 夜雨聆风
夜雨聆风
导读 腾讯云数据库 TDSQL-C 通过 Serverless 架构和 AI 技术双轮驱动,解决传统数据库在弹性、调优、成本和运维方面的痛点。本文详解其存算分离架构、预测式弹性、零抖动扩缩容技术,以及基于腾讯混元大模型构建的 AI 优化器和 Hermes Agent 智能运维系统。
1. 云原生数据库的智能化变革
2. Serverless 智能弹性
3.AI 自学习优化器
4. AI Navigator 智能数据库管理
5. 问答环节
分享嘉宾|陈昊 腾讯云数据库高级产品经理
内容校对|韩珊珊
出品社区|DataFun
01
云原生数据库的智能化变革
IDC报告中显示,预计到 2029 年中国数据库市场将达到 186 亿元,年复合增长率 20.1%。66% 的企业因 AI 技术发展正在重构数据底座,而 85% 的线上故障由 SQL 导致,处理工单平均耗时 4.5 小时,SQL 调优占据 50% 的人力投入。

传统数据库面临四个核心痛点。第一是弹性不足,电商大促时流量 10 倍突增,扩容需要小时级别。陈昊举例:"AI 时代下,不知道哪一天产品可能成为爆点。如果突发流量后再扩容,很可能来不及,没办法扛住流量洪峰。"第二是调优困难,SaaS 业务可能涉及 21 万张表、29 表连接,人工优化效率极低。第三是成本浪费,所有数据都放在数据库会带来很高成本。第四是运维复杂度逐步增加。
TDSQL-C 提出两个破局方向:Serverless化,让数据库自动弹性扩缩;AI 驱动,把人力释放到业务模型上。产品定位为以 Serverless 架构为底座,AI 技术为引擎,重构数据库弹性能力、查询效率与管理体验。
传统数据库采用存算一体架构,磁盘不够需要扩容时,即使计算资源只用了 20% 也要一起扩容,造成资源浪费。传统云数据库主从通过 Binlog 做同步,跨地域延迟很大。
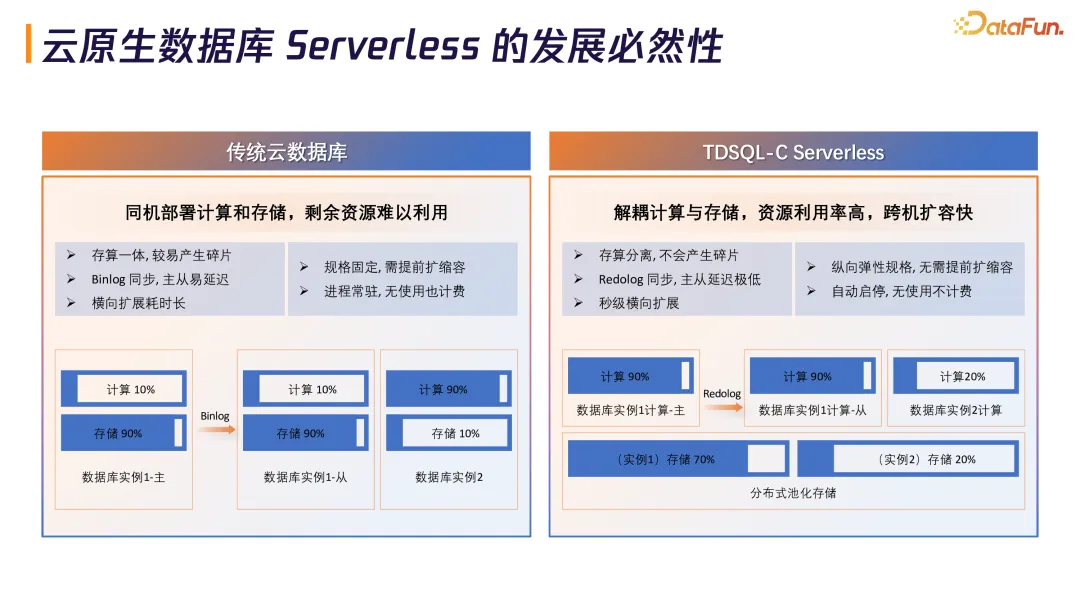
TDSQL-C 基于存算分离架构,计算全在计算资源池,存储做三副本线性可扩展。存储不够扩存储,计算不够扩计算。更重要的是,TDSQL-C 不再依赖 Binlog,全部采用物理日志 Redolog 同步,极大提升复制效率,使主从延迟极低,支持秒级横向扩展。实现自动启停,无使用不计费,真正按量付费。
02
Serverless 智能弹性
1. 全链路 Serverless 架构:亚秒级弹性、极致降本
TDSQL-C 采用一主多从架构,最上面是 Proxy 层负责动态流量分发。整个架构有两个核心弹性能力:垂直弹性根据数十种监控指标,在同机情况下做到亚秒级弹性;横向弹性能做到秒级拓展节点。
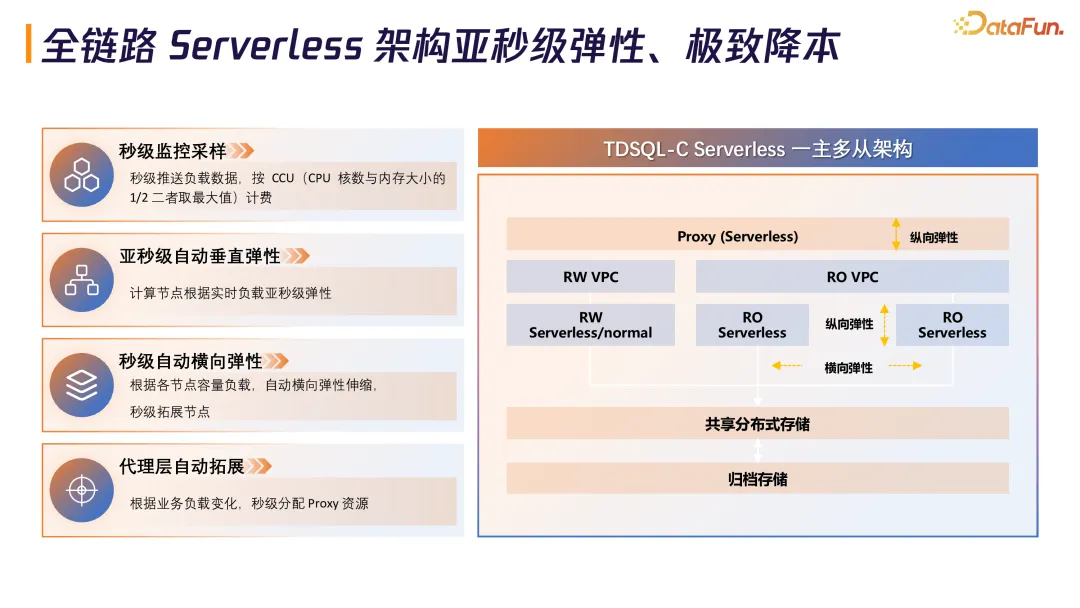
计费模式采用 CCU(CPU 核数与内存大小的 1/2 二者取最大值),秒级监控采样,秒级推送负载数据,实现按量计费。
2. 预测式弹性:更贴合业务的高精度弹性
传统弹性方式是事后弹性,当 CPU 使用量达到 80%、内存使用率达到 90% 时才决策扩容,对突增流量场景很难控制。TDSQL-C 引入 AI 实现预测式弹性,分为四个阶段。
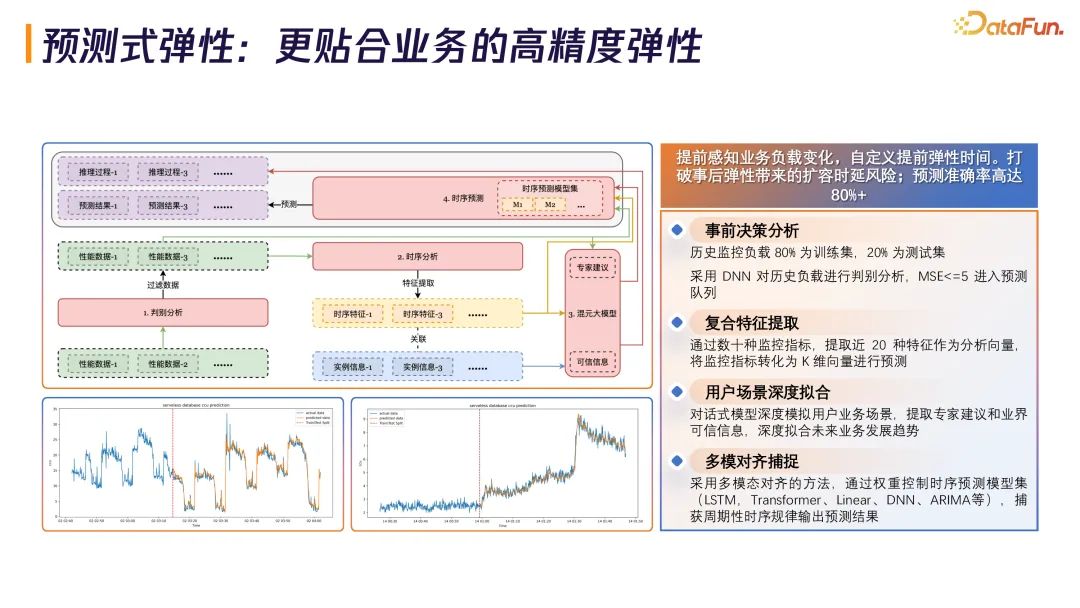
事前决策分析:历史监控负载 80% 作训练集,20% 作测试集,采用 DNN 算法预测,均方误差小于 5 就加入预测队列。复合特征提取:提取近 20 种特征作为分析向量。用户场景深度拟合:通过大模型对话方式提供外置增强插件能力,比如提前告知明天有重大节日或赛事,提前扩容。多模对齐捕捉:通过权重控制时序预测模型集(LSTM、Transformer、Linear、DNN、ARIMA 等),预测准确率达 80% 以上。
3. 实时弹性的稳定性保证
TDSQL-C 做了两个技术优化保持稳定性。
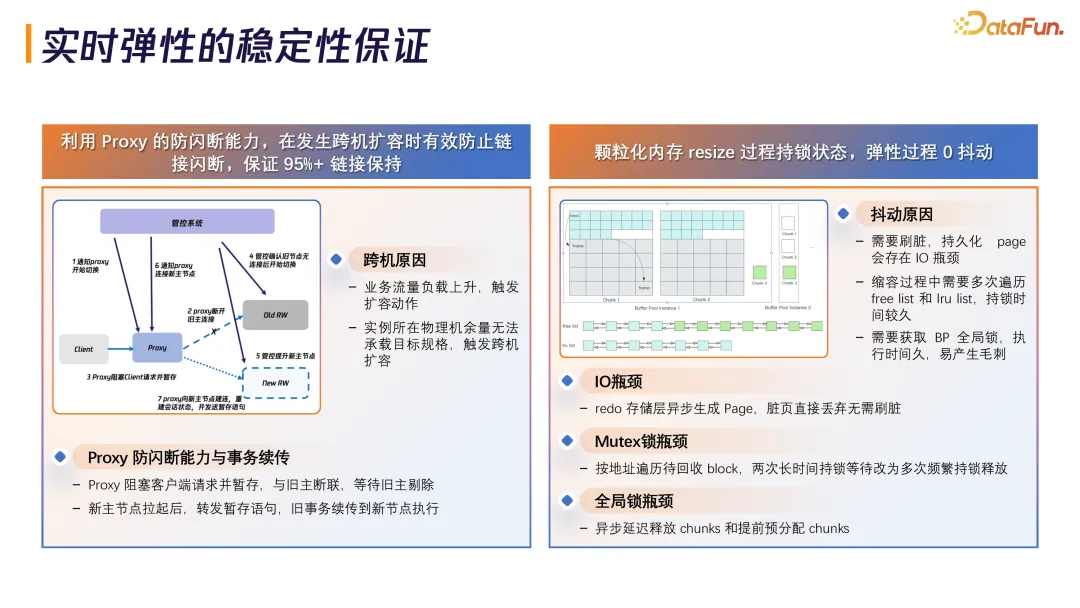
Proxy 防闪断能力:扩缩容时可能需要跨机扩容,Proxy 把流量兜住,底层节点切换时所有流量通过 Proxy Hold 住,针对不同语句做续传,跨机扩容时链接保持率达 95% 以上。
内核层面优化:缩容过程涉及内存 Buffer Pool 机制,传统 MySQL 方案要吃两次 Mutex 锁,TDSQL-C 改成频繁多次小锁,按地址遍历待回收 block。还解决了 IO 瓶颈(redo 存储层异步生成 Page,脏页直接丢弃)和全局锁瓶颈(异步延迟释放 chunks 和提前预分配 chunks),实现弹性过程零抖动,查询时长控制在 100 毫秒以内。
4. 可释放存储:触发式冷数据压缩与访问
TDSQL-C 研发了可释放存储技术,数据归档到二级存储(对象存储),释放一级存储。写请求以 redo 日志持久化,读请求以 Page 形式加载。写延迟和命中读延迟是百微秒级别,非命中读延迟是百毫秒级别,导入速度平均 5GB/s 以上。
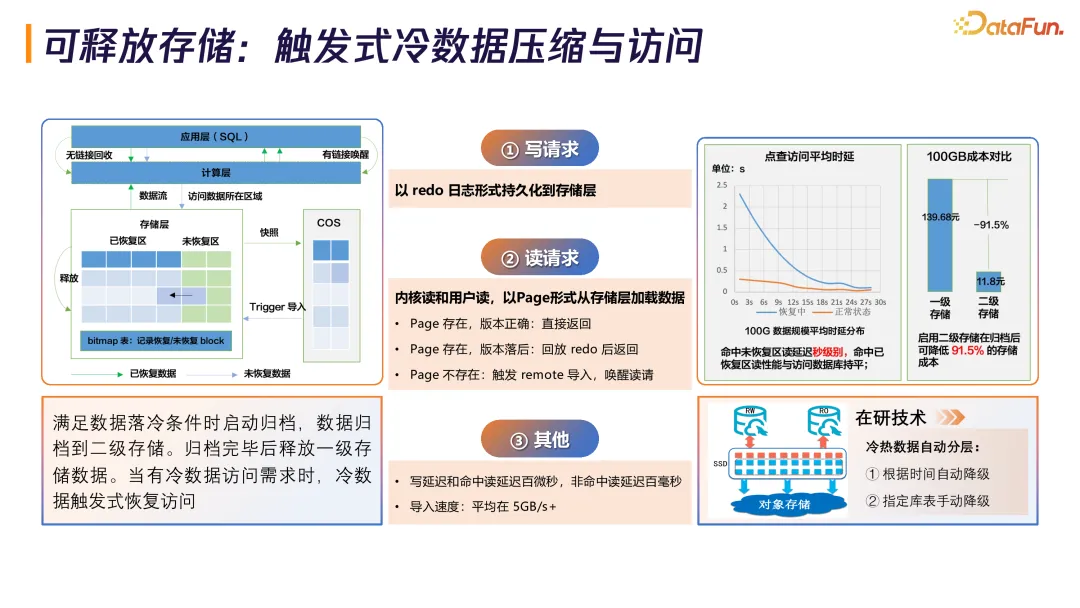
trigger 流程设计:"不是一次性把所有配置页都拉回来,而是根据用户请求,先把需要的配置页先拉回来。"采用异步方式,根据实际访问需求优先拉取所需 Page。
5. 实战案例
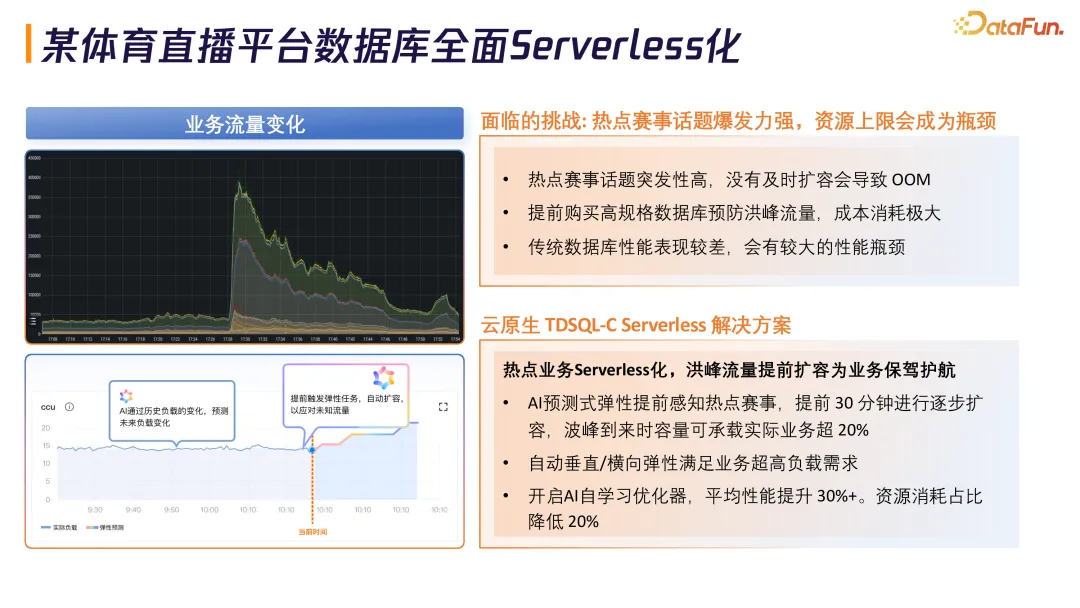
某体育直播平台面临热点赛事突发性高挑战。TDSQL-C Serverless 解决方案:AI 预测式弹性提前 30 分钟逐步扩容,波峰到来时容量可承载实际业务超 20%。开启 AI 自学习优化器后,平均性能提升 30% 以上,资源消耗占比降低 20%。
某证券平台面临周期性流量变化,TDSQL-C 采用一写八读架构,通过 Proxy 防闪断能力保障平滑变更。垂直弹性时,颗粒化 resize Buffer Pool 锁状态,过程无抖动,查询时长小于 100ms,跨机扩容时链接不断,业务无损。

03
AI 自学习优化器
在 POC 或投产验证中,性能 SQL 调优人力投入占比高达 47%,成为规模化复制瓶颈。线上工单分析显示,性能类问题平均处理时长 4.5 小时/单,占总时长 12.5%。
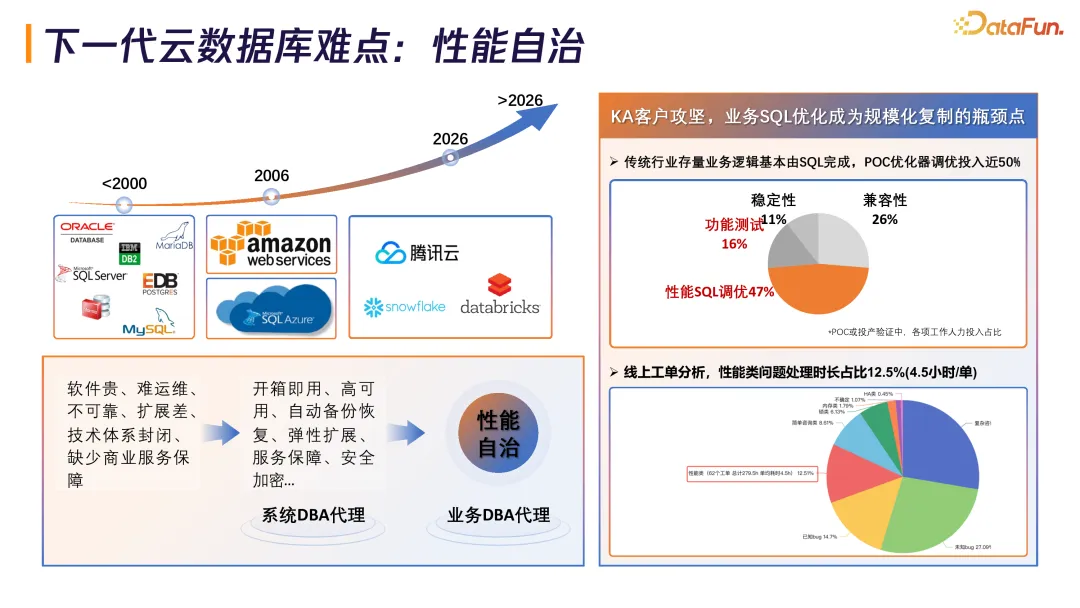
传统优化器面临三大局限:搜索空间爆炸(10 张表连接顺序约 360 万种);业务和系统资源动态变化,难达全局最优解;优化器模型需要长时间积累,Oracle 投入 40 年,百万级代码量。
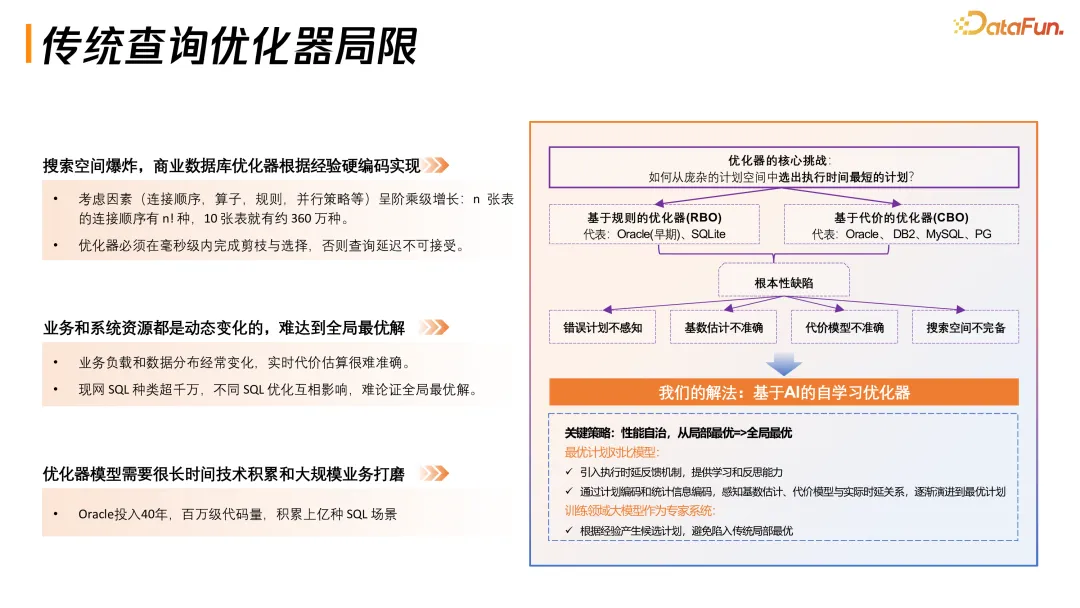
传统优化器四大根本缺陷:错误计划不感知、基数估计不准确、代价模型不准确、搜索空间不完备。TDSQL-C 的解法是基于 AI 的自学习优化器,从局部最优到全局最优。引入最优计划对比模型,通过执行时延反馈机制提供学习和反思能力。训练领域大模型作为专家系统,根据经验产生候选计划。
技术架构包括负载收集、全计划空间训练、指令微调加强化学习微调(SFT/RL),生成腾讯混元优化器大模型。数据库内核根据训练结果直接选择最优执行计划,在实例 1 中训练出的全局最优计划可供实例 2 至实例 N 复用,实现性能规模化自治。
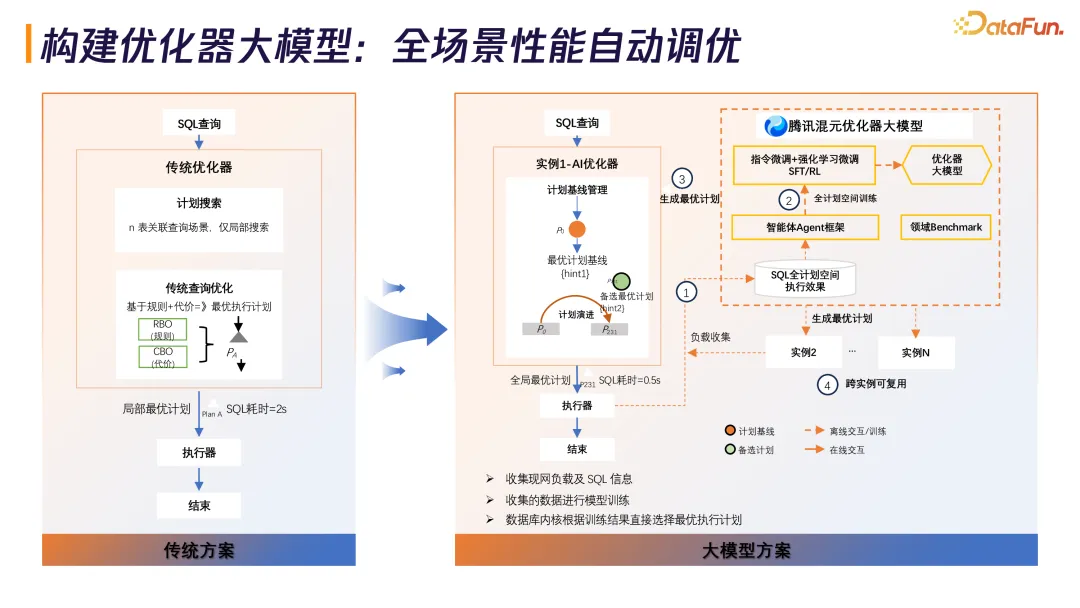
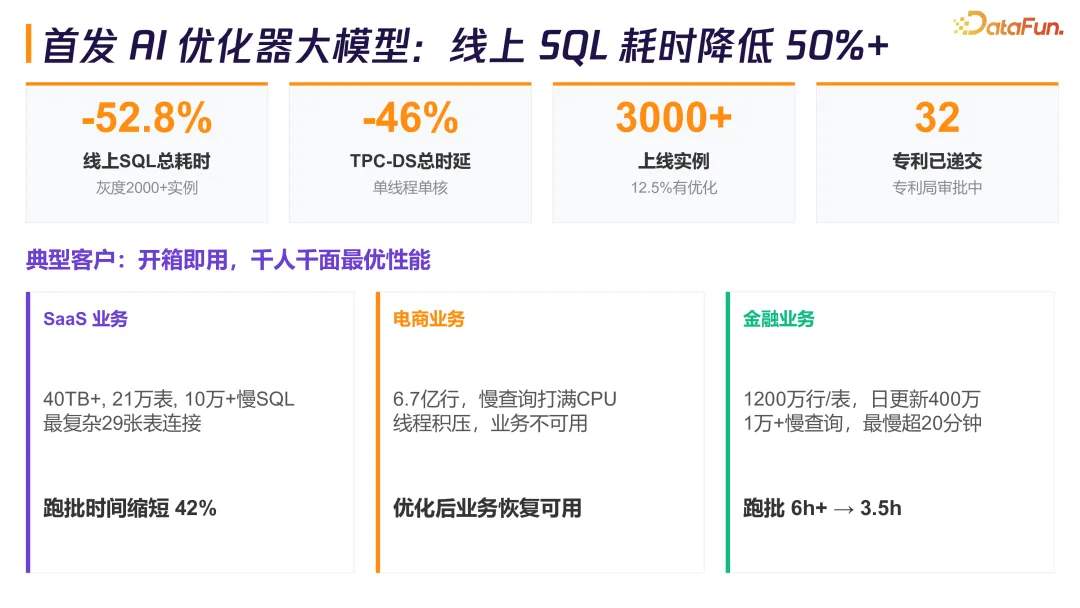
陈昊透露,这个技术结合了腾讯内部微信、支付等业务的优化经验训练大模型。效果显著:线上 SQL 总耗时降低 52.8%,TPC-DS 测试中总时延降低 46%。已灰度覆盖 2000+ 实例,上线实例总数超 3000+。针对拥有 40TB+ 数据、21 万张表、10 万+慢 SQL 的 SaaS 业务,跑批时间从 6 小时以上缩短至 3.5 小时,缩短 42%。
04
AI Navigator 智能数据库管理
AI Navigator 基于 Hermes Agent,实现从"被动存数"向"主动赋能运营"转变。

六大技术特性:三层持久记忆(短期上下文、跨会话长期记忆、技能记忆库,利用 FTS5 全文检索);闭环自主学习(自动提炼经验,自动生成可复用操作技能);7×24 小时后台运行(Daemon 模式,实时感知异常,秒级预警);本地数据主权(本地 SQLite 存储,五级权限管控);20+模型支持(集成腾讯云 TokenHub);多平台消息网关(企业微信、微信等IM平台)。
四个应用场景:业务指标实时洞察(自动识别业务表,T+1 延迟报表转化为实时业务看板);智能用户分层与精准运营(自动输出高价值/流失风险/加购未付人群包,提升 30% 以上转化率);实时业务风控(毫秒级主动防御,拦截高频刷单、跨区异常登录);AI 内核双向增强(结合 AI 优化器消除慢查询,降低 50% 以上 SQL 耗时)。

05
问答环节
Q1:AI 对 SQL 优化的具体策略是什么?是否包含预定义的知识和技能,以及动态调整?
陈昊:我们通过三个层面做优化。第一是内置的 AI 优化器,在内核层改变执行计划,比如算子选择用 Hash 还是其他方式,优化复杂查询。第二是提供相关 skill,把数据库参数调优经验(如 buffer pool)封装成专属 skill,内置到 Hermes Agent。同时利用大模型做业务 SQL 改写和联网搜索。我们结合了大模型、专属 Skill 和内核能力,构建完整 SQL 优化体系。
Q2:AI 时代到来后,数据库的使用场景发生了哪些变化?
陈昊:变化很大。国外 PG(PostgreSQL)已经跟 MySQL 用量一样了,因为 PG 有很多插件化能力,对多模支持好。AI 处理的东西很多,有图片、时序、向量等,AI 开发者希望后端能是单一的,支撑所有 AI 产品需求。比如构建 RAG(检索增强生成)底座,希望原生底座就能做,不需要搬到专门的向量数据库。更重要的是角色发生变化,以前是给 DBA 或业务用,现在对象变成了 AI,让 AI 更好地理解和调用数据库,还要解决上下文长度和持有期等问题。
📢活动预告
5月29日,腾讯云「数据库+AI」发布会将首次完整披露从“AI-In-Database”原生融合,到全面支撑Agent的演进路径与核心能力。
诚邀您见证“AI 原生重构数据库”的行业变革,共建下一代智能体应用的数据根基。
👇 扫码即刻报名!席位有限,先到先得!


往期推荐

点个在看你最好看
SPRING HAS ARRIVED

