 夜雨聆风
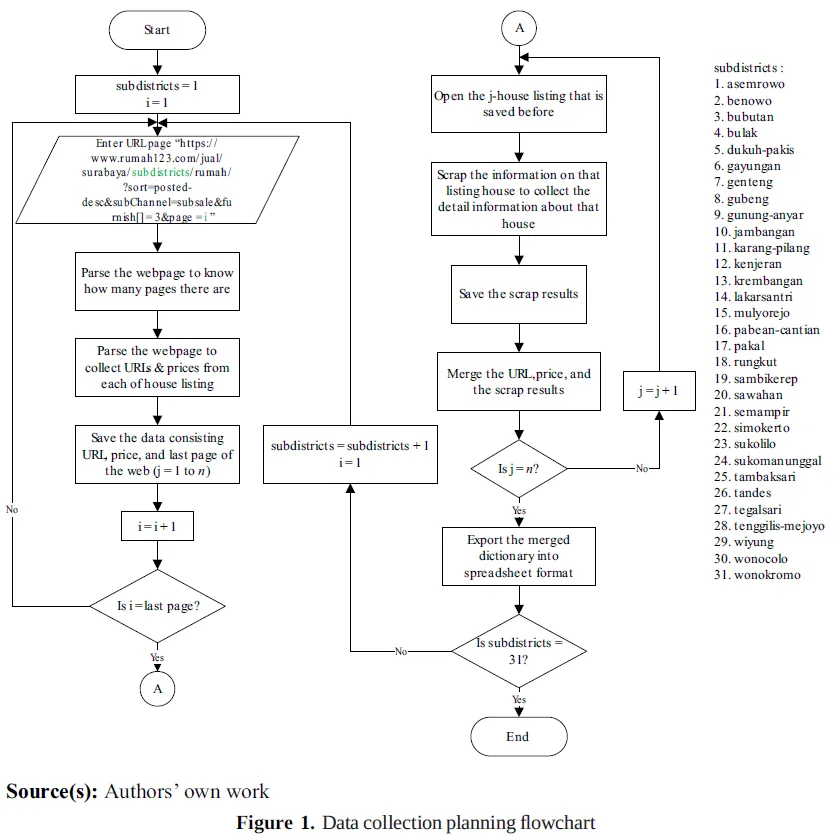
夜雨聆风研究者从印尼房地产平台 Rumah123 抓取泗水市住宅挂牌数据,覆盖31个片区。原始数据包括挂牌价格、所在片区、卧室数量、卫生间数量、土地面积、建筑面积、产权证书、电力容量、道路宽度、朝向、房屋状况等信息。文章中的 Figure 1 展示了数据爬取流程:研究者先按片区和页码获取房源链接与价格,再进入具体房源页面抓取房屋属性,最后合并成表格。Table 1(略)展示了各变量的缺失率,研究据此删除缺失严重的变量,并进行去重、缺失值处理和异常值处理。
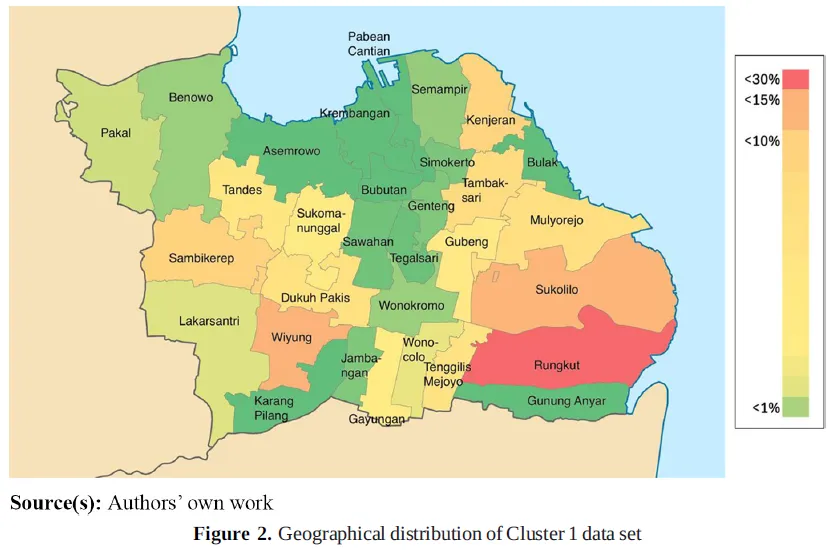
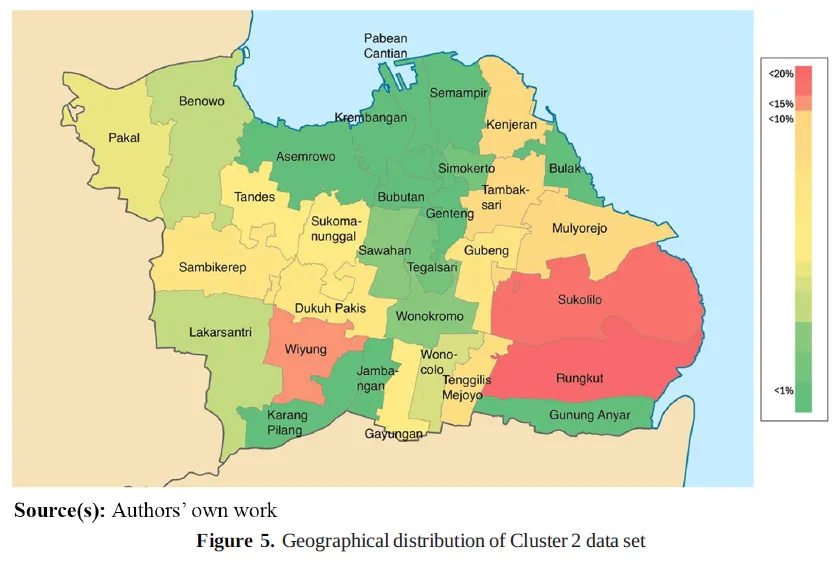
清洗后,研究形成 2562 条可用样本;进一步处理离群值后,最终保留 2460 条住宅数据。作者还通过 k-means 将样本划分为两个住宅子市场。Figure 2 和 Figure 5 分别展示了两个子市场在泗水市内的空间分布,可以看到样本主要集中在 Rungkut、Sukolilo、Wiyung 等片区。
2.方法
这篇文章比较了四种模型:多元线性回归、人工神经网络 ANN、支持向量机 SVM、分类与回归树 CART。四种模型面对的是同一类问题:给定房屋的面积、建筑面积、卧室数量、卫生间数量、片区、电力容量、道路宽度、房屋状况等变量,预测这套房子的挂牌价格。研究将数据按 70% 和 30% 划分为训练集与测试集,并使用 grid search 对模型参数进行调优。
2.1.多元线性回归
多元线性回归是最传统、也最容易理解的房价预测方法。它的基本思路是:房价可以由多个因素共同解释,例如土地面积增加多少、建筑面积增加多少、卧室数量增加多少、片区发生变化,都会对应一个价格变化。模型会为每个变量估计一个系数,再把这些变量加总起来,形成一个预测价格。文章中给出的公式就是:房价 = 截距 + 各变量系数 × 各变量取值。
2.2.ANN人工神经网络
ANN 人工神经网络可以理解成一套多层估价系统。第一层负责接收信息,比如土地面积、建筑面积、卧室数量、所在片区;中间层负责综合判断;最后一层输出预测房价。文章也明确说明,ANN 由输入层、隐藏层和输出层构成,隐藏层中的权重会在训练过程中不断更新,以减少预测误差。
它的计算过程可以这样理解:模型先随机给每个因素一个权重,然后根据这些权重算出一个房价。例如,一套房子的土地面积是 150 平方米,建筑面积是 180 平方米,位于某个片区,模型先算出一个预测价格。随后,模型把这个预测价格和真实挂牌价进行比较。如果预测低了,模型会调整相关权重;如果预测高了,也会反向调整。这个过程会在大量房源数据中反复进行。
ANN 的关键在于“中间层”。线性回归通常是直接把各因素加起来,而 ANN 会在中间层做多轮组合。例如,土地面积大本身会影响价格,土地面积大且位于热门片区又会形成另一种价格影响,建筑面积大且房屋状况好也可能形成新的价格影响。ANN 会从数据中学习这些复杂组合关系。
2.3.SVM支持向量机
SVM 支持向量机听起来复杂,但可以用“画线”来理解。假设我们只看一个因素:土地面积。横轴是土地面积,纵轴是房价,每一套房子就是图上的一个点。SVM 要做的事,是在这些点中间找一条尽量合适的线,用这条线预测房价。
如果因素变多,比如再加入建筑面积、片区、电力容量,图就会变成多维空间。SVM 仍然是在这个空间里找一条“最合适的边界”或“预测面”。文章中提到,SVM 的核心是寻找优化后的决策边界,并依靠少数关键样本,也就是 support vectors,来决定这个边界。
2.4.CART分类与回归树
模型先发现土地面积是最重要因素,于是先按土地面积分成“大面积房”和“小面积房”;在“大面积房”里面,模型继续发现建筑面积很重要,于是再分成“建筑面积大”和“建筑面积小”;接着模型可能再按片区或卧室数量继续分组。最后,一套新房进入这棵树,就会沿着这些判断规则一路往下走,最终落到某一个价格组里。
CART 的优点是直观,读者容易理解。它的缺点是容易受样本影响。如果某个分支里的样本很少,模型算出来的平均价格就可能不稳定。本文结果显示,CART 可以预测房价,但整体准确度低于 ANN 和线性回归。
3.结果
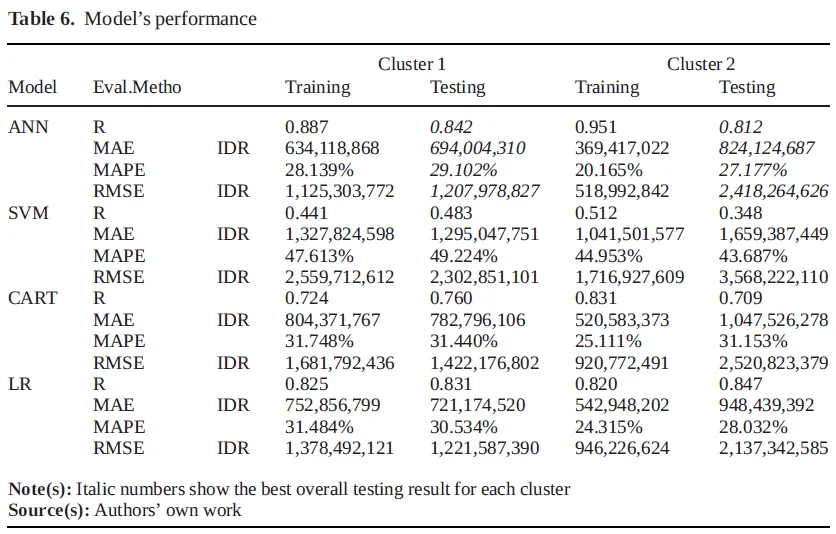
文章中的 Table 6是核心结果表。结果显示,ANN 整体预测效果最好。在 Cluster 1 中,ANN 测试集相关系数为 0.842,平均绝对百分比误差为 29.102%;在 Cluster 2 中,ANN 的平均绝对百分比误差为 27.177%。线性回归表现也较稳定,部分指标接近 ANN。CART 具备一定预测能力。SVM 在本文数据中的误差较大,整体表现最弱。
文章中的 Figure 6 和 Figure 7 展示了 ANN 模型的变量重要性。两个子市场中,土地面积都是最重要的房价预测变量。建筑面积、电力容量、片区位置、卧室数量等因素也会影响价格,但权重整体低于土地面积。
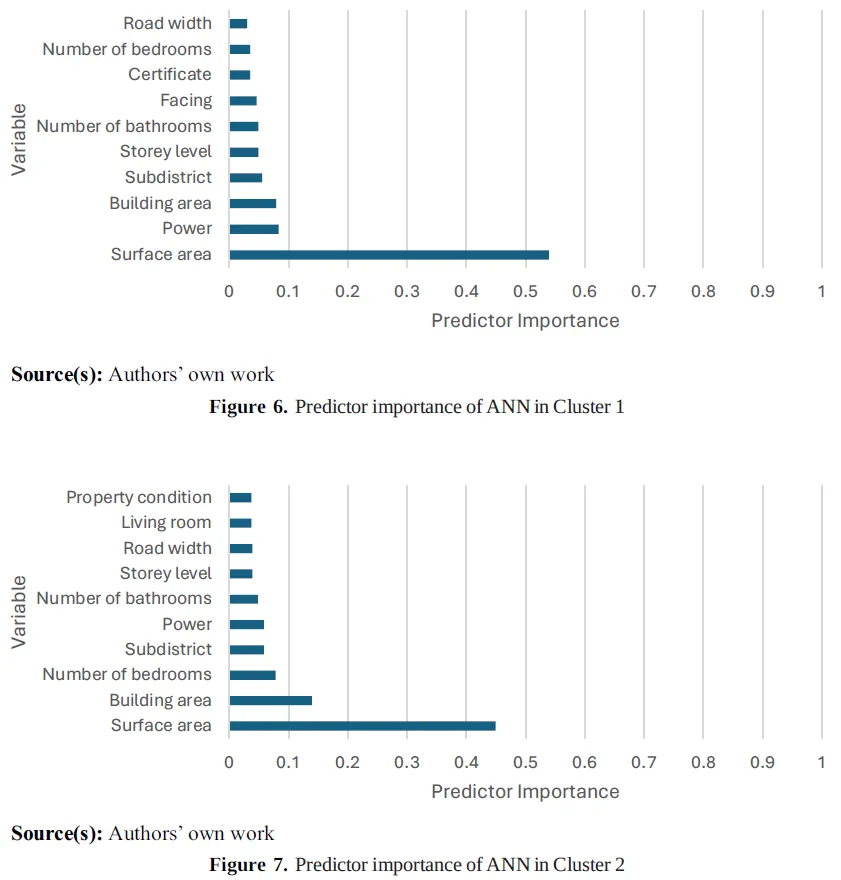
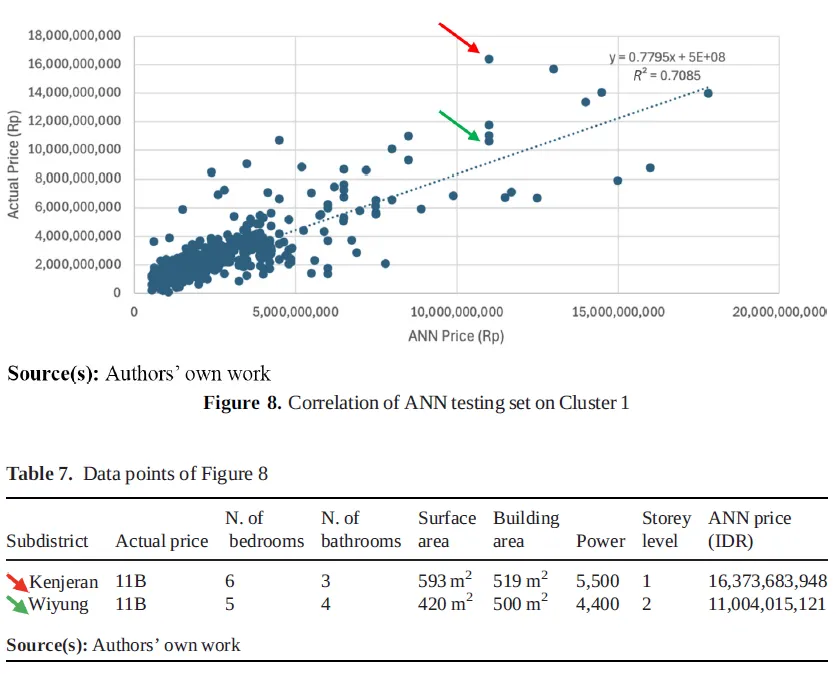
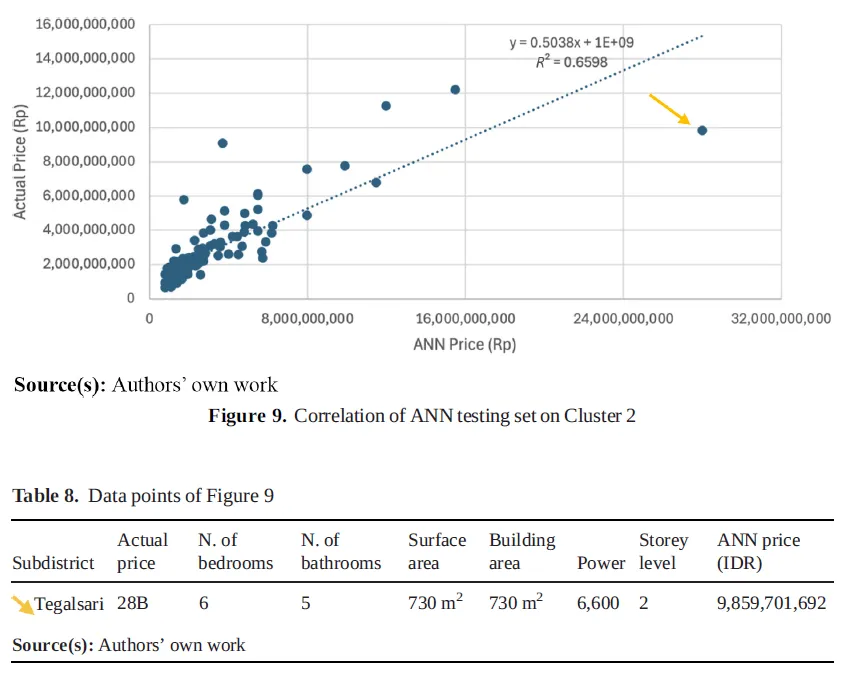
研究还展示了 AI 估价的局限。Figure 8 和 Table 7 比较了两个实际价格相同的住宅样本,模型因面积、电力容量和片区样本数量不同,给出了不同预测价。Figure 9 和 Table 8 展示了 Tegalsari 片区的一个高价住宅样本,由于该片区训练样本极少,模型明显低估了价格。
4.结论
人工智能已经可以参与住宅估价,并在一定程度上提高价格判断的客观性。对中介、投资者和买卖双方而言,模型可以提供更稳定的报价参考;对城市治理而言,模型也可服务于房产税评估、住房市场监测和空间规划。
房价预测的关键包括数据来源、变量质量、区域样本均衡度和子市场划分方式。AI 能让估价更精细,也让我们更清楚地看到:城市住宅价格始终嵌在具体的空间结构、市场供需和数据分布之中。
编辑:盒子鱼、Chat GPT 5.5
DOI:https://doi.org/10.1108/IJHMA-01-2025-0022
