 夜雨聆风
夜雨聆风点击👆蓝字或👇名片,关注"AI与医学"
胸部X光影像在疾病诊疗中应用广泛,但高质量、多样化的标注数据稀缺,严重制约了人工智能模型的开发与泛化能力。为此,本研究提出了ChexGen——一个面向胸部放射影像的生成式视觉语言基础模型。该模型采用潜在扩散变压器架构,在目前最大的96万对X光影像—报告数据集上预训练,能够根据文本描述、解剖掩码或边界框精准生成逼真的胸片。






背景:医学人工智能的发展受限于大规模、多样化且高质量标注数据的匮乏,而生成式基础模型在自然图像领域已展现出通过合成数据缓解这一瓶颈的巨大潜力,但其在胸部放射影像中的系统应用仍有待深入探索。
目的:本研究旨在开发一个名为 ChexGen 的生成式视觉语言基础模型,用于胸部 X 光图像的文本、掩码及边界框可控合成,并通过系统评估验证其在训练数据增强、有监督预训练以及模型公平性检测与缓解中的实际效用。


1. 数据集构建(OpenChest)
收集8个公开胸部X光数据集,共约96万对影像-文本对。
使用GPT-4将结构化的患者元数据(年龄、性别、疾病标签等)转换为标准化放射学描述。
利用Qwen-2.5进行质量控制和校正,确保描述准确、完整。
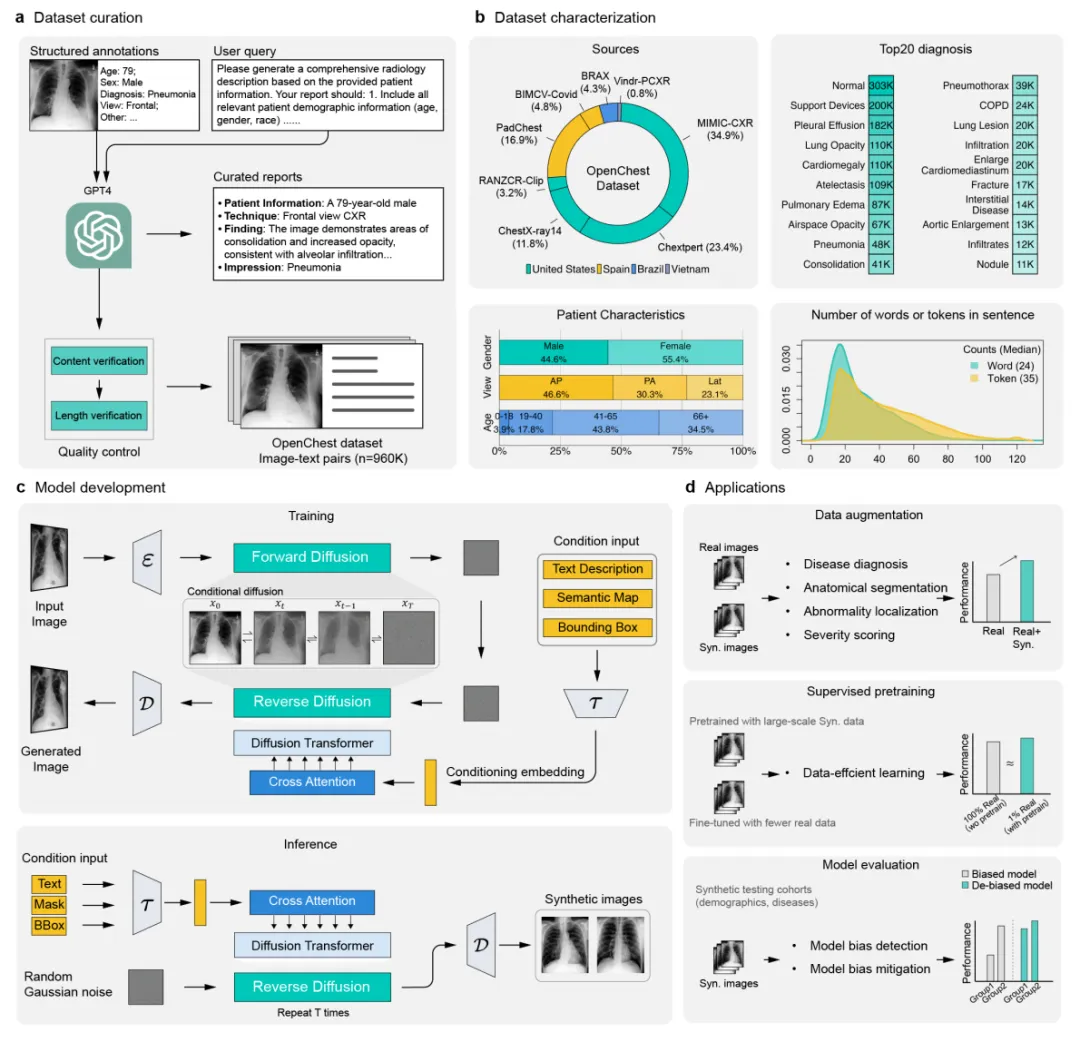
2. 模型架构设计
采用潜在扩散模型(LDM) 框架,包含三个核心组件:
▪ 变分自编码器(VAE):将图像压缩至潜在空间,实现8倍降采样。
▪ T5文本编码器:处理最长120个token的放射报告,输出4096维嵌入。
▪ 扩散变压器(DiT-XL/2):含28个Transformer块,通过自注意力和交叉注意力实现去噪生成。
引入ControlNet适配器,支持以分割掩码或边界框作为额外空间条件输入,实现精确空间控制。
3. 训练策略
两阶段训练:
阶段一(视觉-语言预训练):在OpenChest数据集上以256×256分辨率训练800轮,学习基础图文对应关系。
阶段二(视觉-语言对齐):在MIMIC-CXR的45,000对高质量PA位影像-报告上以512×512分辨率微调300轮,增强临床细节。
ControlNet微调:冻结预训练主干,仅训练ControlNet适配器,利用21k对空间标注数据(掩码/边界框)实现空间可控生成。
优化器:AdamW,学习率1e-4,梯度裁剪1.0,使用32块A100 GPU。
4. 生成图像质量评估
定量评估:
保真度:Fréchet Inception Distance(FID,使用CLIP和胸部X光专用分类器提取特征)。
多样性:平均成对结构相似性(SSIM,值越低越多样)。
事实正确性:预测疾病分数的Pearson相关系数(使用预训练CXR分类器)。
定性评估:两名认证放射科医生对150例随机样本进行盲评,采用-2(完全不匹配)到+2(完美匹配)的5点Likert量表评分。
5. 下游应用实验方法
数据增强:
使用ChexGen生成1倍或2倍于原始训练集的合成影像,与真实数据混合训练。
评估任务:多标签疾病分类(MIMIC-CXR, VinDr-CXR)、解剖分割(气胸、肋骨)、异常检测(异物、病变)、严重程度回归(肺部混浊评分)。
有监督预训练:
先在1~5倍规模的ChexGen合成数据上预训练模型,再使用不同比例(1%~100%)的真实数据微调。
评估数据集:MIMIC-CXR、VinDr-CXR、MedFMC(少样本学习基准)。
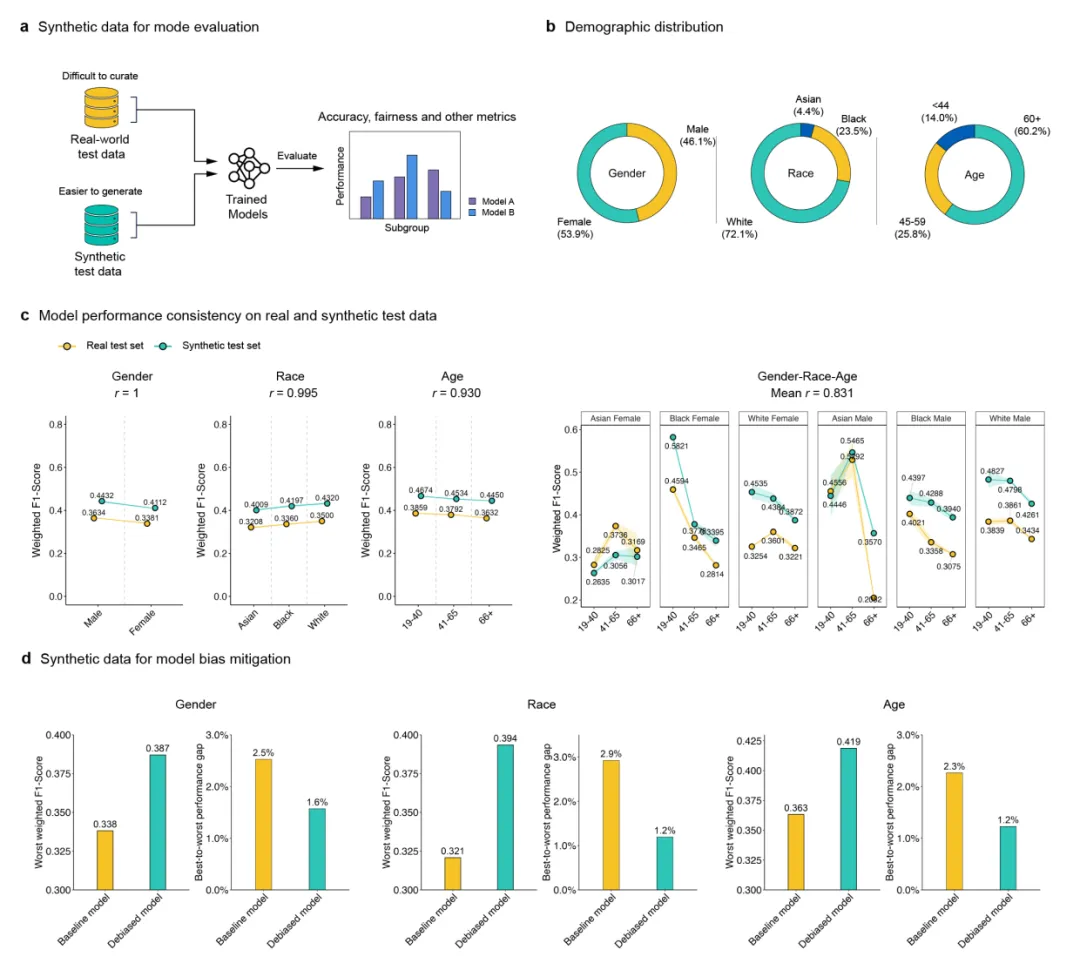
模型偏差检测与缓解:
利用ChexGen生成具有指定人口统计学属性(性别、种族、年龄)的合成测试集,评估模型在亚组间的性能差异。
针对代表性不足的亚组生成额外训练样本,使各群体样本量平衡,重新训练以缓解偏差。
6. 统计与实现
所有实验重复5次,结果以均值±标准差表示。
使用双尾Wilcoxon符号秩检验比较模型间差异,Pearson相关系数评估相关性,p<0.05视为显著。
基于PyTorch实现,使用Hugging Face diffusers库、xformers加速注意力计算。


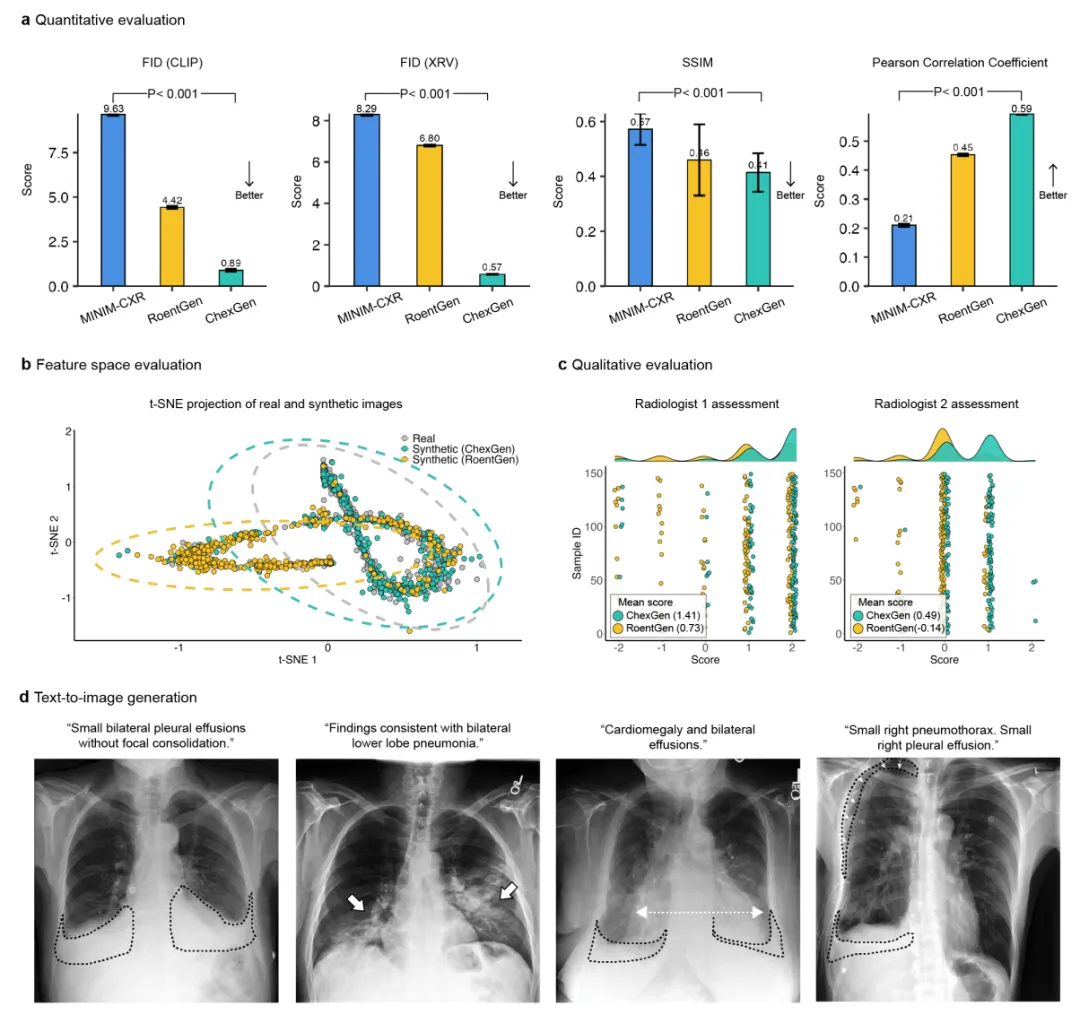
1. 生成图像质量评估
定量指标:ChexGen 在 Fréchet Inception Distance(FID)上显著优于对比模型(CLIP特征:0.89 vs. RoentGen 4.42 和 MINIM-CXR 9.63;胸部X光专用特征:0.57 vs. 6.80 和 8.29)。
多样性:平均成对结构相似性(SSIM)为 0.41,低于 RoentGen(0.46)和 MINIM-CXR(0.57),表明生成图像更多样。
事实正确性:生成图像与真实图像在疾病预测分数上的 Pearson 相关系数为 0.59,高于 RoentGen(0.45)和 MINIM-CXR(0.21)。
特征空间分布:t‑SNE 可视化显示 ChexGen 生成图像与真实图像分布高度一致,优于 RoentGen。
放射科医师盲评:两名医师对 ChexGen 的评分分别为 1.41±1.01 和 0.49±0.70,显著高于 RoentGen(0.73±1.31 和 ‑0.14±1.01,p<0.001)。
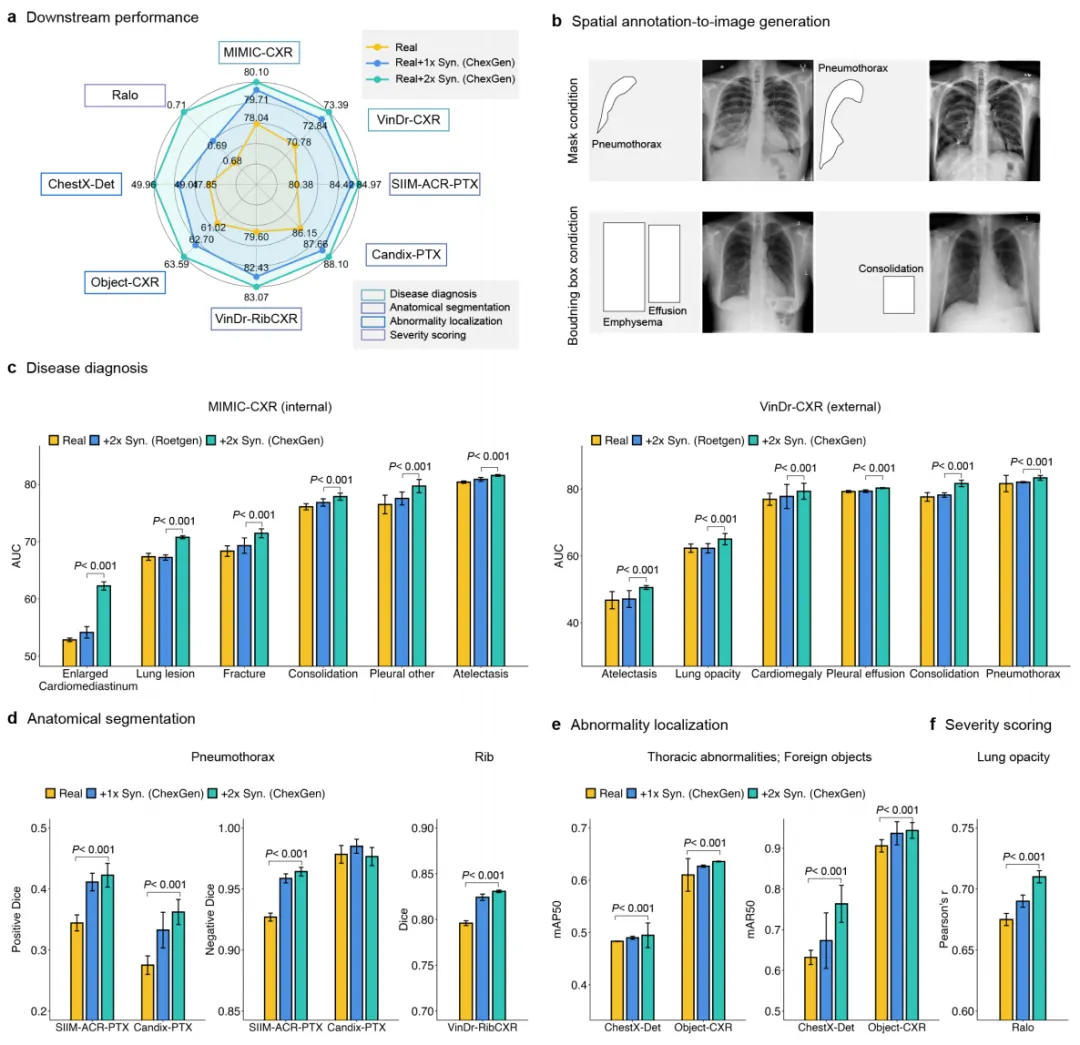
2. 数据增强效果
疾病分类(MIMIC‑CXR 14类):平均 AUC 从基线 78.0% 提升至 80.1%(2倍合成数据),RoentGen 仅提升至 78.5%。在外部 VinDr‑CXR 上,平均 AUC 从 70.8% 提升至 73.4%。
解剖分割:气胸分割阳性 Dice 从 0.34 提升至 0.42(2倍数据),肋骨分割 Dice 从 0.80 提升至 0.83。
异常定位:ChestX‑Det 上 mAP 从 47.9% 提升至 49.0%,mAR50 从 63.2% 提升至 76.4%;Object‑CXR 上 mAP 从 61.0% 提升至 63.6%。
严重程度回归(肺部混浊评分):MAE 从 0.65 降至 0.58,MSE 从 0.71 降至 0.63,Pearson 相关从 0.72 升至 0.78。
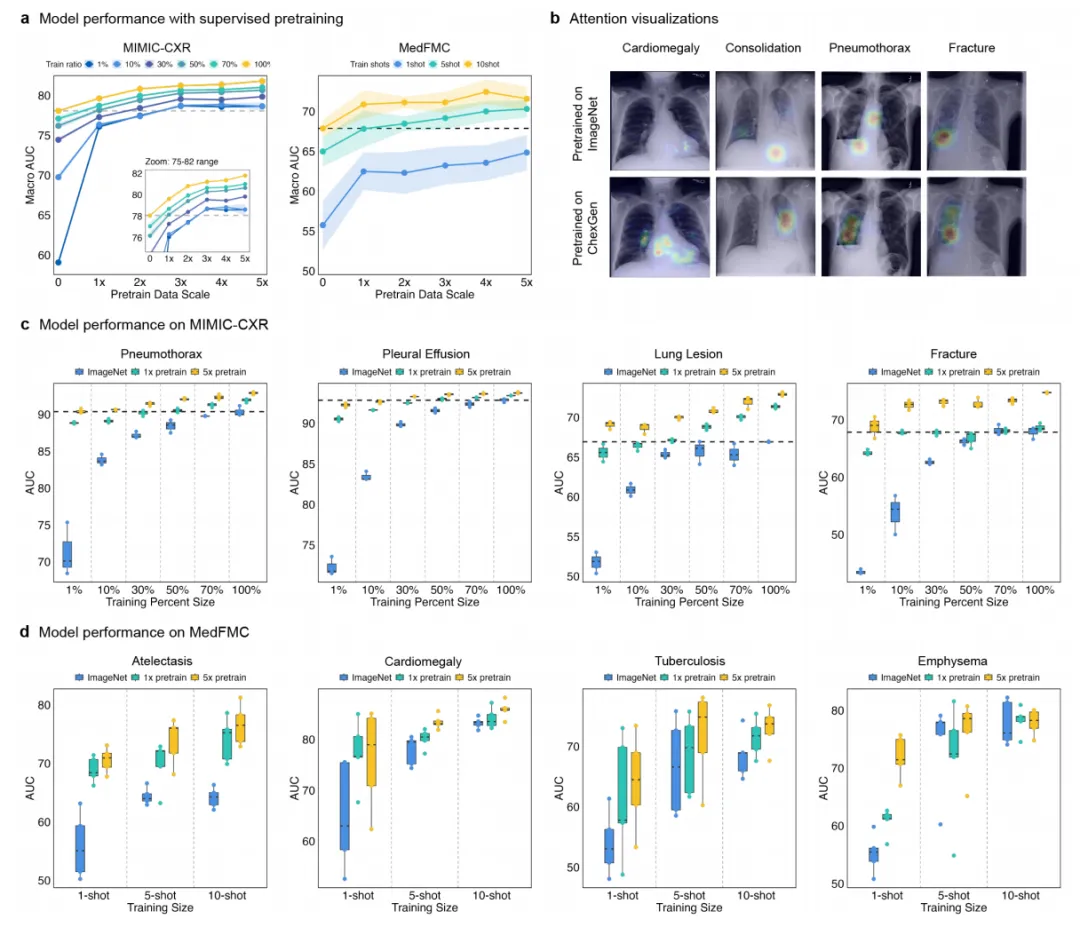
3. 有监督预训练(数据高效学习)
MIMIC‑CXR:仅使用 1% 真实数据微调时,ChexGen 预训练(5倍合成数据)获得 macro AUC 78.6%,超过 ImageNet 预训练用 100% 真实数据的 78.1%。
少样本学习(MedFMC):1‑shot 场景下 macro AUC 从 ImageNet 预训练的 55.7% 提升至 64.8%(5倍合成数据);10‑shot 下从 67.8% 提升至 71.6%。
注意力可视化:Grad‑CAM 显示 ChexGen 预训练模型关注区域更精准地集中在疾病相关解剖位置,而 ImageNet 预训练模型关注范围弥散。
4. 模型偏差检测与缓解
偏差检测:ChexGen 生成的合成测试集与真实测试集在各人口学亚组(性别、种族、年龄及组合)上的性能高度相关(r 最高达 1.0),表明合成数据可可靠反映真实数据中的偏差模式。
偏差缓解:使用 ChexGen 对代表性不足的亚组(如黑人、高龄人群)生成额外训练样本至群体平衡后,最差亚组的 F1 分数显著提升(性别:0.338→0.387;种族:0.321→0.394;年龄:0.363→0.419),最佳与最差亚组的性能差距相对减少高达 60%。
定量指标:ChexGen 在 Fréchet Inception Distance(FID)上显著优于对比模型(CLIP特征:0.89 vs. RoentGen 4.42 和 MINIM-CXR 9.63;胸部X光专用特征:0.57 vs. 6.80 和 8.29)。
多样性:平均成对结构相似性(SSIM)为 0.41,低于 RoentGen(0.46)和 MINIM-CXR(0.57),表明生成图像更多样。
事实正确性:生成图像与真实图像在疾病预测分数上的 Pearson 相关系数为 0.59,高于 RoentGen(0.45)和 MINIM-CXR(0.21)。
特征空间分布:t‑SNE 可视化显示 ChexGen 生成图像与真实图像分布高度一致,优于 RoentGen。
放射科医师盲评:两名医师对 ChexGen 的评分分别为 1.41±1.01 和 0.49±0.70,显著高于 RoentGen(0.73±1.31 和 ‑0.14±1.01,p<0.001)。
疾病分类(MIMIC‑CXR 14类):平均 AUC 从基线 78.0% 提升至 80.1%(2倍合成数据),RoentGen 仅提升至 78.5%。在外部 VinDr‑CXR 上,平均 AUC 从 70.8% 提升至 73.4%。
解剖分割:气胸分割阳性 Dice 从 0.34 提升至 0.42(2倍数据),肋骨分割 Dice 从 0.80 提升至 0.83。
异常定位:ChestX‑Det 上 mAP 从 47.9% 提升至 49.0%,mAR50 从 63.2% 提升至 76.4%;Object‑CXR 上 mAP 从 61.0% 提升至 63.6%。
严重程度回归(肺部混浊评分):MAE 从 0.65 降至 0.58,MSE 从 0.71 降至 0.63,Pearson 相关从 0.72 升至 0.78。
MIMIC‑CXR:仅使用 1% 真实数据微调时,ChexGen 预训练(5倍合成数据)获得 macro AUC 78.6%,超过 ImageNet 预训练用 100% 真实数据的 78.1%。
少样本学习(MedFMC):1‑shot 场景下 macro AUC 从 ImageNet 预训练的 55.7% 提升至 64.8%(5倍合成数据);10‑shot 下从 67.8% 提升至 71.6%。
注意力可视化:Grad‑CAM 显示 ChexGen 预训练模型关注区域更精准地集中在疾病相关解剖位置,而 ImageNet 预训练模型关注范围弥散。
偏差检测:ChexGen 生成的合成测试集与真实测试集在各人口学亚组(性别、种族、年龄及组合)上的性能高度相关(r 最高达 1.0),表明合成数据可可靠反映真实数据中的偏差模式。
偏差缓解:使用 ChexGen 对代表性不足的亚组(如黑人、高龄人群)生成额外训练样本至群体平衡后,最差亚组的 F1 分数显著提升(性别:0.338→0.387;种族:0.321→0.394;年龄:0.363→0.419),最佳与最差亚组的性能差距相对减少高达 60%。


ChexGen 能够生成高质量、多样且临床真实的胸部X光图像,在定量指标和放射科医师评估上均显著优于现有模型(如RoentGen和MINIM-CXR)。该模型支持文本、分割掩码和边界框三种条件的精确引导,实现了空间可控的医学图像合成。
ChexGen 生成的合成数据在多个下游任务中具有实用价值:用于数据增强可提升疾病分类、分割、检测和严重程度回归的性能;用于有监督预训练可大幅降低对真实标注数据的需求(仅用1%真实数据即可达到全量数据训练效果);用于模型评估能有效检测并缓解人口统计学偏差,提高算法的公平性。
感谢您的阅读,如果您对这项研究感兴趣或想了解更多关于AI在医学中的应用,请继续关注我们,我们会定期分享最新的科研成果和健康资讯。别忘了点赞和转发哦!👍🔄

编辑:小黄 审稿:大壮
注:本文仅用于分享相关学术论文研究,如存在侵权,请告知,及时删

往期推文
Science Robotics IF=27.5 | 机器人辅助疗法治疗自闭症谱系障碍的疗效与实效性研究:从实验室到实际应用
Science Robotics IF=27.5 | 基于深度学习的离体猪眼视网膜静脉自主插管术
IF=3.9 Sci Rep 单核细胞与淋巴细胞比值与需入住ICU的急性胰腺炎患者死亡率的相关性:一项基于机器学习的回顾性队列研究与预测模型建立
顶刊Science IF=45.8 | 肥厚型心肌病三维微结构重构的深度学习分析
Commun Med IF=6.3 | 腹部磁共振成像的心血管测量数据揭示腹部血管的遗传结构
Cell Reports Medicine IF=10.6 | 模型对抗与协作:一种提升大型语言模型医疗推理能力的辩论智能框架
