 夜雨聆风
夜雨聆风🔥 MinerU:PDF文档一键转Markdown,LLM数据预处理神器

64k+ Stars 的开源文档解析引擎,支持 PDF/Office 多格式输入,自动 OCR 识别、公式转 LaTeX、表格转 HTML,输出 LLM 即用型 Markdown/JSON。写论文、喂 RAG、训模型,全是它的主场。


🚀 什么是 MinerU?
MinerU 是由上海人工智能实验室 OpenDataLab 团队开源的文档智能解析工具。它能将复杂文档(PDF、图片、DOCX、PPTX、XLSX)转换成 LLM 友好的 Markdown 或 JSON 格式,解决「文档进、AI 吃」之间的中间处理难题。
传统 PDF 解析工具普遍存在几个硬伤:多栏排版错乱、扫描件无法识别、公式变成乱码、表格脱框。MinerU 用一套端到端的方案把这些坑全填了。
核心定位:文档解析界的瑞士军刀,64k Stars 不是盖的
适用人群
AI 应用开发者:RAG 系统文档预处理、知识库自动构建 科研人员:论文 PDF 批量解析、公式提取 数据工程师:训练数据清洗、PDF 结构化抽取 教育从业者:教材数字化、题库自动化
核心功能一览
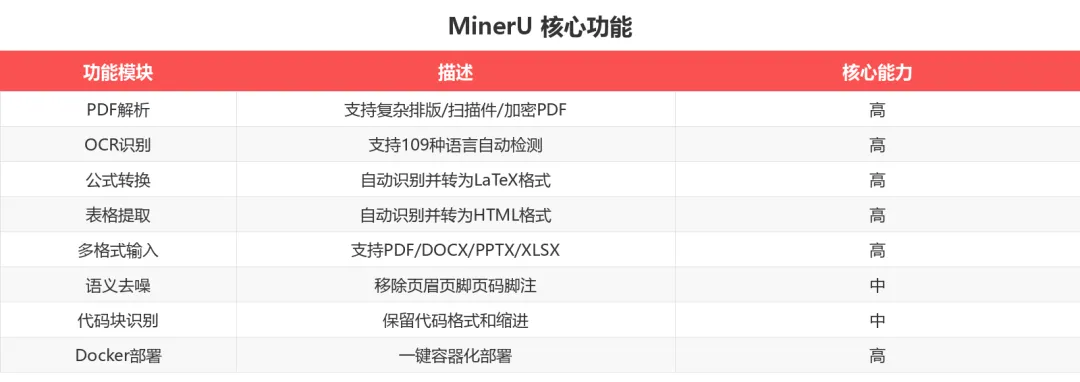
🛠️ 5 分钟快速上手
安装
MinerU 一键安装,有多简单?
# pip 安装(推荐 uv,比 pip 快 10 倍) pip install --upgrade pip pip install uv uv pip install -U "mineru[all]" # 或从源码安装 git clone https://github.com/opendatalab/MinerU.git cd MinerU uv pip install -e .[all] # Docker 部署 docker pull opendatalab/mineru:latest 注意:加 [all] 安装所有核心功能,包含 OCR 引擎和公式识别模型
基本使用
一行命令,PDF 秒变 Markdown:
# 单文件解析 mineru -p input.pdf -o output/ # 批量处理整个目录 mineru -p ./pdfs/ -o ./output/ -b pipeline # 解析结果包含:Markdown + JSON + 图片 + 表格 + 公式 Python SDK 调用
from mineru import MinerU parser = MinerU() result = parser.parse( pdf_path="paper.pdf", output_format="markdown", ocr_enabled=True, formula_recognition=True, table_extraction=True ) print(f"正文字数: {len(result.text)}") print(f"图片数: {len(result.images)}") print(f"表格数: {len(result.tables)}") result.save("output.md") result.save("output.json", format="json") 一行代码集成到 LangChain RAG:
from mineru import MinerU from langchain.text_splitter import RecursiveCharacterTextSplitter parser = MinerU() md_content = parser.parse("report.pdf").text splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) chunks = splitter.split_text(md_content) # 直接喂给 vector store! 与竞品对比
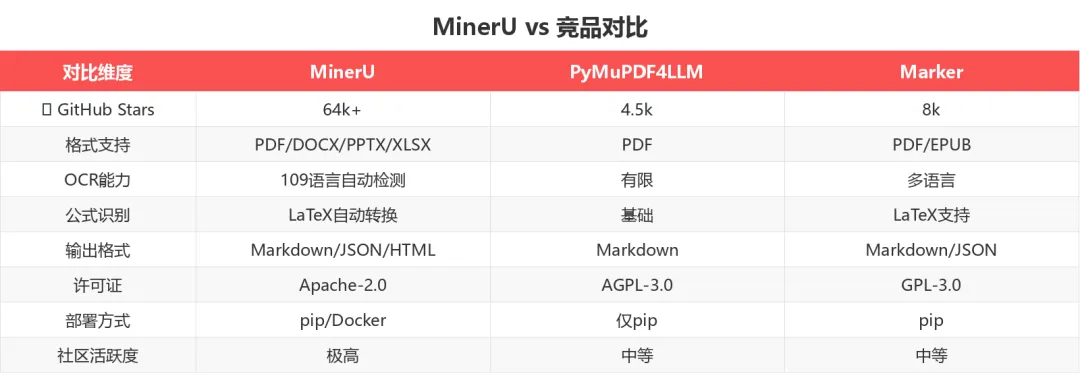
适用场景
1. RAG 知识库文档预处理
将企业文档(PDF 合同、Word 报告、Excel 数据表)一键转 Markdown/JSON,喂给向量数据库。
import os from mineru import MinerU parser = MinerU() docs_dir = "company_docs/" for fname in os.listdir(docs_dir): if fname.endswith(('.pdf', '.docx', '.pptx', '.xlsx')): result = parser.parse(os.path.join(docs_dir, fname)) result.save(f"parsed/{fname}.md") print(f"处理完成: {fname}") 输入要求:任意格式的文档文件 输出效果:干净的结构化 Markdown/JSON 适用场景:企业内部知识库、法律合同分析、财务报告处理
2. 学术论文批量解析
自动检测 PDF 中的数学公式,转换为 LaTeX 代码。表格自动转为 HTML,保留原格式。
输入要求:论文 PDF(含排版复杂的双栏、公式、图表) 输出效果:LaTeX 公式保留、表格结构化、图片分离 适用场景:论文综述写作、题库整理、教材数字化
mineru -p papers/ -o papers_output/ -b pipeline 3. 训练数据清洗流水线
扫描件自动 OCR 识别,109 种语言自动检测。语义去噪能力自动移除页眉页脚页码。
输入要求:扫描件 PDF、老旧文档 输出效果:干净的训练数据 适用场景:LLM 训练数据处理、多语言语料构建
用户群体总结
AI/ML 工程师:RAG 数据预处理,行业标准 科研人员:论文批量解析、公式提取 教育从业者:教材数字化、题库自动化 企业文档团队:合同/报告批量结构化
开源与协议
MinerU 是完全开源的项目,Apache-2.0 协议,商业使用零限制。
开源协议: Apache-2.0 GitHub 仓库: opendatalab/MinerU
完全免费开源,Apache-2.0 对商业使用零限制
总结
MinerU 是目前社区规模最大的开源文档解析工具。64k Stars 不是凭空来的——它解决了 AI 时代最基础也最头疼的问题:让机器看懂文档。
推荐指数: 五颗星
适合人群: AI 工程师、科研人员、教育从业者、企业文档团队
GitHub 仓库:opendatalab/MinerU
在线体验:mineru.net WebApp
数据截至 2026-05-21,最新信息请以官网为准。
