 夜雨聆风
夜雨聆风病理大模型的新方向
让AI不只是“看图”,还要懂疾病
文献分享 | Cancer Cell 2026年4月
近年来,人工智能在病理诊断中的应用发展迅速。从癌区识别、肿瘤检测,到全切片图像(whole-slide image, WSI)层面的肿瘤分型,病理 AI 正在逐渐从单一任务模型走向基础模型。
不过,现有许多病理 AI 模型仍主要依赖图像数据或简单的图文配对进行训练。也就是说,模型虽然能够“看图”,却未必真正理解疾病名称、同义词、疾病定义以及不同疾病之间的层级关系。
本期文献分享介绍 Cancer Cell 2026 年发表的一项研究:Knowledge-enhanced pretraining for vision-language pathology foundation model on cancer diagnosis。该研究提出了一个知识增强型病理视觉语言基础模型 KEEP,尝试将疾病知识图谱融入病理大模型预训练,使模型不仅学习病理图像与文字描述,还能理解疾病之间的医学语义关系。
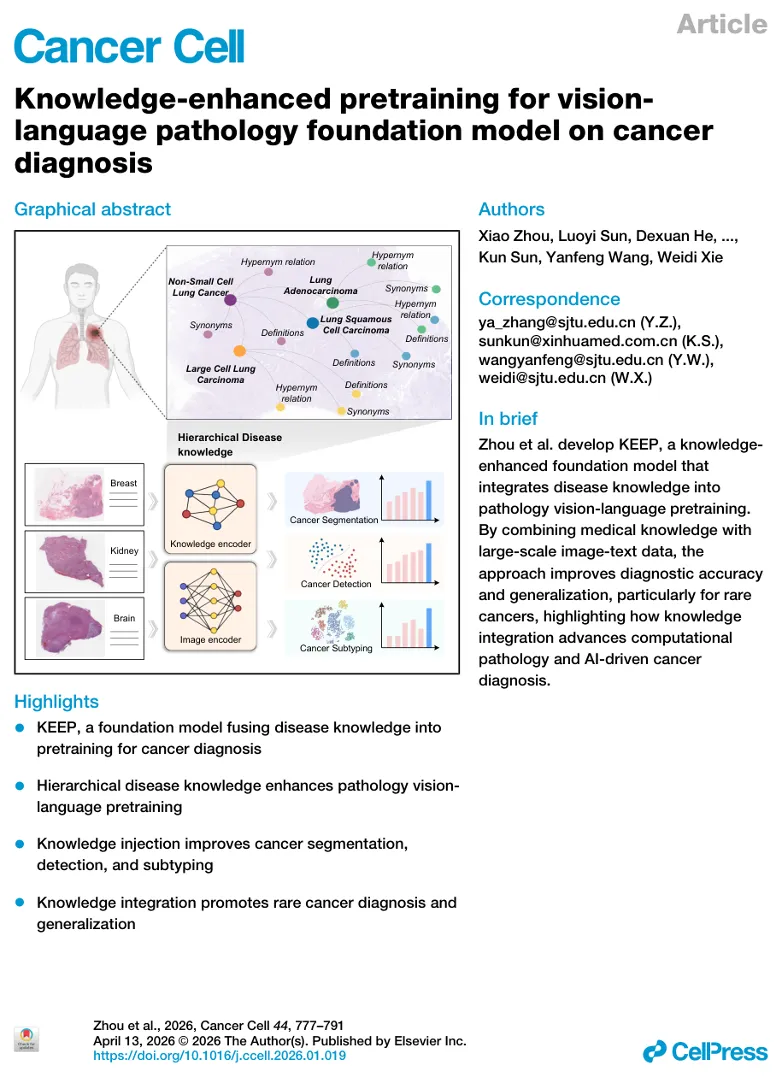
图形摘要:KEEP 将疾病知识图谱融入病理视觉语言预训练
读图要点: KEEP 的核心思想是把病理图像、文字描述和疾病知识图谱结合起来。模型既学习图像特征,也学习疾病名称、同义词、定义和上下级关系,最终用于癌区分割、癌症检测和肿瘤分型。
1
概述
病理诊断是肿瘤诊断的金标准。传统深度学习模型通常依赖大量标注图像进行训练,但病理标注成本高,且在罕见肿瘤、复杂亚型和低样本场景中,模型泛化能力往往受限。
近年来,病理视觉语言模型(vision-language model)逐渐受到关注。这类模型通过病理图像和文字描述联合训练,能够在一定程度上实现 zero-shot 诊断,即不针对某一具体任务重新训练,也能根据文字提示完成分类或检索。
但已有模型仍存在一个关键问题:多数模型主要是“图文配对学习”,缺乏系统医学知识。对于病理诊断而言,疾病名称并不是孤立词语。例如“肺鳞状细胞癌”同时属于“肺癌”“非小细胞肺癌”和“鳞状细胞癌”等不同层级概念,也可能有多种同义表达。单纯图文对齐很难充分捕捉这些医学语义关系。
因此,本文提出 KEEP 模型,试图让病理 AI 从“看图识别”进一步走向“知识增强诊断”。
2
文章摘要
本研究提出knowledge-enhanced pathology(KEEP),一种知识增强型病理视觉语言基础模型。研究团队整合 Disease Ontology 和 UMLS,构建了包含 11,454 个疾病实体 和 139,143 个疾病相关属性 的疾病知识图谱,并据此将大规模病理图文数据重组为约 143,000 个语义结构化分组。
研究在 18 个公开基准数据集,超过 14,000 张 WSI,以及 4 个院内罕见癌数据集,926 例病例 中进行验证。结果显示,KEEP 在癌区分割、癌症检测、肿瘤亚型分类、罕见癌诊断及 tile 级别图像任务中整体优于多种已有病理基础模型。
3
研究背景
现有病理 AI 基础模型大致可以分为两类:
第一类是视觉模型
这类模型主要从病理图像中学习特征,例如用于 WSI 分类、肿瘤检测或预后预测。它们在特定任务中表现良好,但通常需要较多标注数据进行训练或微调。
第二类是视觉语言模型
这类模型通过病理图像和文本描述进行联合训练,例如 PLIP、QuiltNet、MI-Zero、CONCH 等。视觉语言模型能够利用文本提示进行 zero-shot 分类,因此在低标注场景中具有潜力。
然而,病理文本数据常来源于网络、教学视频或公开平台,存在描述短、噪声高、医学结构信息不足等问题。作者认为,如果模型不能理解疾病之间的层级关系和医学语义,仅靠图文对齐难以支撑复杂诊断,尤其是在罕见肿瘤和精细亚型识别中。
4
研究目的
本研究旨在构建一种知识增强的病理视觉语言基础模型,使模型在学习病理图像与文本描述的同时,进一步整合疾病知识图谱中的医学信息,包括:
• 疾病名称
• 疾病同义词
• 疾病定义
• 疾病上下位关系
研究希望通过这种方式提升模型在癌症分割、检测、分型和罕见癌诊断中的准确性及泛化能力。
5
研究方法
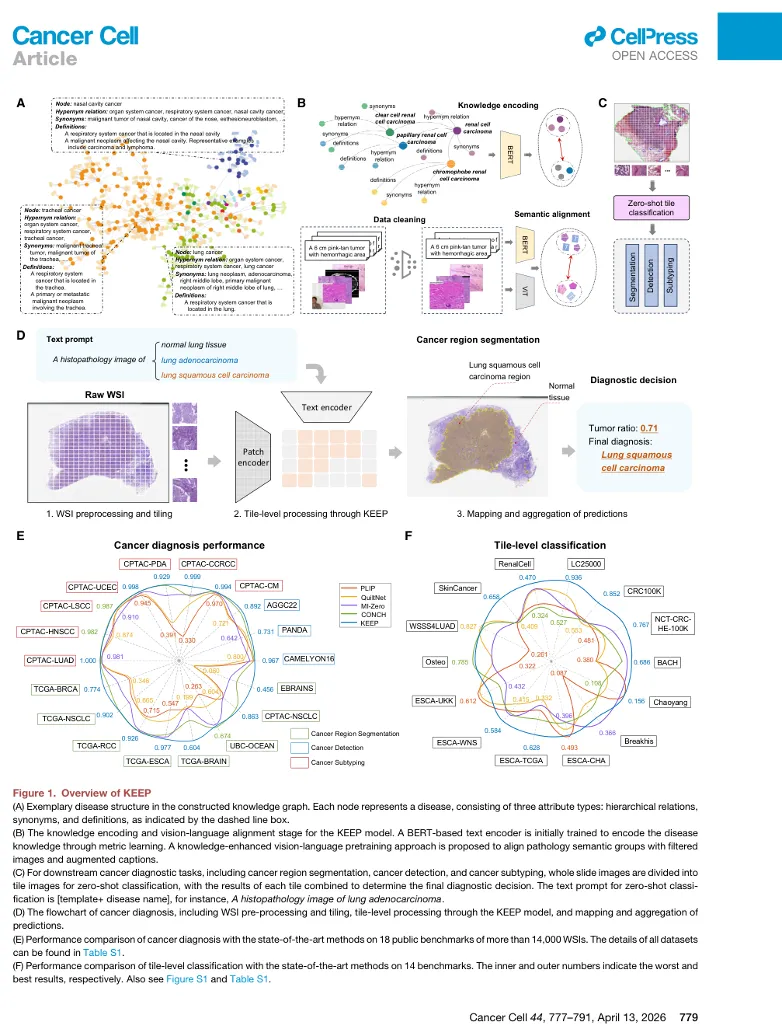
读图要点: Figure 1 展示了 KEEP 的整体框架。模型先构建疾病知识图谱,再进行知识编码和图文语义对齐。下游诊断时,WSI 被切分为 tile,模型对每个 tile 进行 zero-shot 分类,再通过 tile 结果汇总完成整张切片的诊断。
疾病知识图谱构建
研究团队整合 Disease Ontology 和 UMLS,建立疾病知识图谱。该知识图谱包括 11,454 个疾病实体和 139,143 个属性,其中包括疾病定义、同义词以及上下位关系。
例如,对于“肺鳞状细胞癌”,模型不仅学习这个诊断名称,还学习它与“肺癌”“非小细胞肺癌”“鳞状细胞癌”等概念之间的层级关系。这样,文本编码器能够形成更符合医学知识体系的疾病表征。
病理图文数据清洗
作者使用 OpenPath 和 Quilt1M 等公开病理图文数据进行预训练。但这些数据来源较复杂,可能混有非病理图像、低质量图片或无关文本。
因此,研究团队先用 YOLOv8 去除非病理图像,再用自然语言处理方法从文本中抽取医学实体,并将文本中的疾病名称与知识图谱中的疾病概念进行匹配。经过清洗和语义整理后,形成约 143,000 个语义分组。
知识增强视觉语言预训练
KEEP 的图像编码器基于 ViT-L/16,文本编码器基于 PubMedBERT。文本编码器先通过疾病知识图谱进行训练,使其能够理解疾病同义词、定义和层级关系。随后,模型在整理后的病理图文语义组上进行视觉语言对齐训练。
在 WSI 任务中,作者将全切片图像切分为 tile,每个 tile 通过 KEEP 进行 zero-shot 分类,再根据肿瘤 tile 所占比例完成癌症检测或肿瘤分型。这一策略被称为 tumor-ratio-based prediction,具有一定可解释性。
6
研究结果
癌区分割
在癌区分割任务中,KEEP 与 PLIP、QuiltNet、MI-Zero、CONCH、MUSK 等模型进行比较。结果显示,KEEP 在多个数据集上取得更优表现。与 CONCH 相比,KEEP 在 CAMELYON16 和 AGGC22 上的 DICE 分别提高约 6.8 和 8.1 个百分点。
需要注意的是,由于模型逐 tile 判断,预测图中可能出现散在假阳性区域。作者采用简单的形态学开运算进行后处理,去除小的孤立区域后,分割表现进一步提高。
癌症检测
作者在 7 个 CPTAC 数据集上进行癌症检测验证,涵盖黑色素瘤、肾透明细胞癌、胰腺导管腺癌、子宫内膜癌、肺鳞癌、头颈鳞癌和肺腺癌等。结果显示,在特异度(specificity)固定为 0.95 时,KEEP 的平均敏感度(sensitivity)达 0.898,高于 CHIEF、CONCH 和 MUSK 等模型。
此外,作者还收集了院内罕见癌检测数据,包括 59 张肾母细胞瘤 WSI 和 51 张正常 WSI。结果提示,视觉语言模型在 zero-shot 罕见癌检测中具有一定优势。
肿瘤亚型分类
在脑肿瘤分型任务中,KEEP 的平均 平衡准确率(balanced accuracy)为 0.604,较 CONCH 提高 0.15。在 EBRAINS 罕见脑肿瘤数据集中,KEEP 的 balanced accuracy 为 0.456,比 CONCH 高 8.5 个百分点,比 MUSK 高 15.5 个百分点。
不过,模型在部分亚型中仍存在混淆。例如 IDH-mutant 与 IDH-wildtype 相关胶质瘤之间的区分较困难。这提示对于依赖分子特征的诊断,单纯 HE 图像模型仍有天然上限。
罕见儿童肿瘤与 tile 级别任务
研究进一步纳入 816 张院内儿童罕见癌 WSI,包括神经母细胞瘤、肝母细胞瘤和髓母细胞瘤。KEEP 在神经母细胞瘤和肝母细胞瘤分型中优于多数比较模型,但在髓母细胞瘤亚型识别中,各模型表现均有限。
此外,KEEP 还在病理图像-文本检索和 tile 级别 zero-shot 分类任务中取得较好表现,提示知识增强预训练不仅有助于 WSI 诊断,也能提升更细粒度的病理图像理解能力。
消融实验
作者将 KEEP 与未加入知识增强的普通对比学习模型进行比较。结果显示,知识增强模型在 16/18 个 WSI 数据集 上表现更优。
这说明文章的核心贡献并非简单更换模型结构,而是证明了:将疾病知识图谱引入病理视觉语言预训练,确实能够改善模型对病理图像与疾病语义之间关系的学习。
7
研究讨论
本文提示,病理 AI 的发展可能正在从“图像识别模型”走向“知识增强型病理基础模型”。
KEEP 的优势主要来自两个方面:
第一,疾病知识注入。
模型通过疾病名称、同义词、定义和层级关系学习疾病语义,使其在识别相关疾病和罕见疾病时具备更好的知识先验。
第二,基于肿瘤比例的 WSI 判断。
模型先对 tile 进行分类,再汇总为整张切片的诊断结果,因此可以生成类似热图的区域提示,具有一定可解释性。
这与病理医生的诊断思维有相似之处。病理诊断并不是简单“看图”,而是结合形态学特征、疾病谱系、临床背景和分子信息进行综合判断。KEEP 的意义在于,它尝试让 AI 向这种“知识驱动的诊断思维”靠近。
8
研究局限性
本文也存在一些值得注意的局限。
首先,罕见癌训练数据仍然有限。即使引入疾病知识图谱,某些罕见亚型仍难以稳定识别。
其次,zero-shot 视觉语言模型仍受 prompt 设计影响。不同文字提示可能导致模型表现波动,未来需要更稳定的 prompt learning 方法。
第三,部分肿瘤亚型依赖分子或表观遗传特征,仅凭 HE 图像难以准确区分。因此,未来病理基础模型可能需要进一步融合基因组、表观基因组、蛋白组或临床信息。
最后,KEEP 虽然在多个公开数据集和院内数据中表现较好,但距离临床实际部署仍需要更大规模、多中心、前瞻性验证,并结合真实临床工作流进行评估。
9
小结
总体来看,这篇文章的核心价值并不只是提出了一个性能更好的病理 AI 模型,而是提供了一种新的建模思路:病理基础模型不能只依赖图像特征和简单文本标签,还应进一步融合疾病知识体系。KEEP 通过引入疾病知识图谱,使模型在训练过程中学习疾病名称、同义词、定义及上下级关系,从而增强其对病理图像与疾病语义之间关系的理解。
对于病理诊断而言,这一点具有重要启发。病理医生在日常诊断中并不是单纯“看图识别”,而是基于形态学表现,结合疾病分类体系、临床背景、免疫表型和分子特征进行综合判断。KEEP 所代表的知识增强型模型,正是在尝试让 AI 从单纯的图像识别工具,逐步向更接近医学诊断逻辑的辅助系统发展。
本研究也提示,未来病理 AI 的发展方向可能不再只是追求更大的数据量和更复杂的模型结构,而是更加重视图像、语言、疾病知识和多模态临床信息的深度融合。尤其是在罕见肿瘤和低样本场景中,知识图谱等医学先验信息可能为模型提供额外支持,帮助其提升泛化能力和诊断稳定性。
当然,KEEP 目前仍处于研究阶段,距离真正临床应用还有一定距离。对于依赖分子改变或表观遗传特征区分的肿瘤亚型,单纯基于 HE 图像的模型仍存在局限。未来还需要更大规模、多中心、真实世界队列的外部验证,并进一步评估模型在不同医院、不同染色条件、不同扫描设备和不同病例构成下的稳定性。
因此,这篇文章对病理科的意义不仅在于展示了病理大模型的前沿进展,也提醒我们:医院病理科可以在这一领域中发挥重要作用。即使不从零训练大模型,也可以基于本院真实世界病例开展外部验证、错误模式分析、适用边界评估和辅助诊断价值研究,为病理 AI 的临床转化提供更贴近实际场景的证据。
参考文献
Zhou X, Sun L, He D, et al. Knowledge-enhanced pretraining for vision-language pathology foundation model on cancer diagnosis. Cancer Cell. 2026;44:777-791. DOI: 10.1016/j.ccell.2026.01.019.
图片来源
本文配图均截取并整理自上述开放获取论文原文,仅用于文献学习与学术交流,正式发布时请保留原文出处和 DOI。
供稿:郭佳骐
审核:

