 夜雨聆风
夜雨聆风Agent 从 Demo 到生产,隔着一道「无状态断崖」
你用 Agent 处理 10 份文件,跑得飞快,Demo 效果完美。
然后你让它处理 2000 份。跑到第 1501 份,网络抖了一下,Agent 挂了。
怎么办?重新跑。从第 1 份开始。
Turing Post 最新长文开头直指了这个问题——
"Most agent architectures are secretly stateless."
「大多数 Agent 架构,本质上是无状态的。」

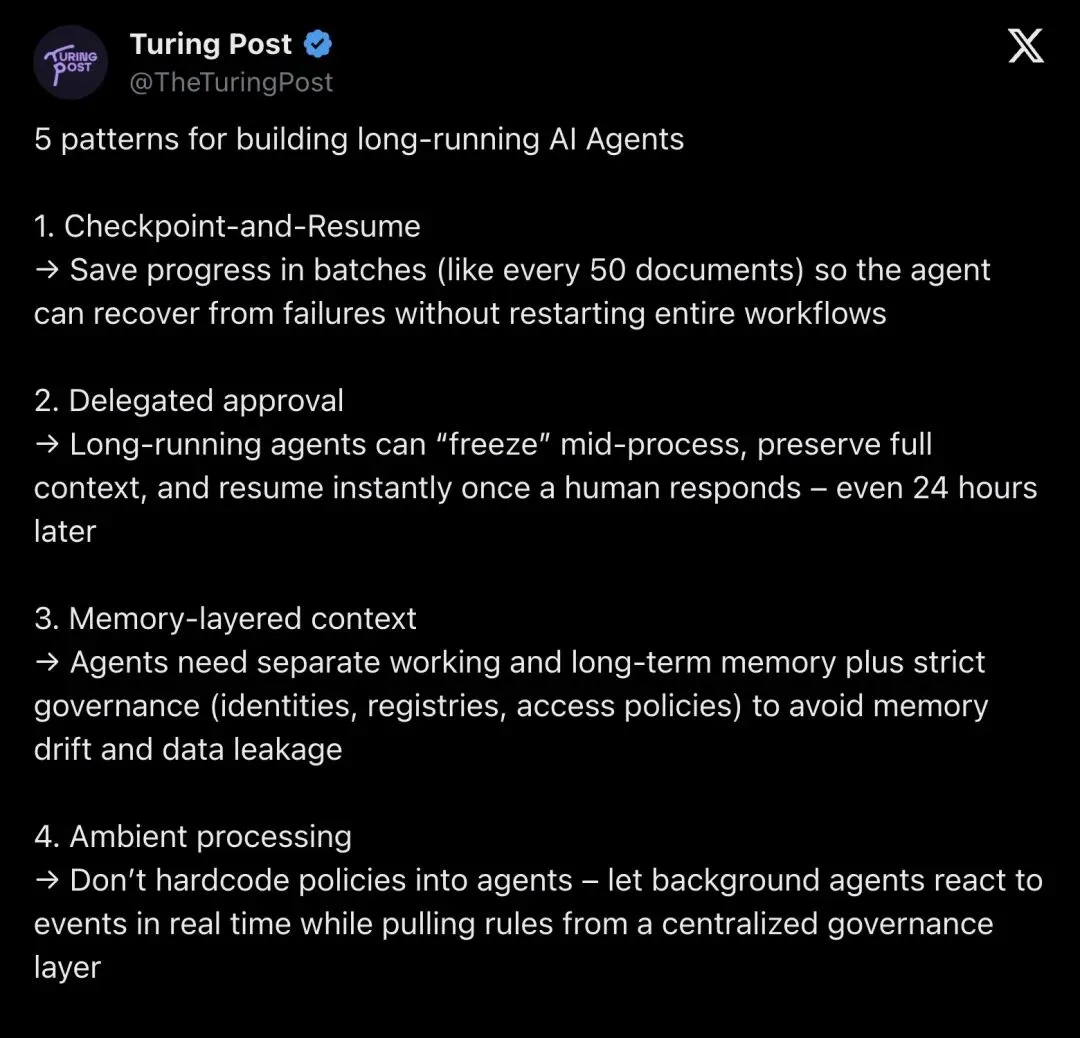
▲ Turing Post 长文首屏——标题直接点明「生产断层」:五种构建长运行 AI Agent 的模式
这篇文章由 Google Cloud DirectorAddy Osmani和 Google Cloud Senior AI Product ManagerShubham Saboo联合撰写。两人的核心判断:真正重要的业务流程——保险理赔、销售序列、财务对账、内容审核——往往持续数小时甚至数天。
"The workflows that actually matter in production... take days, not seconds."
「生产环境中真正重要的工作流,持续的是天,不是秒。」
然而,大量教程和框架默认每次交互都从零重构上下文。推理链断了,置信梯度丢了,soft signals 没了。这些教程能跑通 Demo,但进不了生产。
五种「保命」模式,一张图看完
Turing Post 在 X 上发的帖子,把这五种模式压缩成一张图:

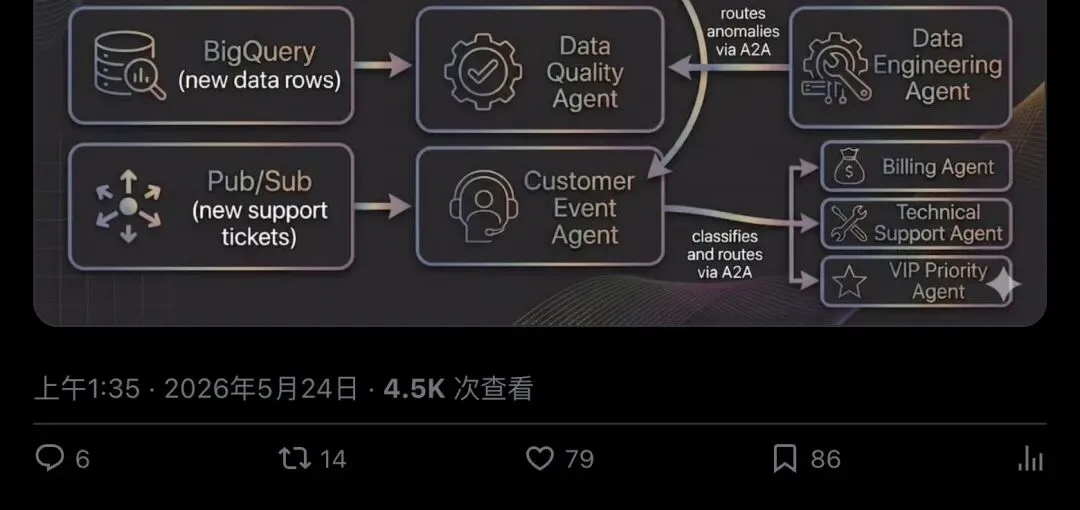
▲ Turing Post 主帖:五种长运行 AI Agent 模式的高密度摘要,附 Ambient Event Mesh 架构图
五种模式分别是:
1.Checkpoint-and-Resume(存档与恢复) 2.Delegated Approval(委托批准) 3.Memory-Layered Context(分层记忆上下文) 4.Ambient Processing(后台事件处理) 5.Fleet Orchestration(多 Agent 编排)
看上去像最佳实践清单?其实每一个都对应着生产环境里的一个致命问题。下面逐个拆。
模式一:Checkpoint-and-Resume —— Agent 也需要「存档读档」
你打游戏知道存档。数据管道工程师知道 checkpoint。但大多数 Agent 框架,到今天还没把这件事当回事。
Checkpoint-and-Resume 的逻辑:按批次保存进度,失败后从上次存档点继续,不必重跑整个工作流。
比如处理 2000 份文档,每处理完 50 份存一次档。第 1501 份崩了?从第 1451 份的存档点恢复,损失最多 50 份的工作量。
这可不只是 Turing Post 的一个比喻。Google ADK 官方文档已经把 Resume 做成了框架级能力。
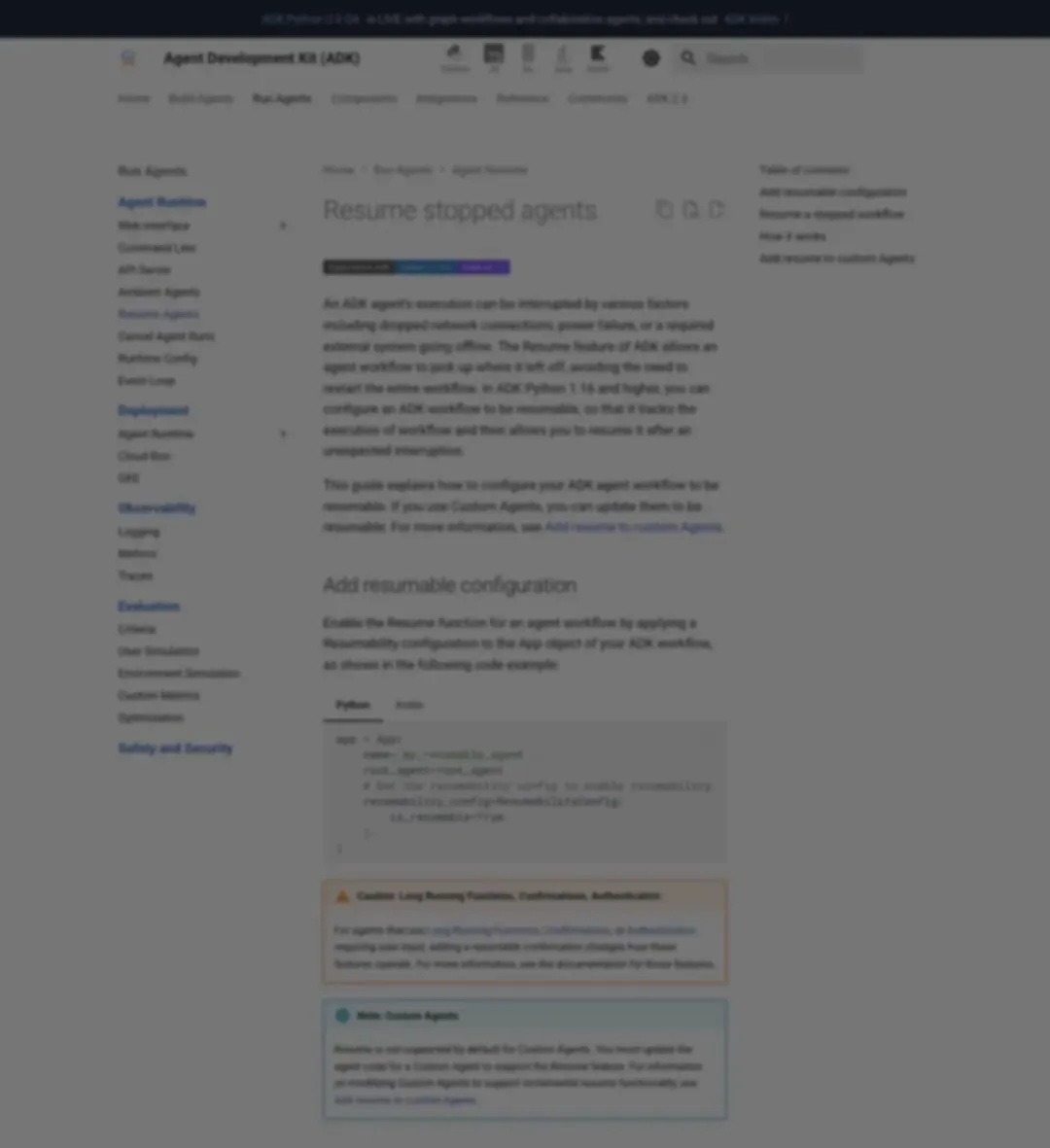
▲ Google ADK Resume Agents 文档:Agent 执行可因网络中断、电源故障、外部系统离线而被打断,Resume 功能允许从中断处继续
ADK 文档的表述毫不含糊:
"The Resume feature of ADK allows an agent workflow to pick up where it left off, avoiding the need to restart the entire workflow."
「ADK 的 Resume 功能允许 Agent 工作流从中断处继续,避免重启整个工作流。」
文档还要求 Custom Agents 必须实现三个关键状态:initial state(初始状态)、每个完成步骤的 state checkpoints(状态检查点)、以及 end_of_agent 标记(结束标记)。
但 checkpoint 的代价不能忽视。社区用户 @CharlieMor6296 指出了一个关键权衡:每 50 项存一次和每个步骤都存一次,是完全不同的策略。粒度越细,I/O 和存储成本越高,但崩溃后损失越小;粒度越粗,成本低但回滚代价大。
还有一个容易忽略的问题:幂等性。你的 Agent 在第 150 步发了一封邮件,崩溃后从第 149 步恢复——它会不会重新发那封邮件?如果会,客户就收到了两封一模一样的通知。Checkpoint 的设计必须考虑重跑产生的副作用。
模式二:Delegated Approval —— 让 Agent 学会「冻结等批准」
想象一个处理保险理赔的 Agent。它跑了三个小时,分析完所有材料,准备批准一笔 50 万的赔付。
这时候你希望它直接打款?还是暂停下来,等人类审核?
Delegated Approval 的核心:长运行 Agent 可以在流程中途「冻结」,保留完整的执行上下文,等人类响应后恢复。哪怕人类 24 小时后才批准,Agent 也能原地解冻继续跑。
Google ADK 的 Action Confirmation 文档把这个能力落到了具体实现:
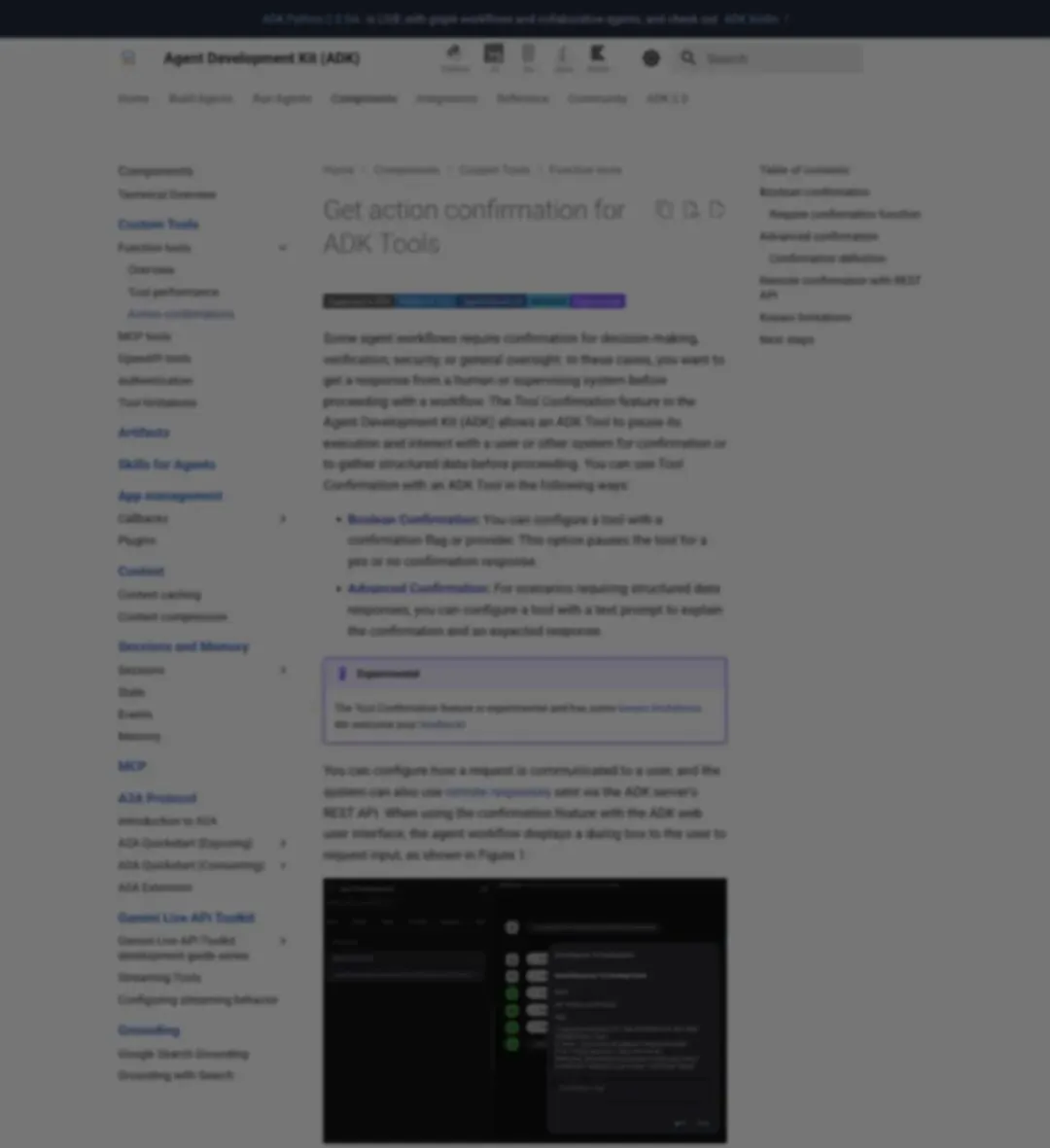
▲ Google ADK Action Confirmations 文档:工具可暂停执行,等待用户或监督系统确认后继续
"Some agent workflows require confirmation for decision making, verification, security, or general oversight."
「部分 Agent 工作流需要在决策、验证、安全或监管环节进行确认。」
ADK 支持两种确认模式:Boolean Confirmation(简单的 yes/no)和Advanced Confirmation(结构化数据输入)。这意味着人类审批者不只是点"同意",还能修改 Agent 提交的参数。
但有一个重要边界:这个功能目前仍标注为 experimental,存在已知限制。它还没有成为开箱即用的完整能力。
社区里 @Timur_Yessenov 和 @BruzWJ 还提出了一个更深层的问题:24 小时后恢复执行,但外部世界已经变了。客户可能撤回了申请、价格波动了、合规规则更新了、库存卖空了。Agent 冻结时记住的上下文,恢复时可能已经过期。所以恢复前,系统必须检测 checkpoint 之后的外部状态变化。
模式三:Memory-Layered Context —— Agent 记得越多,越像一个需要权限管理的企业系统
你的 Agent 跑了一个月,跟 500 个客户交互过。它记住了什么?它该记住什么?它有权记住什么?
Memory-Layered Context 的要求:Agent 需要分层记忆——工作记忆(working memory)、会话记忆(session memory)、长期记忆(long-term memory)——并在每一层加上身份认证、注册表管理和访问策略。
Turing Post 长文特别强调了一个经常被忽视的问题:
"The question to ask yourself isn't just 'what are my agents doing?' It's 'what are my agents remembering, and how is that changing their behavior over time?'"
「除了关注'Agent 在做什么',更要追问:'Agent 记住了什么,这些记忆怎么在改变它的行为?'」
Google Cloud Agent Platform 文档提供了平台级支撑:
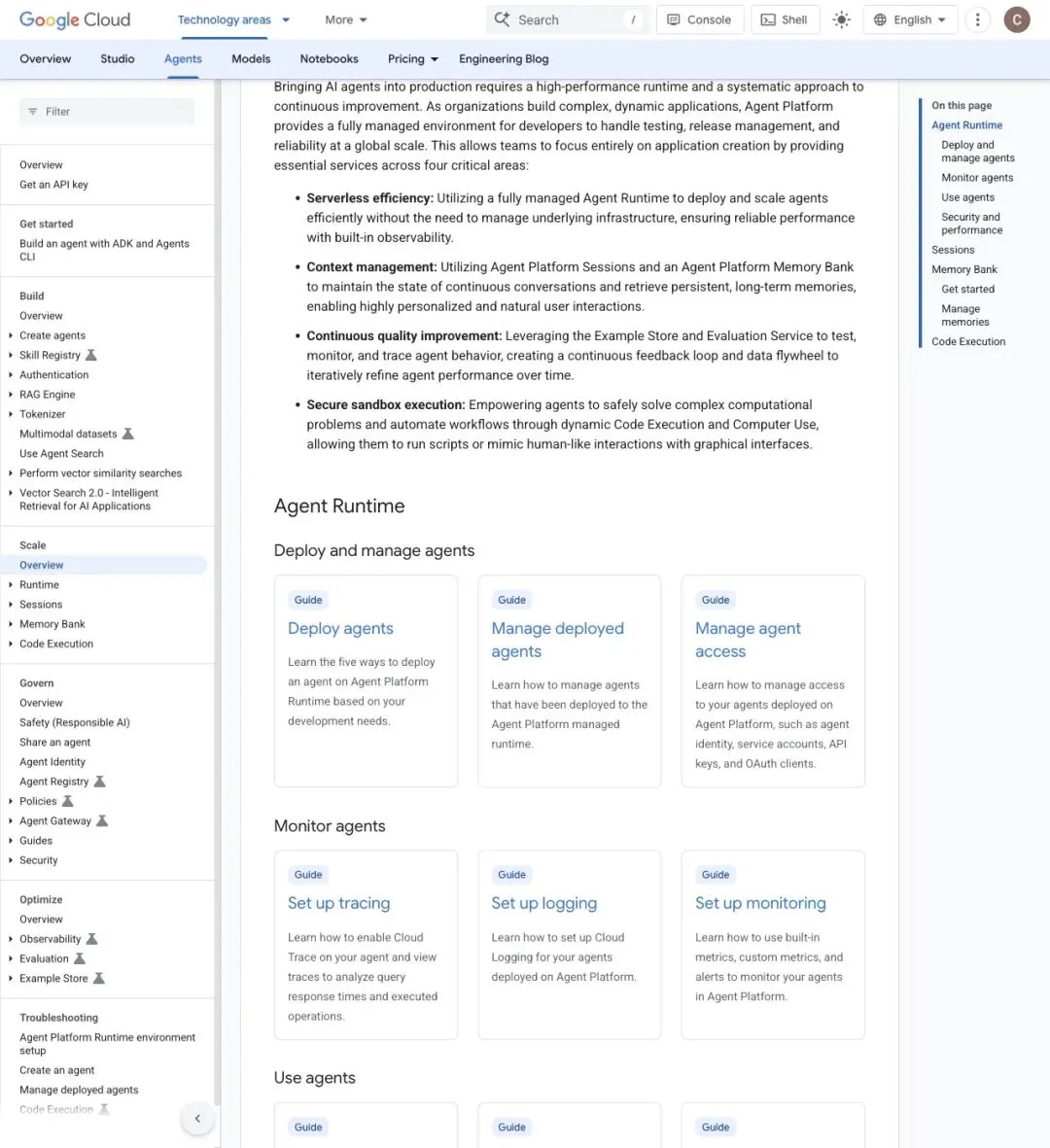
▲ Google Cloud Agent Platform Scale 文档:Sessions 维护会话状态,Memory Bank 存储持久化长期记忆
文档明确列出了Agent Platform Sessions(会话管理)和Memory Bank(记忆库),分别用于维护连续对话的状态和检索持久化的长期记忆。
但长期记忆的隐患同样不能回避:
- PII 泄漏
:Agent 把客户身份证号写进长期记忆,下次交互时作为上下文送回 LLM - 记忆漂移
:Agent 的旧记忆和新事实矛盾,但它默认信任旧记忆 - 权限越界
:A 部门的 Agent 记住了 B 部门的商业机密
所以 Turing Post 长文强调:策略必须在边界处执行(policy enforcement at the boundary),Agent 访问记忆和工具时必须受身份与策略控制。PII 进入长期记忆之前就该被拦住,等事后审计才发现已经来不及了。
模式四:Ambient Processing —— 看着像魔法,拆开全是事件工程
Ambient Processing 听起来很酷:后台 Agent 实时响应事件,自动触发处理流程。
但它有一个容易被忽略的硬约束。
Google ADK Ambient Agents 文档写明:
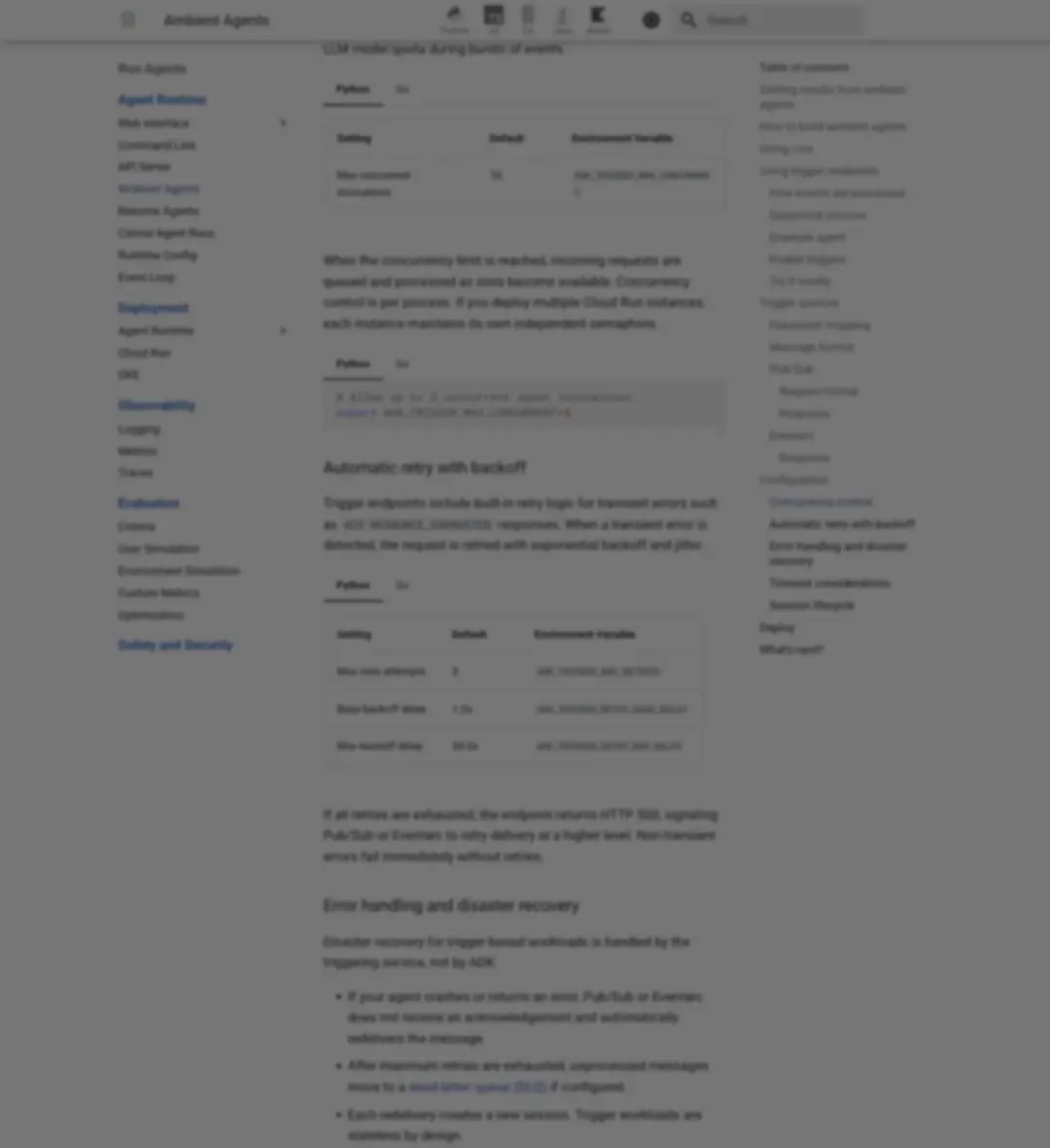
▲ Google ADK Ambient Agents 文档截图
Trigger endpoints 有明确的执行时长上限。超过这个阈值的长任务,官方建议切换到 Pub/Sub pull subscriptions、Cloud Run Jobs 或 worker pool architecture。
还有一个关键细节:默认的 trigger sessions 是 per-event ephemeral(每个事件独立、用完即弃)的。只有配置了 persistent SessionService,才会自动保存会话状态,用于审计、调试和事故分析。
Turing Post 在回复社区提问时也澄清了 ambient event mesh 的定义:它既包括底层的 Pub/Sub、streams、queues、event bus,也包括 Agent 在运行时做 routing 和 execution decisions 的决策层。
Ambient Processing 要落地,需要事件源、消息队列、重试机制、超时控制、session 持久化、可观测性和灾备设计。后台 Agent 越"无人值守",治理层越不能写死在 prompt 里——策略需要从集中治理层动态拉取。
模式五:Fleet Orchestration —— 一个 Agent 扛不住,就上舰队
当单个 Agent 承担的任务越来越复杂,一个必然的结果是:它会变得又大又脆,任何一个环节出错就整体崩溃。
Fleet Orchestration 的解法:用一个 coordinator(协调者)编排多个 specialist agents(专业 Agent),让每个组件独立运行、独立扩缩、独立演进。
Turing Post 主帖对这个模式的描述:
"Use a coordinator to orchestrate specialist agents, allowing components to run, scale and evolve independently. This prevents failures in one agent from cascading to others."
「使用协调者编排专业 Agent,让各组件独立运行、扩缩和演进。这能防止一个 Agent 的故障级联到其他 Agent。」
这和微服务架构的思路高度一致:每个 Agent 有明确的职责边界、独立的工具权限、独立的失败域。coordinator 负责任务分发、状态同步和结果聚合。
但 Fleet Orchestration 绝非"多开几个 Agent"那么简单。它需要:
- Handoff protocol
:Agent 之间传递任务时,上下文怎么交接?哪些信息该传、哪些不该传? - Agent identity 与 registry
:每个 Agent 的能力、权限、版本都需要注册和管理 - A2A/MCP 互操作
:不同框架、不同厂商的 Agent 如何协同? - 故障隔离
:一个 specialist agent 超时了,coordinator 是等、是重试、还是跳过? - 可观测性
:20 个 Agent 同时在跑,怎么知道瓶颈在哪?
跨框架共识:Checkpoint + Interrupt + Resume 已经成为基础设施
如果你觉得这五种模式只是 Google 的一家之言,LangGraph 的文档会打消这个疑虑。
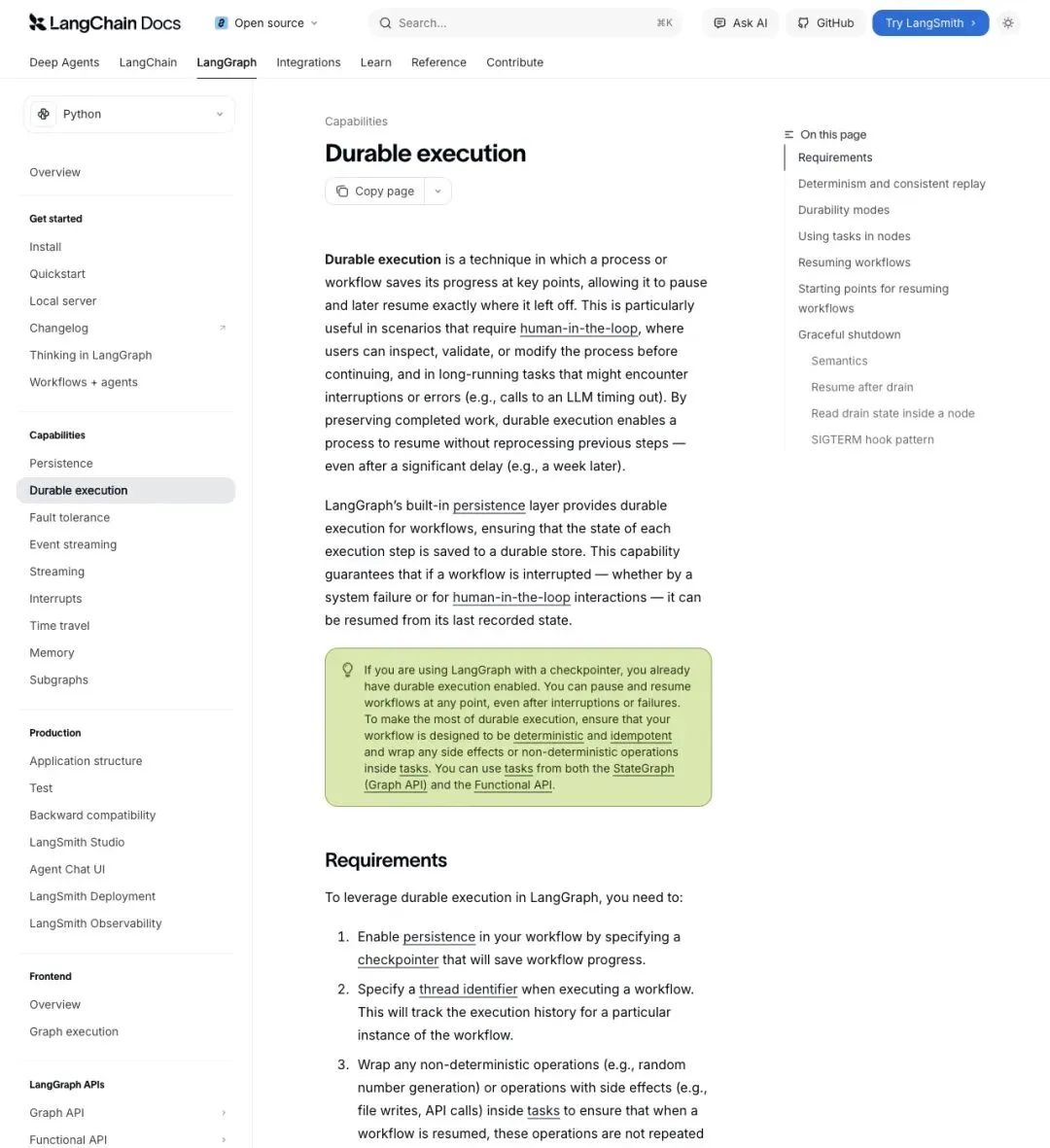
▲ LangGraph Durable execution 文档:workflow 在关键点保存进度,暂停后可从原处恢复,哪怕间隔一周
LangGraph 对 durable execution 的定义:
"Durable execution is a technique in which a process or workflow saves its progress at key points, allowing it to pause and later resume exactly where it left off."
「持久化执行是一种技术:流程或工作流在关键点保存进度,允许暂停并在稍后从完全相同的位置恢复。」
LangGraph 文档还特别指出,这对human-in-the-loop(人类在环)、长运行任务、LLM 超时等中断场景尤为重要;保存已完成的工作后,流程可以在"significant delay(例如一周后)"恢复,无需重新处理此前的步骤。
LangGraph 的 persistence 层支持 checkpointers,具备 human-in-the-loop、conversation memory、time travel debugging(时间旅行调试)和 fault-tolerant execution(容错执行)能力。Interrupts 机制提供 approve/reject、review/edit state、tool interrupts 等模式。
thread_id、checkpoint、interrupt、Command(resume=...)、state snapshot——这些具体的工程接口,正在跨框架成为 Agent runtime 的基础设施共识。
回到核心问题:你的 Agent 准备好「活过一天」了吗?
Turing Post 长文提到,在 Google Cloud Next '26 上宣布 Agent Runtime 支持最多7 天的状态保持。需要说明的是,这个说法目前只在 Turing Post 和作者文本中可以核验到,Google 官方文档中尚未找到完全对应的表述。
但方向已经摆在那里了。
两位作者在文章中写道:
"The same way you'd build a data pipeline that processes millions of records — checkpoint progress, handle partial failures, ensure idempotency."
「就像你构建一个处理数百万条记录的数据管道一样——保存检查点进度、处理部分失败、确保幂等性。」
生产级 Agent 运行时的工程难度,和数据管道、分布式系统、工作流引擎是同一个量级。Checkpoint 像事务日志,Approval gate 像人工审批节点,Memory layer 像带权限控制的存储系统,Ambient processing 像消息队列加事件总线,Fleet orchestration 像微服务编排。
Agent 走向生产的标志:整个运行时可以被暂停、恢复、审计、批准、重试、升级和撤销。
当你的 Agent 能被「存档读档」的那一天,它才真正进入了生产环境。
— END —
