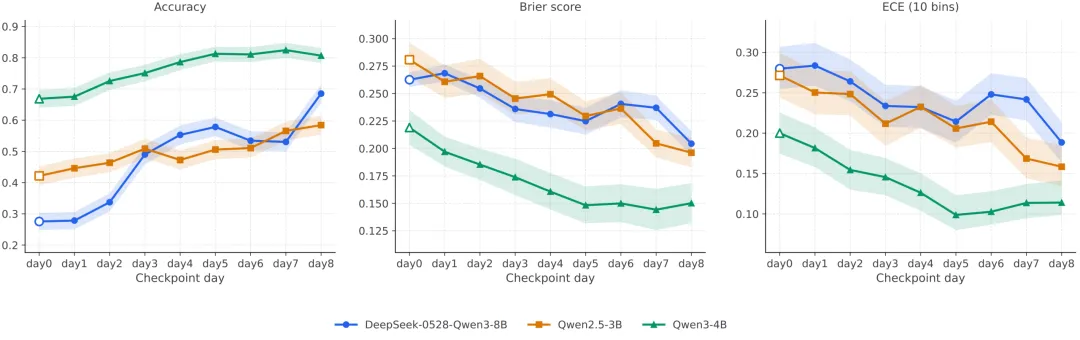
图2:在连续多天训练下,三个开源智能体在准确率、Brier score 和 ECE 上呈现整体改善趋势。
实验二:训练收益并不局限于单一领域
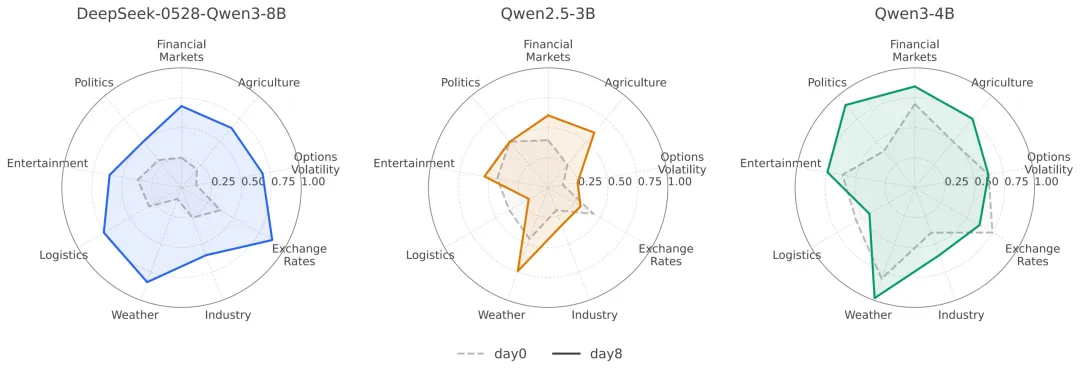
图3:训练前后在不同领域上的预测表现对比,day8 checkpoint 在多数领域取得更好结果。
实验三:超越二分类题型的泛化能力
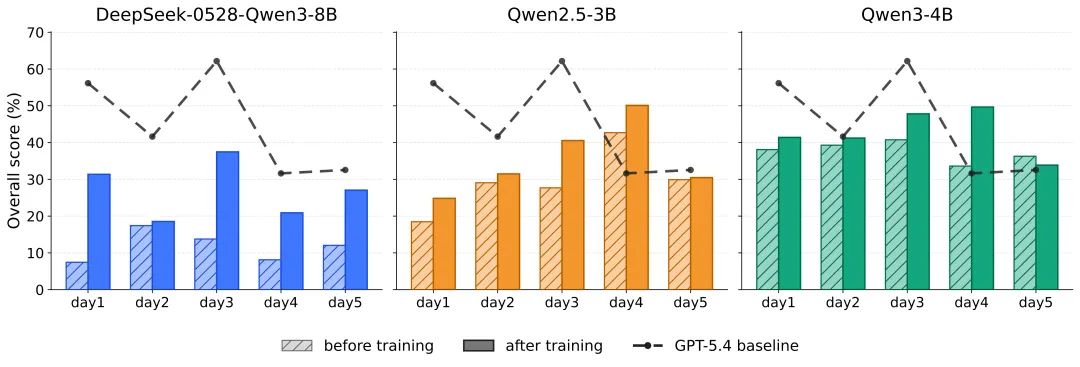
在训练阶段,论文主要使用“事件是否会发生”这类预测问题:系统把尚未发生的真实世界事件整理成二元问题,让智能体判断事件发生的概率,而不是简单回答“会发生”或“不会发生”。为了检验训练得到的能力是否能够延伸到更多样、更为通用的预测场景,研究团队进一步设计了FutureWorld daily benchmark(FutureWorld 每日评测基准)。该基准题目每天更新,单日最多包含50道题,覆盖二元选择题、简单多选题、困难多选题和数值预测四类题型。
连续五天的评测结果显示,三个智能体在经过 FutureWorld 训练后,整体表现均优于训练前。这说明,FutureWorld 训练带来的提升并不是对单一题型的过拟合,而是反映了模型通用预测能力的增强。
Milkyway:在答案揭晓前学习预测未来
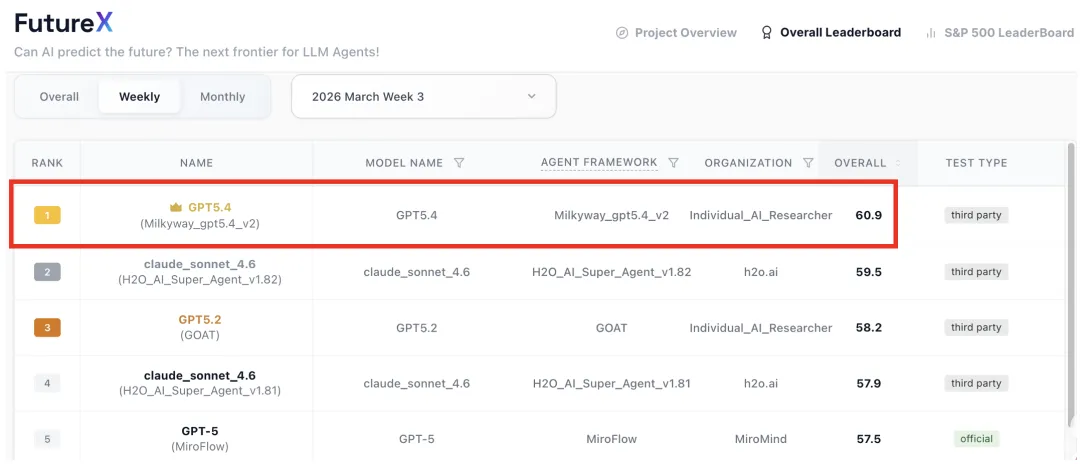
图5:Milkyway 在 FutureX 2026年3月 Week 3 overall leaderboard 中位列第一。
为什么“预测未来”不是更难一点的问答
Future Prediction的难点,不只是问题更复杂,也不只是搜索范围更大,而在于它的任务结构与标准问答不同。普通问答通常默认答案已经存在,系统的主要工作是搜索、阅读和交叉验证;而预测未来时,答案尚未发生,公开证据也仍在变化。
• 答案缺席,反馈极慢:预测发生时不存在可直接检索的标准答案,最终结果往往要滞后很久才出现。
• 证据持续变化:今天看不到的信号,明天可能出现;今天仍然模糊的迹象,后天也许会变成关键证据。
• 最终反馈粗糙:outcome主要告诉系统最后对不对,却很难说明当初漏掉了哪个变量、该监控哪个来源、何时应该保留不确定性。
因此,Future Prediction的挑战不是“更难的搜索题”,而是process-level credit assignment:当最终反馈又晚又粗时,系统如何尽可能可靠地判断,并知道预测过程该如何改进。
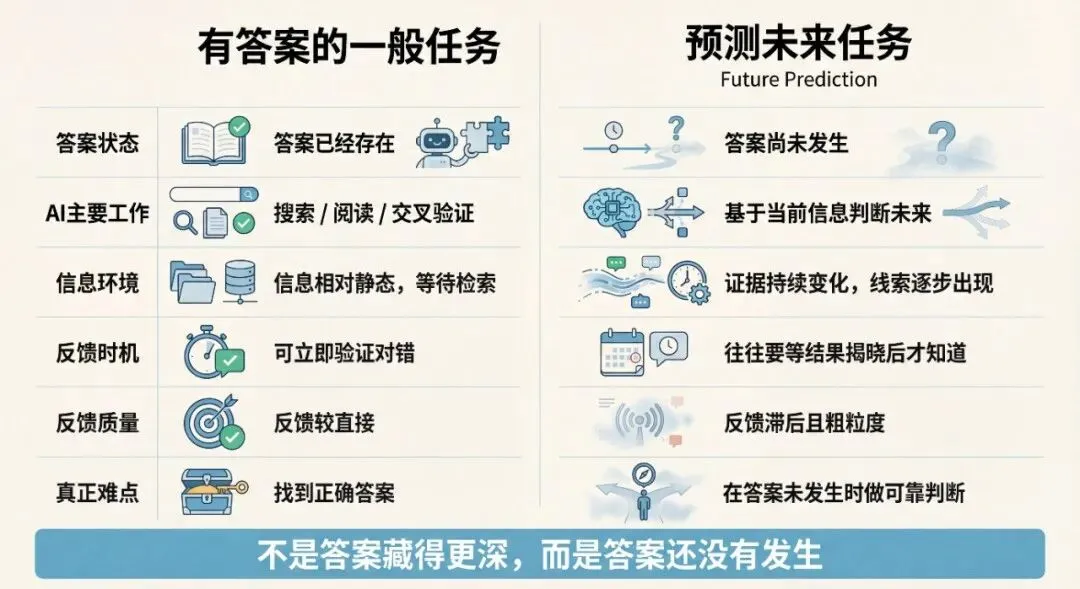
图6:有答案的一般任务与未来预测任务的结构差异。
核心洞察:时间本身可以成为监督信号
Milkyway:不改模型参数,而是进化“预测框架”
基于这个洞察,论文提出了一个能自我进化的架构:Milkyway。在本文设置下,Milkyway不通过更新底层模型参数来适应同一问题的后续预测,而是让固定的 BaseAgent 搭配一个受约束、可编辑、可复用的外部状态:Harness state。这个Harness可以理解为一份动态更新的预测操作手册,但它不是自由写入的记忆库,也不是把答案或原始证据塞进去。

Harness主要包含三个维度:Factors关注该看什么,帮助系统持续跟踪重要变量;Evidence关注去哪里看、怎么看,帮助系统判断证据是否真正匹配题目的 resolution criterion;Uncertainty关注何时下注,提醒系统在关键信息尚未出现时保持谨慎,在信号足够清晰时果断修正判断。
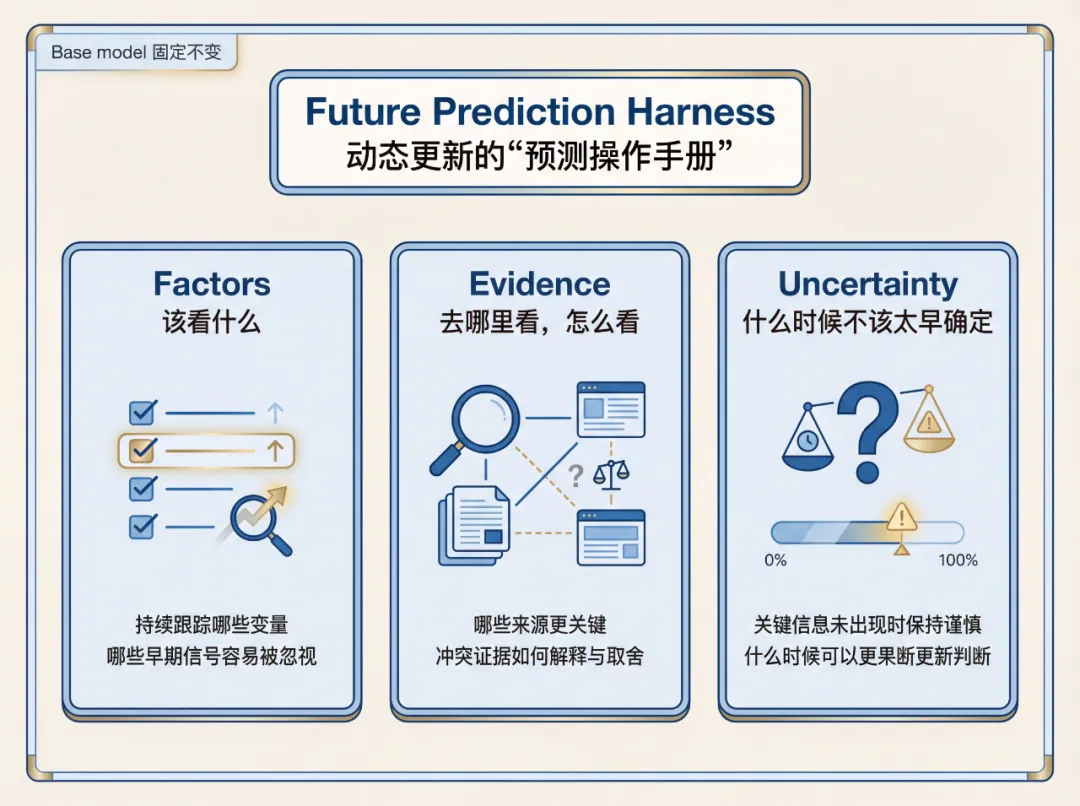
图8:Future Prediction Harness 的三个核心维度:Factors、Evidence 与 Uncertainty。
Milkyway 如何更新
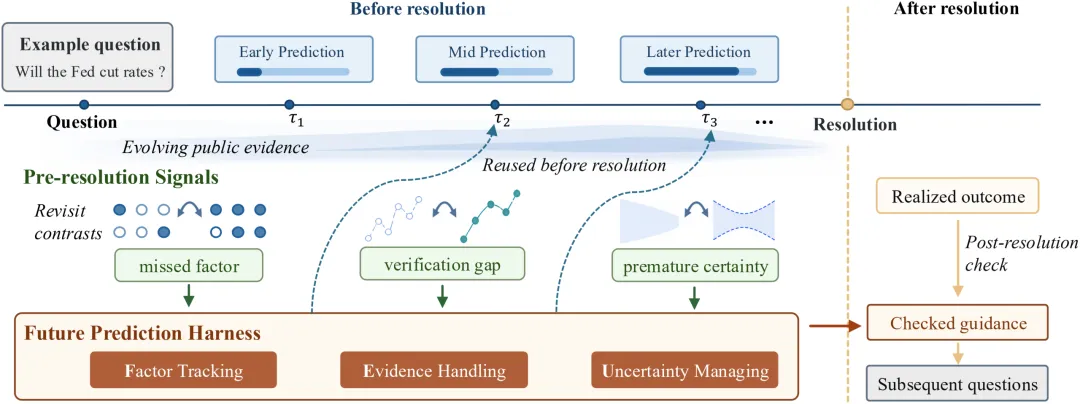
Milkyway的核心工作流可以概括为:当前Harness指导一次预测,系统生成 checkpoint note;随后从同一问题的时间差异中提取内部反馈,写入 bounded patch;下一次checkpoint再复用更新后的Harness。
具体来说,当系统在某个checkpoint上对尚未解决的问题做预测时,BaseAgent会在当前Harness的指导下完成证据搜索、分析和判断。任务结束后,系统记录的不仅是一个预测值,还会生成一份精炼的checkpoint note,说明这一轮看到了什么关键信息、判断逻辑如何变化、当前还存在哪些风险。
接着,系统会把这份新笔记与之前同一问题的笔记进行对比:后来看到了什么是前面完全没意识到的;判断为什么发生修正;前面有哪些地方因为证据不足而过早下结论。由此得到的可复用经验会被写入Harness,供下一次预测调用。
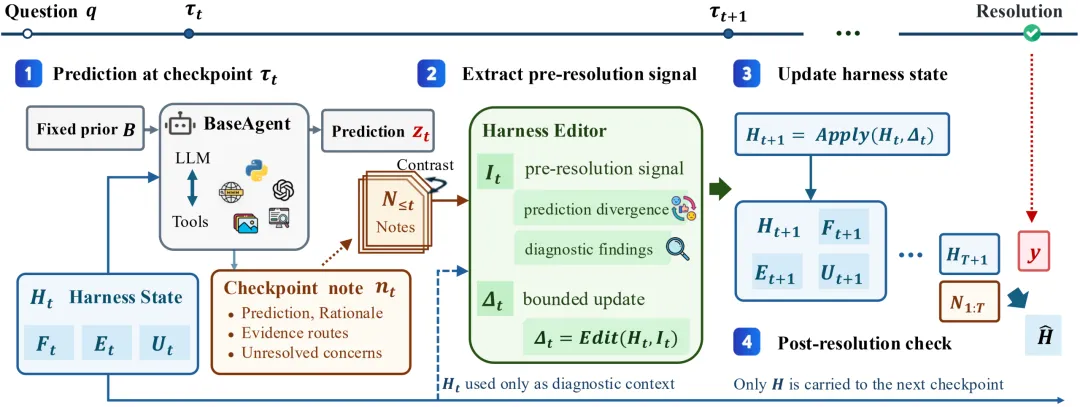
实验结果:越接近结果揭晓,Internal Feedback 越有价值
在论文报告的评测协议下,Milkyway在 FUTUREX和FUTUREWORLD的 overall score 上领先对比方法。结果显示,typed harness与bounded edits 并不是简单增加一段记忆,而是把同一问题在不同checkpoint中暴露出的过程信号转化为后续预测可复用的指导。
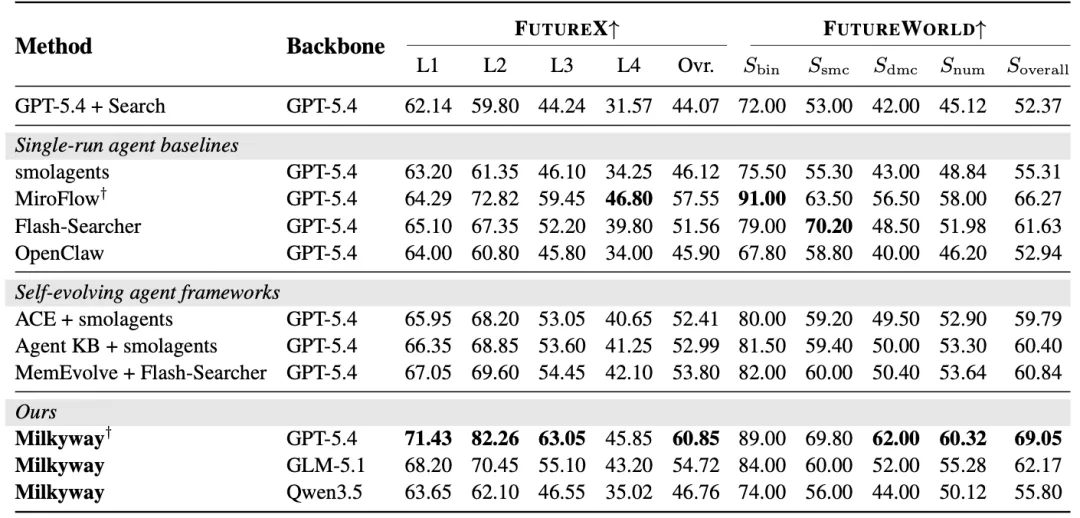
机制实验
为了验证提升来自pre-resolution writeback,而不是重复调用或普通记忆,论文构造了三组matched conditions:NH(No Harness)不保留 question-local persistence,只测 repeated forecasting;GH(Generic Harness)保留同等 byte/write-call budget 的 free-form memory blob;FH(Full Harness)使用 Milkyway 的 typed F/E/U harness 和 bounded edits。
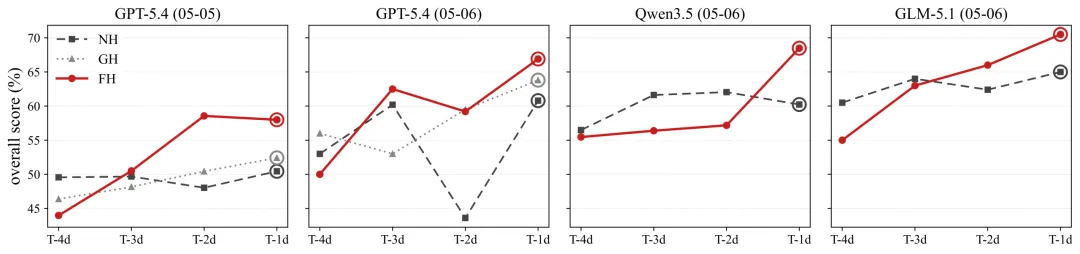
图11:机制实验中的 pre-resolution score trajectories。FH 的优势在 writeback 可被后续 checkpoint 使用后逐渐拉开。
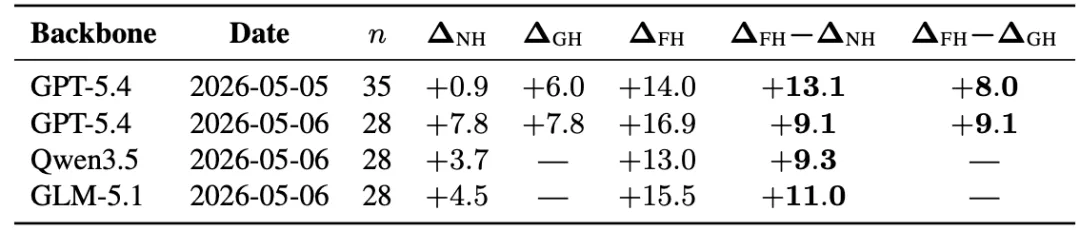
图12:T-4d 到 T-1d 的 endpoint improvement 对比,FH 相比 NH/GH 带来更高增益。
这些结果对应T-4d 到T-1d的endpoint improvement。更关键的是,FH的优势不是一开始就出现,而是在writeback能够被后续checkpoint使用后逐渐拉开。这与论文的机制假设一致:pre-resolution signal 被写入typed harness,随后改变后续预测过程。论文还做了compute-matched check 与 same-day repeated-rounds control,说明提升不能简单归因于更多工具调用、更多prompt token,或同一天重复运行。
两个案例:Harness 改变的是证据路线
FutureWorld与 Milkyway系列工作的作者团队为中关村人工智能研究院副院长、北京中关村学院AI Core学部郑书新副教授带领的信息智能团队,第一作者为北京中关村学院在读博士生魏楚扬(Milkyway)、韩之信、张延智(FutureWorld 共同一作),通讯作者包括中关村两院段易通研究员,施宇研究员,何纪言研究员等,合作单位包括中国科学技术大学、南开大学、中国科学院、清华大学交叉信息研究院等。团队专注于大模型与智能体前沿研究,涵盖架构优化、长上下文推理、协同演化及归因分析,同时立足金融、社会模拟等垂直场景。中关村两院旨在通过技术创新,赋予大模型深层逻辑与行业理解力,加速迈向通用人工智能。

