 夜雨聆风
夜雨聆风引言
Mem0 与 Mem9 都是针对 AI Agent 核心痛点 —— 记忆系统打造的开源记忆层,二者却采用截然不同的技术思路。本文将通过以下例子,对两种不同的记忆系统设计理念和技术实现,展开学习:
历史记忆:"User lives in Beijing"新消息:"我搬到上海了"
一、Mem0:写入极简,检索融合,异步清理
1.1 设计理念
Mem0核心思路是:
写入时 LLM 只做一件事——提取事实。绝不修改已有记忆。清理和去重推迟到检索时和离线批处理。
v2 时代 Mem0 也是 LLM 实时判断 ADD/UPDATE/DELETE,v3 彻底放弃了这个路线。原因很简单:让 LLM 在写入时判断一条事实该增、改还是删,是个容易出错的分类问题。一旦判断错(比如误把 "Moved to Shanghai" UPDATE 成 "Lives in Shanghai",原始时间信息就丢了),错误不可逆。
v3 的核心变化:ADD-only + 多信号检索 + 异步 Dream 清理。
1.2 写入流程
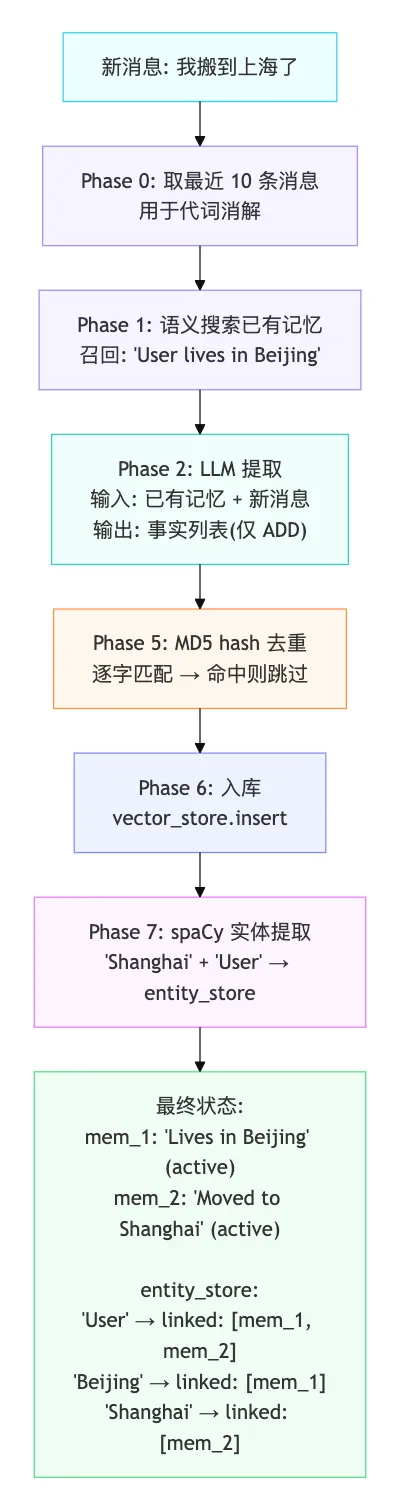
关键代码 —— LLM 提取只做 ADD:
# Mem0/memory/main.py:725system_prompt = ADDITIVE_EXTRACTION_PROMPT# prompt 核心约束:# "Your sole operation is ADD: identify every piece of memorable# information and produce self-contained factual statements."# "Do NOT re-extract information already captured."response = self.llm.generate_response(messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": user_prompt}, # 包含已有记忆 + 新消息])# 解析结果 → 只有 ADD 事件extracted_memories = json.loads(response).get("memory", [])# [{"id": "0", "text": "User moved to Shanghai as of 2025-05-23"}]关键代码 —— 实体链接作为跨记忆桥梁:
# Mem0/memory/main.py:866 (Phase 7)# 从记忆文本提取实体entities = extract_entities_batch(["User moved to Shanghai as of 2025-05-23"])# → [("PROPER", "Shanghai"), ("NOUN", "User")]# 每个实体独立存入 entity_store# "User" 实体已存在 → 追加 mem_2 到 linked_memory_idsentity_store.update( vector_id="ent_user", payload={"linked_memory_ids": ["mem_1", "mem_2"]} # 桥梁)1.3 检索流程
关键代码 —— 多信号融合:
# Mem0/utils/scoring.py:60-121defscore_and_rank(semantic_results, bm25_scores, entity_boosts, threshold, top_k): has_bm25 = bool(bm25_scores) has_entity = bool(entity_boosts) max_possible = 1.0if has_bm25: max_possible += 1.0if has_entity: max_possible += 0.5# ENTITY_BOOST_WEIGHTfor result in semantic_results: semantic_score = result["score"] # 如 mem_2: 0.72, mem_1: 0.65 bm25_score = bm25_scores.get(mem_id, 0) # mem_2: 0.62, mem_1: 0.67 entity_boost = entity_boosts.get(mem_id, 0) # 两条都 0.49 combined = (semantic_score + bm25_score + entity_boost) / max_possible# mem_2: (0.72 + 0.62 + 0.49) / 2.5 = 0.732 ✓# mem_1: (0.65 + 0.67 + 0.49) / 2.5 = 0.724北京被召回的原因: entity_boost 对两条记忆相同(共享 "User" 实体),BM25 上 mem_1 甚至略高("lives" 更匹配 "where...live")。差距仅来自语义搜索的 0.07 分。agent 同时看到两条,自己判断上海是最新的。
1.4 异步清理:Dream Consolidation
写入时不做 UPDATE/DELETE,记忆会逐渐膨胀。Mem0 用一个独立的 LLM agent(Dream)定期清理:
• 触发条件:距上次 ≥ 24h、积累 ≥ 5 个会话、记忆 ≥ 20 条 • 处理逻辑:拉全量记忆 → 识别重复 → MERGE/REWRITE → DELETE 过期/噪声/凭据 • TTL 规则:操作记忆 7 天、项目记忆 90 天
这相当于把 v2 的实时 CRUD 判断变成了"定期审计员"——看到全量记忆再决策,质量更高。
二、Mem9:写入对账,检索 RRF,实时 CRUD
2.1 设计理念
Mem9核心思路是:
每次写入都对账——LLM 提取事实后,和已有记忆逐一比对,实时决定 ADD/UPDATE/DELETE。记忆库始终处于"最新状态"。
Agent 插件是薄客户端,只负责发 HTTP 请求。embedding、向量搜索、LLM 调用全部在服务端完成。
2.2 写入流程
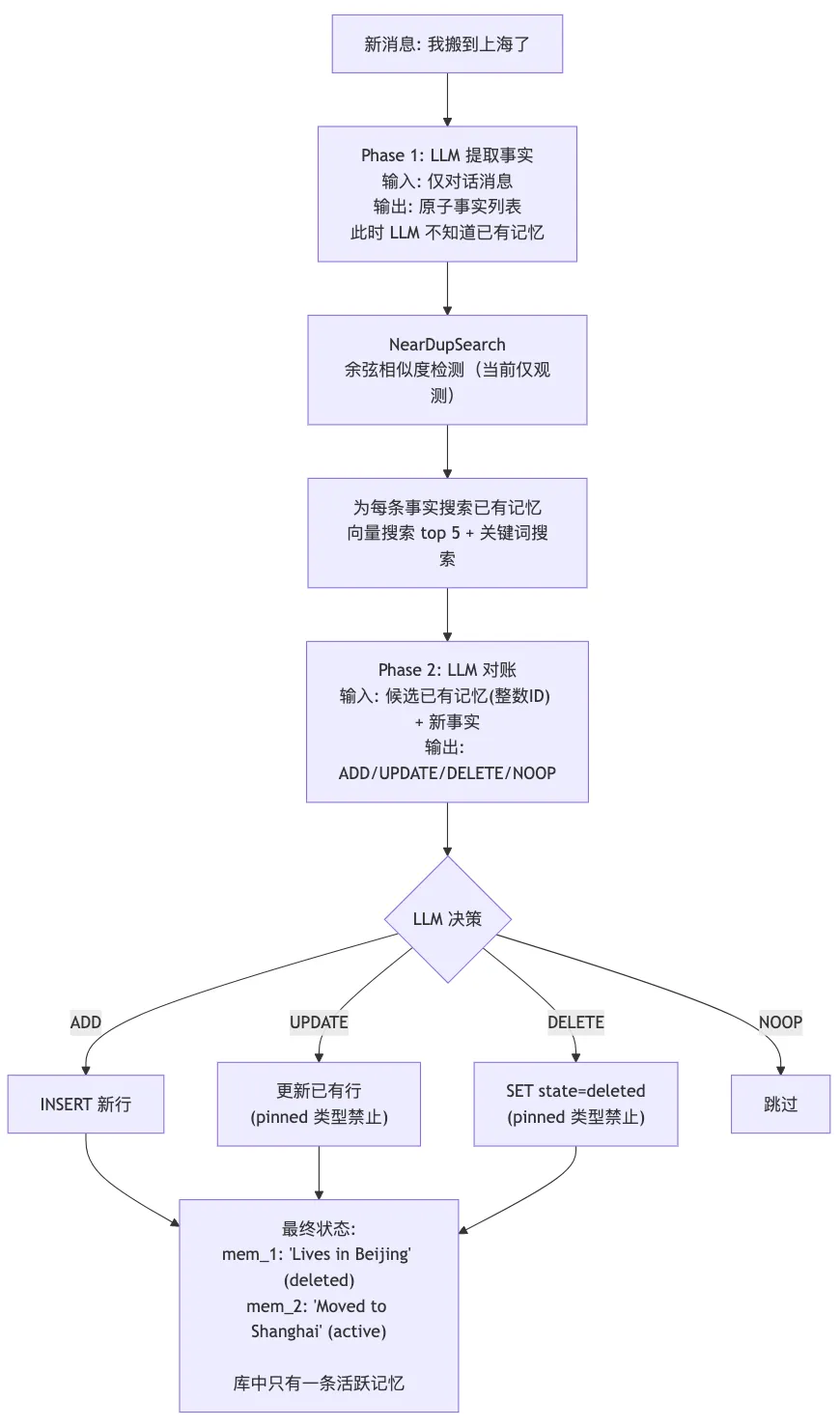
关键代码 —— Phase 2 对账 prompt:
// Mem9/server/internal/service/ingest.go:991-1064systemPrompt := `You are a memory management engine.## Actions- ADD: New info not in any existing memory.- UPDATE: Replaces the same attribute/slot of the same entity only.- DELETE: Explicitly contradicts an existing memory.- NOOP: Already captured by an existing memory.## Rules1. Reference existing memories by integer ID ONLY.2. UPDATE only when the fact targets the same entity AND attribute slot. A new attribute → ADD, not UPDATE.3. When a new fact conflicts with an existing memory on the same topic, older memories are more likely outdated.`关键代码 —— 反幻觉 ID 映射:
// Mem9/server/internal/service/ingest.go:969-984// 传给 LLM 的是整数 ID,防止 LLM 编造 UUIDtype memoryRef struct { IntID int`json:"id"` Text string`json:"text"` Age string`json:"age,omitempty"`}refs := []memoryRef{{IntID: 0, Text: "User lives in Beijing", Age: "11 months ago"}}idMap := map[int]string{0: "real-uuid-mem_1"} // 执行时映射回真实 ID执行动作 —— UPDATE/DELETE 都受保护:
// Mem9/server/internal/service/ingest.go:1131-1221case"DELETE":if memories[intID].MemoryType == "pinned" {// pinned 记忆禁止自动删除,跳过continue } memories.SetState(realID, StateDeleted) // 逻辑删除case"UPDATE":if memories[intID].MemoryType == "pinned" {// pinned 记忆降级为 ADD addInsight(...)continue } updateInsight(realID, newText, ...)2.3 检索流程
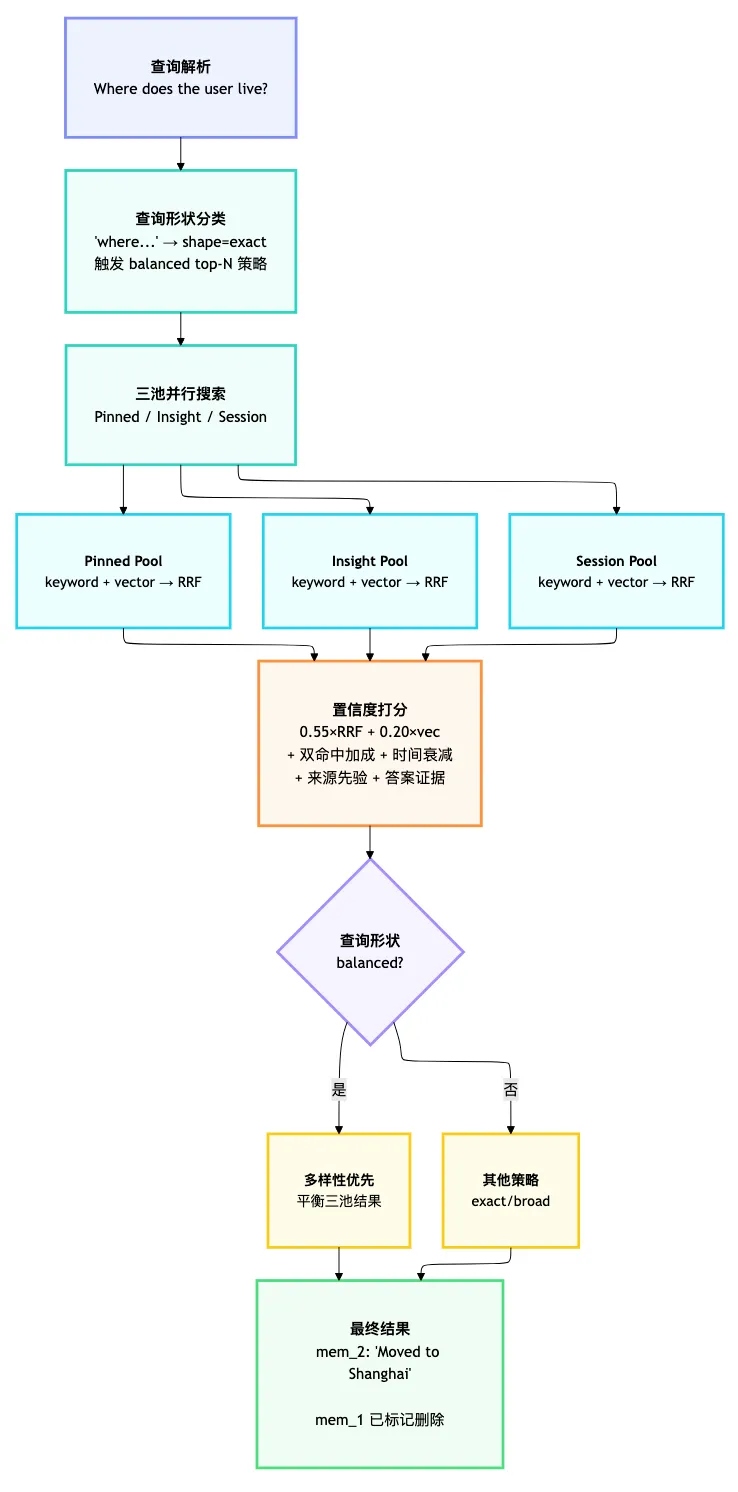
关键区别: mem_1(北京)在 SQL 查询层就被 WHERE state = 'active' 过滤掉了,根本不会进入候选池。agent 只看到唯一的答案。
三、共同点
1. 定位一致。 都是 AI Agent 的持久化记忆层,解决"跨会话遗忘"问题。
2. LLM 做事实提取。 写入时都不存原始对话,而是 LLM 提取原子化、自包含的事实后再存储。都要求消除代词、保留原语言、丢弃问候/噪声。
3. 混合检索。 都认识到纯语义搜索不够用,同时走「向量 + 关键词」两路再融合。Mem0 用加权求和,Mem9 用 RRF。
4. query_intent 过滤。 都识别并丢弃用户的"搜索/查询类问题"("帮我查一下 nginx 配置"),只保留关于自身的陈述("我们生产用 nginx 1.24")。
5. 多 Agent 平台集成。 都覆盖了 Claude Code、OpenClaw、Codex 等主流 agent 运行时。
四、核心不同点:记忆管理的两种哲学
以下只聚焦记忆管理的设计差异,不讨论部署方式、存储引擎、可插拔性等工程层面的区别。
4.1 写入哲学:ADD-only vs 实时 CRUD
这是最根本的分歧。
| 写入动作 | ||
| LLM 调用次数 | ||
| 旧记忆处理 | ||
| 信息保真 | ||
| 记忆库状态 |
北京→上海的例子最直观:
• Mem0:两条都在,"上海"排第一、"北京"排第二,agent 自己判断 • Mem9:写入时"北京"被 DELETE,库里只有"上海"
Mem0 的思路是「写入时宁可多存,检索时再精确筛选」。Mem9 的思路是「每次写入对账,库里始终是最新状态」。
4.2 检索:多信号融合 vs RRF + 查询分类
| 融合方式 | (semantic + bm25 + entity) / max | |
| 信号种类 | ||
| 查询意图理解 | ||
| 置信度模型 |
Mem0 的检索相对轻量,依赖于实体链接作为差异化信号。Mem9 的检索极其复杂(recall.go 1800+ 行),对查询做 NLP 分类后选择不同策略。
4.3 跨记忆关联:实体桥梁 vs LLM 对账覆盖
| 关联机制 | ||
| 关联持久化 | linked_memory_ids | |
| 检索增强 |
Mem0 用实体做间接关联:「User」实体链接了北京和上海两条记忆 → 查询提到 User 时两条都被 boost。Mem9 直接让 LLM 判断北京已过时 → DELETE → 检索时不存在。
4.4 清理机制:异步批处理 vs 写入时实时
| 方式 | ||
| 触发 | ||
| 范围 | ||
| TTL |
Mem0 的 Dream 能看到全量,合并决策更准,但清理不及时。Mem9 每次写入即时清理,但受限于对账时的候选范围(最多 60 条),可能看不到跨时间窗口的全局重复。
4.5 记忆保护机制
Mem9 有 pinned 类型——用户手动创建的规则/配置被标记为 pinned 后,LLM 对账时不能自动 UPDATE/DELETE(代码层硬拦截,pinned UPDATE 降级为 ADD,pinned DELETE 直接跳过)。Mem0 没有这个概念,所有记忆平等对待。
五、小结
Mem0: 写入极简(只ADD) ─→ 检索融合(语义+BM25+实体) ─→ 异步清理(Dream)Mem9: 写入对账(ADD/UPDATE/DELETE) ─→ 检索RRF(查询分类+置信度) ─→ 实时清理本质区别:Mem0 = 把复杂度推迟到检索时,写入只管捕获,历史全保留Mem9 = 把复杂度前置到写入时,每次对账清理,库始终最新如果你的场景需要完整的历史追溯、agent 有能力自己从多条候选中推理出当前状态,Mem0 的 ADD-only 更适合。如果你希望记忆库始终是精确的最新快照、不希望 agent 看到过时信息,Mem9 的实时 CRUD 更合适。
Mem9 的记忆管理操作,恰恰是 Mem0 v2 放弃的路线(写入时 LLM 判断 CRUD),并在工程化上做了强化(反幻觉 ID 映射、pinned 保护、查询形状分类)。
参考文档:Mem0: https://Mem0.aiMem9:https://Mem9.ai
