 夜雨聆风
夜雨聆风点蓝字关注 设为星标 ☆ 优先赏阅
在审计现场,和小伙伴们一起思考,在复杂经营的形势下,外部风险渗入压力很大,如何做好检查。和小伙伴们一起研究新动向、新苗头、新数据。审计工作是实践科学,最终还是要落到数据分析和实地核查上。
在现场,对AI时代的数字化审计,观察到四种状态:
工具式使用:许愿式提问Prompt,提问即终点 穿新鞋走老路:看到了,但还是习惯老路,尤其是技术大拿 健身卡式投入:买了书、听了课,但卡在了环境安装这一步 梦想式构想:制度和资料扔进去直接出问题
无论是否接受,但却无法回避,会写SQL再也不是数字化审计人的护城河。
当AI能替你写SQL、做探索、出结论时,审计人的核心竞争力到底是什么?
引子
AI大神Karpathy的"Claude Coding随手记",跟审计有什么关系?
Andrej Karpathy(前特斯拉AI VP、OpenAI联合创始人、被誉为AI圈最懂代码的人)发了一段题为A few random notes from claude coding quite a bit last few weeks的随手记。
文中Karpathy对LLM老毛病的总结太真实了,这篇文章也在技术圈、AI应用圈刷屏。
Karpathy描述了自己工作流的转变:从2025年11月的80%手写代码+20%AI辅助,迅速切换到12月的80%AI Agent编码+20%人工审核。他称之为用英语编程,就是用自然语言告诉LLM要写什么代码,AI生成,他负责review。
他总结了一系列LLM的老毛病:
🤖 Karpathy总结的LLM五大毛病
| 默默做错误假设 | |
| 不会管理困惑 | |
| 过度设计和抽象膨胀 | |
| 范围蔓延和附带改动 | |
| 微妙的概念性错误 |
Karpathy给LLM的定位是:一个非常快、但有点心不在焉的高级工程师。
信任它生成起点,但不信任它不review就正确。
读完文章,我想到的是审计
作为资深的数字化审计人,我读这篇文章时的感受是:
我们在用AI做数据分析时,这些毛病一个不落。
🤖 审计场景中的"LLM老毛病"对照
| 默默做错误假设 | |
| 不会管理困惑 | |
| 过度设计 | |
| 范围蔓延 | |
| 微妙的概念性错误 |
Karpathy说:
"The primary work is now: framing the problem precisely, specifying constraints & invariants, pointing at the right context, and then carefully reviewing the diff."
翻译过来就是:
核心工作变成了:精准定义问题、指定约束和不变量、指向正确的上下文、然后仔细review结果。
这不就是声明式思维吗?
通俗一点儿说就是:你有什么?你想要什么?你的约束是什么?
Karpathy提出的解决方案,和我们在审计数据分析中应该采用的方法,本质上是同一个思路。
从"写SQL的人"到"设计规则的人"
🤖 传统审计数据分析的工作流
理解需求 → 写SQL → 跑数据 → 看结果 → 调整SQL → 再跑 → 分析 → 出报告这个流程中,审计人60%的时间花在写SQL和调整SQL上,只有40%的时间花在真正的分析上。
但努力不等于回报,你的分析深度,被你的SQL能力锁死了。
一个复杂的分析需求,如果你想不到用窗口函数、CTE、自连接来实现,你就永远看不到那个维度的数据。
🤖 AI时代的数字化审计工作流
定义问题 → AI生成查询 → 看结果 → 追问/调整问题 → AI深化 → 分析 → 出结论关键变化:写SQL这个环节被抽掉了,变成了AI的自动推理。
这里有个微妙而重要的区别:从"告诉AI怎么做"变成"告诉AI要发现什么"。
命令式用法:"帮我写一个SQL,查出A表金额大于100万且B表状态为'已审批'的记录"
这相当于你亲自设计好了查询逻辑,只是让AI替你打字 - 杠杆率:1x
声明式用法:"帮我找出这笔业务中可能存在利益输送的异常交易"
AI需要自己理解"利益输送"的特征(关联交易、异常定价、频繁退款等),自己设计查询路径 - 杠杆率:5-10x
陌生数据的声明式分析
审计工作中,陌生的数据越来越常见:
- 新业务系统导出的数据
比如银行新上了理财系统、托管系统、跨境支付系统 - 被审计单位提供的专项数据
比如某分行提供的内部考核数据、某部门的业务台账 - 外部获取的数据
工商数据、司法数据、舆情数据、供应链数据 - 非结构化数据
合同文本、审批意见、会议纪要
这些数据的共同特征是:你不知道里面有什么、数据质量如何、字段之间什么关系、正常值应该是什么。
🤖 传统做法的困境
面对陌生数据,传统做法是:
先看数据字典(如果有) 打开Excel或SQL客户端,逐列看 做基本的统计(行数、非空数、唯一值、最大值最小值) 凭经验猜哪些字段重要 尝试关联其他已知数据
这个过程极其低效,而且高度依赖审计师的个人能力和运气。 很可能是花了5天时间逐列看,最后只分析了其中5列,实在看不过来。
🤖 声明式分析的范式
对于陌生数据,声明式的核心是:让AI做探索性数据分析(EDA),审计人做解读和判断。
场景1:数据画像
命令式(低杠杆):
"帮我看看这个表有多少行、多少列,每个字段的非空数量是多少,数值型字段的均值、中位数、标准差是多少"声明式(高杠杆):
"请对这份数据进行全面的数据画像,包括:- 数据规模和结构概览- 各字段的数据类型、分布特征、质量情况- 字段之间的相关性- 明显的异常值或缺失模式- 基于字段名和取值推测的业务含义请输出结构化的数据画像报告"关键差异:
命令式只得到统计数字,你需要自己解读 声明式得到的是带解读的画像,AI已经帮你做了初步分析
场景2:关系发现
命令式:
"帮我看看客户ID字段和合同ID字段是不是一对多关系"声明式:
"分析这份数据中各实体之间的关系模式,识别主键候选字段、外键关联字段,推断可能涉及的实体和它们之间的关系(一对一、一对多、多对多)"这个能力在陌生数据分析中极其强大。
传统做法需要你手动验证每一对字段的关系,而AI可以一次性扫描所有字段组合,自动识别关系模式。
场景3:异常发现(无预设目标)
命令式:
"帮我找出金额字段大于1000万的记录"声明式:
"在不预设任何风险假设的前提下,全面扫描这份数据中的异常模式,包括:- 统计异常(离群值、极端值)- 模式异常(不符合常规业务逻辑的记录)- 时间异常(非工作时间的操作、异常时间间隔)- 关联异常(孤立记录、断裂链条)- 分布异常(不符合本福夫定律、正态分布等)按异常程度排序并详细说明"这才是AI真正碾压传统方法的地方。
传统方法下,你只能发现你想到的异常。
声明式+AI的方法下,AI可以从多个维度自动扫描,发现"你没想到的"异常。
🤖 陌生数据的声明式分析框架
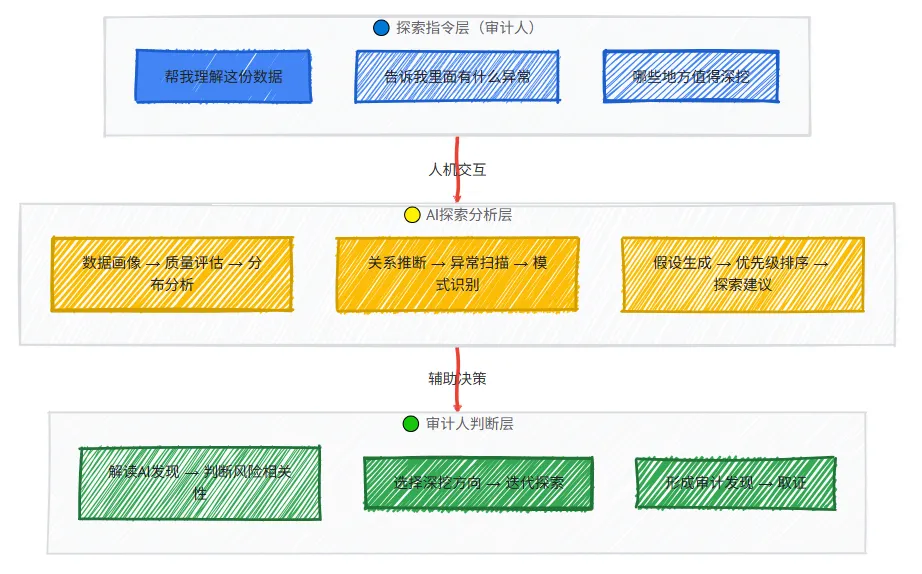
核心逻辑:AI负责广度探索,审计人负责深度判断。
声明式分析的三道"门槛"
大多数AI教程只教你"怎么下指令",但真正决定声明式分析效果的,是以下三个隐藏门槛。
🤖 门槛一:审计专业能力前置
声明式分析看似"更简单"(不用写SQL了),但实际上对审计专业能力的要求更高了。
为什么?
- 命令式分析
你不需要想清楚"什么是异常",你只需要按固定规则筛选(比如"逾期>90天"就是不良) - 声明式分析
你必须想清楚"什么是异常"、"异常的特征是什么"、"哪些维度值得看",因为AI需要你给出清晰的判断标准
举例:
低质量的声明式指令:
"帮我分析这份信贷数据,找出有问题的客户"高质量的声明式指令:
"帮我分析这份信贷数据,从以下维度识别可能存在信用风险的客户:1. 还款异常:逾期天数、还款频率变化、还款金额波动2. 关联风险:同一实际控制人下的多笔贷款、关联方互保3. 资金流向:贷款资金流入房地产、股市等限制性领域4. 财务异常:营收与贷款规模不匹配、资产负债率快速上升请按风险严重程度排序,并说明每个客户的风险特征"两者的效果天差地别。而高质量的声明式指令,本质上是审计师专业能力的直接体现。
声明式分析不是降低了审计门槛,而是把能力要求从"技术执行层"前置到了"专业设计层"。
这也正好印证了Karpathy的观点:AI时代的核心工作变成了"framing the problem precisely"(精准定义问题)。
🤖 门槛二:迭代式追问的能力
声明式分析不是一次性的。
尤其是面对陌生数据,第一轮探索往往只是"开胃菜",真正的价值在后续迭代中。
大多数人的问题是:拿到AI的第一轮结果后,不知道怎么追问。
高质量的迭代追问框架:
第一轮:数据画像"帮我看看这份数据的基本情况"↓ 发现异常第二轮:异常深挖"你刚才提到X字段有15%的异常值,请详细分析这些异常值的分布特征、可能的业务含义、以及与其他字段的关联"↓ 发现关联第三轮:关联验证"你发现A和B字段高度相关,请验证这种相关性在不同子群体中是否稳定,是否存在结构性断点"↓ 发现模式第四轮:模式拓展"基于你发现的这个模式,请在全量数据中扫描所有符合该模式的记录,并评估其总体影响"迭代追问的核心能力是:基于AI的上一轮输出,提出更有深度的下一轮问题。
这要求审计人:
能理解AI的输出(不只是看结论,要看逻辑) 能判断哪些发现值得深挖(风险敏感度) 能设计有效的追问指令(声明式表达能力)
🤖 门槛三:对AI"幻觉"的防御性设计
声明式分析最大的风险是:你给了AI很大的自主权,但AI可能会"自作聪明"。
这正是Karpathy警告的:LLM是"一个非常快、但有点心不在焉的高级工程师"。它会在你看不到的地方犯错,而且错误越来越隐蔽。
典型场景:
AI"脑补"了数据中不存在的字段 AI对异常值的解释完全错误(比如把数据缺失解释为业务异常) AI生成的SQL逻辑有误但看起来合理 AI给出的结论过于绝对,没有区分"相关性"和"因果性"
防御性设计的三个策略:
策略1:要求AI展示推理过程
"不要只告诉我结论,请展示你的分析过程:- 你用了哪些数据- 你做了哪些假设- 你的推理逻辑是什么- 结论的置信度如何"策略2:交叉验证
"你刚才发现X和Y相关,请换一种方法验证:- 用分组对比验证- 用时间序列验证- 用子样本验证看结论是否稳健"策略3:设置"反证"指令
"请尝试反驳你刚才的结论,找出支持相反观点的证据,评估两种可能性的大小"这三个策略的本质是把审计师的职业怀疑态度,编码到对AI的指令中。
审计人的新核心竞争力
回到文章开头的问题:当AI接管了数据分析的执行层,审计人的价值锚点在哪里?
Karpathy在文章最后说了一段话,我觉得是对这个问题最好的回答:
"Manual coding is turning into more of an underlying skill – like knowing how to do arithmetic in the age of calculators. Still important, but no longer the bottleneck."
手写代码正在变成一种底层技能——就像计算器时代的心算能力。仍然重要,但不再是瓶颈。
对审计人员而言,在"问题设计"和"判断决策"这两个AI无法替代的环节。
未来,数字化审计的三大核心竞争力:
🤖 风险敏感度(Risk Intuition)
知道"该查什么"比知道"怎么查"重要100倍。
AI可以帮你扫描100种异常模式,但如果你不知道哪些风险是真正的风险、哪些只是统计噪声,你就无法做出有效的审计判断。
行业经验、业务理解、对人性弱点的洞察, 这些AI教不了你。
🤖 声明式设计能力(Declarative Design)
能把模糊的审计直觉,转化为清晰的声明式指令。
这不是"写prompt"的技术活,而是结构化思维的能力——你能否把一个复杂的审计问题,拆解为可验证的子问题?能否定义清晰的success criteria?能否设计有效的迭代路径?
纸上谈兵没有用,需要逻辑思维训练、方法论沉淀、以及大量的实战练习。
🤖 防御性验证能力(Defensive Verification)
能识别AI的"幻觉"和"过度推断",设计交叉验证和反证机制。
声明式分析给了AI很大的自主权,但自主权越大,出错的风险也越大。你能否在信任AI和怀疑AI之间找到平衡点?
审计师的职业怀疑态度、对数据分析方法论的理解、以及对AI能力边界的认知, 这些始终是底座。
结语
声明式数据分析不是让AI替你干活,而是让你从执行者变成设计者。
更深刻地理解业务和风险 更清晰地表达分析目标 更批判地解读AI输出 更系统地设计分析流程
一旦跨过这个门槛,会发现:数据分析不再是苦力活,而是脑力活。而脑力活,才是审计人真正的价值所在。
正如Karpathy所说:
The fun part is that programming feels more like conversation and design than like typing.
翻译过来就是:最好的数据分析,感觉起来更像是在跟一个聪明的助手对话和设计,而不是在埋头苦算。
(个人观点,不代表所在单位意见,「小智」对本文亦有贡献)
