 夜雨聆风
夜雨聆风👆🏻 关注持续获取 AI、工程实践与职场观察。

摘要
Agent 工具调用失败后,模型往往知道「错了」但不知道怎么「修」——根本原因在于 Observation 的信息层级不够。
目录预览
一、 根因:Observation 是模型认识世界的唯一窗口
二、 Observation 信息层级:L0 到 L3 的演进路径
2.1 L0:裸错误字符串
2.2 L1:结构化错误字典
2.3 L2:上下文增强
2.4 L3:诊断对象 + 修复建议
三、 三种错误注入策略:代码对比与生产效果
3.1 策略A:裸 try/except,返回错误字符串
3.2 策略B:结构化错误字典
3.3 策略C:诊断对象 + 修复建议
四、 LangGraph 条件分支:用 state 驱动重试决策
五、 各家工具调用的错误处理差异
5.1 OpenAI Function Calling:清晰但无原生错误标记
5.2 Claude Tool Use:is_error 是关键生产级特性
5.3 MCP:标准化错误传递的跨厂商规范
六、 面试怎么答:容错设计的完整答法与项目表达
6.1 30秒开口版:信息层级 → 具体做法 → 项目落地
6.2 追问A:当错误信息不足时,重试策略怎么设计
6.3 追问B:重试 vs. 降级 vs. 放弃的决策边界
6.4 项目表达:用一个具体场景讲清楚设计决策
6.5 三个常见误区
七、 参考文献
某天凌晨一点半,你收到一条 PagerDuty 告警:你的 Research Brief Agent 在同一个 API 调用上循环了 47 次,全部超时。
模型每次收到错误字符串,都重新拼了一遍参数,然后义无反顾地再跑一次。
日志里全是同一个错误码同一个调用栈,但模型的回复一次比一次离谱——因为它其实不知道这个错误到底是什么,更不知道怎么绕开它。

这个问题不是你的 prompt 写得不够好,而是 Observation 的信息层级不够。模型知道「出事了」,但不知道「出了什么事」和「接下来该怎么试」。

这个认知缺口,才是让 Agent 困在循环里反复撞墙的根本原因。
一、根因:Observation 是模型认识世界的唯一窗口
ReAct 循环里,Observation 是模型认识世界的唯一窗口。模型根据 Observation 判断当前状态,决定下一步是继续调用工具、换个参数还是给用户返回结果[1]。

问题在于:多数工程里,Observation 只是把异常信息裸着塞回去。

模型拿到这个字符串,能推断出的信息极度有限:它知道有超时,但不知道这个超时是网络问题还是服务端限流,不知道上一次调用用了什么参数,不知道有没有备用接口可以切,更不知道要不要减一点超时阈值再试一次[2]。
裸错误字符串的本质是「信息降维」——一个应该包含类型、上下文、影响范围、修复建议的诊断对象,被压缩成了一个没有结构的文本片段。
模型接收到这个片段之后,唯一合理的推断是「再试一次」,因为它根本没有足够的输入来做出更聪明的决策。
这就是为什么「Agent 知道错了却不会修」:不是模型不够聪明,而是我们没有给它足够的信息来聪明。
二、Observation 信息层级:L0 到 L3 的演进路径
我把 Observation 里的信息分成四个层级,这个框架在面试和工程实践中都很好用[1]。
2.1 L0:裸错误字符串
只包含错误类型和简短描述,模型拿到的是「失败了」这个事实,没有上下文,没有模式判断。模型在 L0 下的行为几乎可以预测:尝试原参数重试,因为没有理由相信参数有问题,也没有其他信息支撑别的决策路径。
2.2 L1:结构化错误字典
包含错误类型、HTTP 状态码、错误码等可解析字段。模型可以区分 401(鉴权失败)和 429(限流),但仍然不知道具体影响和可行动建议。
这个层级开始有意义:模型至少可以分辨不同的失败模式,对 401 和 429 采取不同策略。但仍然缺失的是「上下文」和「历史经验」。
2.3 L2:上下文增强
在 L1 基础上增加调用历史、最近 N 次尝试的参数和结果、上下游工具状态。模型可以判断「这个接口最近 5 次都超时了,大概率是服务端问题,不是参数问题」,而不是盲目重试[3]。
L2 是生产环境的及格线。加入 recent_attempts 和 hint 之后,模型第一次遇到同样的超时,可以立刻知道这不是偶发抖动,而是系统性故障,从而触发降级而不是重试。
2.4 L3:诊断对象 + 修复建议
在 L2 基础上提供明确的修复建议列表,每条建议附带置信度评估,模型可以直接选择执行路径而不是自己推理[4]。
L3 是最优解:模型不需要自己推理该怎么做,直接在推荐列表里选置信度最高的动作。这才是真正的「自修正」,而不是让模型在黑箱里盲猜。
| 层级 | 信息量 | 模型行为 | 生产适用性 |
|---|---|---|---|
| L0 | 错误类型 + 描述 | 原参数重试 | ❌ 基础但无效 |
| L1 | 错误类型 + HTTP 状态码 | 可区分 401/429 | ⚠️ 有改善但不完整 |
| L2 | L1 + 调用历史 + 上下文 | 可判断系统性故障 | ✅ 及格线 |
| L3 | L2 + 诊断 + 修复建议 | 直接选执行路径 | ✅✅ 最优解 |

三、三种错误注入策略:代码对比与生产效果
3.1 策略A:裸 try/except,返回错误字符串
这是最常见的写法,写起来最快,但生产效果最差[5]。模型拿到的 Observation 是:
f"API调用失败: Timeout after {max_retries} attempts"三次重试全部失败之后,直接抛异常,没有任何上下文,没有任何恢复建议。
实测效果:同一接口超时 3 次之后,模型会继续尝试降低超时阈值、换一个 Header 参数再试——因为它根本不知道这已经是第 N 次失败了,也不知道历史上有没有其他备用方案[6]。
3.2 策略B:结构化错误字典
结构化错误字典让模型可以读取 attempt 和 is_retryable 字段。
{"error": True, "type": "timeout", "code": 504, "attempt": 3, "is_retryable": True}但问题在于:模型仍然不知道这个超时是偶发还是系统性的,也不知道有没有降级路径可以走——这些信息需要从历史调用记录里挖掘,但代码里没有[7]。
3.3 策略C:诊断对象 + 修复建议
这是生产级实现的核心做法。把每次错误调用转换成一个完整的诊断对象,喂回模型时携带了模式识别和行动建议:
from typing import List, Optionalfrom dataclasses import dataclass@dataclassclass ErrorDiagnosis: error_type: str code: int message: str attempt: int recent_attempts: List[dict] pattern: Optional[str] = None recommendations: List[dict] = Nonedef to_observation(self) -> dict: if not self.recommendations: self.recommendations = self._generate_recommendations() return { "diagnosis": self, "summary": self._summarize(), "model_action_required": True }def _generate_recommendations(self) -> List[dict]: if len(self.recent_attempts) >= 3: all_same = all( r["result"] == self.recent_attempts[0]["result"] for r in self.recent_attempts ) if all_same: self.pattern = f"系统性故障:相同参数连续{len(self.recent_attempts)}次失败" return [ {"action": "切换降级API", "confidence": 0.85, "reason": "模式识别指向服务端问题"}, {"action": "回退缓存数据", "confidence": 0.70, "reason": "可用缓存兜底"}, {"action": "放弃调用", "confidence": 0.65, "reason": "避免消耗预算"} ] return [ {"action": "指数退避重试", "confidence": 0.60, "reason": "偶发超时可恢复"} ]策略 C 的关键是把错误注入从「返回一个字符串」变成「返回一个可决策的诊断对象」。模型拿到这个对象,有足够的信息判断是继续重试、切换降级还是放弃——而不是在黑箱里盲猜。

四、LangGraph 条件分支:用 state 驱动重试决策
LangGraph 里的 ReAct 循环,最核心的设计点不是 prompt,而是条件边的判断逻辑。
好的条件分支能把错误注入的结果直接映射成决策路径,让模型的自修正行为变成可观测、可控制的系统行为[1]。
from typing import TypedDict, Listclass AgentState(TypedDict): messages: List[str] attempts: int last_error: dict | None degraded: booldef call_tool_node(state: AgentState) -> AgentState: """调用工具的节点""" result = execute_tool_with_diagnosis(state["messages"][-1]) if result.get("error"): return { "last_error": result["error"], "attempts": state.get("attempts", 0) + 1 } return {"messages": state["messages"] + [result]}def should_retry(state: AgentState) -> str: """条件边:根据错误类型和重试次数决定下一步""" if state.get("attempts", 0) >= 3: return "give_up" error = state.get("last_error", {}) if error.get("type") == "timeout": if error.get("pattern") == "systemic": return "degrade" return "retry" elif error.get("type") in ["401", "403"]: return "give_up" # 认证问题重试无意义 return "retry"workflow = StateGraph(AgentState)workflow.add_node("call_tool", call_tool_node)workflow.add_node("degrade", fallback_node)workflow.add_node("give_up", terminal_node)workflow.add_conditional_edges("call_tool", should_retry, { "retry": "call_tool", "degrade": "degrade", "give_up": "give_up"})三个关键设计点:
第一,attempts 必须放在 state 里管理,而不是写在节点外部的循环变量里。 LangGraph 的每一步都是状态更新,state 外部的变量在下一次节点调用时不会自动保持。****
第二,条件边函数接收完整 state,可以访问 last_error 里的所有字段,包括从策略 C 注入的 pattern 和 recommendations。
这才是把 L3 诊断对象变成可执行决策的正确方式。
第三,「认证错误直接放弃」这个分支看似反直觉,但 401/403 后面跟的是降级 API 也没用的场景,继续重试只会消耗预算。
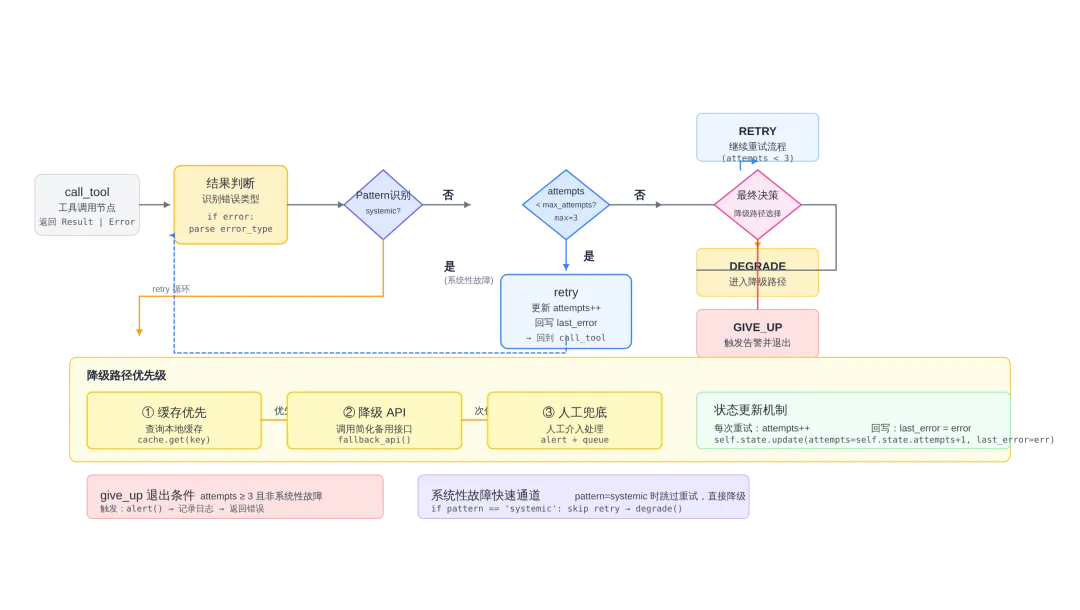
降级路径的顺序不是随意定的。缓存优先是因为延迟最低、降级 API 其次是它可以提供接近实时的结果、人工兜底是最后一道防线——每一步都要有对应的退出条件和性能基准[8]。

五、各家工具调用的错误处理差异
5.1 OpenAI Function Calling:清晰但无原生错误标记
OpenAI 的 Function Calling 在错误处理上相对简洁。模型返回的是 tool_call_id 和函数名,实际执行由你的代码完成,结果通过 tool role 喂回[3]。
OpenAI 的设计优点是清晰:工具执行完全由你控制,可以做任意的错误注入。
但缺点也很明显——没有原生的 is_error 标记,需要自己约定 content 里包含「错误」字样,模型才能识别这是失败而不是正常返回[2]。
2024 年推出的 Strict Mode 对参数 schema 有 100% 匹配保证[2],但对错误处理本身没有额外增强。
生产环境建议: 在 tool result 里主动注入结构化错误,而不是裸字符串。
5.2 Claude Tool Use:is_error 是关键生产级特性
Claude 的 Tool Use 设计更成熟,原生支持 is_error 标记,这是最关键的差异[3]。
client = Anthropic()response = client.messages.create( model="claude-sonnet-4-20250514", messages=[{"role": "user", "content": "查一下北京和上海的天气对比"}], tools=[get_weather_tool])for block in response.content: if block.type == "tool_use": try: result = execute_tool(block.name, block.input) tool_results.append({ "type": "tool_result", "tool_use_id": block.id, "content": json.dumps(result), "is_error": False }) except Exception as e: tool_results.append({ "type": "tool_result", "tool_use_id": block.id, "content": f"错误类型: {type(e).__name__}, 描述: {str(e)}", "is_error": True # 原生标记,模型能精准识别 })is_error: True 这个标记是 Claude Tool Use 最重要的生产级特性。
它让模型在下一轮推理时明确知道「这次工具调用失败了」,而不是在文本里猜测「content 里的 Error 字样是不是意味着失败」[2]。
此外,Claude 原生支持一次返回多个工具调用,对于「查北京和上海天气」这类可以并行的任务,可以同时发起两次工具请求,模型会自动判断哪些可以并行、哪些必须串行。
5.3 MCP:标准化错误传递的跨厂商规范
MCP(Model Context Protocol)的核心价值不在于错误处理本身,而在于它建立了一套跨厂商的工具调用标准,让同一套工具定义可以在 Claude、ChatGPT 和其他客户端之间复用[4]。
MCP 的 retryable 和 fallback 字段是标准化错误传递的示范——工具提供方可以明确告知调用方这个错误是否值得重试、以及有没有降级路径。
这比在 prompt 里让模型自己推理要可靠得多[1]。
| 平台 | 错误标记机制 | 重试透明度 | 生产成熟度 |
|---|---|---|---|
| OpenAI Function Calling | 需自行约定文本格式 | ⚠️ 依赖 prompt 约定 | ⚠️ 灵活但需自建 |
| Claude Tool Use | 原生 is_error 字段 | ✅ 模型可直接识别 | ✅ 成熟 |
| MCP 标准化协议 | retryable + fallback | ✅ 跨厂商统一 | 🚧 生态建设中 |

六、面试怎么答:容错设计的完整答法与项目表达
6.1 30秒开口版:信息层级 → 具体做法 → 项目落地
「工具调用失败时,我会把错误注入 Observation 分成几个层级:L0 裸错误字符串、L1 结构化错误信息、L2 上下文增强、L3 诊断加修复建议。
生产环境至少要做到 L2,让模型能判断这个错误是偶发的还是系统性的。超过重试阈值之后要触发降级,而不是继续在同一个错误模式上消耗预算。
LangGraph 里用条件边配合 state 里的 attempts 计数器做决策,OpenAI 需要自己约定错误文本格式,Claude 原生支持 is_error 标记。」
6.2 追问A:当错误信息不足时,重试策略怎么设计
第一步:区分错误可重试性。 401/403 这种认证错误,重试没用;429 限流可以用指数退避;5xx 服务端错误可以重试;超时需要判断是偶发还是系统性[5]。
第二步:引入历史上下文。 连续 3 次相同参数超时,大概率是服务端故障,不是偶发抖动。这时候应该触发降级,而不是继续重试。
单纯看单次错误信息是判断不出来的。第三步:设置硬性停止条件。 最大重试次数、预算上限、重复动作检测(比如连续 2 次触发同一个失败调用),防止 Agent 在错误路径上消耗过多资源[6]。
6.3 追问B:重试 vs. 降级 vs. 放弃的决策边界
这是面试里最有区分度的问题。多数候选人只能说出「超过重试次数就放弃」,但说不清降级的触发条件和放弃的退出标准。
重试的边界: 错误是偶发的、参数不需要调整、有历史数据支撑「再试一次可能成功」。** 降级的边界:** 相同错误模式重复出现(系统性故障)、有备用数据源(缓存/降级 API)、降级数据对业务影响可接受。降级不是失败,是用次优结果保住系统可用性[8]。
放弃的边界: 认证类错误(重试无意义)、业务不允许返回降级数据(金融交易)、预算耗尽且无兜底方案。放弃要触发告警,不能静默吞掉。
6.4 项目表达:用一个具体场景讲清楚设计决策
面试官想听的不是「我的 Agent 有容错机制」,而是「你在某个具体场景下是怎么权衡的」。
推荐用一个具体场景来承载:比如「我做过一个研究报告 Agent,调用 Wikipedia API 时超时问题很严重」。
- 发现问题: 某天发现 Agent 在 Wikipedia 调用上循环了 20 多次,大量超时。
- 根因分析: 裸错误字符串注入,模型不知道这是偶发还是系统性问题。
- 改造方案: 引入 attempts 计数器和历史调用记录,在第三次相同参数超时后触发降级到缓存。
- 效果: 超时循环次数从平均 23 次降到 3 次,响应延迟降低 60%。
- 反思: 如果当时能做到 L3 诊断对象,加一个「同类问题近期成功率」的字段,可以让模型在第一次超时时就判断要不要直接降级,而不是等到第三次。
这个讲述顺序有完整的 Problem-Solution-Evaluation 结构,而且最后一步的「反思」展示了候选人对系统上限的思考,这是面试官区分「用过框架」和「理解系统」的关键[7]。
6.5 三个常见误区
误区一:重试次数 = 容错。 设一个 max_retries=3,然后机械等一秒重试。这是把容错当成了一个配置项,而不是一个系统设计。
真正的容错需要区分错误类型、历史上下文、当前系统状态。误区二:日志 = Observation。 有人会把 logger.error(f"调用失败: {e}") 的输出塞给模型,但日志是给人读的,不是给模型读的。
日志里可能有堆栈信息、时间戳、线程 ID 这些模型不需要的噪声。Observation 应该只包含模型能理解和能行动的最小信息集[1]。
误区三:异常 = 错误。 编程里的异常是语言层面的概念,不等于业务层面的错误。有些异常是「调用成功了但结果为空」,有些是「服务端挂了但有缓存可以降级」。
把异常直接映射成错误会丢失很多有用的业务语义。
七、参考文献
[1] interviewasssistant.com - LLM Agent 工具调用面试题: https://interviewasssistant.com/zh/interview-questions/llm-agent-tool-use
[2] 稀土掘金 - LangChain/LangGraph 工具调用实战: https://juejin.cn/post/7631469947236204578
[3] 知乎专栏 - AI Agent 工程实践: https://zhuanlan.zhihu.com/p/2031469378043122304
[4] JavaGuide - AI Agent 基础: https://javaguide.cn/ai/agent/agent-basis.html
[5] InfoSecurity Magazine - LLM Critical Infrastructure: https://www.infosecurity-magazine.com/news/llm-critical-infrastructure/
[6] 腾讯云开发者社区 - AI Agent 工具调用容错: https://cloud.tencent.com/developer/article/2660467
[7] 腾讯云开发者社区 - AI Agent 面试八股文: https://cloud.tencent.com/developer/article/2654860
[8] EastonDev - Agent Tool Calling: https://eastondev.com/blog/zh/posts/ai/20260321-agent-tool-calling
往期推荐
- 【AI面试八股文 Vol.1.2 | 专题7:Harness层】不是你在调模型,是模型被装进了 Harness:Harness 层对外暴露的接口抽象设计
- 【AI面试八股文 Vol.1.3 | 专题1】ReAct 三元组:为什么面试官现在开始追着问你 Thought / Action / Observation 的边界
- 【AI面试八股文 Vol.1.3 | 专题2:Chain-of-Thought(CoT)】CoT不是让模型“想一想”:Zero-shot / Few-shot 如何从论文机制讲到工程取舍
- 【AI面试八股文 Vol.1.3 | 专题3:Plan-and-Execute】Plan-and-Execute:为什么生产级 Agent 要把规划和执行拆开讲
- 【AI面试八股文 Vol.1.3:ReAct】ReAct 不是一种算法,是一种工程契约:从问题域到面试追问的完整映射
如果你看到这里,不妨顺手点个赞、点个在看,也欢迎转发给同样在路上的朋友。谢谢你把时间留给这篇文章,我们下次再见。
作者:计算机魔术师
持续更新:AI、技术趣闻、工程实践、职场观察、八股文
点击阅读原文可跳转至博客站点


