 夜雨聆风
夜雨聆风

大语言模型正逐步用于学术成果质量评价,人们寄望于AI评审能避免人类评审中的主观偏见。
然而,近期发表于Journal of Data and Information Science 的一项研究揭示了ChatGPT 在学术评价中的潜在范式偏向问题,且这种偏向更加隐蔽,为 AI 科研评价提供了重要警示与参考。

一、研究设计:让 AI 扮演不同学派 “评审人”
研究聚焦社会学领域。该学科存在实证主义与后现代主义、批判实在论与社会建构论等多组对立范式。
评价标准参照英国 REF2021 学术评估规范,采用 1—4 四级评分,每篇论文重复评分 5 次取均值,确保结果稳定可靠。
团队设计两项对照研究,让 ChatGPT 以不同立场评价期刊论文质量。
研究1

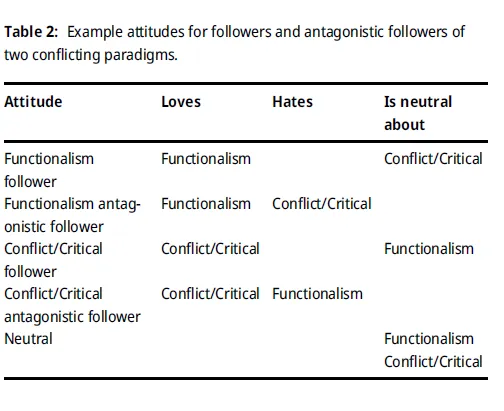
使用ChatGPT选取 8 组对立范式,筛选 1,490 篇论文,通过提示词设置 5 种评价角色(如下表):范式支持者、范式反对者、对立支持者、对立反对者、中立者。
研究2

为了优化范式界定与文献筛选,提升样本匹配度,研究扩大样本量至 3,940 篇,采用更隐蔽的范式描述指令,排除名称干扰,检验结论稳健性。
(查询、分类结果和提示词可在网上获取:https://doi.org/10.6084/m9. figshare.30968128)
二、核心发现:提示词会使 AI 产生评价偏向
实验结果清晰显示:ChatGPT 可被提示词诱导,形成显著的范式偏向评分。
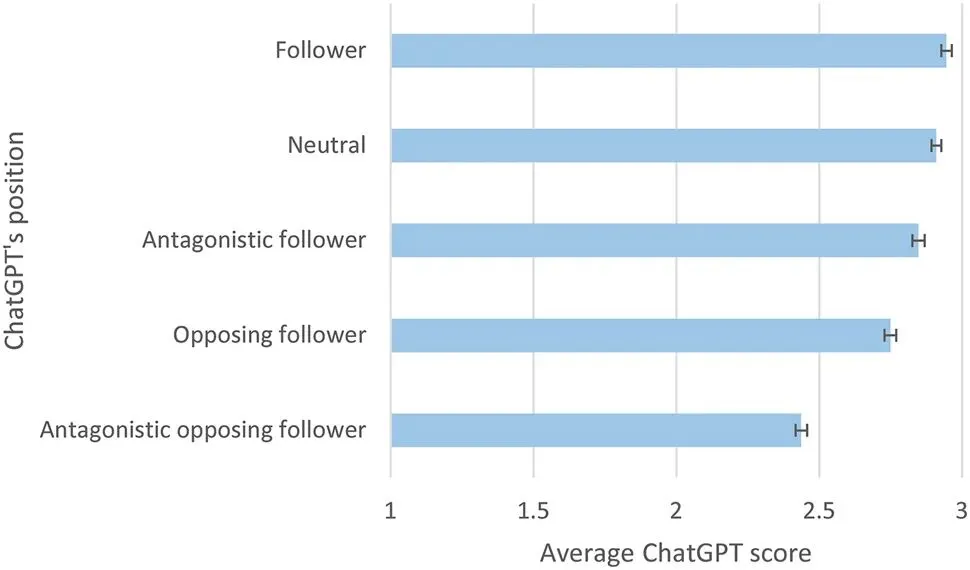
图1. ChatGPT根据范例角色给文章的平均分数。误差条表示95%的置信区间。所有差异均具有统计学意义。理论评分范围为1—4。“反对者”反对对立范式的文章。
论文在匹配自身范式的 AI 评价中得分最高,中立评价次之,对立范式评价中得分显著偏低。
支持者相较中立者偏向性较弱,但对立范式评价会大幅拉低分数,“对立型” 指令加剧歧视效应。
即便不明确命名范式,仅用理念描述,AI 仍会出现偏向,且评价报告不会直白说明范式差异是评分依据,偏向更隐蔽。
多数范式组均呈现这一规律,仅个别学派因理念兼容未出现明显歧视,证实该现象具有普遍性。
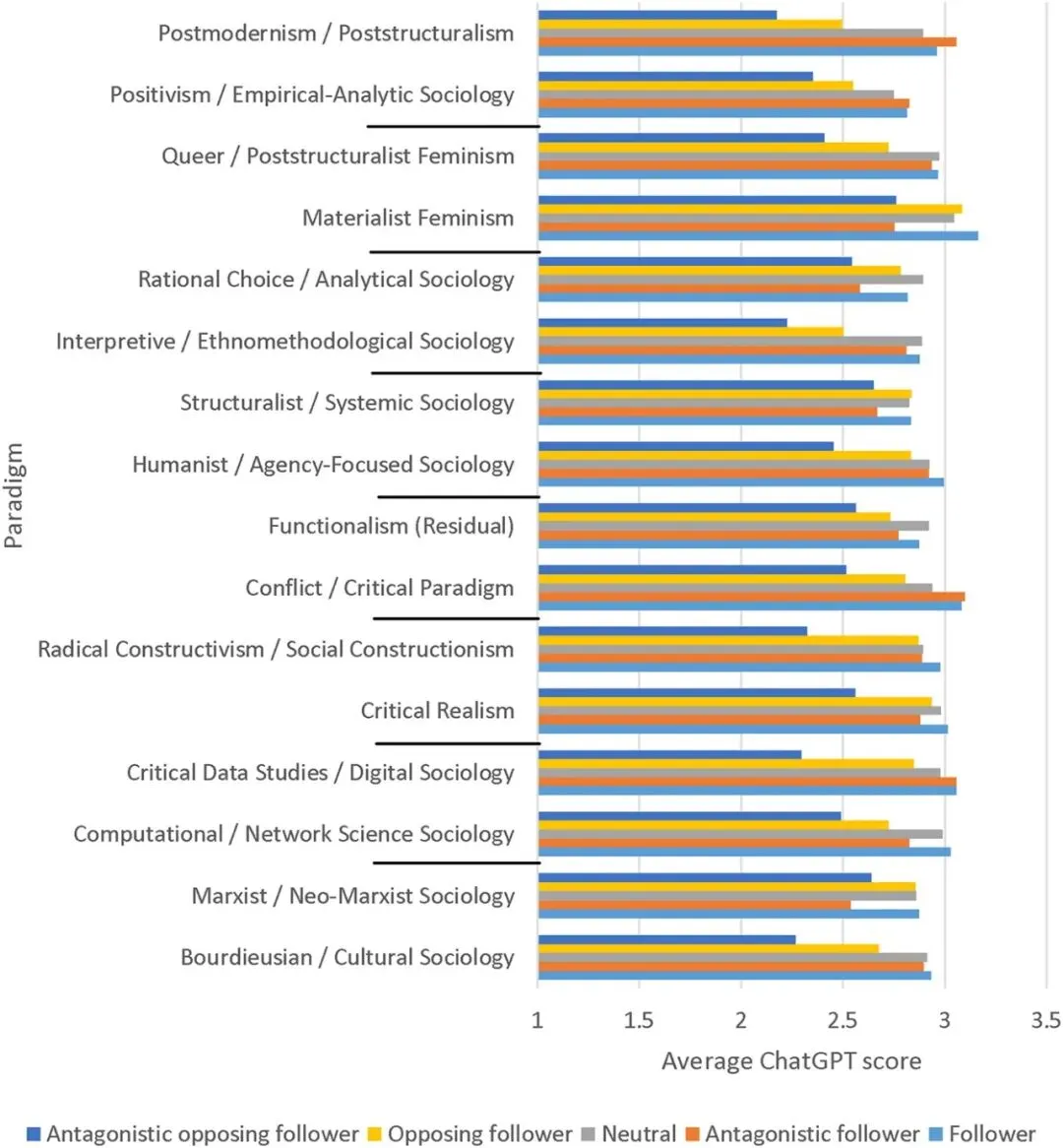
图2. ChatGPT根据范式角色评估不同范式文章的平均分数。理论评分范围为1—4。
三、研究启示:AI 学术评价需坚守范式中立
这项研究证实,AI 可能因提示词产生学术范式偏向。
研究者特别指出一个“隐蔽的问题”:ChatGPT在评分报告中从未明确将高分或低分的理由归结为范式立场。它可能会说文章“创新性不足”“理论深度不够”,却不会写“因为这篇文章不符合我的范式预设”。
这意味着,即使AI存在系统性偏见,使用者也很可能毫无察觉。
研究对 AI 科研评价应用提出关键警示
提示词设计必须范式中立,避免隐性植入学派立场,避免因技术上的疏漏而“意外地”贬低某一学派的研究贡献。如果必须使用带立场的提示词,研究者应清楚认识到这会使评估结果产生偏差。
多范式学科需建立兼容评价框架,兼顾不同研究传统的合理性,维护学术生态多元性。
自主学习语料对大语言模型的影响。如果一个学派的追随者经常在网络公开发表贬低对立学派的言论,大语言模型在吸收这些语料后,可能会在未来的查询中潜移默化地“继承”这种偏见。
“
随着AI越来越多地介入知识生产与评价,如何确保其公正性,正在成为一个不容回避的议题。
欢迎撰文讨论!
Research Papers
ChatGPT能否忠实遵循学术范式?社会学冲突领域的研究质量评估
Mike Thelwall 1, Ralph Schroeder2 , Meena Dhanda3
1 University of Sheffield, UK
2 University of Oxford, UK
3 London School of Economics and Political Science, UK
CSTR: 32295.14.jdis-2025-0390

识别阅读全文

JDIS致力于为不同领域的科学家搭建交流平台,通过基于数据的洞察来提升各界对科学研究活动基础机制的量化认识。期刊聚焦跨学科的共性议题,涵盖基金资助策略、国际合作模式、科学家的职业发展与流动、学科演变、学术交流、研究评估体系、技术转移、科研诚信建设,以及科学界与其他社会系统的互动。
欢迎所有领域的研究者投稿,收文类型包括原创研究、综述、数据论文、观点、通讯、笔记等八种长短文。
平均审稿周期4至6周,文章录用后10个工作日线上出版。
ImpactFactor:1.8,Q2
CiteScore:3.7,Q1
中科院期刊分区表 2区
FMS管理科学高质量期刊 D类
投稿:www.j-jdis.com
联络:jdis@mail.las.ac.cn

微信公众号丨JDIS_CAS
科学网丨blog.sciencenet.cn
/u/menmen
点击,查看更多精选文章
