 夜雨聆风
夜雨聆风🍃作者介绍:AI 应用负责人/AI产品架构师,阿里云专家博主。专注 LLM 应用开发、Agent 系统设计、具身智能与工业 AI 落地。日常在大模型训练、Coding Agent 工具链、AI 产品商业化等方向持续输出实战内容。🐼GitHub主页:https://github.com/XZL-CODE
文章目录
1、前言:AI 圈最近吵的事2、AI 写字到底怎么"写"的3、ELF 登场:用"先画后写"魔法4、它凭什么吊打过去的扩散派5、连续 DLM 这条路走了 5 年6、它在工程上的意义(人话版)7、它真的赢了吗?小白也要知道的争议8、未来:ChatGPT 真的会变成"画"出来的吗9、写在最后

1、前言:AI 圈最近吵的事
先讲一个画面。
如果你今年五月还泡在 AI 圈,可能注意到一件挺有意思的事。一篇 32 页的论文挂上 arXiv,作者团队的最末尾印着三个字——何凯明。论文的题目叫 Embedded Language Flows,简称 ELF。论文挂出来不到一周,X(推特)上、知乎上、各种群里就开始炸锅,吃瓜表情包刷屏。有人喊"扩散派翻身了",有人冷冷甩一句"32 步赢了 1024 步,你比的是个啥",还有人跳出来盖章:这是 AI 写字(也就是大语言模型)下一站的入口。

我看完整篇论文之后的第一反应是:有点东西,但也确实有点滑头。所以这篇博客我想做两件事:
• 把 ELF 用大白话讲清楚:不放公式、不放推导,就用比喻和故事,让没听过 Diffusion / Flow Matching 的朋友也能听明白; • 把围绕它的争议也用大白话翻译一遍:吹的人在吹什么,骂的人在骂什么,你听完自己来判断到底是不是"里程碑"。
这篇文章的目标读者很简单——你能听懂"模型""训练""生成"这三个词,剩下的就交给我。
「明天发布 ELF 深度精读-从数学原理到对抗性审视」
友情提示:本文不假设你懂 Diffusion,也不假设你懂 Flow Matching、CFG、self-conditioning 这些黑话——我们会一个一个用比喻拆开。
2、AI 写字到底怎么"写"的
聊 ELF 之前,得先聊一个被大多数人误以为只有一种答案的问题:
AI 是怎么把一段话"造出来"的?
你大概率以为答案就是"ChatGPT 那种一个字一个字往外蹦"。其实远不止。AI 写字目前江湖上至少有三大门派,三派之间从 2022 年吵到现在还没歇。咱们一个个看。
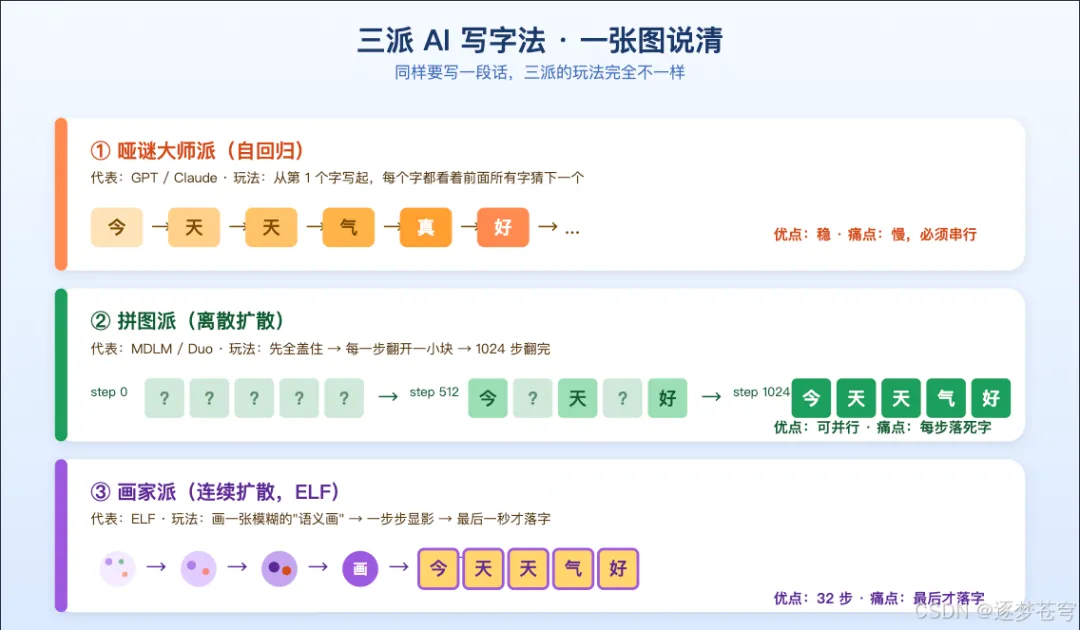
2.1 哑谜大师派(自回归 GPT 类):一个字一个字猜
这是你最熟悉的一派,ChatGPT、Claude、Gemini、Qwen、DeepSeek 全在这条路上。术语叫"自回归(Autoregressive)",听上去高大上,其实做的事很朴素:
从第一个字开始,看着前面已经写出来的所有字,猜下一个字。猜完,把猜出来的字接上去,再去猜再下一个字。
像不像一个写哑谜的大师?
每一个字都要"接得上"前面的,所以质量稳、文风一致、逻辑顺。GPT-4、Claude 这种水准的对话流畅度,都是靠这条路堆出来的。
• 优点:写出来的东西像人话,模型结构成熟,能 scale 到上万亿参数。 • 缺点:慢。每个字都得等前面写完才能写。你今天用 ChatGPT 让它写 3000 字小说,它没法"并行写",每个字都得严格按顺序蹦出来,所以你能看到字一个个跳,跳到地老天荒。
哑谜大师派的核心痛点就这一个字:慢。
2.2 拼图派(离散扩散 MDLM 类):先盖住再一块一块翻开
第二派叫 离散扩散语言模型(Discrete Diffusion Language Model,简称离散 DLM)。代表作有 MDLM、Duo、E2D2 这些名字。这一派试图解决哑谜大师派的"慢"问题。
它的玩法是:
先把整段话"全盖住",变成一连串问号
?????????????,然后让模型每一步翻开一小块格子,把里面的"?"换成真字。反复多次,直到所有问号都变成字。
像不像在玩 填字游戏 / 一块一块翻牌?
这一派最大的好处是可以并行翻牌——一步可以同时翻好多块,理论速度比哑谜大师快得多。听上去很美?但有个隐藏的烦人之处:
每一步都必须给出"确定的字"。不能写半个字,不能写模糊的字,不能写"差不多是这个意思"的字。
这就好比你玩拼图,规则要求你每翻一块,这一块就立刻焊死,再也不能改。所以为了不出错,你得反复来回翻,得很谨慎地翻。结果就是——为了稳,模型一般要走 1024 步才能凑齐一段质量过关的话。
它快没快?只能说理论上能并行,实际上为了质量并不真的有那么快。
2.3 画家派(连续扩散):本来想这么干,但一直效果不行
第三派的灵感来自 AI 画图。
你用过 Stable Diffusion 或者 MidJourney 吧?画图模型的玩法是:
从一张乱糟糟的彩色雪花图(纯噪声)开始,每一步轻轻"擦一笔",让雪花慢慢"显影"成一张精美的画。
画图领域近几年所有大爆款(DALL·E、Stable Diffusion、Sora、可灵)都走的是这条路,统称 扩散模型(Diffusion) 或者 流匹配(Flow Matching)。
那很自然的问题就来了:
画图能这么"显影"出来,写字能不能也"显影"出来?
研究者从 2022 年就开始尝试这条路,整整 5 年——全都效果不行。要么质量上不去,要么训练特别费劲,要么得加各种七拼八凑的补丁才能勉强工作。
所以业界慢慢形成了一个共识,甚至变成了"行业偏见":
文字是离散的("猫"和"狗"是两个完全不同的符号,中间没有半个猫半个狗),不像图像可以连续变化。所以扩散模型"显影写字"这条路注定吃亏。
整整五年,画家派的存在感都是个"科研笑话"——大家觉得这路就是死胡同。
直到这次 ELF 出场。
3、ELF 登场:用"先画后写"魔法
ELF 走的就是上面说的第三派——画家派。但它做了几个极其聪明的小手术,让这条被认为是死胡同的路,第一次被走通了。
整个 ELF 可以用一句话总结:
AI 不是在写字,是在"画一张关于这段话的模糊语义画"——画完最后一笔,才把画"翻译"成具体的字。
听上去很玄?我们拆成四块讲。
3.1 把字变成"灵魂光球"(T5 embedding 比喻)
第一步要解决的问题是:文字是离散的,怎么让画家派能"连续地画"?
ELF 的招数是——先把字翻译成连续的东西,再去画。
它借用了 Google 一个老模型 T5 当"翻译器"。T5 干什么呢?它把每一个字(更准确说,每一个 token),变成一组512 个数字组成的小向量,术语叫 embedding(嵌入向量)。
听到向量你别慌,咱们用比喻:
embedding 就像把每个字的"灵魂"抽出来,变成一团有方向、有距离的小光球。
"猫"的光球和"狗"的光球离得近(都是宠物,软乎乎、四条腿、会叫);"猫"和"汽车"的光球离得远(差太多了);"猫"和"小猫咪"的光球几乎重合。
一旦字变成光球,奇迹发生了——光球之间可以连续地变化。你可以从"猫"的光球,沿着一条平滑的路径,慢慢飘到"狗"的光球,途中每一个位置都是一个"有意义的中间状态"。
一旦能"连续变化",画家派那一套"轻轻擦一笔"的玩法就有用武之地了。
小补充:ELF 用的是 T5 已经预训练好的 embedding——相当于借了一本现成的高级翻译词典,省去了自己从头学的麻烦。论文里还做过对比:用 T5 预训练 embedding 比让模型从零自己学,效果好得多。
再深一层的细节:T5 出来的"灵魂光球"原本是 512 维(一个光球由 512 个数字描述)。ELF 没有直接在 512 维上"画",而是先把每个光球压缩到一个更小的"瓶颈尺寸" 128 维,在 128 维空间里完成所有画功,最后一秒再展开回去落字。
为什么要压一道? 这就好像画家不会一上来就用 4K 屏幕画底稿,而是先在 A4 纸上勾轮廓——维度低,画起来更稳、更快,flow 也更容易学。论文里专门做过对比:bottleneck=128 比 256/512 都更好。这是 ELF 一个非常"何凯明"风格的小手术——把别人觉得"理所当然要在大维度跑"的事,硬生生压到小维度跑通了。
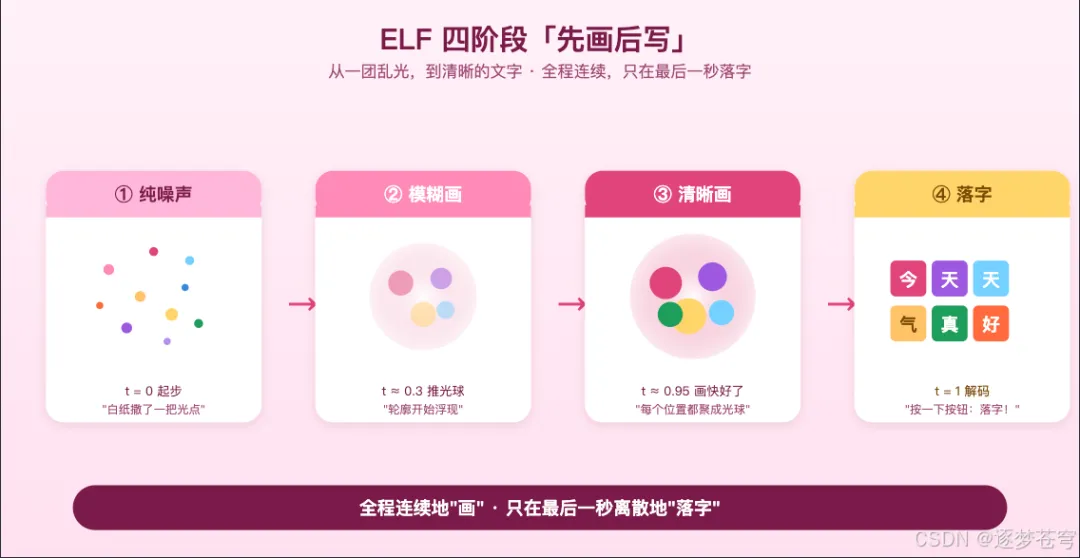
3.2 从噪声画到清晰画(flow 比喻)
有了光球的世界,怎么"画一段话"?
想象一下:
白纸上撒了一把乱糟糟的彩色光点(纯噪声)。AI 的任务是:每一步把这些光点轻轻"推一推",让它们慢慢聚成清晰的形状,最后形成一张"有清晰图案的画"——也就是一段有意义的文字的 embedding。
每一步推光球的过程,论文里叫 Flow(流)。这也是 ELF 名字里"Flow"的来历——Embedded Language Flows。
整个过程是纯连续的:
噪声 → 模糊画 → 半清晰画 → 清晰画每一步都不需要"必须落到某个具体的字"。AI 只管推光球,不用考虑落字的问题。这是它和"拼图派"最大的不同——拼图派每一步必须落字,而 ELF 全程都在画。
只在最后一步(论文里写作 t=1,咱们就叫"画完那一秒"),AI 才说:
"好,画完了。我现在看看每个位置最像哪个字,然后落字。"
一句话总结 ELF 最关键的设计:
整个过程都是连续的,只在最后一秒才离散化为具体的字。
这就是"先画后写"魔法的真正含义。
3.3 一个员工兼两班(shared-weight 比喻)
这里有个特别巧妙的小设计。
ELF 这个模型其实要干两件不一样的事:
1. 去噪(denoise):每一步把光球推得更清晰一点 2. 解码(decode):最后一步把"画"翻译成具体的字
按常规思路,这是两个完全不同的活,应该养两个独立的网络分别干。之前的几种类似方案(latent diffusion 系列)都是这么做的——画的归画的,翻译的归翻译的。
但 ELF 说:没必要养两个,一个人就能兼两班。
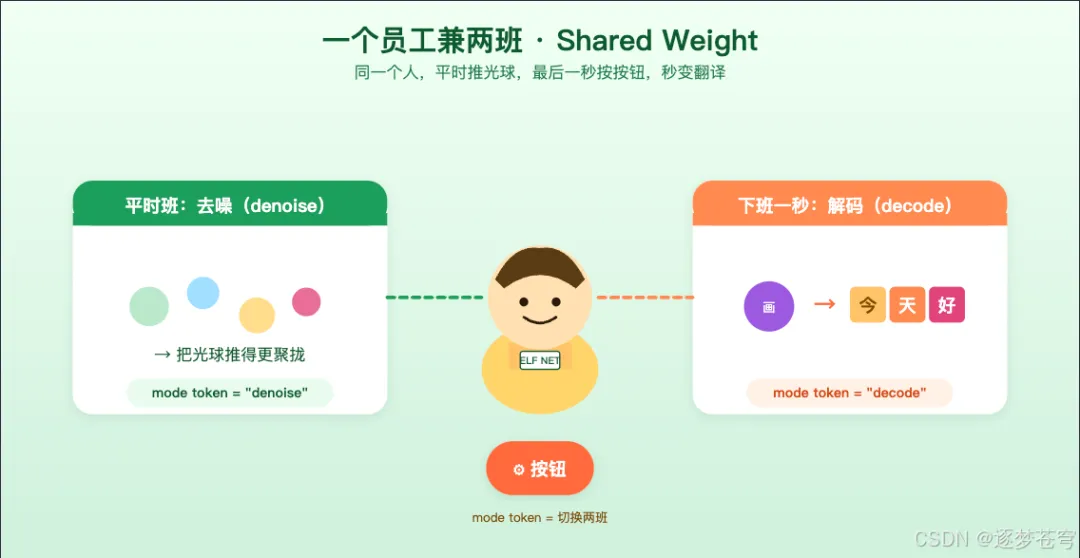
打个比方:
想象公司里有个万能员工。平时他干"推光球"的活;到了下班最后一秒,老板按一个按钮,他立刻切换成"翻译模式"——把今天累积的光球整理成最终的报告文字。
这个"按钮"在论文里叫 mode token——但有个非常巧的细节:
它不是 AI 网络外面的旋钮,而是被"写"在输入序列的最前面,像一句口令。
具体说——每次 AI 拿到一段输入,最前面会插一个特殊的 token:是 denoise 还是 decode,员工一眼看见就知道这一秒该干什么活。
这种做法叫 "in-context prepend(插在开头)",对比之前常见的"专门加一层条件控制层"(搞 AI 的人叫它 adaLN-Zero),有两个朴素的好处:
• 参数省了 30%:模型从 148M 砍到 105M(专门加层会每一层都多一组开销) • 更灵活:员工每读一层网络,都能"回头看一眼口令"再决定怎么处理,而不是只在入口看一次
还有一个被很多人误读的细节——
训练的时候,并不是"每个样本同时算 80% MSE + 20% CE 的混合 loss"。
实际做法是:一个 batch 里,80% 的样本被分去走"推光球"(denoise)的训练,20% 的样本被分去走"翻译"(decode)的训练。两群人不冲突,员工今天 80% 时间练主活、20% 时间练副活。
一个员工兼两班的好处有三个:
• 模型更小:不用养两个独立网络 • 任务互相促进:同一套"对语言的理解"既用来推光球,也用来翻译,两边的训练信号互相加成 • 训练省力:一套权重训完,两件事都会做
这是 ELF 整套架构里我个人最喜欢的一笔——简单、漂亮、有效。
3.4 像图像一样能"加提示词"(CFG 比喻)
到这里 ELF 已经够亮眼了,但它真正吊打离散派的"杀手锏"还在后头。
如果你玩过 Stable Diffusion,一定调过一个参数叫 CFG Scale。它的作用是:
让 AI 更"听话"地按提示词去画。CFG 调大,画面更紧贴提示词;调小,AI 更"自由发挥"。
打个比方:
CFG 就像 AI 戴的一副耳机的音量旋钮。提示词是你说的话,AI 平时听到三分意思就开始自由发挥;你把 CFG 旋大,相当于把音量调大,逼它老老实实按你说的画。
关键来了——CFG 是图像扩散里"大杀器"级别的工具,但是老派离散扩散语言模型用不了它!因为 CFG 需要在"连续空间里"对着模型的输出做平滑的加权操作,而离散派每一步都强行落字,根本没法平滑加权。
而 ELF 全程在连续空间里跑,CFG 直接搬过来就能用。不仅能用,论文里还玩出了花——
ELF 在训练的时候就把 CFG 的"听话效果"烤进了模型,论文叫 training-time CFG。推理时一次前向就拿到了带 CFG 的结果,速度还不打折。
这意味着:
AI 画图领域积累的 5 年所有 trick——CFG、各种 sampler、self-conditioning……ELF 整箱整箱地搬到写字上。
继承了别人 5 年的武器库,谁顶得住?
4、它凭什么吊打过去的扩散派
ELF 的"成绩单"挺刺激的。我们看 3 个数字,每个都翻译成人话。
4.1 训练数据只用 1/10
主流的扩散语言模型,训练数据一般要 500B token(5000 亿)起步。ELF 只用了 45B token——只有同行的 1/10 左右。
翻译成人话:
同样难度的考试,别人复习了 5000 道题才考及格;ELF 复习了 500 道题就考到了同样的分。
这不是节省点电费的小事——在大模型这个动不动训练成本上千万美金的时代,数据省 10 倍 = 训练成本省一个数量级,是核弹级的差距。
4.2 采样从 1024 步缩到 32 步
离散派的 MDLM 要走 1024 步才能生成一段质量过关的话。ELF 只要 32 步。
1024 ÷ 32 = 32 倍——理论上,同样硬件下,AI 生成文字的速度有机会快 30 倍。
这意味着同一个"AI 翻译"、"AI 写作助手"、"AI 长文创作"——你点完确定到看到第一段输出,等待时间从 30 秒变成 1 秒。这种延迟差距,是产品体验的鸿沟。
4.3 不需要蒸馏的"作弊"
补一个小知识:以前扩散模型要做"快速版",几乎都得靠一种叫 蒸馏(distillation) 的技巧——
大白话讲:先训一个慢但厉害的"老师模型",然后让一个快但傻一点的"学生模型"去学老师的输出。学生跑得快,但是它的本事是从老师那"偷"来的。
这是一种事后压缩,工程上多一道工序,性能也容易掉。
ELF 的不同之处是:
它天生就快,32 步是它原装的能力,不是被强行压缩出来的。论文里展示,它的少步生成质量,甚至能反过来打蒸馏过的 MDLM、Duo、FMLM。
天生丽质 vs 整容加速,差距就在这。
5、连续 DLM 这条路走了 5 年
聊到这你可能有个疑问:ELF 看起来不复杂,T5 embedding、Flow Matching、CFG 都是现成的工具。为什么之前 5 年都没人这么干?
这就是这篇论文最让圈内人感慨的地方——这条路其实有人走,但没人走通。让我用故事化的方式串一下时间线:
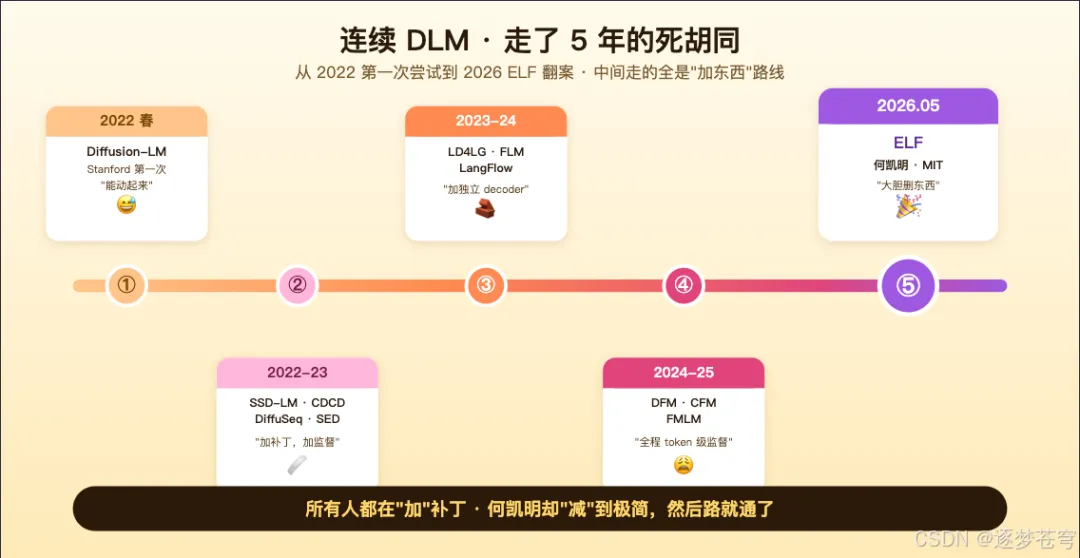
2022 年初,斯坦福,Diffusion-LM 第一次出手。Li 等人第一次试图把扩散用到文字上。他们在 embedding 空间里跑扩散,可惜效果差强人意,只能干一些填空、改写的小任务,离 GPT 那种通用生成差得远。但这是连续 DLM 的"创世记"——它告诉所有人,这条路至少能"动起来"。
2022 年下半年到 2023 年初,CMU、Google、Stanford 接着上。SSD-LM、CDCD、DiffuSeq、SED……一堆论文涌出来,思路都是"在 embedding 空间里跑扩散"。共同的痛点是——生成质量始终上不去,每一篇论文都得在不同地方加补丁、加约束、加 token 级监督,才能勉强 work。
2023 - 2024,Latent Diffusion 系入场。LD4LG、FLM、LangFlow 等等。这一派的思路是把图像里的"潜空间扩散"那套搬过来,但因为需要养一个独立 decoder、噪声调度也很复杂,整体仍然比离散派慢一截、贵一截。
2024 - 2025,DFM / CFM / FMLM 出现。这几篇已经很接近 ELF 了——它们也用 Flow Matching、也在连续空间里跑。但都有一个共同的尾巴:沿着整条 flow 轨迹都需要 token 级的 cross-entropy 监督。说人话就是——它们还是不敢真正放手让模型"连续地画完",每一步都要拽一下"你下一个字必须是哪个"。
2026 年 5 月,何凯明 + MIT 团队出手。他们做了一个有点反直觉的决定:
既然 t=1 才真正落字,那就只在 t=1 这一刻做 cross-entropy 监督,前面所有时刻都纯靠 MSE。
也就是说——前面所有时刻 AI 都不知道"自己将来要落哪个字",它只管推光球。这听起来太大胆了,跟之前几年所有人在做的"全程拽着模型"完全反着来。
更妙的是,他们把"推光球"和"最后一秒落字"用 同一个模型(shared weight)+ 一个 mode token 做了,整套架构极简。
这就是这件事的精彩之处:
过去 5 年大家都在加东西——加 token 级监督、加独立 decoder、加更复杂的 noise schedule。何凯明团队做的事情,是反过来——大胆删东西。
简洁本身就是力量。当一条路上越走越多人在加补丁、加附件,反而是有人把所有补丁一把撕掉,发现底下的简洁版本其实最稳。
这种"删而不是加"的研究品味,是何凯明过去 10 年所有代表作(ResNet、Mask R-CNN、MoCo、MAE)的共同基因。
再具体点拆给你看:如果你把 ELF 看成"15 件听起来都像新东西的事"——其中真正"作者团队自己想出来的"只有 4 件(最后一秒才落字、一个网络兼两班、选对了预测目标、训练时给字加不同噪声);剩下 11 件全是从图像扩散那边借来的零件(Flow Matching、CFG、self-conditioning、T5 embedding……)。
这就像一场 5 年的接力赛——前面 Stanford / CMU / Google 一棒一棒往前传,每个团队都加了一两个新零件。何凯明这一棒做的事,就是把所有零件第一次"正确组装"起来——不是发明了新零件,而是发现了"正确的装法"。
6、它在工程上的意义(人话版)
学术意义聊完,咱们换个视角——作为一个产品经理 / 工程师 / 普通用户,ELF 对你的现实生活有什么影响?
我列三件最可能发生的事。
第一件:翻译会变快。
论文里专门做了 WMT14 De-En(德英)翻译任务,ELF 在 32 步采样下打过了同等规模的离散 DLM。意味着未来如果工业界跟进,实时翻译、字幕生成、跨语言对话这些场景会先吃到红利——延迟低、能跑在边缘设备上。
第二件:写作助手的"等待感"会消失。
你点"帮我写一段开篇",现在 ChatGPT 还要等一两秒第一个字才蹦出来;如果 ELF 路线成熟,等待时间可能直接降到 0.1 秒级。这是用户体验的鸿沟——你想想刷短视频如果每个视频要等 3 秒加载,和现在的秒切换之间,差的是一整个时代。
第三件,也是最关键的:长文创作和可控生成可能洗牌。
现在让 ChatGPT 写一篇 5000 字的长文,逻辑跑偏、前后矛盾、写着写着主题就漂走——这些问题都来自"一个字一个字猜"的方式:它根本看不到全局。
ELF 这种"先画全局再落字"的方式,理论上能更好地把握长文的整体结构——因为它"画完一整张画"之后才落字,而不是边写边憋下一个字。配合 CFG 那种'提示词放大器',未来可能出现一种新形态的写作助手:你给一段提示词,它一次性出一整篇结构完整、风格统一的稿子——而且速度还快。
但说一句诚实话:
ELF 不是"全场碾压"。2026 年春天,跟它前后脚出现的还有 LangFlow、DFM、CFM、FMLM、FLM 几个"连续派反击作"。ELF 跟 LangFlow 几乎打平(一个 24 分一个 24.6 分),少数指标上还被走了"蒸馏捷径"的 FMLM 反超一小截。
ELF 真正的卖点不是"绝对最强",而是——用最轻的装备(无蒸馏、训练数据少 10 倍、模型只有 105M)跑出了 top 3 的成绩。它赢得最优雅,不是赢得最狠。
如果这件事真的能 scale 到 ChatGPT 那个量级,那 AI 写字这个领域接下来 3 年会被洗一遍。
不过——
"如果"两个字下面,藏着这次围绕 ELF 最大的争议。
7、它真的赢了吗?小白也要知道的争议
这一节是这篇博客最关键的一节。
吹的我们前面吹够了,咱们也得听一下骂的人在骂什么。AI 圈每篇爆款论文出来都有反对声音,ELF 也不例外——而且反对的声音里,有几个真的挺扎实的。
我从论文社区目前讨论最多的争议里,挑了 6 个最值得讲的,每一个都给你一个生活化比喻——其中 3 个还会展示"作者一方怎么说 / 质疑方怎么怼 / 我怎么判"的对照格式,方便你自己拿主意。最后再给你一条"番外争议"加餐。

7.1 "Gen PPL 用 GPT-2 算" = 拿小学生当裁判去评高中生作文
ELF 论文里有个关键指标叫 Gen PPL(Generation Perplexity,生成困惑度)——简单说就是用一个"裁判模型"去打分,看 AI 写的东西有多自然。
ELF 拿出来当裁判的是 GPT-2 Large。
但 GPT-2 是 2019 年的模型,还不到 2 个 B 参数。今天 ChatGPT、Claude 这种动辄上千亿参数的大模型已经横扫一切,让 GPT-2 当裁判——
这就好比让一个小学生去评高中生的作文。小学生看得懂"句子通顺",但不一定看得懂"逻辑严密"和"文采高级"。
所以"32 步 Gen PPL = 24"这个数字虽然看起来很漂亮,但裁判的水平就在那。换一个更强的裁判,ELF 还能不能这么强?没人知道。这是悬而未决的疑问。
7.2 "模型最大 652M" = 在小池塘里游得快,到大海里能不能游得快还不知道
ELF 论文里最大的模型 ELF-L 是 652M 参数——以今天的标准看,这是个非常小的模型。
ChatGPT 是 100B+,Claude 大概也在这个量级。ELF 还没有人在 7B、70B 上验证过。
这就好比一只鱼在小池塘里游得飞快,你说它是"鱼类之王"——但谁知道它到了大海里,是不是连普通的金枪鱼都追不上?
scaling law(大模型 scale 越大效果越好的规律)会不会在 ELF 这条路上变形?没人知道。论文里展示了 105M → 342M → 652M 的 scaling 曲线,前景看起来不错,但这只是 3 个点连出来的一条线——能不能外推到 70B,没人敢打包票。
这是 ELF 最大的不确定性。
7.3 "音量旋钮开到顶" = 更清楚,还是更死板?
这条争议有点技术,但用比喻一秒就懂。
CFG 调大,AI 更听话,生成的句子更"标准"、PPL 更低(更顺)。但同时,entropy(多样性指标)也跟着降低——意思就是它写出来的东西越来越像"模板答案",多样性变差了。
就像你听音乐,把音量旋钮转到顶——每个音符都听得清清楚楚,但整首歌的层次感、情绪起伏全没了,听上去像背景白噪音。
这场争议很典型,作者方和质疑方都有话讲——
• 作者一方说:"这是正常的 质量 - 多样性 trade-off。你要更顺的句子,就得放弃一点多样性,写作里所有人都要面对这个取舍。" • 质疑方说:"PPL 和 entropy 同步往下走,是 mode collapse(模式塌缩) 的经典特征——模型不是更聪明了,是更不敢出花样了。论文里没有报真正的多样性指标(比如 Self-BLEU),这种嫌疑就排除不掉。" • 我的判断:这是真正悬而未决的争议。等社区独立复现的时候补上 Self-BLEU 这种"花样多不多"的指标,才能给这事定案。
7.4 "代码 5/11 才开源" = 新菜谱刚发出来,还没人按这个菜谱炒过菜验证味道
论文挂在 arXiv 是 2026 年 5 月 11 日。代码仓库 lillian039/ELF 同期才开放——也就是说,截至这篇博客写出来的时候,社区独立复现的工作还没有真正出来。
这就好比一本新菜谱刚发表:"只要按这个步骤炒,每个人都能做出米其林三星的菜"——但还没人按这个菜谱炒过菜呢,到底味道如何,得等一段时间才知道。
AI 学术圈过去几年出现过好几次"论文数字漂亮但社区复现不出来"的事故。ELF 还在"等社区复现"阶段——这种时候得对漂亮数字保持一份"等等再说"的克制。
7.5 "对手发烧带病比赛" = ELF 真的反杀 AR 了吗?
ELF 在 WMT14 De-En 翻译上拿了 BLEU 26.4——这个数字"反杀"了同等规模的 AR(自回归)baseline 的 25.2。听上去爽不爽?爽。但仔细看,又是一场对照争议——
• 作者一方说:"Table 1 里数字白纸黑字,BLEU 26.4 > 25.2,我们就是赢了。" • 质疑方说:"你们的 AR baseline 用的是 greedy decoding(贪心解码) + 固定学习率(论文 Table 8),这是 DLM 圈传统的'弱 AR baseline'。一个正经调过的 99M 参数 Transformer NMT 能打到 BLEU 27+。你赢的是个没热身、还发着烧上场的对手。" • 我的判断:ELF 在"DLM 圈内的 SOTA"是没问题的,但"反杀 AR"这个 narrative 要打折听。它是同等懒训练设定下赢,不是真正的最强 AR。
比喻续一秒:你跟职业拳击手比赛赢了——但对手当时正发着烧、还没热身、戴着旧手套。赢确实是赢,但你不能因此宣称"职业拳击手不过如此"。
7.6 "对手用的是老枪" = 你赢的是不是只是"朴素 AR"?
最后一个争议,是 ELF 速度 narrative 里最容易被忽视的一刀。
ELF 说自己 32 步就写完了,AR(ChatGPT 那种)要一个字一个字蹦——所以快。听上去 ELF 完胜,是吧?但是——
过去 3 年,AR 圈早就发展出了一堆"加速 AR"的新技术:
• Speculative decoding(投机解码):让一个小模型先猜一堆字,大模型一次性确认 — 2-3 倍加速 • Medusa:让 AR 一次性预测好几个字 — 2-2.5 倍加速 • Lookahead decoding:边写边并行猜未来几个字 — 1.5-2 倍加速
这些方法叠加起来,ChatGPT 那种 AR 模型也可以跑得飞快——实际速度跟 ELF 的 32 步可能差不多,甚至更快。
而 ELF 论文里——完全没和这些"加速 AR"对比。它对比的是"朴素的、一个字一个字蹦的 AR"。
比喻:AI 写字这场速度赛,ELF 说"我跑得比对手快"。但对手用的是一把老枪(朴素 AR)。如果对手换上 2023 年之后的新枪(speculative decoding / Medusa / Lookahead),可能跟 ELF 打个平手,甚至反超。
我的判断:ELF 的速度优势在"朴素 AR"那把尺子上是真的,但论文完全没和加速 AR 对比——这是 ELF "比 AR 快"这个核心 narrative 里最没回答的一刀。如果你信"ELF = 下一代 AR 杀手",那这刀就直接戳到了痛处。
7.7 番外争议:"训练省 10 倍",还是只省了 6 倍?
最后一条加餐,是最近社区讨论度最高的一个争议。
ELF 论文里有一张非常吸睛的图——只用 45B token 训练就达到 SOTA,远低于同行的 524B,号称"训练效率高 10 倍"。这数字一出来圈里都炸了。
但是几天之后,一些细心的读者发现了一个细节——
• 作者一方说:"Token 数白纸黑字,10× 红利写在论文 Fig.7c。" • 质疑方说:"你们每个训练步要做 两次模型 forward(一次开 self-conditioning、一次关 self-conditioning),实际算力只省了 6 倍左右,不是 10 倍。" • 我的判断:还是省,但没那么爆炸。"省 6 倍训练 + 推理 32 步"已经够猛了,何必非要包装成"10 倍"?这种"标题党"式包装,是 ELF 论文最让人不太爽的一个点。
比喻:两个工厂,A 厂雇 10 个工人,B 厂只雇 1 个工人——但 B 厂那 1 个工人每天加班干双倍活。最后实际产出比是 1 : 6,不是 1 : 10。B 厂还是赢,但赢得没有海报上那么夸张。
一句话总结这一节:
ELF 是个非常漂亮的工作,但它不是"通杀级"的工作。它的数字漂亮,方向对,但是裁判可能有点小、池塘有点浅、菜还没人按菜谱炒过、对手发着烧、地图还是 2019 年的、海报上吹的 10 倍其实是 6 倍。
可以看好,但别神化。看好它的方向,警惕它的包装。
8、未来:ChatGPT 真的会变成"画"出来的吗
聊完吹和骂,咱们来个最终预测。
ChatGPT 短期会不会被 ELF 这种连续扩散方式替代?
我的判断:12 个月内不会,但5 年内的格局可能完全不一样。
理由分三层。
第一层(6 个月内):ELF 还得等社区独立复现。代码开源到稳定的开源实现 + 各种 ablation 真正被外部跑出来,至少要等到 2026 年底。所以短期内 GPT、Claude、Gemini 这一票还是 AR(哑谜大师派)的天下。
第二层(1 - 3 年内):会先在**"特定场景"看到 ELF 风格的产品**——
• 机器翻译:ELF 论文已经验证了在翻译上有竞争力,未来 1 - 2 年大概率会有商业产品采用类似架构; • 代码补全 / 代码生成的草稿模式:因为代码有强结构,连续扩散 + 全局规划可能反而比 AR 写得更整齐; • 结构化长文生成:法律文书、合同模板、技术报告这种"模板感强"的长文,ELF 风格"先画后写"可能比 ChatGPT 更稳。
第三层(3 - 5 年内):可能出现统一多模态生成模型。这是 ELF 最让人激动的地方。
AI 画图 / 视频 / 3D / 音频 现在都在用扩散 / Flow Matching;如果 AI 写字也用同样的范式,那么一个模型用同一套底层方法生成文字、图像、视频、3D就变得真正可能。
这不只是工程上的简化——这意味着多模态之间的"理解"和"生成"是浑然一体的,AI 可以"看着图片想下一段故事的视频画面",无缝衔接。
但话说回来——
这事会不会真的发生,取决于 ELF 这条路能不能 scale 到 GPT-4 级别。
而这个问题,目前没有人有答案。包括何凯明自己也没有给出。
9、写在最后
最后我想说三个朴素的观察。
第一个:科研里很多看起来"理论上不行"的事情,其实只是"还没人用对方法"。
"连续扩散写字不行"这个说法流传了 5 年,被 ELF 一篇论文翻案了。
这给所有做 AI 的人提了个醒——不要太轻易相信"理论上不行"这种结论。很多时候,所谓"理论上不行",只是因为之前的尝试者没有想到正确的设计。
第二个:AI 画图、AI 写字、AI 视频,正在加速融合。
ELF 是融合趋势里一个清晰的标志位。未来 3 - 5 年,"图像生成"和"语言生成"会越来越像同一件事,工具箱会打通,研究者会同时做两边。这件事对从业者最直接的影响——
如果你今天只懂语言模型不懂扩散模型,或者只懂扩散模型不懂语言模型,未来都会被夹击。
第三个:好的研究不一定是"加东西",更经常是"砍东西"。
ELF 最让我服气的不是它的数字,是它的克制——
• 没有加复杂的 noise schedule • 没有加独立 decoder • 没有加蒸馏 • 没有沿着整条 flow 做 token 级监督 • 没有花里胡哨的 trick
它就靠 1 个网络 + 1 个 unembed 矩阵 + 一个 mode token,把一件被认为是死胡同的事情做通了。
简单不是因为容易,是因为真的把问题想透了。
读完 ELF,你大概率会有一种感觉——
"啊,原来这件事可以这么简单。"
这种感觉,是何凯明过去 10 年所有代表作的共同烙印。ResNet 是这种感觉、MAE 是这种感觉、MoCo 是这种感觉、MeanFlow 是这种感觉——ELF 也是。
总结这篇博客:
ELF 是一篇值得记住名字的论文。它告诉我们——AI 写字下一站可能不是"更大的 ChatGPT",而是"先画后写"的画家派。
它的方向很对、数字很漂亮、设计很优雅;但它的裁判有点小、池塘有点浅、地图还是 2019 年的——这一切都意味着,这是一个起点,不是终点。
故事的下一章会怎么写?要看接下来 12 个月,社区能不能把这套方法在 7B、70B 上验证一次。
如果验证成功,AI 写字的下一站,就开门了。
