夜雨聆风
夜雨聆风现在AI正加速从赛博空间向物理空间转化,每个智能体都需要独立的cpu,gpu,存储器,当前产业链远远不足,每年产能翻倍都满足不了。
如果相信AI带来的智力平权,把生产力能放大千倍万倍,全球整体经济规模会空前暴涨,那这一切都还非常早,还是新世界诞生的前夜,现在只是AI引起的一点点小浪花。
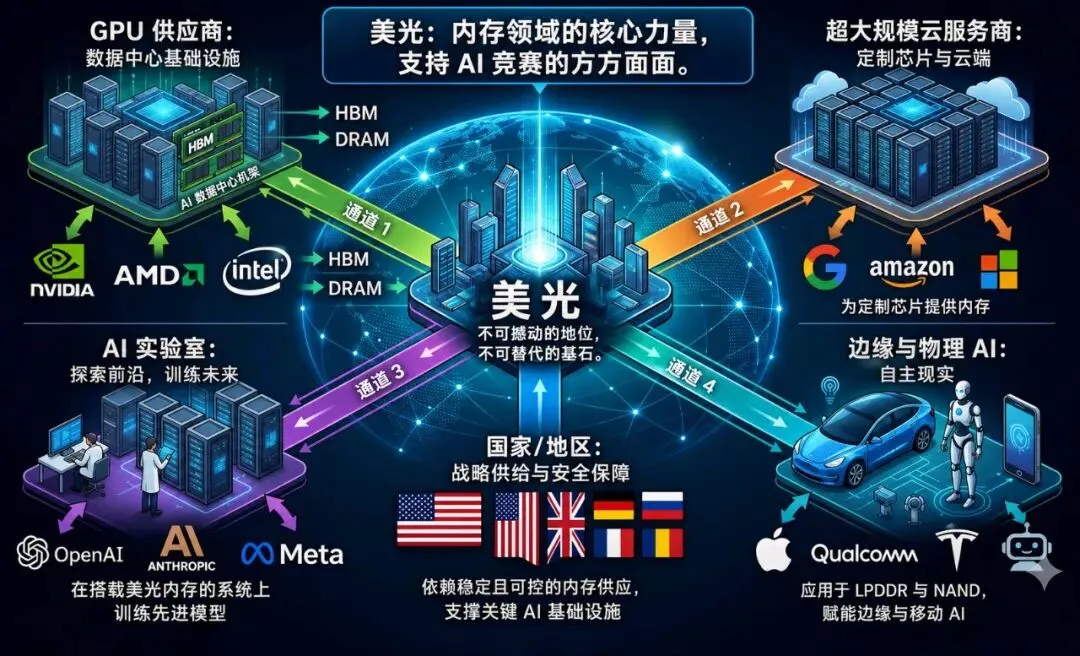
美光最被低估的上行潜力不是HBM需求,而是内存内处理(PIM)和内存内计算(CIM)。这不是对内存的渐进式改进,而是对计算本身潜在的重构。
如果内存从被动存储演变为计算相邻层甚至计算集成层,美光的作用将发生根本性转变。它将不再是周期性组件供应商,而是成为核心计算基础设施的一部分。这种区别正是能够证明20–30倍市盈率的依据,而不仅仅是搭乘AI内存周期的顺风车。
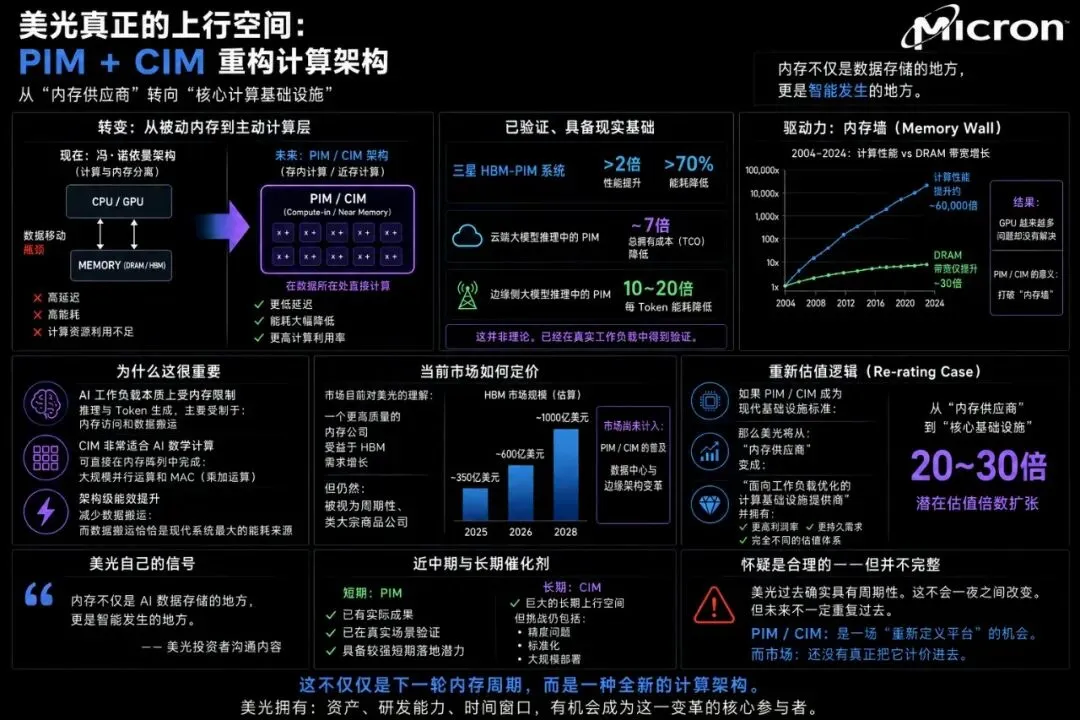
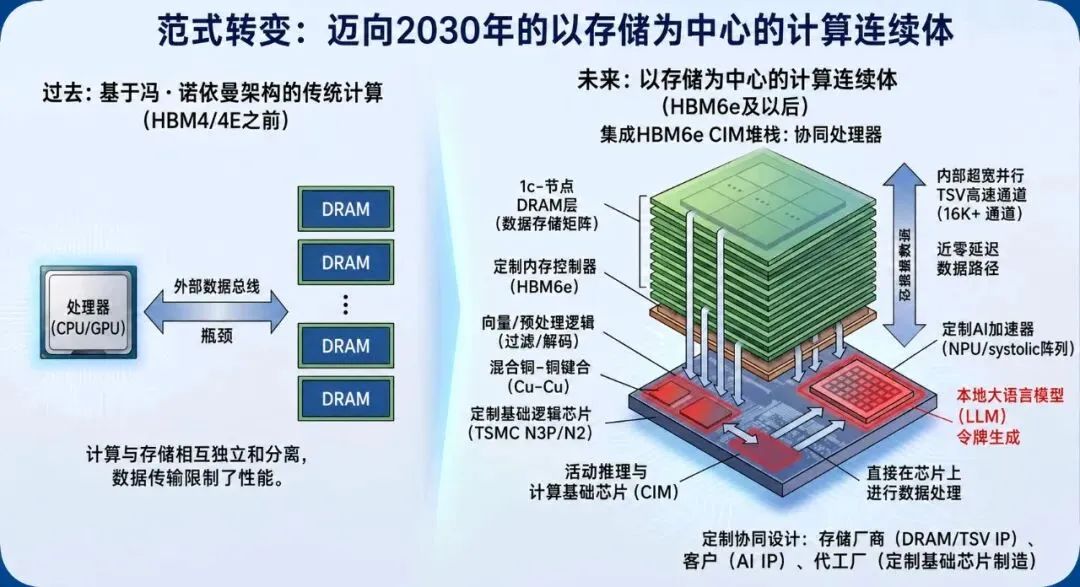
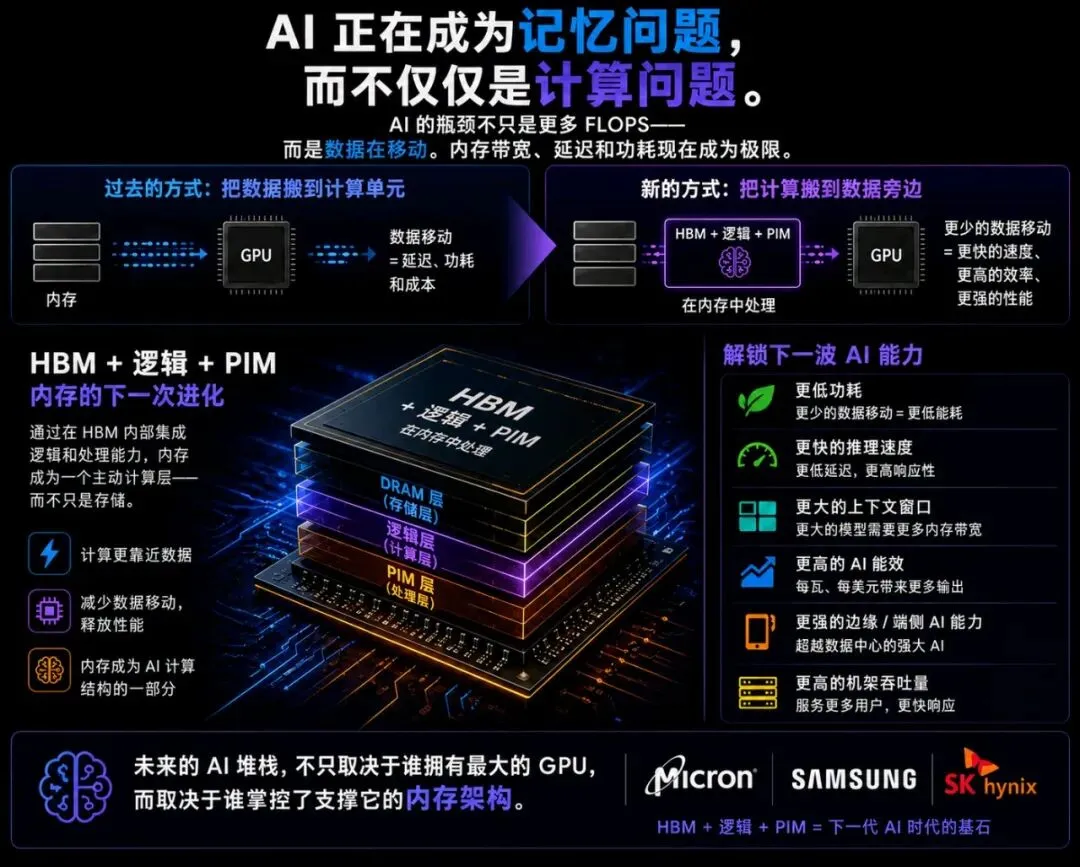
这一转变背后的驱动力是“内存墙”。过去二十年,计算性能提升了约60,000倍,而DRAM带宽仅改善了约30倍。这种不平衡意味着添加更多GPU越来越多地导致计算资源因数据瓶颈而未被充分利用。PIM和CIM通过将计算移至数据已驻留的位置,直接解决这一问题,从而在架构层面减少数据移动和能耗。
这之所以重要,是因为现代AI工作负载,尤其是推理和令牌生成,主要受内存访问和数据移动主导,而非原始计算。CIM架构特别适合这些工作负载,因为它能够在内存阵列内直接启用大规模并行操作,如乘累加。
如今,市场将美光视为一家受益于HBM驱动需求的高质量内存公司。这仍是一个周期性、商品相邻的叙事。但如果PIM/CIM成为数据中心和边缘架构的标准,美光的位置将发生变化。它将成为差异化、针对工作负载优化的基础设施提供商,具备结构性更高的利润率和更持久的需求。
美光本身已暗示这一转变,将内存定位为AI“认知”功能的核心,而非辅助组件。与此同时,仅HBM预计将从2025年的约350亿美元增长至2028年的1000亿美元。这一估计尚未完全计入PIM/CIM的采用。
短期内,PIM是更具现实催化剂,已在真实AI推理工作负载中展示出显著收益。CIM提供更大的潜力,但仍面临精度、标准化和部署方面的挑战。
对美光的怀疑源于其作为周期性内存生产商的历史。这一历史是真实的。但它可能无法定义未来。
英伟达 H100 标志着 AI 从实验阶段转向云端大规模部署。内存处理(PIM)和内存计算(CIM)可以为物理世界带来同样的变革。

首先,它们实现了边缘的真正独立。像机器人或智能系统这样的设备可以在本地运行大型视觉-语言-行动模型,而无需依赖云连接。这消除了延迟,降低了故障风险,并允许实时决策。
其次,它们从根本上改变了硬件设计。与其将昂贵的处理器与独立的内存结合,不如让计算直接在内存内部发生。这简化了系统架构,并降低了构建先进智能设备的成本。
H100 时代是关于在大型数据中心集中 AI 的。PIM 和 CIM 代表了相反的转变:将智能分布到各处。它们使 AI 能够超越服务器机架,直接在现实世界中运行。
这是下一波浪潮……三大 HBM 领导者……SK 海力士、三星和美光正在汇聚于同一个战略终点:将先进逻辑直接嵌入内存堆栈下方。这正迅速成为 AI 硬件领域的核心战场,并标志着计算架构的结构性转变。

为什么这尚未被广泛讨论?尽管其重要性,此转变仍被低估,原因有三:
1. 它是隐形的:公众叙事聚焦于 GPU 和加速器,而 HBM 堆栈内部日益增强的智能被埋藏在技术细节中。
2. 软件隐藏了它:开发者与高层框架如 CUDA 或 PyTorch 交互,这些框架抽象了计算实际发生的位置。
3. 过时认知:内存公司仍被视为大宗商品供应商,而非先进逻辑和封装的新兴领导者。
实际变化是什么?这不仅仅是渐进改进,而是新架构的早期阶段。
随着逻辑移入内存堆栈,处理器与内存之间的传统分离开始瓦解。曾经分布在主板上的系统正坍缩成紧密集成的系统级封装设计。
到 HBM4E 和 HBM5 时,基底芯片将不再是被动控制器,它将成为主动计算层。届时,“内存”和“处理器”将不再是清晰可分的类别。
其含义显而易见:内存供应商不再仅仅是带宽的提供者。他们正成为定义 AI 系统架构的核心玩家,并可能成为整个计算堆栈的守门人。
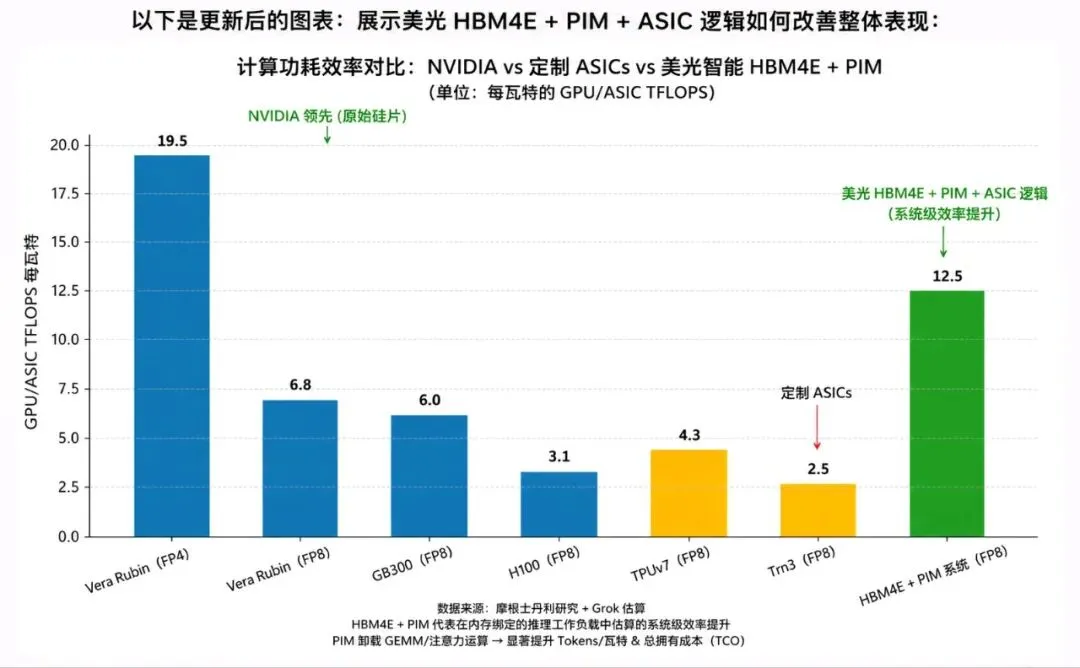
从本质上讲,这是一场权力转移。今天,NVIDIA掌控着AI基础设施的大脑。但如果计算迁移到内存中,这种控制权就开始向那些制造和设计内存本身的公司转移。
如果计算更接近内存,AI硬件栈将变得更模块化、更少集中化,超大规模云服务商不再从NVIDIA购买整体系统,而是组装自己的:定制逻辑(ASIC)、 先进内存(HBM + PIM)、内部软件生态系统,这种转变打破了当前层级结构。
NVIDIA 失去了作为单一瓶颈的地位。内存供应商获得了结构性重要性和定价能力。超大规模云服务商重新获得了对成本和架构的控制权。实际上,数据中心的“大脑”不再是单一芯片,而是变成一个分布式系统,其中内存扮演核心角色。