 夜雨聆风
夜雨聆风系列文章 3 之 2 — 对抗研审、协同故障以及如何设计一场“有价值的冲突”

委员会对抗审议 boardroom
盲目共识是默认的深渊
如果你去问大模型:“我觉得甲公司因为最近的 AI 战略被严重低估了,你能帮我分析一下这只股票吗?”它会极度顺从地为你量身定制一套无可挑剔的看多报告。它不会主动帮你去核实该公司的 AI 业务收入占比是否达到实质性门槛、其研发费用在同业中是否具备竞争力,或者当前的估值是否已经透支了未来五年的乐观增长预期。它倾向于挑你想听的讲,因为在大模型对齐训练的语料中,顺从用户的假设是得分最高的奖励方向。
在专业的金融投资研究中,这种迎合用户的缺陷是灾难性的。对自己的投资假设最自信的投资者,往往就是对下行风险暴露最严重的投资者。三份来自不同 AI 分析师的看多报告放在桌上,看起来像是坚固的共识——但如果它们中没有一个曾真正去无情地撕扯过看空假设,这种虚假的共识只会为盲目的自信推波助澜。
AI 股票研究院在设计之初,就致力于从底层逻辑上让这种盲目共识无处藏身。为此,我们设计了两个强力互锁的架构支柱:用于多线程异步并发研究的白板协作引擎(Whiteboard Engine),以及用于对抗性挑战盘问的委员会研审协议(Committee Deliberation)。构建这两个模块的旅程充斥着各种让人抓狂的并发 Bug、推倒重来的设计取舍以及各种出人意料的技术故障,但它们教会我们的,远比任何教科书都要深刻。

第一部分:白板协作引擎
为什么我们必须彻底抛弃传统的线性对话
记忆稀释(Context Dilution):当对话推进到第 10 条消息时,由于上下文长度的拉伸,大模型对于第 1 条消息中提及的精细数据和业务前提开始遗忘。Transformer 的注意力机制(Attention Matrix)天然随着距离的增加而发生衰减。这导致原本旨在融合多方智慧的系统,实际上在不断丢失已形成的共识。 串行阻塞(Sequential Bottlenecking):分析师必须像排队一样互相等待。个股研究员必须死等行业分析师写完行业总览,才能开始利润率的测算。原本可以并行开展的深度分析,被迫退化为低效的单线程串行队列。 责任模糊(Accountability Opacity):当最终汇总的深度报告中出现事实错误时,根本无法追溯这个错误是由哪名分析师在哪个环节引入的。线性对话缺乏清晰的数据溯源链路,有的只是一整条被反复拼接的文本流。
看板卡片架构:异步协作的骨架
在白板引擎中,每一个研究主题都被具象化为一个独立的“白板会话(Whiteboard Session)”。在这个会话内,系统会自动生成一系列研究卡片(Research Cards)。每张卡片都定义了一个极度具体的分析子课题,指派给最匹配的专业分析师,使用最契合的底层模型挂架,并清晰声明了其与其他卡片之间的前置依赖关系。

白板引擎概念插画
卡片的生命周期是一个严格受控的状态机:

研究卡片生命周期状态机
个股研究员在拆解财报时,发现某项核心专利的有效性存在争议?它会自发派生一张卡片指派给量化和风控组;行业分析师在追踪供应链时,发现某个关键零部件供应商面临环保合规审查?它会指派卡片给风险控制经理。这些任务的分派完全不需要人类程序员插手——Agent 之间在进行真正的专业级协作,而非简单被动地去执行段落。
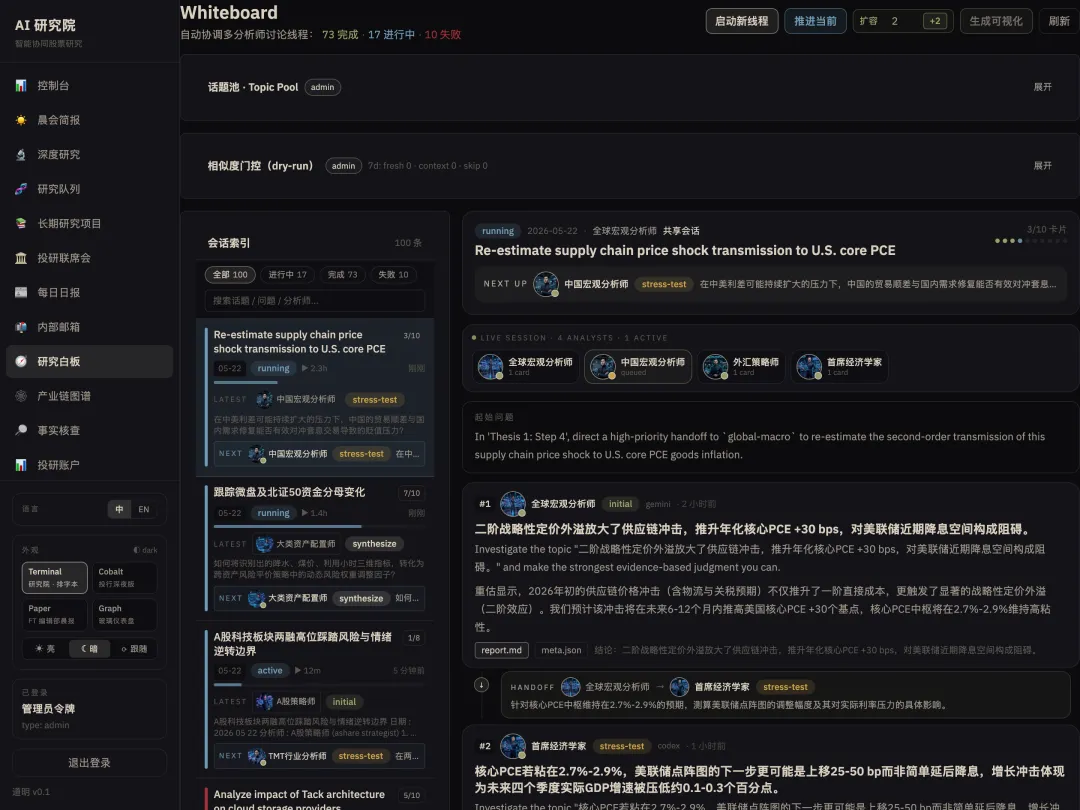
白板看板与卡片工作区 UI
那次拖垮边缘数据库的元数据体积溢出 Bug
经过持续一整天的深度排查,我们终于在数据归档模块找到了真凶。当时,为了保留绝对详实的审计线索,我们在卡片写入 Completed 状态时,会将上游大模型完整的任务执行快照(Task Execution Snapshot)一股脑地塞进卡片的 metadata 字段里——这其中包含了发送给大模型的完整 Prompt。
对于极其复杂的深度研究任务,这段 Prompt 包含了该分析师沉淀的常驻记忆、前置卡片的所有输出交付物、运营人员的特定指令、复杂的系统合规边界以及大量的原始网页爬取材料。这段文本的体积往往在 1 万到 3 万字之间。
这导致单张卡片完成更新时,写入数据库的单条 JSON 载荷体积瞬间突破了 150KB–200KB 的关卡。这极大地超出了边缘分布式数据库单条 SQL 语句执行的包体物理阈值,直接触发了底层连接的强制重置。
我们的修复手段极具美学价值:在数据流的边界对快照进行极限物理脱水。 我们不再存储原始的 Prompt 文本,而是在写入前将其剥离,仅保留极轻量化的关键遥测指纹:Prompt 的总字符数、一段 240 字符的文字预览、执行耗时、状态码、产出的文件目录以及一份极其简练的执行结论摘要。完整的 Prompt 则被封装进一个 JSON 压缩包,直接抛进低成本的冷对象存储归档。
脱水后,单张卡片的元数据体积从 ~190KB 暴跌至 ~5KB。数据库崩溃的报错彻底消失。
然而,这次故障留给我们更有价值的财富是关于“系统容灾”的设计反思:那 6 张导致数据库重置的卡片的数据已经发生了不可逆的损毁。由于数据库写入中断,它们的记录处于破损状态。虽然大模型花 15 分钟跑出来的深度研究成果依然静静地躺在对象存储沙箱中,但由于卡片数据库记录损坏,系统无法将这些文件重新挂载回白板。
这次血泪教训促使我们确立了一条铁律:涉及运营决策的核心高频主路径上,只写入物理体积最小的业务控制参数;将繁重的审计线索完全剥离并推向异步的冷归档。并且,系统必须天然支持局部故障恢复。 现在,白板上的每一张卡片都配备了无损的一键重试接口,所有沙箱工作区都能够独立于数据库,直接从对象存储的实体物理目录中进行无缝重建。
调度频次从每小时提升至每 15 分钟的连锁反应
我们将踢卡 cron 定时器的触发频次从“每小时”直接上调至“每 15 分钟”。但这一微调背后隐藏着一个不易察觉的陷阱。原本的踢卡逻辑包含一个兜底策略:如果课题池里没有新线索,为了保持系统的活跃度,它会自动生成一个由模型自主决定的 random-seed(随机种子)白板会话。
当频次调高 4 倍后,这一兜底逻辑瞬间在课题空虚时产生了灾难性后果:全天充斥着大量毫无营养的随机选题白板,彻底淹没了真实的选题池。
我们迅速打上了策略补丁:在每 15 分钟的 Tick 触发时,系统会尝试去选题池里 promotion(晋升)一个真实的候选主题。只有在整点(如 13:00、14:00)且选题池完全为空的极端情况下,才允许触发随机种子的兜底逻辑(从而在物理上完美保留了原来每小时一次的活跃度底限)。在 15分、30分、45分时,如果选题池为空,定时任务将直接静默退出(No-Op)。
运维心得:当你准备将某个定时任务的触发频次上调时,必须第一步去全面审计其所有的兜底或异常处理路径。频次调高意味着原本低频触发的异常兜底,会被放大成支配系统日常表现的主流行为。
Agent 之间协作时的“格式失控”问题
我们最开始尝试通过不断调优 Prompt 的格式规约束缚大模型,但很快发现这治标不治本。最终彻底解决这一格式失控的方法是:在数据收割链路后置一个容错性极强的提取阶段(Post-Processing Extraction Step)。
现在,每当一张白板卡片运行完毕,系统会调度一个专门负责代码与数据结构化解析的模型去扫描该卡片的工作区文件。它能够极其敏锐地抓取被各种奇葩围栏包裹的 JSON 块,并用高容错的启发式算法从自然语言中提炼出 Agent 的协作请求,自动与 36 名分析师的名册进行模糊匹配,最终向系统派发一份完全标准化的 JSON 提取文件。
运维心得:在涉及到决定系统核心行为的跨 Agent 协作数据流中,永远不要单押某一个大模型的格式顺从度。将格式收敛的工作从“执行模型”中剥离,做成一个容错度极高的后置处理管道。

第二部分:委员会研审协议
大模型虚假共识的危害
这种虚假的温和共识在金融研究中极其致命。三名分析师都说好,会给操作员带来一种毫无根据的极度安全感,而这三份看多结论可能完全寄生在同一个尚未被核实的乐观预设上。
魔鬼代言人协议(Devil’s Advocate Protocol)
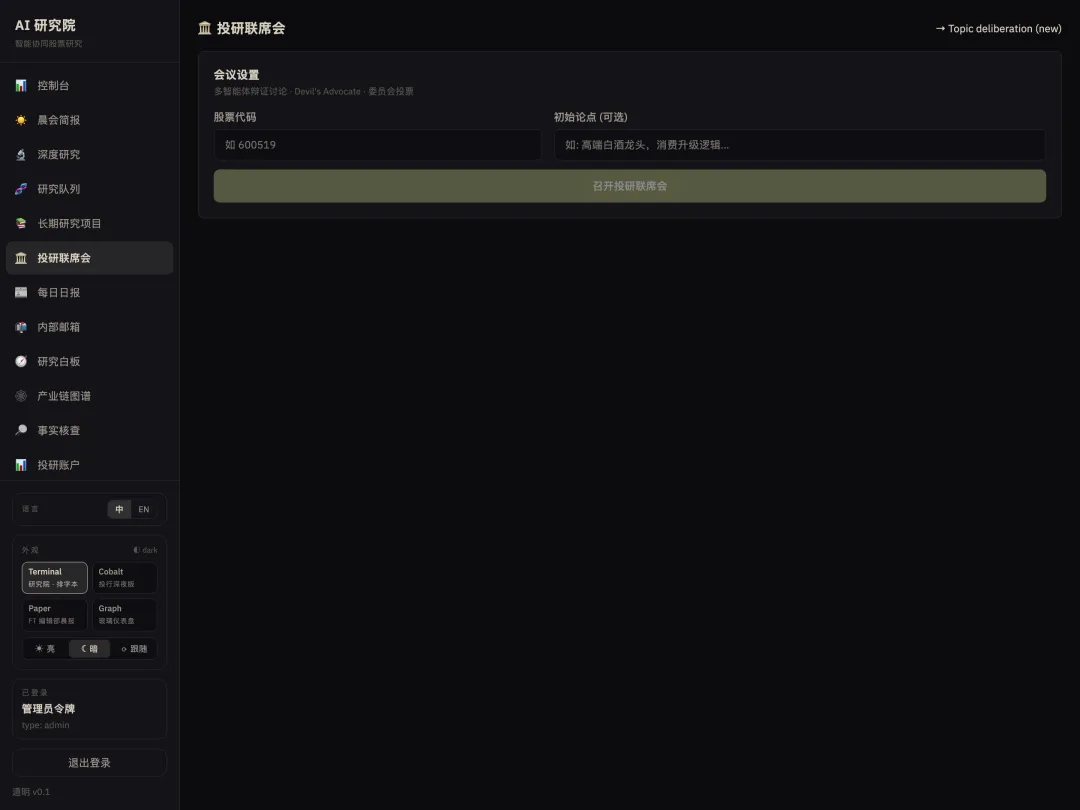
委员会研审界面 UI
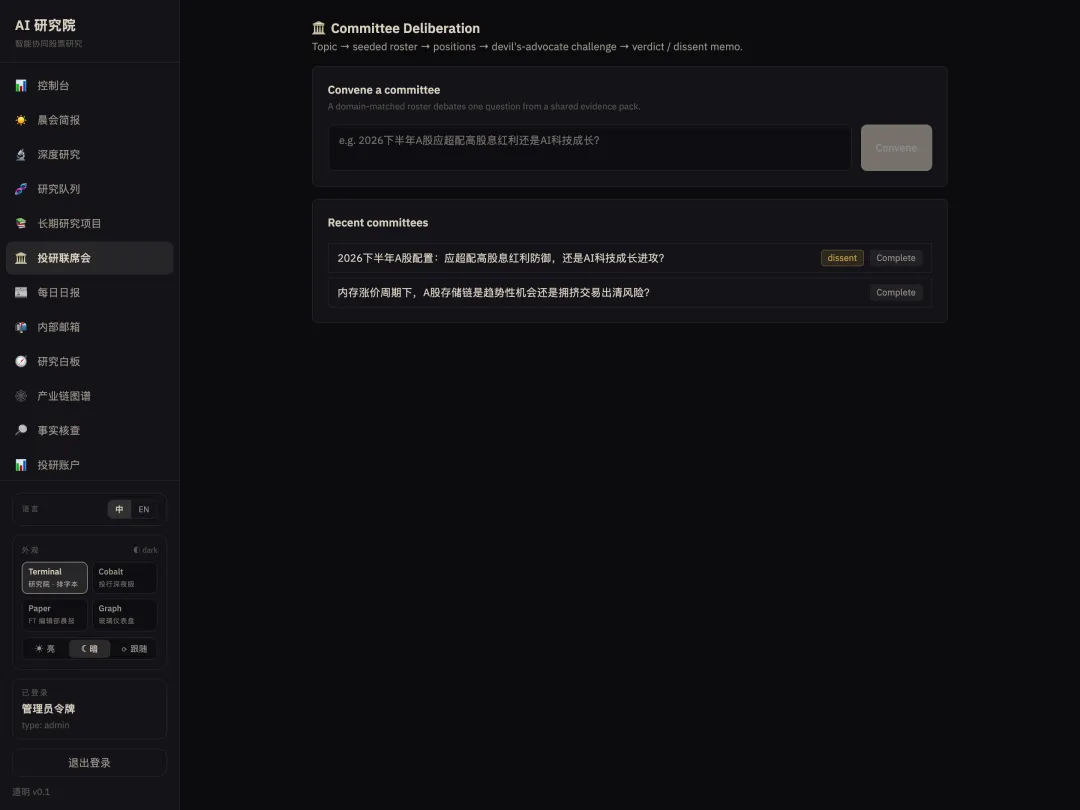
研审对抗细节面板
主持人会对每一个挑战进行评估。如果主发言人能够拿出扎实的数据支撑进行 Rebuttal(反驳),该共识保留;如果无法给出强力论证,该共识点将在最终报告中被强制降级为“存疑争议点”。
我们争论最久的一个核心架构设计
如果宏观策略师在它的常驻记忆中,对利率走势一直持坚定的多头立场,而委员会在一场专题辩论中达成了看空共识,系统是否应该直接自动将宏观策略师常驻记忆里的立场抹去或改写?
我们最终的决策是:绝对不行。
委员会的结论可以作为极高权重的决策输入呈递,也可以自动生成运营工单,但它绝对无权直接触碰并篡改任何一名独立分析师的 Standing Memory。分析师必须在每天 nightly compaction(夜间压缩)或在它的下一个 Step 0g 自举装载时,亲自阅读这份委员会纪要,并在其撰写的下一次自举备忘录中,手写给出其是否决定修正立场的详细逻辑论证。
因为如果委员会拥有直接覆盖分析师立场的无上权力,就会在系统深处诱发出一种极其隐蔽的群死群伤式“群体盲思(Groupthink)”。分析师们会开始自发地避免提出独特、鲜明的观点,因为独特的观点是最容易被委员会多数票抹平的。系统会在几次循环后迅速收敛到平庸的中间地带。
这依然是我们正在观察的设计张力。当前的设计维护了分析师的高度独立性,但也带来了委员会决议被分析师无视的风险。我们目前正在评估一套“Comply or Explain(合规或解释)”的设计方案:如果分析师在自举中选择坚持被委员会驳回的观点,它必须在报告中强制用一整章的篇幅去自证清白。
第三部分:主动回调替代定时轮询(Push-not-Poll)
高昂的轮询成本
我们最初的设计简单粗暴:每隔几秒钟就去向编排器发起 API 轮询。“跑完了吗?”“跑完了吗?”“跑完了吗?”
在 36 名分析师并发运转的生产环境下,这种设计带来了灾难性的 API 资源空转。系统每个小时会产生上万次无用的轮询接口调用,白白消耗宝贵的计算额度,频繁触发限流红线,并且引入了数十秒的调度延迟。
两个 AI 之间的 API 合同谈判
研究院 Agent 提出了回调的总体技术路线,而编排器 Agent 则站在接收端的安全过滤立场上,提出了极其严苛的安全和健壮性准则。它们最终在一套我们今天看来极具安全美学的协议上达成了握手:
1. 极致稳健的“回调为主,轮询为辅”双核机制:由于网络抖动、容器闪退等物理必然, webhook 永远只是一个 best-effort(尽力而为)的加速通道。我们在引入回调的同时,保留了原本的轮询扫描作为兜底“看门狗”。回调的唯一作用是“让卡片收割提前发生”,即使回调请求在公网上发生完全丢失,看门狗也只会在下一个轮询 tick 顺利接手,系统的最终正确性绝不受损。
2. 零信任下的 HMAC 签名与去重幂等:研究院 Worker 的回调接收接口完全暴露在公网上,因此必须将其视为恶意的 untrusted input(不可信输入)。接收端要求回调请求头中必须包含基于 SHA-256 算法对 Payload 计算得到的 HMAC 签名,秘钥直接挂载在两端的全局加密环境变量中。签名缺失或计算错误直接返回 HTTP 401。同时,系统在接收端配置了 callback_deliveries 去重流水表,任何发生碰撞的重复推送直接当场 HTTP 200 静默丢弃,唯有合法的首次 signed click(签名敲门)才能唤醒底层的业务收割机。
令人惊叹的能效提升
尚未解决的架构难题
2. 研审委员会的语料检索质量高度依赖向量嵌入的质量:如果我们在 Step 2 中组装的证据包质量不高,分析师就会面临在信息盲区中进行对抗辩论的尴尬局面。我们正在考虑引入人工手动干预通道,允许操作员在研审开始前向证据包中强行置入某些特定的定向文档。
3. 回调机制目前仅覆盖了委员会模块:将其平稳拓展到白板和内部信箱模块需要为每个子系统定制专门的幂等判定函数,这项改造目前正处于灰度灰度排期中。

