 夜雨聆风
夜雨聆风上周谷歌威胁情报小组发了份报告,首次确认有攻击者用AI生成了零日漏洞利用代码,还拿去实战了。这段代码针对一款流行的开源Web管理工具,绕过了双因素认证。

这事在安全圈炸了锅,各种分析满天飞。但我不想再写一篇安全视角的解读,网上已经够多了。我想说另一个角度——AI在加速信息生产这件事,对搞科研情报搜集的人到底意味着什么。
先理一下这个事
5月11日谷歌GTIG的报告,核心信息就几条:
攻击者用AI生成了一段Python零日漏洞利用代码,代码结构非常"教科书式",带着教学性质的文档字符串,甚至编了一个CVSS评分。 漏洞本身是高层语义逻辑缺陷——不是那种模糊测试跑出来的内存问题,而是AI擅长发现的那种"逻辑上的不合理"。 多个APT组织(APT27、APT45等)已经在批量用AI辅助做漏洞发现和利用开发。 俄罗斯那边用AI语音克隆冒充记者做虚假视频。
你看,这里有个共同点:AI正在让"生产看起来专业的内容"这件事变得非常便宜。 不管是漏洞代码、分析报告还是新闻视频。

这才是科研情报搜集者该担心的
我做开源信息采集做了十来年,服务的主要是科研院所、军工单位、高校这些客户。他们日常干的事情是:从国内外政府机构官网、实验室网站、大学发布平台、企业公告、法律法规数据库、论文库、行业媒体这些地方搜集信息,然后整理、分析、写报告。
这些工作有一个隐含前提——你采集到的信息,大部分是"真人写的、机构发的",可信度有基本保障。
但AI正在动摇这个前提。

第一,专业信息的"伪造门槛"在急速降低。
以前你能相信一篇IEEE论文、一份兰德智库报告、一个政府机构公告,是因为这些东西的生产成本很高——需要专业知识、需要时间、需要机构背书。但AI已经能生成看起来非常专业的技术分析了,带数据、带引用、带逻辑推导,外行人根本看不出问题。
我前几天翻某个领域的研究动态,看到一篇英文的技术分析文章,写得有板有眼,引用了三篇论文,还有数据图表。仔细一查,那三篇论文一篇不存在,两篇跟结论没太大关系。整篇文章大概率是AI生成的,但发布在一个看起来挺正规的行业博客上。
这种事以后只会越来越多。对我们搞采集的人来说,以前"采集到"约等于"可信",现在不行了。
第二,信息量在膨胀,但你真正需要的信息并没有变多。
AI不只是生成假信息,它也在大量生成"看起来有用但其实没新意"的内容。很多行业媒体、研究机构的官方账号,现在都在用AI辅助生成日常动态、简报、周报。这些内容不是假的,但属于"稀释型信息"——把已有信息换了个说法重新包装一遍,没有新增任何洞察。
打个比方,以前你采集某个技术领域,一天能采集到30篇有价值的信息,现在一天可能采集到300篇,但真正有新意的可能还是30篇甚至更少。你的筛选成本在暴增。
我们有个客户是做航空领域的,之前他们研究员每天花两个小时看采集回来的信息就够了,现在信息量翻了好几倍,但说"有用的反而更难找"。
第三,多语种信息的验证难度在加大。
这个我们感触特别深。很多科研单位需要跟踪境外信息——俄罗斯的实验室动态、日本的产业政策、德国的研究机构发布。以前多语种信息至少有个"语言壁垒"在那里,你能采集到,但得靠翻译和分析人员来判断内容。
现在大模型翻译质量上来了,采集系统能自动翻译几十种语言,这在效率上是好事。但问题是:你翻译过来之后,对一个你完全不熟悉的语言环境的原始信息,怎么验证它是不是靠谱?一个俄文的"技术简报",翻译成中文之后看着挺专业,但你怎么知道它是不是某个俄罗斯自媒体用AI生成的?
语言障碍消除了,但验证障碍还在。
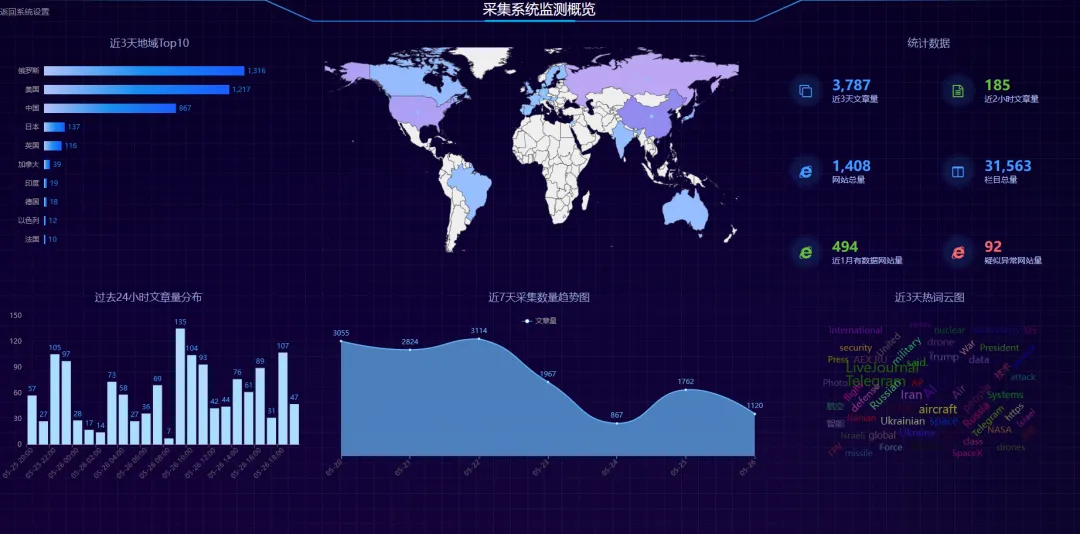
怎么应对?说几个实际的,也是我们每天在做的事。几点经验:
坚持"认机构不认内容"。
一条信息可不可信,最简单的办法是看它从哪来的。政府机构官网发的公告、大学实验室发布的研究成果、国际组织的技术白皮书——这些"机构发布"的信息,因为发布者有声誉风险,可信度天然更高。
反过来,行业博客、自媒体号、某些看起来专业但机构背景不明的网站,信息质量就参差不齐。不是说这些渠道没有好内容,而是需要更多交叉验证。
我们给客户配置采集源的时候,第一优先级永远是官方发布渠道——.gov、.edu、机构官网、正规期刊库。这些是"锚点",其他渠道的信息用来补充和验证。
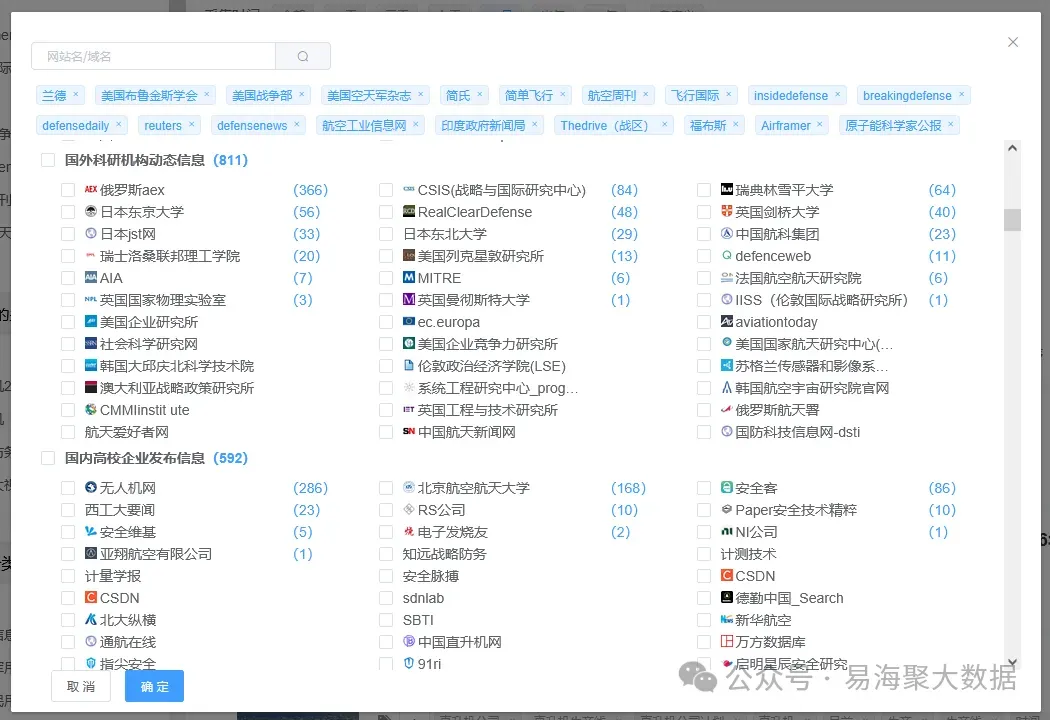
给信息源建档案,而不是简单堆链接。
很多人做信息搜集就是存一批网址,定期去看。这不够。你需要对你用的每个信息源有个基本判断:这个网站是谁运营的?更新频率?历史上有没有发布过不实信息?被引用的情况怎么样?
比如我们做军工领域采集的时候,对每个核心网站都有记录——这个网站是哪个机构的、采集稳定性怎么样、信息质量如何。如果一个网站连续两周采集不到新内容,要么是网站结构变了,要么是它本身就不活跃了,需要及时处理。
这个工作很枯燥,但没有捷径。信息源的质量决定了后面所有工作的上限。
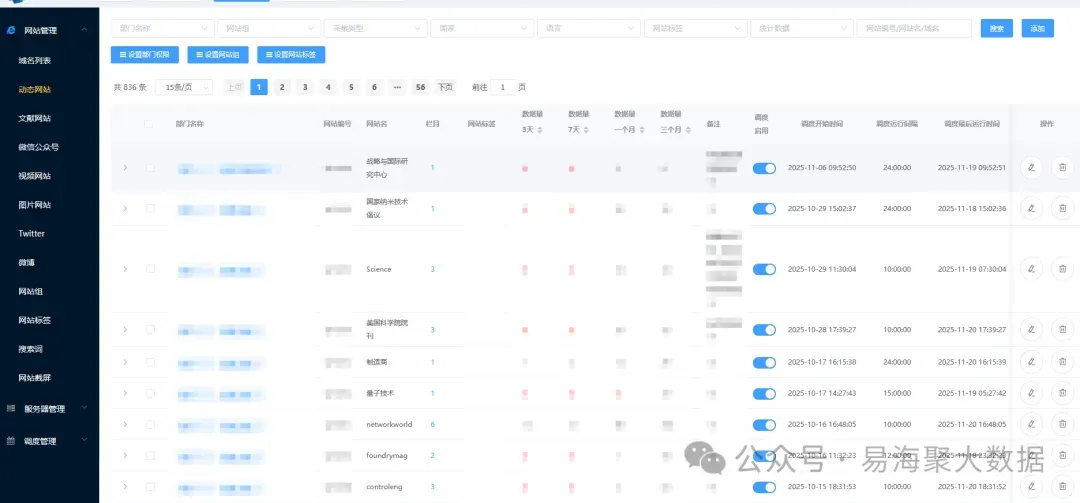
善用交叉验证,特别是跨语言的。
一个技术动态,如果同时被英文源和俄文源报道,且内容可以互相印证,那可信度就高不少。如果某个消息只在单一语言环境出现,其他语言环境完全没有相关报道,那就要小心了。
比如之前有个关于某国高超音速武器的"技术突破",只在某几个俄文小众网站上报道,英文主流媒体和学术圈没有任何讨论。后来证实那个"突破"是被夸大的。
跨语言交叉验证的前提是你得有足够多的多语种信源。这一块我们积累了不少,境外各类专业网站的配置和维护是持续在做的事情。
对AI生成的内容保持警觉,但不必恐慌。
AI生成的信息有几个常见特征:结构完美、不会有错词语法问题等、缺乏具体细节、引用文献查不到、观点过于平衡中立(没有明显立场)等等。但这也不是绝对的,随着技术发展以后AI肯定会越来越会"伪装"。
所以核心还是回到上面说的——信源优先。只要信息来自可信的机构渠道,内容是不是AI辅助生成的其实没那么重要。关键是不要被"看起来专业但来源不明"的东西蒙了。

最后说两句
AI生成零日漏洞这事,本质上是AI降低"专业内容生产门槛"的一个极端案例。在安全领域,它降低了攻击门槛;在科研情报领域,它降低了"伪造专业信息"的门槛。
但反过来说,AI也在降低"验证信息"的门槛——自动翻译、智能摘要、实体抽取、关系提取等这些能力,让我们能更快地处理和交叉验证信息。工具是中性的,关键看怎么用。
做了这么多年采集,我们最大的经验就一条:信源是根基,验证是底线,效率是锦上添花。 没有好的信源和严谨的验证,再先进的工具也白搭。这也是我们一直坚持维护数万个经过验证的专业信息源的原因,这个活虽然笨,但省不了。
更多热门阅读
【开源情报系统介绍】开源情报搜集系统:科研创新的强大引擎
【情报系统应用案例】案例视角下的开源情报搜集系统应用实践
【大模型的应用】大模型在开源情报搜集系统中的应用汇总
【情报系统构建】不止于“爬”:如何构建真正可靠的情报采集系统
—————————————————————
易海聚:信息搜集,信息整合,信息分析!

业务咨询、技术交流合作请联系:

