 夜雨聆风
夜雨聆风AI Agent 的进化四课:你让AI写一篇文章,30秒里发生了什么?

你点了一份外卖。
手机屏幕上显示"骑手正在取餐",二十分钟后门铃响了。你拿到饭,吃完,全程没多想一秒。但如果你停下来往回看——接单、备菜、烹饪、打包、配送——这链条里的每一个环节,缺一个都不行。
AI 写文章也一样。
你说"帮我写一篇公众号文章",30秒后一篇排版精美、配图齐全的文章出现在草稿箱。你看了两眼,改了几个字,点了发送。
那 30 秒里发生了什么?
答案是:四堂课。AI Agent 花了四年时间,上了四堂课,才学会怎么像一个人一样完成这件事。
今天我们就来讲这四堂课。
第一课之前:一台只会"接话"的机器
2022年底,ChatGPT 横空出世。全世界都疯了。
你问它什么,它答什么。你让它写诗,它就写诗。你让它翻译,它就翻译。看起来无所不能。
但它有个致命缺陷。
它只能"接话"。你给一句,它回一段。它不知道今天是几号,搜不了最新的新闻,打不开任何网页,也写不了文件。就像一个被关在房间里的人,智商很高,但和现实世界之间隔着一堵墙。
为什么呢?
因为大语言模型的本质是"预测下一个字"。它读过海量的文本,学会了语言的统计规律,但它没有一个"行动"的出口。它能告诉你"查天气的方法",但它查不了天气。它能描述"写代码的思路",但它执行不了代码。
这在简单的问答场景里够用了。但写一篇公众号文章,需要搜索最新的热点、读取用户的历史风格、生成配图、排版推送——这些事,光靠"接话"做不到。
用一段伪代码来看,最原始的 AI 是怎么工作的:
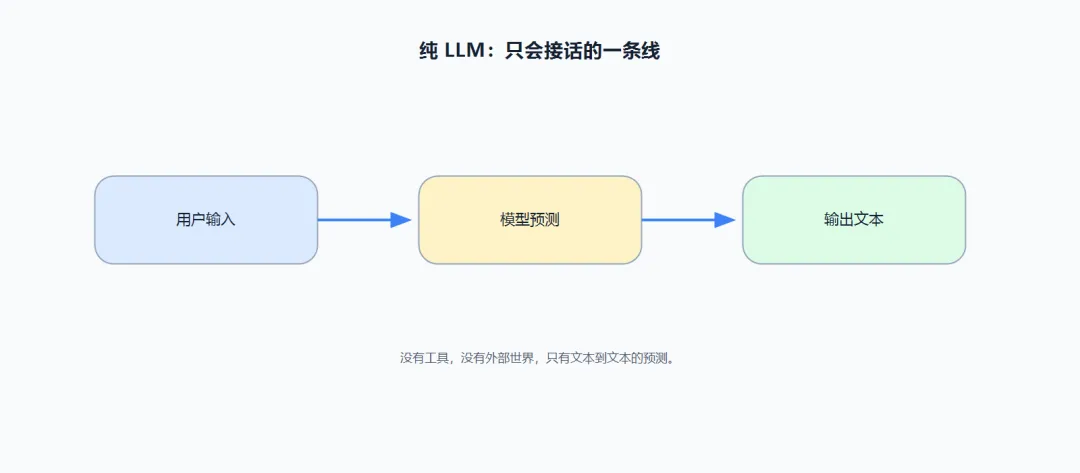
没了。就这一条线。模型没有"手",没有"眼",只有一个"嘴"。你问"今天北京天气怎么样",它会基于训练数据里见过的天气预报文本,编一段看起来合理的回答。但2023年3月15日的北京实际气温是多少?它不知道。它没见过那天的数据。
你让它写一篇关于"2025年AI行业最新动态"的文章——它写的全是2022年以前的知识。
就像一个被困在房间里的人。外面发生了什么,他不知道。
于是,第一堂课开始了。
第一课:学会用工具——"给它一双手"
这堂课的正式名字叫 Tool-Use,也叫 Function Calling。
名字不重要,重要的是它解决了一个关键问题:怎么让一个只会说话的大脑,长出可以做事的手。
实现的逻辑其实非常直白。先给模型配一张"工具菜单":
{"tools": [{ "name": "web_search", "description": "搜索网页,获取实时信息" },{ "name": "read_file","description": "读取本地文件内容" },{ "name": "write_file", "description": "将内容写入文件" },{ "name": "generate_image", "description": "调用AI绘图接口生成图片" }]}然后告诉模型:你需要用到什么工具的时候,说出来就行。
接着神奇的事情发生了:
用户: 帮我写一篇公众号文章,主题是"AI Agent 进化史"AI: 我需要先了解一下最近有什么相关的热点。 → [调用工具: web_search("AI Agent 2025")]系统: [返回搜索结果: 3条相关文章, 2篇论文...]AI: 好的,素材够了。我开始写大纲。 → [生成大纲中...]AI: 正文写到一半,需要配一张封面图。 → [调用工具: generate_image("AI Agent 进化四课 封面")]每一次工具调用,都是模型在说"这件事我靠自己搞不定,帮个忙"。
模型遇到"查一下今天的热搜"时,它不再编一个假的热搜榜。它说:"我需要调用搜索工具。"系统帮它搜了,把结果塞回给它。它看了一眼,继续写。
这个过程像一个什么比喻?一个被困在房间里但终于有了电话和电脑的人。以前有人敲门问"今天外面热不热",他只能根据过去的经验猜。现在他可以拿起手机查天气预报了。
工具调用的本质,是打破了语言模型的边界。
从"我知道"变成了"我能做"。
但你很快就会发现问题。真实世界的任务,很少是"查一次→出结果"这么简单的。
比如写文章。你以为的流程是"搜一个关键词→拿到素材→写"。实际的流程是:搜了关键词→发现这个词热度不够→换一个词再搜→搜到了但是信息太少→换个搜索引擎再试→终于够了→开始写→写到一半发现数据不够→又去搜。
你看。这不再是一次性的"调用-返回"了。
这是一连串的"观察→调整→再行动"。
第二堂课由此而来。
第二课:学会思考——"边想边做"
这堂课的正式名字叫 ReAct,是 Reasoning(推理)和 Acting(行动)的合成词。
但我更喜欢一个厨房里的比喻。
你做一道菜。菜谱上写"加一勺盐"。你加了。然后你尝了一口——太咸了。你加了一点糖。再尝——嗯,差不多了。又觉得颜色不够好看,撒了几颗葱花。
你做菜的过程,不是"读完菜谱→一次性做完"。而是每一步都在观察结果,然后决定下一步怎么做。
ReAct 就是这个做菜的过程。
形式化地说——每个循环包含三个步骤。观察(现在是什么状态)→思考(我需要做什么)→行动(执行并得到新结果)。然后进入下一个循环。
不抽象。来看一个真实的 ReAct 写作场景——Agent 正在写一段关于"AI行业增长"的文字:
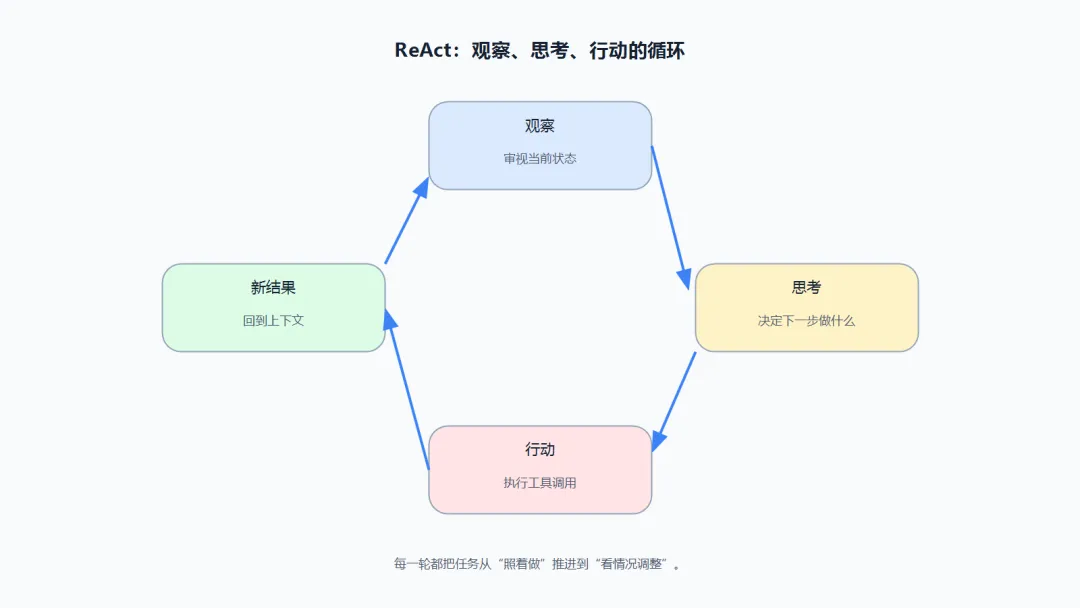
三个循环,三次观察-思考-行动。句子从一个空洞的断言,变成了一个锚定在数据上的信息点。
如果用伪代码把这个循环写出来,大概长这样:
def react_loop(task, tools, max_steps=10): context = taskfor step in range(max_steps):# 观察(Observe): 审视当前状态 observation = observe(context)# 思考(Reason): 决定下一步做什么 thought = reason(observation)# 终止条件: 如果"想"完觉得够了,就输出if thought == "DONE":return context# 行动(Act): 执行工具调用,得到新信息 result = execute_tool(thought.selected_tool, thought.params)# 将结果加入上下文,进入下一轮 context += result循环停下来的条件很简单——模型觉得自己已经足够好了,或者到了步数上限。
这才是人类写作的真实方式。没有人先把全文都在脑子里想好再落笔。你边写边发现缺了什么,缺了就去查,查到就写进去,写完再读,读不顺就改——每一轮都是一次微型的观察-思考-行动。
ReAct 让 Agent 从"执行者"变成了"问题解决者"。
它学会了灵活应变。
但你很快发现了新的问题。
灵活应变适合处理"当下的这一步"。写一段,发现缺素材,去搜。再写一段,发现语气不对,去调。这没问题。
但如果目标是写一篇完整的文章呢?如果目标是写一本书呢?如果目标是开发一个 App 呢?
如果没有地图,你会在细节的迷宫里绕不出去。
第三堂课来了。
第三课:学会规划——"谋定而后动"
这堂课的正式名字叫 Plan-Execute。先规划,再执行。
装修房子是最好的类比。
你拿到一套毛坯房。你不会拿起锤子就开始砸墙。你会先请设计师出一份图纸。客厅怎么布局,水电走哪里,家具放什么。图纸确认了,然后才是:拆除→水电→泥瓦→油漆→硬装→软装。
每一步有它的先后顺序。水电不能排在油漆后面——因为线管要埋在墙里。
复杂任务天生有结构。忽略这个结构,越灵活越容易出错。
Agent 学会了这一点。在开始写作之前,它先画一份"图纸"。这份图纸长什么样?以写一篇公众号文章为例:
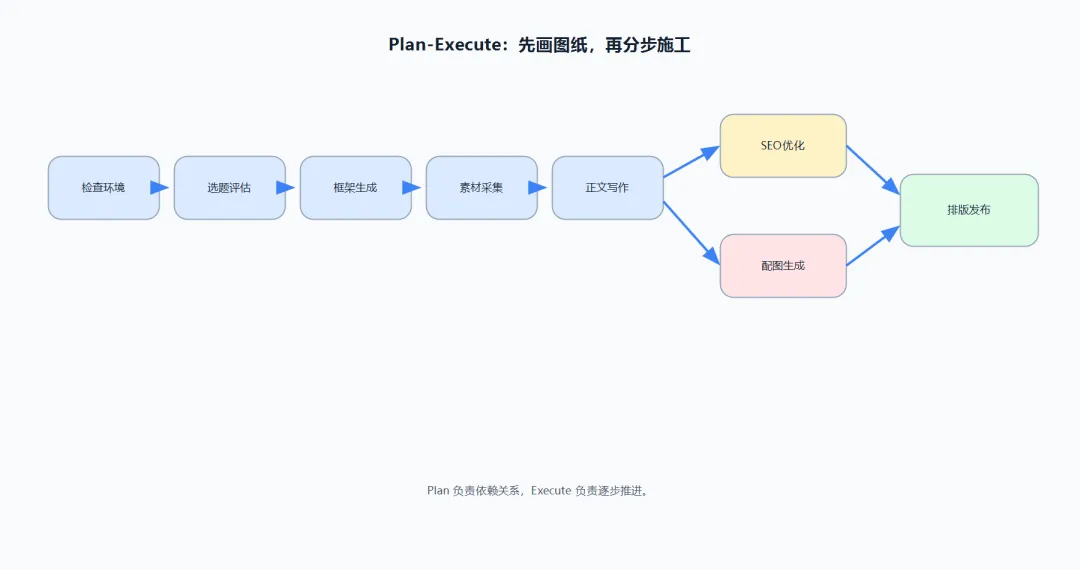
注意 depends_on 这个字段——它定义了步骤之间的依赖关系。选题必须先于写作,排版必须在写作完成之后。但配图和 SEO 可以并行(它们都只依赖 step_5,互不依赖)。
这就是 Plan 的价值——在执行开始之前,依赖关系已经理清楚了。
然后用 ReAct 的能力一段一段去写——写的过程中该搜就搜、该改就改。这叫 Execute。因为有了 Plan,每一刻都知道自己在整个结构中的位置,不会走着走着偏离主线了。
我拿你正在读的这篇文章来举例。
写之前,Agent 先做了一个规划——这篇文章用"进化递进"的叙事框架,四堂课加一个番外,每节课讲一种模式解决什么问题、为什么被逼出来。这个规划保证了整篇文章的连贯性,不会写到最后发现自己跑题到了"AI 取代人类"的哲学讨论上。
然后每一段的写作仍然用 ReAct——写到某些地方发现需要更具体的例子,就去搜索真实的产品或论文作为佐证。
Plan 负责"不跑偏"。ReAct 负责"不枯燥"。
这就是 Plan-Execute 的核心价值:它让 Agent 从"处理一件事"升级到"搞定一个项目"。
三堂课下来,一个 Agent 已经很强了。能规划、能执行、能反思、能调用工具。一个人能干完大部分文章的写作工作。
但你有没有发现一个问题?
从头到尾,只有一个 Agent 在工作。
真实世界里的复杂产出——一本杂志、一部电影、一个软件产品——从来不是一个人完成的。是一个人定方向,另一个人写具体内容,第三个人配图排版,第四个人做最后的核对。
一个人的注意力有限。30 个步骤的任务,总会有某几步被做浅了、做漏了。
所以有了第四堂课。
番外课:学会协作——"一个人做不到的事"
这堂课的正式名字叫 Multi-Agent,多智能体协作。
它的核心洞察非常简单:不是造一个更强的 AI,而是让一群会配合的 AI 来干活。
回到编辑部这个比喻。
一个好的编辑部里不是只有一个员工。有主编负责选题和最终质量,有记者负责采访和写稿,有美编负责封面和排版,有校对负责错别字和事实核查。每个人专精一个环节,合在一起出来的东西,一个人绝对做不出来。
Multi-Agent 就是给 AI 配了一个虚拟编辑部。
实际操作中,一个"主编 Agent"先把文章规划好,然后启动几个"专家 Agent"并行工作。大概长这样:
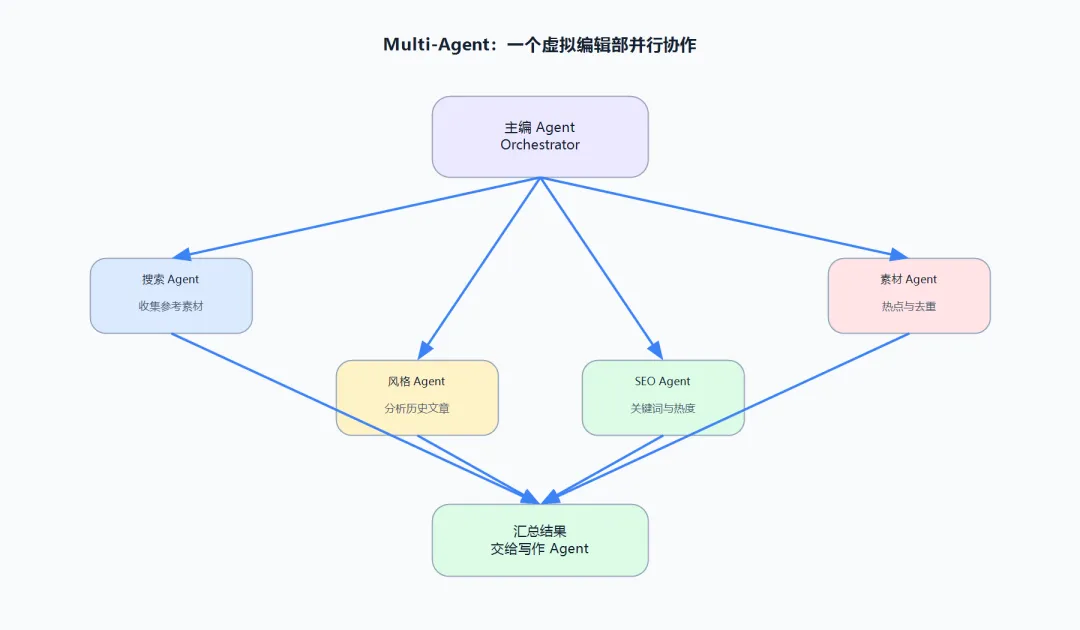
三个 Agent 同时跑,主编拿到全部结果后汇总给写作 Agent。
整个过程在 30 秒内发生。
你可能觉得这离自己很远。其实就在此刻,Claude Code、Cursor、Copilot 这些编程助手背后已经在重度使用 Multi-Agent 模式了。一个 Agent 负责理解你的需求,一个 Agent 负责搜索相关代码,一个 Agent 负责写代码,一个 Agent 负责检查它。你只看到一个对话窗口,但窗口背后是一个团队在运转。
从信息论的角度说,Multi-Agent 解决了一个根本的瓶颈——单个模型的注意力是稀缺资源。把一个复杂任务拆给多个专业角色,每个角色只关注自己职责范围内的信息,整个系统的有效注意力就放大了数倍。
这不只是一个工程优化。这是 Agent 在组织形态上向人类靠近的关键一步。
尾声
最后,让我们回到开头那个场景。
下午三点,你对 AI 说"帮我写一篇公众号文章"。五分钟后,一篇排版精美的文章出现在草稿箱。
这五分钟里,五种模式各司其职。
| 纯 LLM | |||
| Tool-Use | |||
| ReAct | |||
| Plan-Execute | |||
| Multi-Agent |
大部分技术科普文章到这儿会补一句结论。但我想说点别的。
Agent 进化的四条路径——用工具、会反思、懂规划、能协作——本质上不是 AI 的原创。
这是人类几千年组织工作经验的外化。一个人干活遇到瓶颈了,开始用工具。工具用多了发现要复盘。小事做熟了开始做大事,需要规划。大事做多了开始建团队,需要协作。
AI Agent 的进化课,其实是重新走了一遍人类文明的效率之路。
只不过它走得快多了。
四年。四堂课。接下来是什么?没人知道。但有一件事是确定的——AI 在变得越来越像"一个人"。不是长得像,而是做事的方式像。
而理解这些方式,就是你理解 AI 最好的一把钥匙。
