 夜雨聆风
夜雨聆风今天刷 X 的时候,我看到几条 AI 工具更新。
Claude Design 的 token limit 翻倍。Claude 在 Code with Claude London 上发布 self-hosted sandboxes 和 MCP tunnels。Open Design 开始接入 Codex,还把几百个 templates、skills、design systems 打包进设计工作流。另一边,llama.cpp 支持 Qwen3.6 的 MTP,本地模型速度继续往上爬。中文圈里,SEO Audit Skill、学术研究 Skill、微信读书 Skill,也开始被越来越多人转发。
单看每一条,都像普通产品迭代。
但如果把它们放在一起看,我觉得味道变了。
这不是“又多了几个 AI 工具”。这是 AI 工具开始争夺“执行权”的信号。
过去两年,我们问 AI 的问题是:哪个模型更聪明?哪个回答更像人?哪个写文章更自然?哪个写代码更快?
这些问题当然重要,但它们本质上还停留在“回答权”阶段。也就是说,AI 主要负责给你答案、建议、方案、代码片段、灵感和解释。
下半场,问题变了。它能不能接入我的文件?能不能调用工具?能不能在安全环境里执行?能不能把设计、代码、浏览器、数据库放进同一个上下文?能不能留下日志,方便我接管?能不能部署在企业自己的环境里?
说得再直白一点:
AI 的上半场,是模型争夺回答权;AI 的下半场,是系统争夺执行权。
这件事,对普通人、产品经理、企业老板、AI 从业者都很重要。因为如果你还只盯着“哪个模型回答更好”,你很可能会错过真正的变化。
真正的变化不是聊天窗口变聪明了。真正的变化是,AI 正在从一个“回答问题的东西”,变成一个“进入现场的系统”。
工具负责回答,系统负责交付。
01
我们过去两年,可能误会了 AI 工具
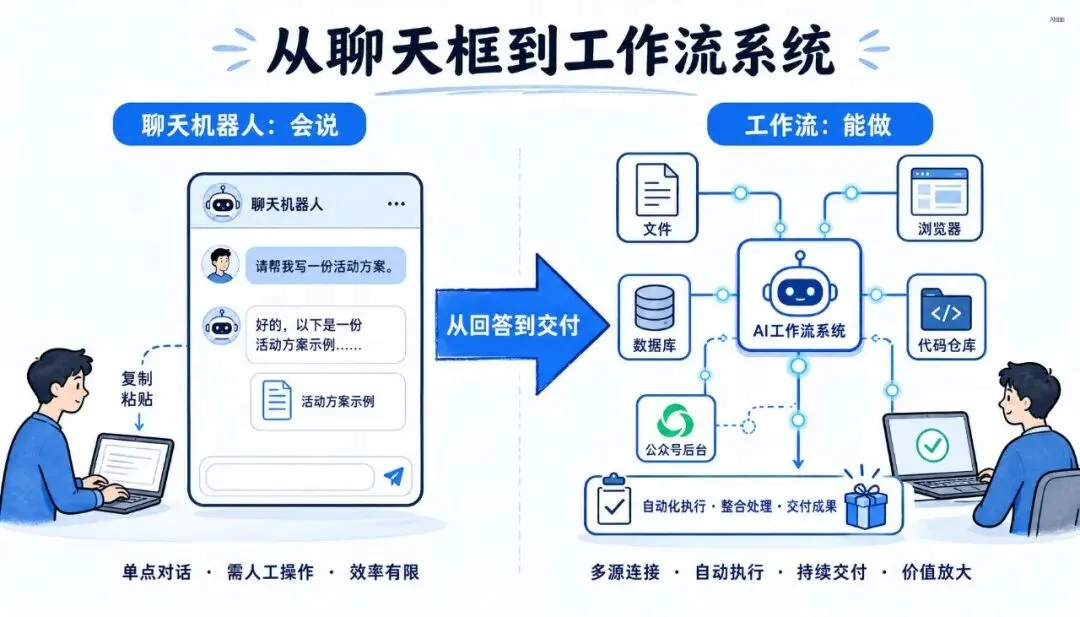
过去两年,大家评估 AI 工具的方式很简单。
拿一个问题问 ChatGPT,再拿同一个问题问 Claude、Gemini、DeepSeek、Kimi,然后比较谁回答得更长,谁逻辑更顺,谁更像人。
这当然有用。
但问题是,这套评估方式,本质上还是 Chatbot 时代的体系。
Chatbot 时代,AI 的核心产品形态是对话框。你说一句,它回一句。你多问几句,它多答几句。它像一个坐在你旁边的高智商实习生,懂很多,但你不让它动手,它就只能说。
这就是为什么很多人用了一圈 AI 之后,会产生一种微妙的疲惫感。
刚开始很震撼。后来开始麻木。再后来会发现,AI 好像什么都能说,但很多事还是要自己做。
你让它写方案,它写了。你还要复制到 Word 里改格式。你让它分析竞品,它给了框架。你还要自己打开网页、截图、整理表格。你让它写代码,它给了片段。你还要自己拉项目、装依赖、跑测试、修报错。你让它做设计,它给了灵感。你还要自己画页面、调间距、改组件、交给前端。
所以很多人用 AI 的真实体验不是“生产力爆炸”,而是“我多了一个很会说的同事,但最后收尾的人还是我”。
这就是第一代 AI 工具的瓶颈。
它能生成内容,但不一定能完成任务。它能给你答案,但不一定能进入流程。它能帮你想,但不一定能替你做。
AI 的价值,不在于它说得多像人,而在于它能不能把任务往前推进一步。
这也是为什么我觉得最近这些更新值得看。它们表面上各做各的,实际上都在回答同一个问题:AI 怎么从聊天框里走出来?
从聊天框走出来,第一件事就是要有一个能安全干活的地方。
02
Claude 的新动作,其实是在补“安全工位”
先看 Claude。
Claude Design token limit 翻倍,表面上看是额度问题。用户觉得 Claude Design 好用,但不够用,Anthropic 把 token limit 往上提,是在解决高频创作的续航问题。
但真正更值得看的,是另一条:Claude 推出 self-hosted sandboxes 和 MCP tunnels。
这两个词听起来很技术。
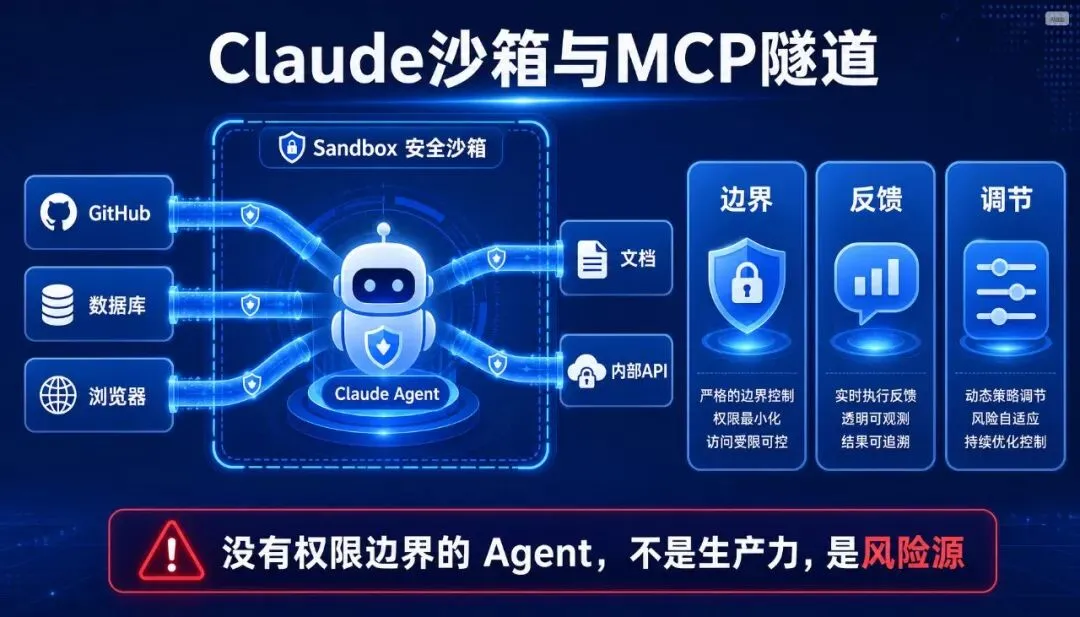
翻译成人话,就是两件事:第一,AI 要有自己的安全工位;第二,AI 要能通过正规门禁进入你的工具系统。
为什么这重要?因为只要 AI 开始“干活”,风险就变了。
过去 AI 只是回答你,它说错了,大不了你不采纳。可一旦 AI 开始读文件、改代码、调用接口、访问数据库、执行脚本,它就不再只是顾问,它开始变成操作者。
操作者必须有边界。
它能不能误删文件?能不能访问不该访问的数据?能不能把敏感信息发出去?能不能在生产环境里乱跑命令?出了错以后,谁知道它刚才干了什么?
这不是杞人忧天。
这就是企业级 AI 落地的第一性问题。
普通用户觉得 AI 好不好用,主要看回答质量。企业看 AI 能不能用,第一看权限边界,第二看过程审计,第三看成本控制,第四才看回答质量。
所以 self-hosted sandboxes 和 MCP tunnels 这类东西,比普通的“模型又升级了”更值得关注。
沙箱解决的是边界问题。MCP tunnels 解决的是连接问题。
前者告诉 AI:你可以做事,但只能在这个安全范围里做。后者告诉 AI:你可以连接工具,但必须通过规范的通道连接。
这就像公司招一个很强的人,不是给他一张万能门禁卡,让他随便进财务室、机房、仓库和客户数据库。成熟组织会给他岗位权限、流程制度、操作日志和审批机制。
AI 也是一样。
没有权限边界的 Agent,不是生产力,是风险源。
AI 一旦开始执行,安全就不再是附加题,而是入场券。
《系统之美》作者德内拉·梅多斯说:“系统的行为来自系统结构。”
这句话放到 AI Agent 上非常准确。一个能在企业里干活的 AI,必须具备三件事:边界、反馈和调节。
边界,决定它哪些能做、哪些不能做。反馈,决定人能不能看到结果、判断对错。调节,决定它出错以后系统能不能收敛,而不是一路错下去。
模型智商决定它能不能理解任务。系统结构决定它能不能安全完成任务。
03
AI 设计不再只是“出图”,而是进入交付链路
再看 Open Design。
今天 X 上 Open Design 相关的内容很密集:html-anything fully available,近 400 个 templates、skills、design systems,Open Design now runs on Codex。
这件事对设计和产品开发都有启发。
过去大家谈 AI 设计,第一反应往往是“生成一张图”。比如做一张海报,生成一张插画,画一个 App 页面,做一个好看的 banner。
这当然有价值。
但这不是 AI 设计的终点。
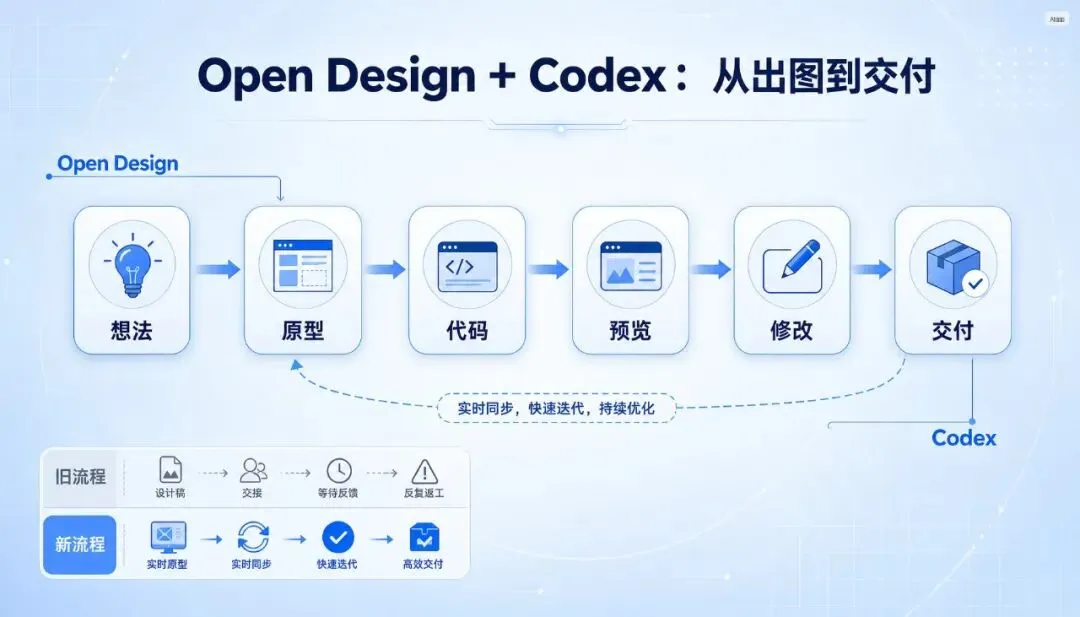
真正的 AI 设计,不是出图,而是把设计意图、页面结构、代码实现、修改反馈,放进同一个工作流里。
传统产品设计流程里,信息损耗非常严重。老板说一个想法,产品经理写需求,设计师画原型,UI 出稿,前端实现,测试提 bug,业务再改需求。每过一手,信息就损耗一次。
很多项目最后做出来不像最初想要的,不是因为大家不努力,而是因为上下文在传递中不断丢失。
AI 设计工具如果只是生成一张漂亮图片,解决不了这个问题。它真正要解决的是:如何让想法直接变成可修改、可预览、可交付的原型。
Open Design 接入 Codex 的意义就在这里。
它不是让 AI “画得更好看”这么简单,而是让设计进入代码环境,让 Agent 可以围绕同一个 live prototype 持续修改。
你可以让它改布局,可以让它检查交互,可以让它把某个组件换成另一种风格,可以让它根据已有 design system 生成一致的页面,甚至可以让它边看页面、边改代码、边保留文件。
这就是从“生成图片”到“生成工作资产”的变化。
以前的流程像这样:想法 → 文案 → 原型 → 设计稿 → 前端 → 预览 → 修改 → 再沟通。
现在的流程开始变成:想法 → 原型 → 代码 → 预览 → 修改 → 交付。
中间很多交接环节被压缩了。
这不是设计师不重要了。恰恰相反,当执行成本下降以后,真正稀缺的东西会变成判断力。
你知道什么是好,什么是坏,什么能交付,什么只是看起来漂亮。
真正改变行业的工具,往往不是一开始最完美的那个,而是第一个把旧流程压缩掉的那个。
《创新者的窘境》作者克莱顿·克里斯坦森提醒我们:破坏性创新往往从“不够完美”的边缘开始。
今天很多 AI 设计工具看起来还不完美。中文字可能翻车,细节可能不稳,组件可能不够精致。
但别被这些表面问题骗了。
只要它能把“想法到原型”的时间从几天压到几十分钟,它就已经改变了竞争规则。因为效率变化到一定程度,就不只是效率问题,而是组织方式问题。
04
本地模型速度上来以后,企业会重新算账
再看本地模型。
今天还有一条信号:llama.cpp 支持 Qwen3.6 的 MTP。相关资料里提到,MTP 支持已经合并进 llama.cpp 主线,本地 Qwen3.6 可以通过 speculative decoding 获得明显速度收益。
很多普通用户看到这个,会觉得这是技术圈自嗨。
我不这么看。
这背后其实是企业 AI 成本账的问题。
Chatbot 时代,一个人问一句,AI 答一句。成本是线性的。
Agent 时代不一样。
你给它一个任务,它会拆步骤、查资料、读文件、写代码、跑测试、修 bug、再跑一次、整理结果。你表面上只发了一句话,但背后可能触发几十次甚至上百次模型调用。
这就像你请一个顾问来开会,和你雇一个团队连续干三天,账单当然不是一个量级。
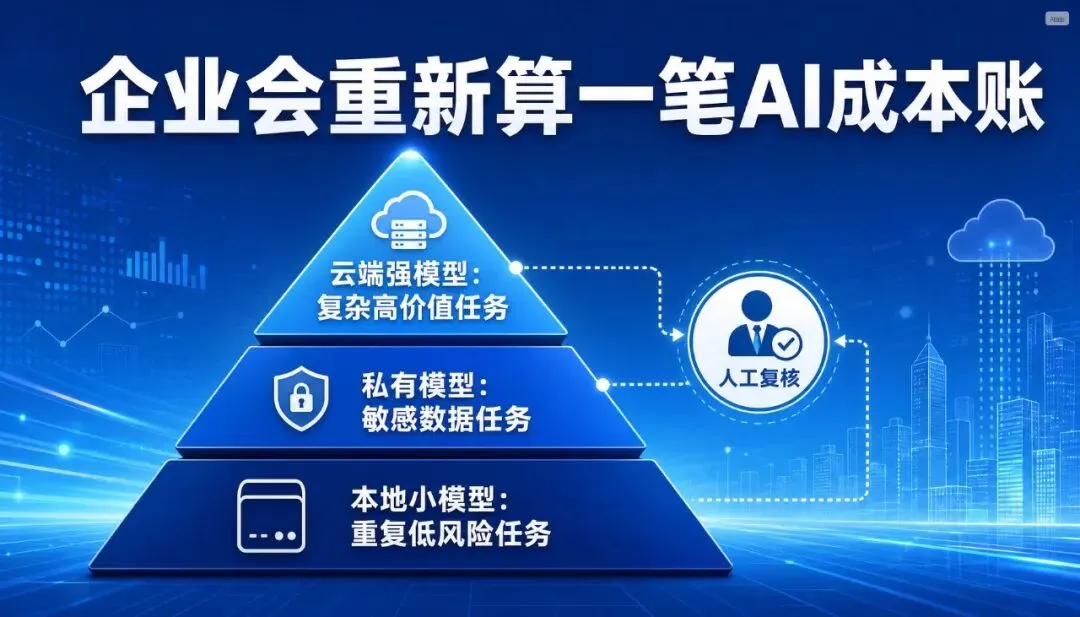
所以 Agent 真正跑起来以后,企业一定会问:哪些任务必须用最强云模型?哪些任务可以用本地模型?哪些任务要放在私有环境?哪些任务可以用小模型加工具链完成?哪些任务必须人工审批?
这时候,本地模型速度提升就不是技术圈玩具,而是成本结构变化。
凯利公式讲的是下注比例。它告诉我们,在长期博弈里,最重要的不是每一把都梭哈,而是根据胜率和赔率控制仓位。
企业用 AI 也一样。
不是所有任务都值得上最贵模型。
一个成熟的企业 AI 系统,未来很可能是混合模型结构:高价值、高风险、高复杂度的任务,用最强云模型;重复性、低风险、内部数据敏感的任务,用本地模型;流程判断、权限审批、结果校验,用规则系统和人工节点。
这才是真正的 AI 成本管理。
如果你是企业里的 AI 负责人,或者想做 AI 解决方案,这一点一定要看清楚。
老板不关心你今天又试了哪个模型。老板关心的是:这套东西能不能稳定跑?会不会泄密?出错谁负责?一个月花多少钱?能不能让业务指标变好?
所以未来 AI 落地的核心能力,不是“我会用很多工具”,而是你能不能设计一套合理的智能工作系统。
企业买的不是模型智商,而是稳定、可控、可复盘的业务结果。
05
Skill 生态扩散,说明 AI 能力正在被资产化
今天还有一个很有意思的现象:各种 Skill 开始扩散。
SEO Audit Skill,可以让 AI 抓网站做基础 SEO 检查。学术研究 Skill,可以把论文检索、摘要、综述写作流程封装起来。微信读书 Skill,可以读取书籍数据和笔记,帮人做阅读分析。Open Design 里也有大量 templates、skills、design systems。
我自己最近也在折腾各种 Hermes Skill。越折腾越有一个感觉:
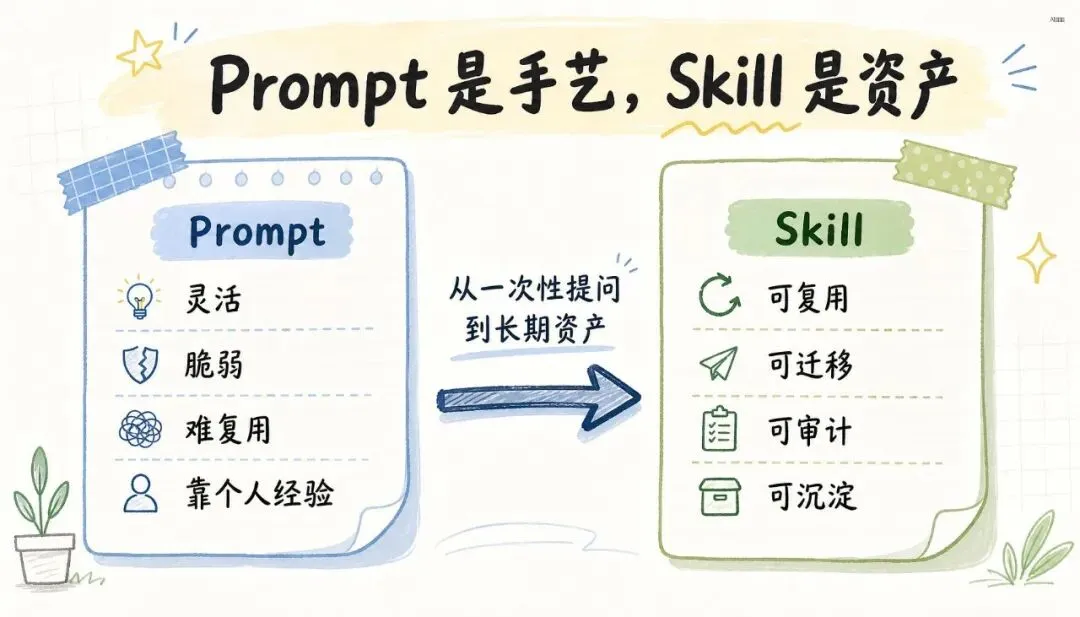
Prompt 是手艺,Skill 是资产。
Prompt 很灵活,但也很脆。
你今天写了一个好提示词,明天换个场景可能就不灵了。你自己知道怎么调,别人未必会用。你让团队复用,也很难保证质量一致。
Skill 不一样。
Skill 是把一套流程、工具、约束、经验、坑点、模板封装起来。
它不只是“怎么问 AI”,而是“怎么让 AI 按一个可复用流程完成任务”。
这就像手机 App 的价值,不是把代码给你看,而是把复杂功能封装成按钮。AI Skill 的价值,也不是炫耀提示词写得多漂亮,而是把复杂工作封装成可调用能力。
普通人未来不会每天从零写 prompt。
真正高频的能力,会被封装成 Skill。
比如网站诊断 Skill、客户跟进 Skill、面试复盘 Skill、行业研究 Skill、竞品分析 Skill、会议纪要转任务 Skill、公众号文章生产 Skill、招投标信息筛选 Skill。
这些东西看起来小,但很值钱。
因为它们不是知识点,而是工作单元。
《穷查理宝典》里,查理·芒格反复强调“多元思维模型”的重要性。他真正想说的不是你要背很多概念,而是你要把重要模型变成可反复调用的判断工具。
Skill 也是一样。
它是 AI 时代的“可调用经验”。
一个人如果只是收藏工具,他的效率提升是线性的。一个人如果开始沉淀 Skill,他的能力会有复利。
因为每一个 Skill,都会变成下一次任务的起点。
收藏工具是在增加库存,沉淀流程才是在积累资产。
06
我把自己的 Skills 开源了
这对我自己也很有警醒。
我以前也容易沉迷工具探索,今天试这个,明天试那个。看起来很勤奋,其实很多时候只是在消费新鲜感。
真正有价值的不是“我又发现了一个新工具”。真正有价值的是“我把一个高频问题沉淀成了一套可复用流程”。
热力学第二定律告诉我们,孤立系统会自然走向熵增。人的知识系统也是一样,如果你只是不断收藏信息,它会越来越乱。
只有持续做结构化沉淀,才能对抗熵增。
所以我现在越来越相信一句话:
AI 时代真正的个人资产,不是工具清单,而是工作流资产。
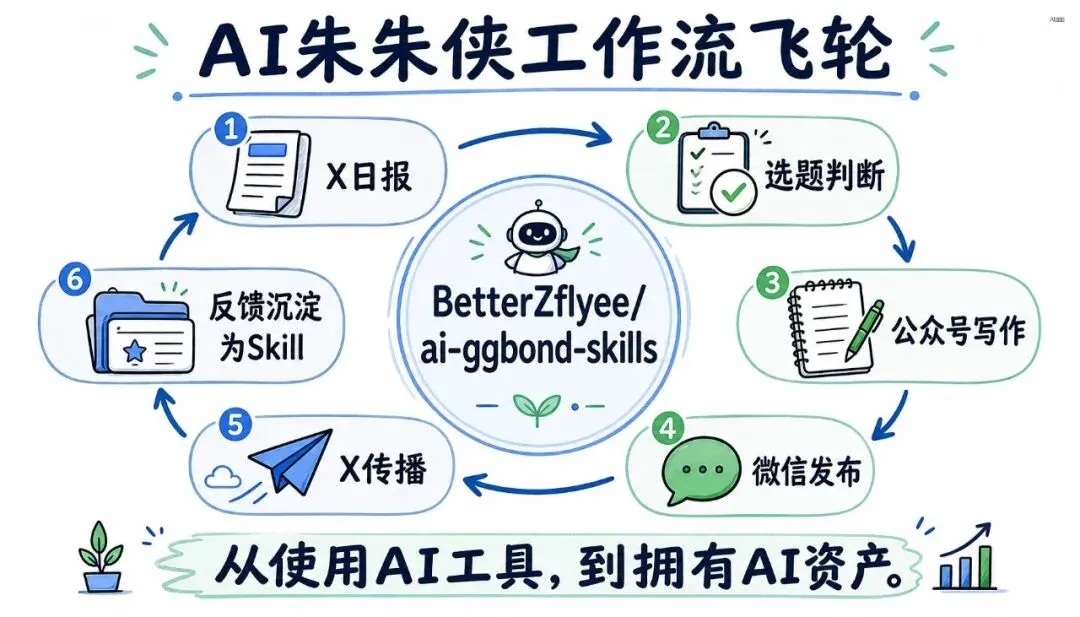
也因为这个判断,我把自己最近沉淀的一部分工作流,整理成了一个开源仓库:AI GGBond Skills。
GitHub 地址:https://github.com/BetterZflyee/ai-ggbond-skills
这里面放的不是“提示词收藏夹”,而是我真实在用的工作流资产:X 日报、公众号写作、微信发布、X 传播。
如果你觉得有用,欢迎 Star、Fork,也欢迎直接 Contribute。
我更希望它变成一个开放的小实验:看看普通个体能不能把自己的经验,沉淀成可复用的 AI Skill。
它现在主要有几类我自己真实在用的技能:
- ai-ggbond-x-followings-feed
:自动抓取 X/Twitter 关注流,把零散信息整理成结构化 AI 日报。今天这篇文章的选题,就是从这个流程里冒出来的。
- ai-ggbond-article-writer
:把选题、资料搜索、结构设计、初稿写作、去 AI 味、配图规划这些步骤,沉淀成公众号文章工作流。
- ai-ggbond-post-to-wechat
:把 Markdown/HTML 文章处理成微信公众号草稿,自动处理图片上传、封面图、主题样式。
- ai-ggbond-push-to-x
:把长文观点拆成适合 X/Twitter 传播的短内容。
这几个 Skill 不是什么宏大的平台。
它们更像我给自己打造的几把“工作扳手”。
每天看新闻,不是刷完就算,而是让 X 关注流先变成日报,再从日报里筛选公众号选题。写公众号,不是从空白页开始硬憋,而是让文章写作 Skill 先完成资料整理、结构判断和初稿搭建。发公众号,不是复制粘贴到崩溃,而是把排版、图片和草稿箱推送尽量自动化。发 X,也不是临时想一句金句,而是把长文里的关键判断拆成适合传播的短观点。
这就是我理解的 AI Native 工作流:
不是让 AI 替我思考,而是让 AI 接住那些可流程化、可复用、可沉淀的动作。
一个 Skill 不大,但它会让下一次任务站在上一次的肩膀上。
这就是从“使用 AI 工具”,走向“拥有 AI 资产”的第一步。
07
企业 AI 落地,真正难的不是模型
很多企业谈 AI,第一句话就是:“我们要不要接入大模型?”
这个问题问得太早了。
更应该先问的是:你到底想让 AI 改变哪条业务链路?
是销售线索获取?是客户跟进?是售前方案?是合同审核?是客服质检?是生产排程?是设备巡检?是知识库问答?
不同场景,对 AI 的要求完全不同。
销售线索分析需要的是信息抽取、排序、跟进建议。合同审核需要的是权限、审计、法律边界。设备巡检需要的是多模态识别、异常检测、工单流转。售前方案需要的是行业知识、客户语境、案例库和方案模板。
你不能拿一个聊天机器人去糊所有场景。
这也是为什么我一直觉得,“企业 AI 培训”如果只教大家怎么写 prompt,价值很有限。
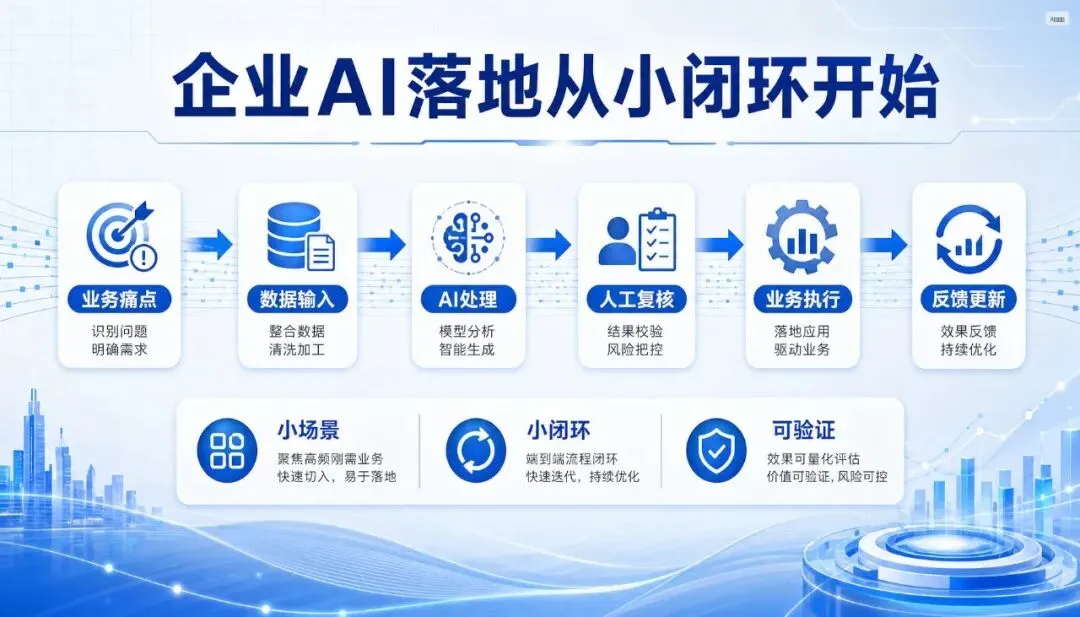
真正有价值的是帮企业把流程拆出来:哪个环节输入是什么?输出是什么?谁负责审批?哪些数据能给 AI?哪些数据不能给?AI 的结果由谁复核?复核不通过怎么回退?
这套流程跑通以后,再谈模型选择,才有意义。
否则就是拿锤子找钉子。
贝叶斯理论有一个核心思想:我们不是一次性得到真理,而是在新证据到来以后不断更新判断。
企业 AI 落地也是贝叶斯过程。
不要一上来就做大而全系统。先选一个小场景,跑一个闭环,收集反馈,再更新方案。
比如一个制造业企业想用 AI,别一开始就喊“我要建设企业级智能体平台”。
先做一个很小的闭环:每天自动抓取行业招标信息,按产品线和区域筛选,生成商机摘要,推送给销售负责人,销售标记是否有价值,系统根据反馈更新筛选规则。
这就是一个完整闭环。
它不性感,但有用。它不宏大,但能产生业务结果。
很多企业 AI 项目失败,不是模型不够强,而是第一步就选错了战场。他们想做一个“万能 AI 大脑”,最后变成没人用的展示系统。
真正能落地的 AI,往往从一个小而硬的业务痛点开始。
小到足够可控。硬到足够刚需。闭环到足够验证结果。
别先造大脑,先跑闭环;别先谈愿景,先拿结果。
08
普通人应该怎么做
说到这里,普通人该怎么办?
我给一个很直接的建议:别再把主要时间花在收藏 AI 工具上了。
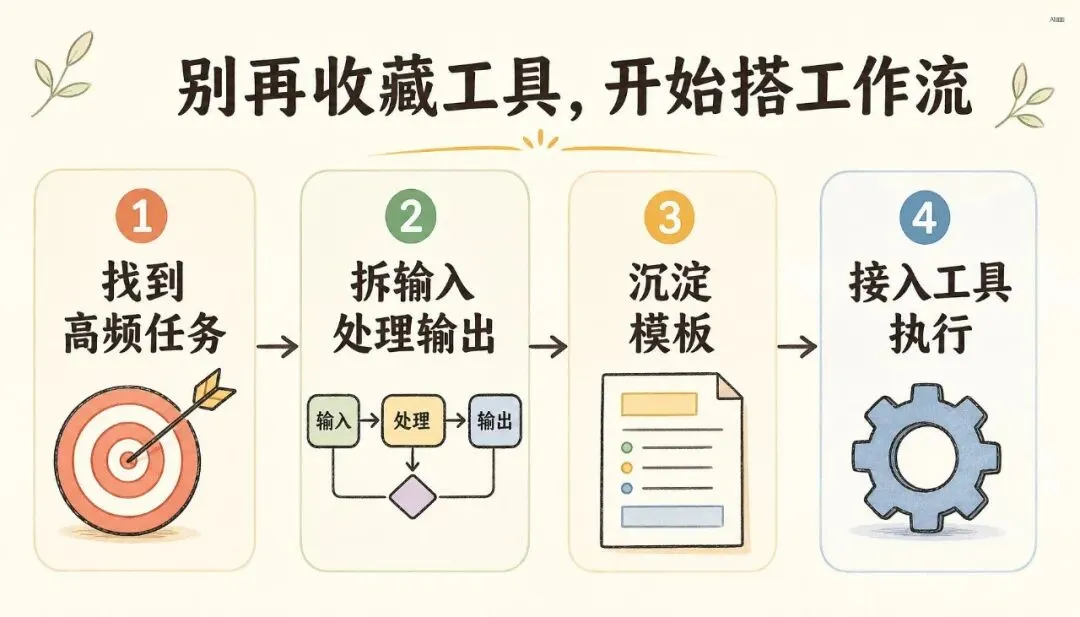
从今天开始,选一个你最高频、最痛、最能产生结果的任务,把它做成固定工作流。
不是写一个 prompt。
是做一个流程。
第一步,找到你的高频任务。
不要选听起来很高级的任务,选你真的每周都做、每次都烦、做完还能带来价值的任务。比如写公众号、整理会议纪要、分析一个岗位 JD、跟进客户、做竞品研究、整理行业新闻、写周报、准备面试。
这里有一个原则:
低频任务不值得自动化,高频任务才值得资产化。
你的高频任务,就是你最值得下注的 AI 自动化仓位。
第二步,把任务拆成输入、处理、输出。
比如写公众号,不要只说“帮我写文章”。你要拆成:输入是热点素材、目标读者、核心观点、参考链接、个人经历;处理是选题判断、资料搜索、结构设计、初稿撰写、去 AI 味、排版、配图、发布;输出是 Markdown 原文、HTML 排版、封面图、摘要、朋友圈文案。
拆到这个程度,AI 才能真正进入流程。
否则你每次都在和 AI 聊天,每次都从零开始。
第三步,把关键步骤沉淀成模板。
模板不是为了限制创造力。模板是为了减少低级重复。
比如公众号文章,你可以固定几个模块:选题判断模板、资料搜索模板、文章大纲模板、去 AI 味检查清单、配图提示词模板、发布检查清单。
一旦有了模板,你就不需要每次重新发明轮子。
第四步,让 AI 进入工具,而不是停留在聊天框。
这一步最关键。
如果 AI 只能回答,它还是顾问。如果 AI 能读文件、写文件、调用脚本、访问数据库、生成图片、推送消息,它才开始变成执行者。
这就是为什么我现在很重视 Hermes、Claude Code、Codex、各种 Skill 和自动化脚本。
它们不只是工具。
它们是在帮我把“想法”接到“行动”。
09
从一个最小闭环开始
普通人没必要一上来搞得很复杂。
你可以从最小工作流开始。
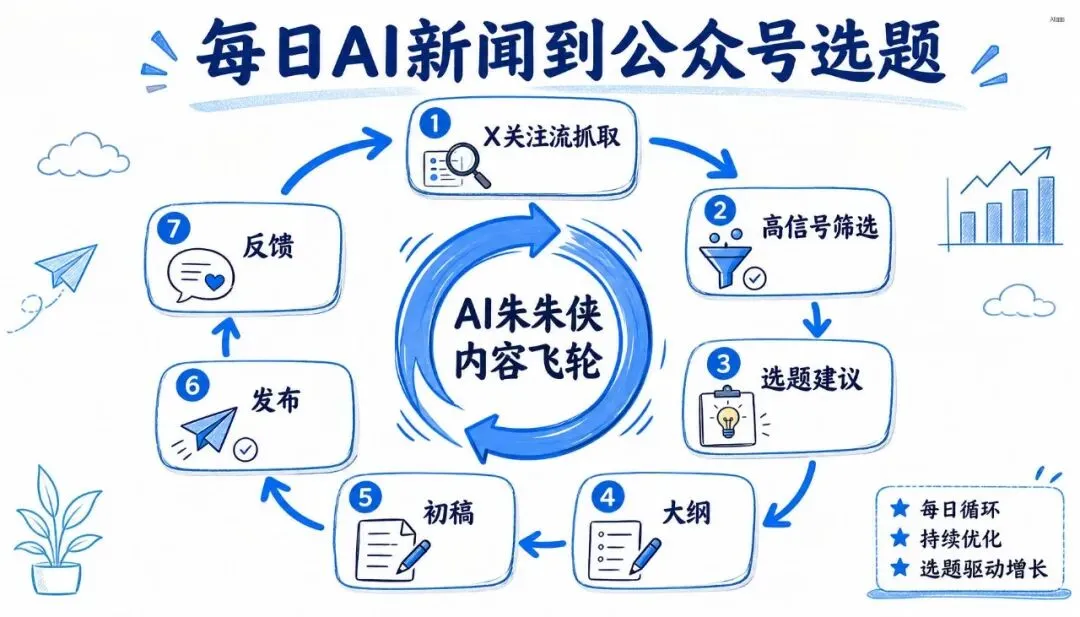
比如做一个“每日 AI 新闻 → 选题建议 → 公众号大纲”的流程。
每天早上抓 X、公众号、官网更新。AI 帮你筛出 5 条高信号。再按你的定位推荐 3 个选题。你选一个。AI 生成大纲和素材卡片。
这就够了。
先跑起来。
跑通比完美重要。
《精益创业》作者埃里克·莱斯说:“创业的核心是经过验证的学习。”
AI 工作流也是一样。
别幻想一次搭出完美系统。先搭一个能跑的版本,然后用真实任务喂它,用真实反馈改它。
工作流不是设计出来的完美蓝图,而是在一次次真实任务里长出来的系统。
10
我对未来 AI 工具的一个判断

我有一个判断:未来 AI 工具会分成三层。
第一层,是模型层。
OpenAI、Anthropic、Google、DeepSeek、Qwen、Kimi 这些公司继续卷模型能力。这一层很重要,但普通人很难参与。
第二层,是执行环境层。
比如 Claude Code、Codex、Hermes、Open Design、本地沙箱、MCP、浏览器自动化、文件系统权限、工具调用框架。这一层会决定 AI 能不能进入真实工作现场。
第三层,是工作流资产层。
也就是各种 Skill、模板、行业方案、企业流程、个人方法论。
这一层,普通人和中小团队反而有机会。
因为你不需要训练大模型。你只需要比别人更懂一个场景,更懂一个流程,更懂一个行业,然后把这套理解封装成可复用的工作流。
这就是 AI 时代的小机会。
不是每个人都要做大模型。但每个人都可以做自己的工作流资产。不是每家公司都要做基础模型。但每家公司都需要把自己的业务流程 AI 化。不是每个个体都要成为程序员。但每个高价值个体,都要学会把 AI 接进自己的产出链路。
《孙子兵法》孙武说:“胜兵先胜而后求战,败兵先战而后求胜。”
放到今天,就是:真正会用 AI 的人,不是临时打开工具求救,而是在开战前就把工作流准备好了。
等别人还在问“这个问题怎么 prompt”,你已经有一套流程自动跑起来了。
这就是差距。
AI 时代的“先胜”,就是任务到来之前,工作流已经在场。
11
结尾:不要再把 AI 当许愿池
所以,回到开头。
Claude 提升 token limit,不只是额度变多。self-hosted sandboxes 和 MCP tunnels,不只是技术功能。Open Design 接入 Codex,不只是设计工具更新。llama.cpp 支持 Qwen3.6 MTP,不只是本地模型玩家的好消息。Skill 生态扩散,也不只是 AI 圈又多了一些玩具。
这些信号放在一起,说明 AI 工具正在发生一次底层迁移。
从聊天,到执行。从回答,到交付。从 prompt,到 skill。从工具清单,到工作流资产。从模型崇拜,到系统能力。
我知道,很多人还是会继续问:到底哪个模型最强?
这个问题不是不能问。
只是它已经不够用了。
更重要的问题应该是:这个 AI 能不能进入我的真实工作?它能不能帮我完成一个闭环?它能不能留下过程,方便我复盘?它能不能变成我的长期资产?
如果答案是否定的,那它再聪明,也只是一个会聊天的工具。
如果答案是肯定的,那它就开始变成你的生产系统。
这就是 AI 工具的下半场。
不是谁更会聊天。
而是谁能真正下场干活。
最后留一句我今天最想强调的话:
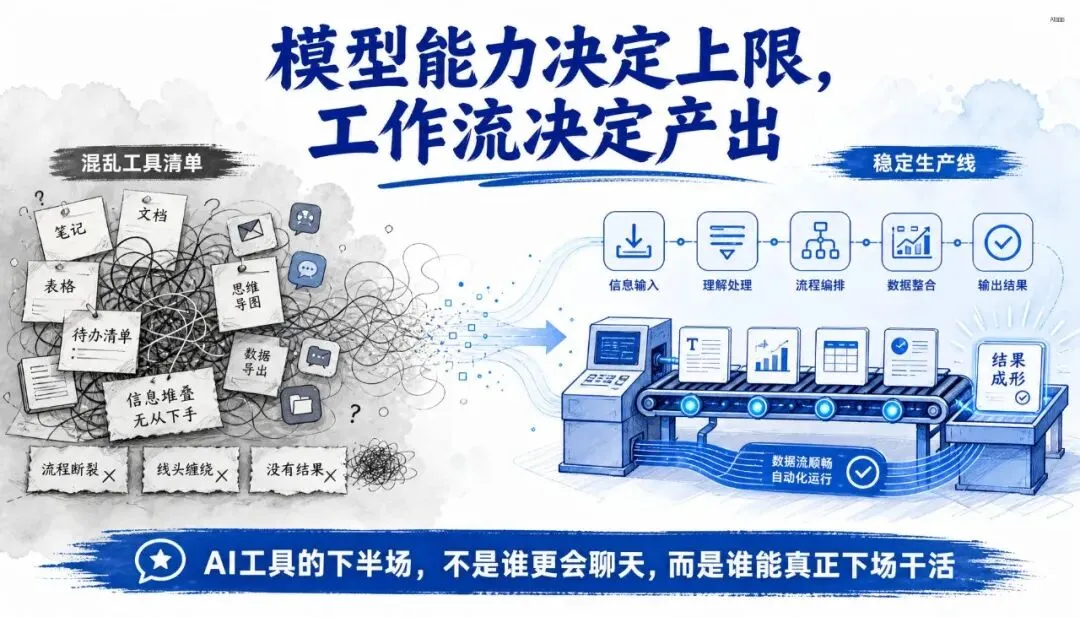
模型能力决定上限,工作流决定产出。
你不缺 AI 工具。
你缺的是一套能持续产出结果的 AI 工作流。
不要再把 AI 当许愿池。
把它接进你的文件、工具、流程和复盘系统里。
从一个高频任务开始,把它拆成输入、处理、输出,再慢慢沉淀成模板、脚本和 Skill。
我已经把自己的一部分 Skills 开源出来了。
如果你也在搭自己的 AI 工作流,欢迎 Star、Fork,甚至直接 Contribute。
别只收藏别人的工具。
从今天开始,沉淀你自己的工作流资产。
📌 Skills 已开源
欢迎 Star / Fork / Contribute:https://github.com/BetterZflyee/ai-ggbond-skills
