夜雨聆风
夜雨聆风
上个月,我花了整整一个下午试图复刻一条爆款口播视频。
过程是这样的:先暂停播放、逐帧截图,把文案一句句敲下来,再花半小时改写成自己的版本,接着用配音工具生成语音,然后把语音和数字人素材丢进剪辑软件对口型,对不上就一帧帧调,最后导出、加字幕、上传——一条60秒的视频,我前后折腾了4个小时。
发出去之后,播放量只有三位数。
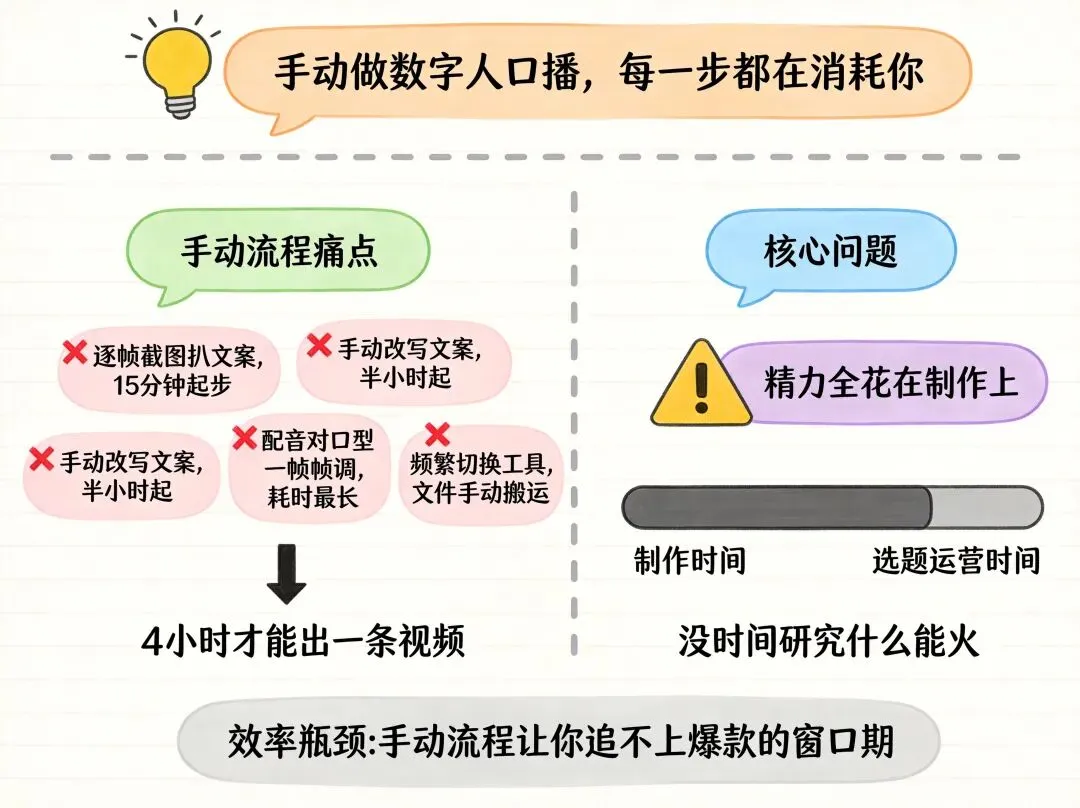
那一刻我意识到,问题不只是视频没火,而是这条路本身就走不通:手动做数字人口播,每一个环节都在消耗你的时间和耐心,你的精力全花在了"制作"上,根本没有余力去研究什么选题能火、什么钩子能留住人。
直到后来我试了即时AI,才发现这件事可以完全换一种做法。
即时AI的核心逻辑很简单:你不需要从零开始做视频,你只需要找到一条已经火了的视频,然后一键"追爆"。
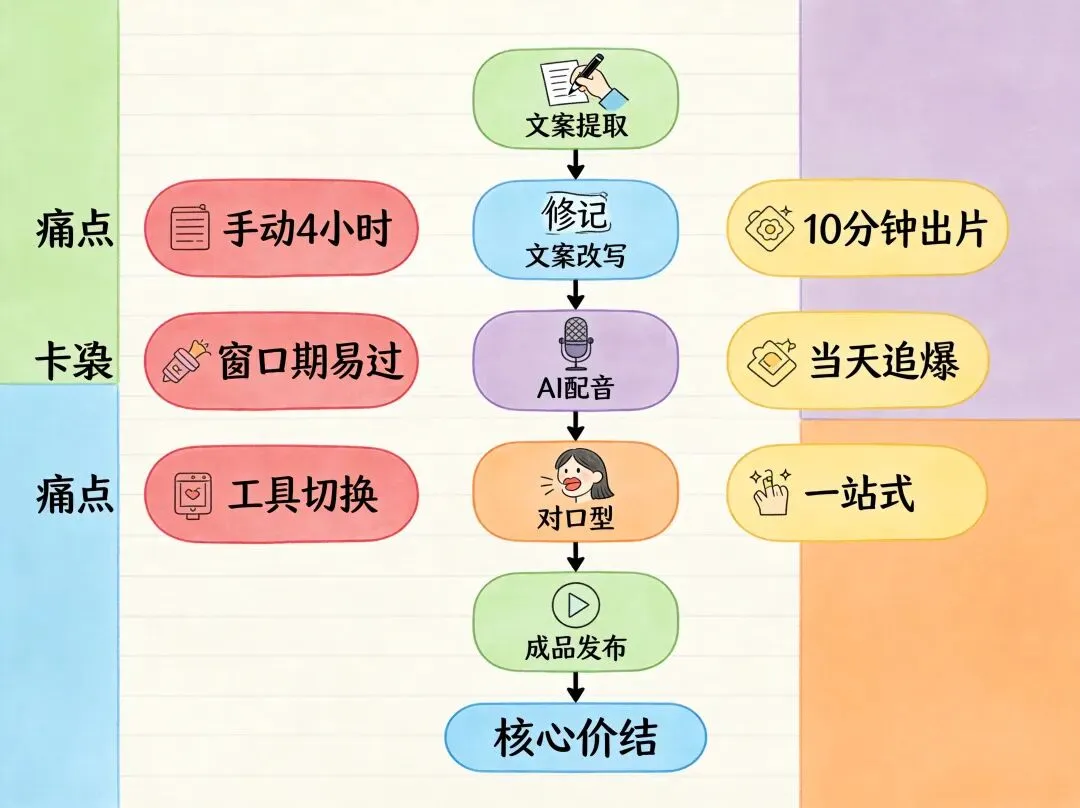
整个流程被压缩成了5步:爆款视频文案提取 → 文案改写 → 配音 → 数字人对口型 → 成品发布,一站式搞定。每一步之间不需要切换工具、不需要手动搬运文件,前一步的输出直接是下一步的输入。
说实话,第一次跑完这个流程的时候,我有点不敢相信——从粘贴一条视频链接到拿到成片,我前后只花了不到10分钟,而我之前手动做同样的事情要4个小时。
让我把这5步拆开来说说我的实际体验。
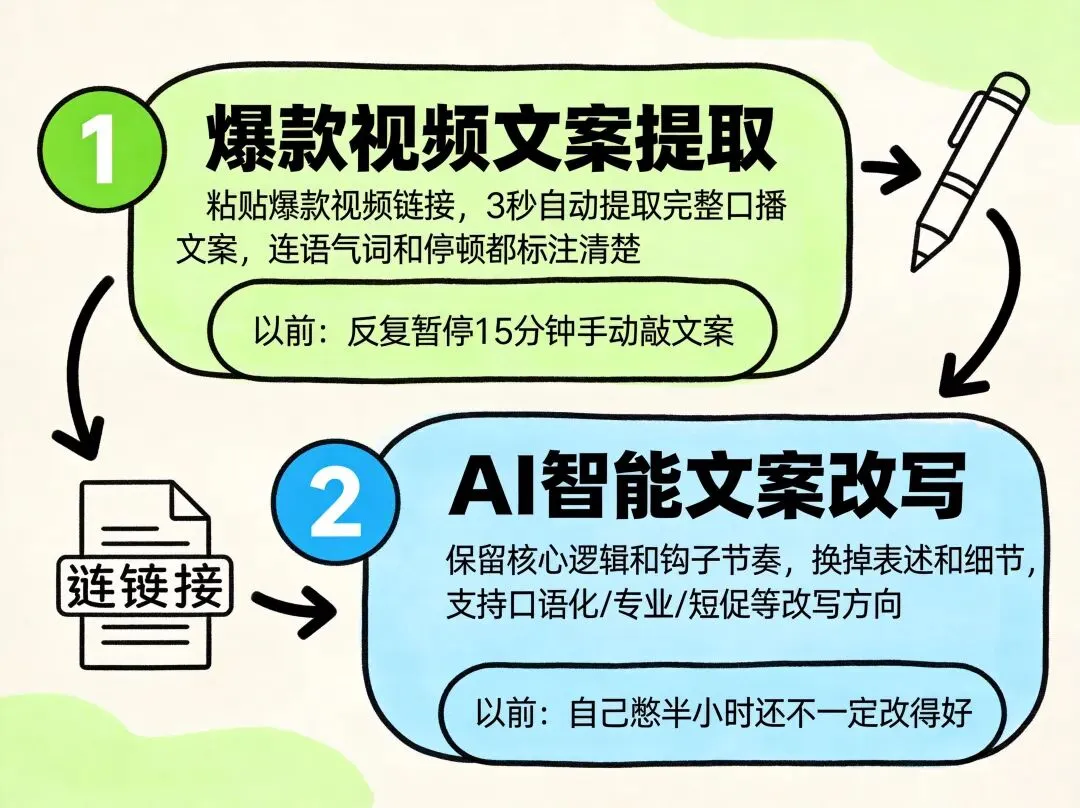
第一步是"爆款视频文案提取"。你只需要把目标视频的链接丢进去,系统会自动把视频里的口播文案完整提取出来。以前这一步我得反复听、反复暂停,一条1分钟的视频至少花15分钟才能把文案敲完,碰上语速快的博主还得倒回去听好几遍。现在?链接一贴,3秒出结果,连语气词和停顿都给你标得清清楚楚。
第二步是"文案改写"。提取出来的原文直接进入改写环节,AI会帮你把别人的文案改写成你自己的版本——保留核心逻辑和节奏,但换掉表述和细节,避免撞车。你可以指定改写方向,比如"更口语化""更专业""更短促",也可以让它保留原版的钩子结构,只换掉中间的干货内容。我试过直接用原版文案改,也试过只提取选题方向完全重写,效果都比我之前自己憋文案快得多。
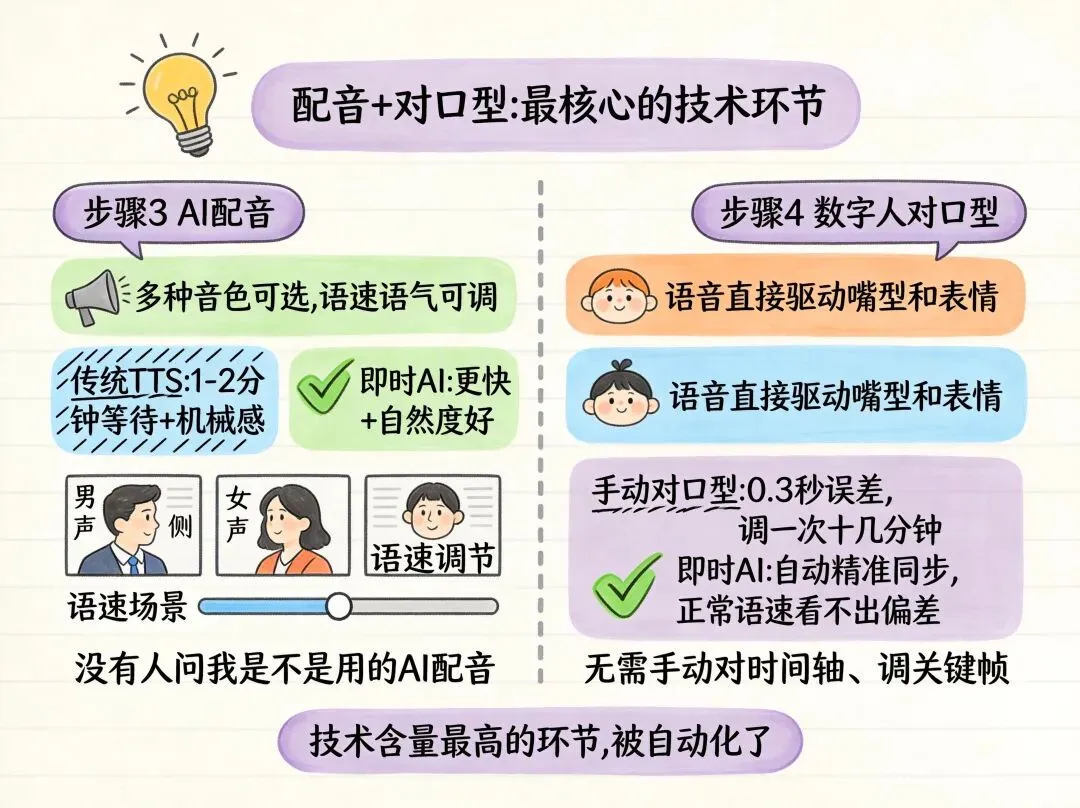
第三步是"配音"。改写好的文案直接进入语音合成,多种音色可选,语速和语气也能调。之前我用别的配音工具,生成一条语音大概要等1-2分钟,而且音色听起来总有点"AI味"。即时AI的配音速度更快,关键是自然度好不少,没那么明显的机械感,至少我发出去之后没人问我"你是不是用的AI配音"。
第四步是"数字人对口型"。这一步是整个流程里技术含量最高的——语音生成后直接驱动数字人的嘴型和表情,不需要你手动对时间轴、调关键帧。我之前用剪辑软件对口型,嘴型和声音差0.3秒就能看出来,调一次要十几分钟。即时AI的口型同步做得相当精准,至少在正常语速下,我反复看了几遍都没发现明显的嘴型对不上的情况。
第五步是"成品发布"。视频生成后直接导出,横屏竖屏都支持,拿去发抖音、快手、视频号、小红书都没问题。从提取文案到拿到成片,整个流程跑下来就是一气呵成的,中间没有需要你手动介入的环节。
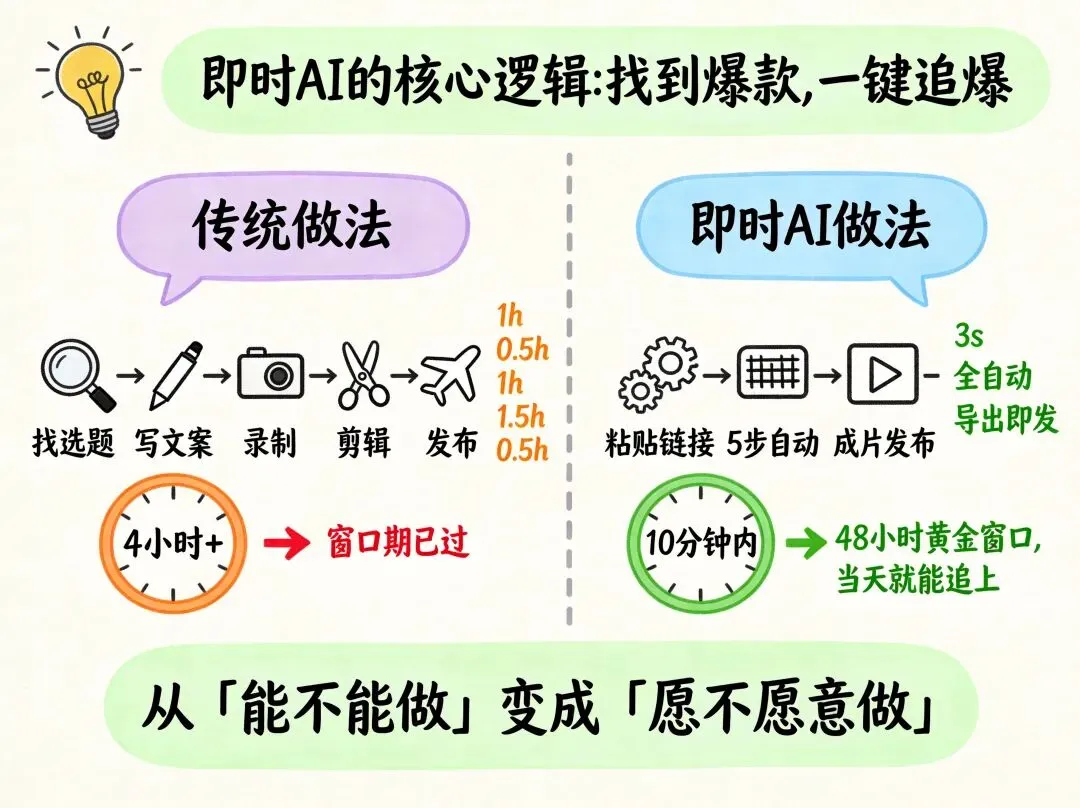
这5步走完,我算了一笔账:以前手动做一条数字人口播,4小时起步;用即时AI,10分钟以内。效率差了20倍不止。
但效率高不是重点,重点是这套流程解决了"追爆"的问题。
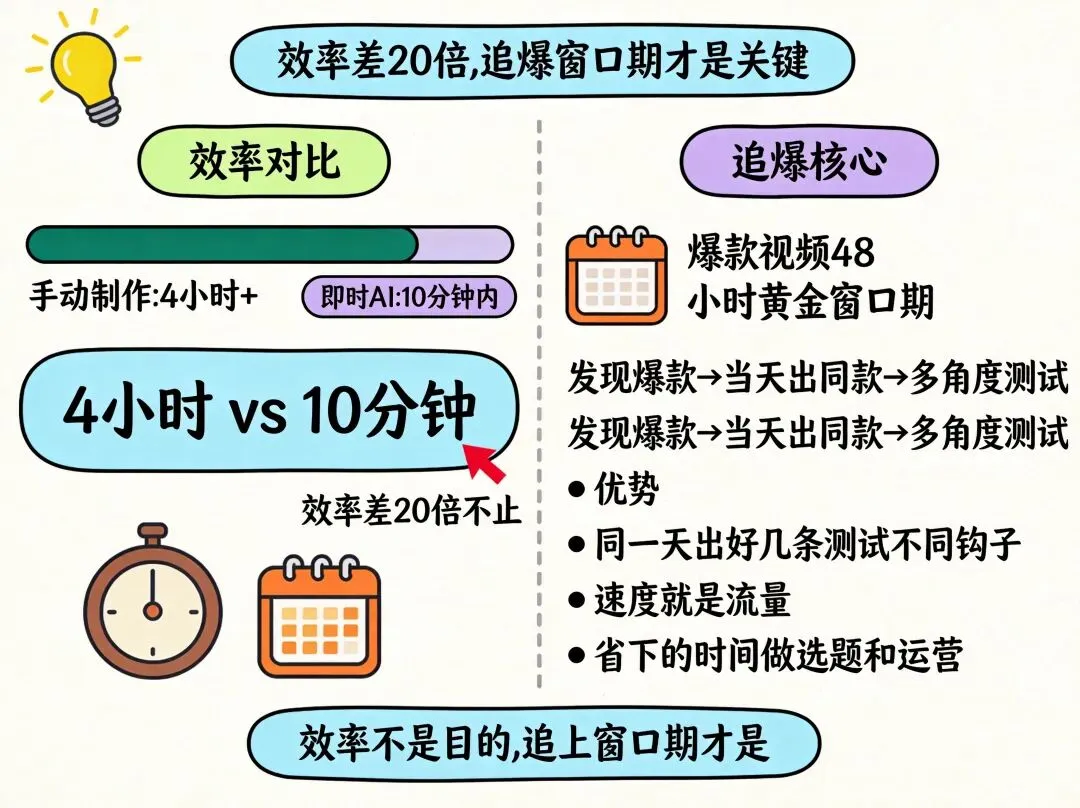
做短视频的人都知道,追爆的核心是速度——一条视频火了,48小时内是黄金窗口期,越早跟上越容易吃到流量。问题是手动做视频太慢了,等你把文案扒下来、改完、配好音、做好数字人,窗口期早过了。即时AI的5步流程把时间从小时级压缩到分钟级,这意味着你看到爆款视频,当天就能出同款,甚至同一天出好几条,测试不同角度、不同钩子。
当然,这工具也不是没有让我想吐槽的地方。
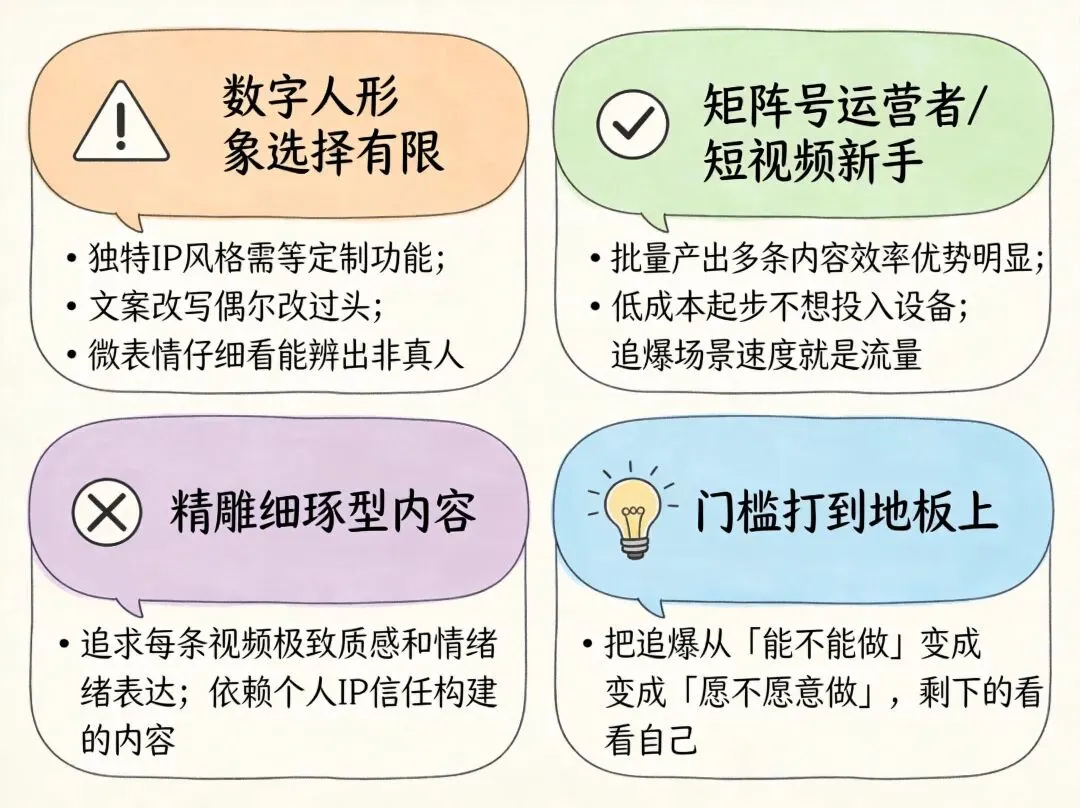
比如数字人形象的选择目前还不够多,如果你想做比较独特的个人IP风格,可能需要等后续定制功能上线。再比如文案改写有时候会"改过头",把原文里一些亮眼的表达也给换掉了,需要你自己再手动调回来。还有一点,视频的微表情——比如眨眼、轻微皱眉这些细节,仔细看还是能分辨出不是真人,不过放在手机屏幕上刷过去,大多数观众不会注意到。
说到底,即时AI解决的不是"做出一条完美视频"的问题,而是"快速、批量、低成本地做出够用的视频"的问题。它的价值在于让你把时间花在更重要的事情上——选题、定位、运营策略,而不是在剪辑软件里对着时间轴一帧帧磨。
如果你是做矩阵号的运营者,每天要产出多条内容,即时AI的效率优势会非常明显。如果你是刚开始做短视频的新手,不想一上来就投入大量设备和时间,它也是个不错的起步工具。但如果你追求的是每一条视频都精雕细琢、靠画面质感和情绪表达打动人,那手动拍摄+精细剪辑仍然不可替代。
我的判断是:即时AI把数字人口播视频的门槛打到了地板上,让"追爆"这件事从"能不能做"变成了"愿不愿意做"。剩下的,就看你自己了。
你用过数字人做口播视频吗?最头疼的是哪个环节?评论区聊聊。