 夜雨聆风
夜雨聆风从“记忆”到“自我整理”:Claude 这条线程真正讲透了什么
最近看到两条博文,表面上是在讲 Claude 的 memory 和 Dreaming,实际上讲的是一件更大的事:AI agent 终于开始从“每次都失忆”的状态,往“能积累经验”的状态走了。
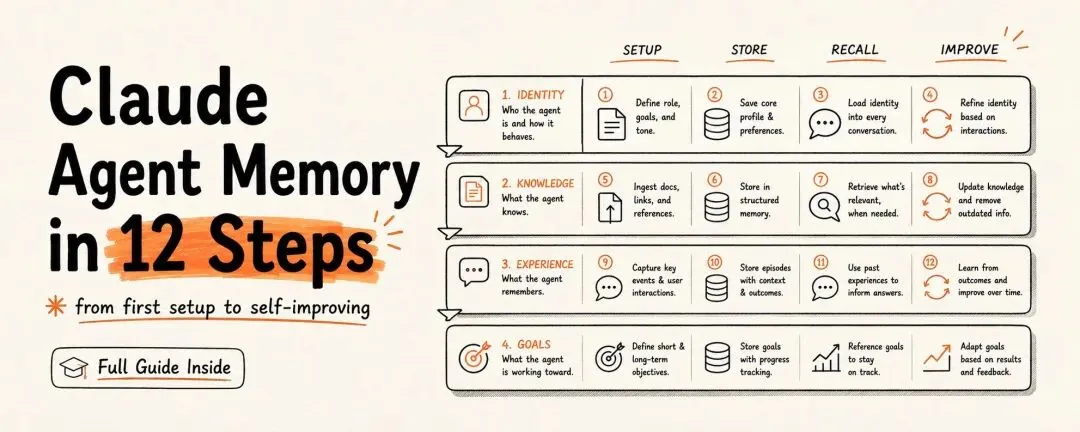
Movez 那条转推很直白,核心就是四件事:「跨会话记忆、memory store、Dreaming、自我优化和低成本缓存」。Codez 的长文则把这件事拆成了 12 步,落到具体设置、项目空间、记忆文件、自动记忆、以及最后的 Dreaming 复盘。
我更愿意把它看成一套分层系统,而不是某个单点功能。真正有价值的不是“Claude 记住了什么”,而是它开始学会区分:哪些信息该长期保存,哪些只是一次性的噪音。
一、先说结论:这不是记忆功能,这是 agent 的操作系统
过去大多数 agent 的问题都很像“金鱼”。每开一个新会话,前一轮刚修好的习惯就没了;刚学会的 workaround,也会在下一次重复犯错。
Codez 的线程把这个问题说得很透:如果没有 memory,agent 第 100 次跑和第 1 次跑,几乎没有本质区别。它不是越来越聪明,而是每次都重新开始。
这也是为什么这条线索里最重要的,不是某个按钮,而是四层东西叠在一起:
Claude 自带的跨会话记忆 Project 级别的工作区 轻量但持续更新的 memory file Dreaming 这种后台整理机制
这四层合在一起,才像一个能持续进化的系统。
二、原文里的 12 步,真正能提炼成 4 个层级
原文写了 12 步,但如果只从产品和工作流的角度看,其实可以压缩成 4 个层级。
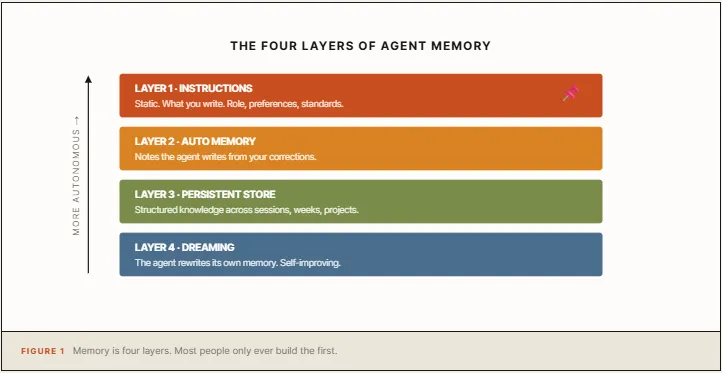
1. 内置记忆,解决“默认失忆”
这一步最基础,也最容易被忽略。Anthropic 这次把 Chat Memory 推给了普通用户,意思很清楚:记忆不再是高阶玩法,而是默认能力。
但这里有个现实问题。自动合成记忆是延迟发生的,不是你刚纠正完,系统立刻就懂了。所以 Codez 才强调:不要等模型自己猜,直接把偏好写进去。
原文给的模板很实用:
Remember the following about me for future conversations:- I work in [field] and my main projects are [X, Y]- I prefer [direct prose / no bullet points / short replies]- My writing style is [describe it]- Never [the thing you always have to correct]这段其实说明了一件事:记忆不是被动采集,而是主动灌注。
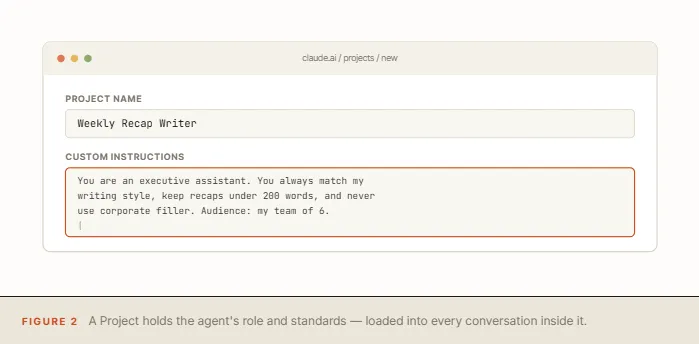
2. Project,不是记忆,而是工作区边界
很多人会把 Project 当成“长期记忆”。这条线程直接纠正了这个误区。Project 记住的是指令和上下文边界,不是你每一次聊天的过程。
这件事很重要,因为它决定了一个产品到底是在帮你“管理状态”,还是只是帮你“保存规则”。
如果说内置记忆是把模型从金鱼升级成有短期习惯的助手,那 Project 更像给它安排了一个固定工位。它知道自己该扮演什么角色,但并不会自动保留每次对话的全部过程。
3. Memory file,才是最朴素但最稳定的长期记忆
原文里最务实的一段,其实不是 Dreaming,而是 memory file。
它的本质很简单:读、写、再读。
这和很多“聪明功能”相比,显得非常土,但也非常有效。因为只要文件结构够清楚,agent 每次启动都能快速找回自己应该遵守的偏好、决策和 workaround。
Codez 还特意强调了一个细节:memory file 不能无限膨胀。要分区,要简洁,要只保留会改变未来行为的信息。
我非常认同这一点。记忆不是知识库,记忆是决策压缩器。

4. Dreaming,才是“自我整理”那一层
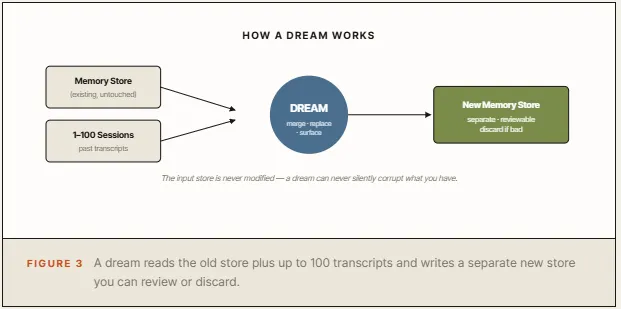
真正让我觉得这条线程有分量的,是 Dreaming。
它不只是“再加一层记忆”,而是后台把很多 session 的经验重新整理一遍:重复项合并、旧项更新、新模式浮现。这个动作像什么?像人睡觉后第二天把碎片经验重新归档。
这也是为什么它叫 Dreaming。名字不是噱头,逻辑是成立的。
但它也有边界:不是所有 agent 都适合 Dreaming。它只对重复跑同类任务的 workhorse 有意义。你如果只是做一次性任务,整理出来的东西不会有多少复利。
三、这套东西真正改变的,不是“记住更多”,而是“记住得更像人”
很多人看到 memory,就会立刻想到“长期保存更多上下文”。我觉得这还是太浅。
更关键的是,它开始接近人类工作方式里的两件事:
会忘记无关细节 会保留会影响下次决策的东西
这就是 agent 和普通聊天机器人之间最大的分水岭。聊天机器人可以每次都从零开始,因为它只负责对话;agent 不行,agent 要干活,要复用经验,要减少重复犯错。
换句话说,记忆不是为了让模型显得更聪明,而是为了让它少做蠢事。
这条线程里最值得抄的,不是某个 API 参数,而是这个判断:
❝记忆的目标不是存最多,而是让未来的行为更少返工。
❞
四、原文最强的地方:它没有停留在概念,而是把边界也说清了
很多关于 AI memory 的内容,常常会写成一篇鸡汤:只要有了记忆,agent 就会自动进化。
Codez 这篇不一样。它把几个容易误解的边界讲得很清楚:
Projects 不是 conversation history memory file 不能做成 wiki dump auto-memory 不是万能的,需要人工筛选 Dreaming 需要在可复用的工作流上才有价值 output store 不能盲目直接上线,必须先 review
这些边界很重要。因为真正能落地的系统,永远不是“更强”,而是“更可控”。
这也是我觉得这条博文比大多数“AI 未来已来”式内容更靠谱的原因。它不是喊口号,而是在告诉你怎么别把系统做坏。
五、如果把这套方法迁移到别的 agent,核心也只有一条
无论是 Claude Code、Cursor、还是你自己搭的 agent,方法都差不多:
把稳定偏好写进可读取的 memory file 把临时任务放进 Project / workspace 把长期行为模式交给后台整理 把“要不要记住”这件事变成一个有标准的筛选过程
这比“多喂上下文”靠谱得多。因为上下文堆得越多,噪音越大;记忆机制越好,系统越轻。
我甚至觉得,未来 agent 竞争的重点不会只是模型本身,而是谁能更好地管理记忆。谁能把该忘的忘掉,把该留下的留下,谁就更接近真正的生产力工具。
写在最后
这两条 X 帖子本质上讲的是同一件事:AI agent 已经不该再以“每次开局清零”为默认状态了。
Movez 提供的是传播层面的判断,Codez 提供的是工程层面的拆解。前者告诉你这件事值得关注,后者告诉你它到底怎么做。
如果只看热闹,你会把它当成一个新功能。 如果看结构,你会发现这其实是 agent 走向成熟的分水岭。
最有价值的不是“记住一切”,而是“记住会改变未来的那部分”。这才是记忆真正开始有用的地方。
「更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。」
原始素材来源:@0 xmovez、@0 xCodez 相关公开内容。原文:@0 xCodez
