 夜雨聆风
夜雨聆风1 前言
Open WebUI(原 Ollama WebUI)是一款开源、可自托管、支持完全离线的大语言模型(LLM)交互 Web 平台,本次主要是通过加入skills搭建专属个人的AI助手
2 搭建过程
(1)启动服务
上个文章中有介绍了如何搭建open-webui,这里就直接启动服务,启动open-webui命令如下:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
(2)访问页面
打开open-webui的网址,使用如下网址和端口访问:
http://x.x.x.x:3000/
开始使用
(3)配置
在登录界面中,点击工作空间
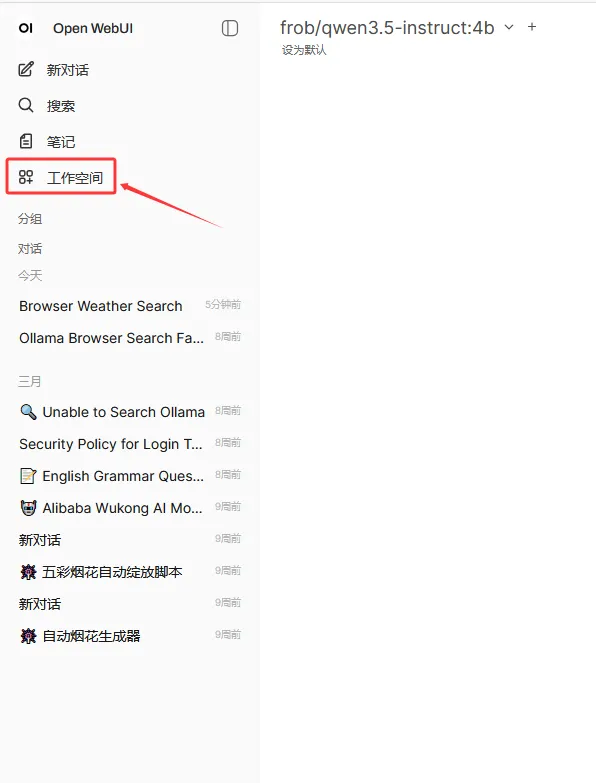
点击工具标签页

点击新建工具

这里面有默认的工具,可以参考这里面的代码
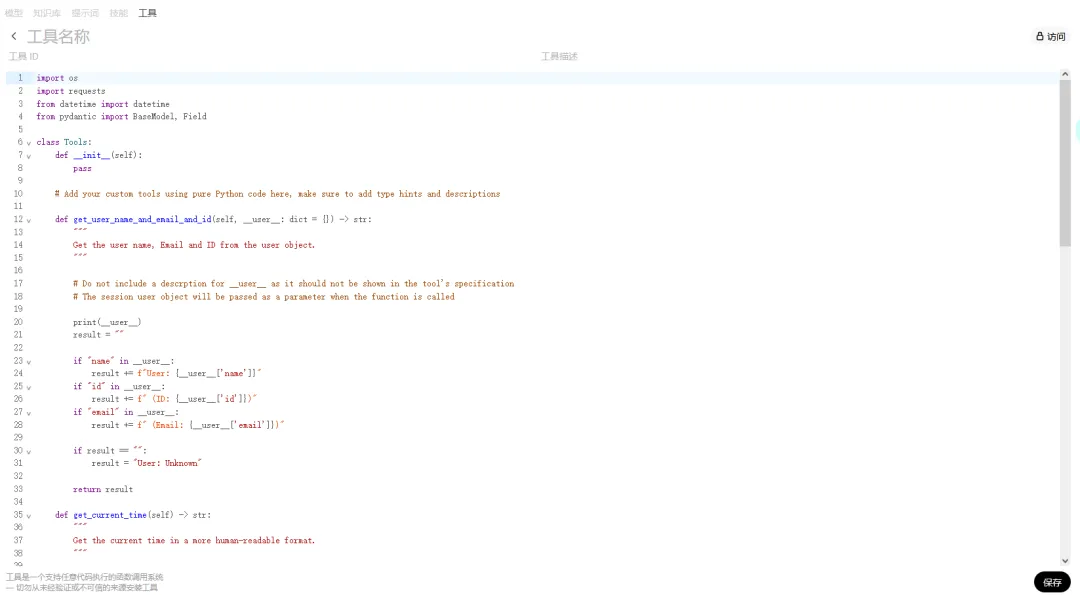
将默认的代码修改成你需要的工具内容
import requestsfrom pydantic import BaseModel, Fieldclass Tools:def __init__(self):passdef automate_browser_on_local_pc(self,instruction: str = Field(..., description="用户自然语言指令,例如:'打开百度,搜索 Ollama'"),) -> str:"""将浏览器自动化任务发送到本地 Windows 电脑执行,这里后面会讲到"""# 👇 替换为你的 Windows 内网 IPLOCAL_AGENT_URL = "http://x.x.x.x:8002/run"try:resp = requests.post(LOCAL_AGENT_URL,json={"instruction": instruction},timeout=120, # 给 Playwright 足够时间)if resp.status_code == 200:result = resp.json()return result.get("message", "任务完成")else:error = resp.json().get("error", "未知错误")return f"❌ 本地代理返回错误: {error}"except requests.RequestException as e:return f"❌ 无法连接到本地 Windows 代理 ({LOCAL_AGENT_URL}): {e}"
(4)配置本地文件
将脚本保存到本地中,并根据实际填写相应的ollama模型ip地址
import sysimport jsonimport refrom flask import Flask, request, jsonifyfrom playwright.sync_api import sync_playwrightimport threadingimport timeapp = Flask(__name__)_BROWSER = Nonedef get_browser():global _BROWSERif _BROWSER is None:p = sync_playwright().start()_BROWSER = p.chromium.launch(headless=False,args=["--start-maximized"])return _BROWSERdef execute_action_in_page(action, page):skill = action.get("skill")args = action.get("args", {})# === 字段名兼容处理 ===if skill == "fill_input":# 支持 selector/element, value/textselector = args.get("selector") or args.get("element")value = args.get("value") or args.get("text")if not selector:raise ValueError(f"❌ fill_input 缺少 selector/element: {args}")if value is None:raise ValueError(f"❌ fill_input 缺少 value/text: {args}")# 执行page.fill(selector, str(value))returnelif skill == "click_element":selector = args.get("selector") or args.get("element")if not selector:raise ValueError(f"❌ click_element 缺少 selector/element: {args}")page.click(selector)returnelif skill == "open_url":url = args.get("url") or args.get("href") or args.get("link")if not url:raise ValueError(f"❌ open_url 缺少 url: {args}")if not url.startswith(("http://", "https://")):url = "https://" + urlpage.goto(url)page.wait_for_load_state("networkidle", timeout=30000)returnelif skill == "wait_seconds":seconds = args.get("seconds", 1)page.wait_for_timeout(int(seconds) * 1000)returnelse:raise ValueError(f"❌ 未知操作: {skill}")def extract_actions_from_text(text: str):actions = []try:data = json.loads(text.strip())if isinstance(data, list):return dataexcept:passpattern = r'"skill"\s*:\s*"([^"]+)"[^}]*?"args"\s*:\s*(\{[^}]*\})'matches = re.findall(pattern, text, re.DOTALL)for skill, args_str in matches:try:args = json.loads(args_str)actions.append({"skill": skill, "args": args})except:args = {}for key in ["selector", "value", "url"]:match = re.search(f'"{key}"\\s*:\\s*"([^"]*)"', args_str)if match:args[key] = match.group(1)if args:actions.append({"skill": skill, "args": args})return actions@app.route('/run', methods=['POST'])def run_automation():data = request.jsoninstruction = data.get("instruction", "")# === 调用远程 Ollama 生成操作计划 ===import requestsOLLAMA_SERVER = "http://x.x.x.x:11434" #替换成你的ollama模型的地址MODEL = "frob/qwen3.5-instruct:4b"full_prompt = ("你是一个浏览器自动化助手,必须将用户指令分解为精确的原子操作序列。\n""规则:\n""- 必须使用以下技能: open_url, fill_input, click_element, wait_seconds\n""- 输出必须是纯 JSON 数组,格式: [{\"skill\":\"...\",\"args\":{...}}, ...]\n""- 不要任何解释、注释、Markdown 或额外文本\n"f"用户指令:{instruction}\n输出:")try:resp = requests.post(f"{OLLAMA_SERVER}/api/generate",json={"model": MODEL,"prompt": full_prompt,"format": "json","stream": False,"options": {"temperature": 0.1}},timeout=60)resp.raise_for_status()ai_response = resp.json()["response"]except Exception as e:return jsonify({"error": f"调用 Ollama 失败: {e}"}), 500try:actions = extract_actions_from_text(ai_response)if not actions:return jsonify({"error": f"未提取到操作: {ai_response[:200]}"}), 400with sync_playwright() as p:browser = p.chromium.launch(headless=False,args=["--start-maximized"])page = browser.new_page()try:for act in actions:execute_action_in_page(act, page)message = "✅ 浏览器自动化任务执行成功!"# 👇 在这里加延迟,比如等 5 秒再关闭page.wait_for_timeout(5000) # 5000 毫秒 = 5 秒finally:browser.close() # 确保关闭return jsonify({"status": "success", "message": message})except Exception as e:return jsonify({"error": f"执行失败: {str(e)}"}), 500if __name__ == '__main__':app.run(host='0.0.0.0', port=8002, debug=False)
本地先运行这个代码
python remote_ai_agent.py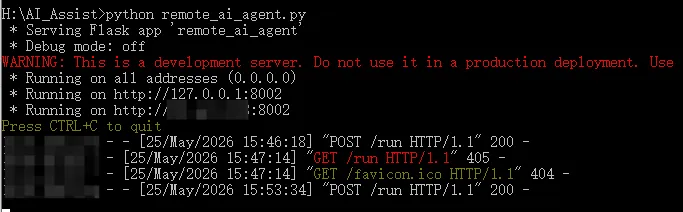
这里可以看到是否运行正常
(5)安装playwright-cli
可以去git上下载playwright-cli插件
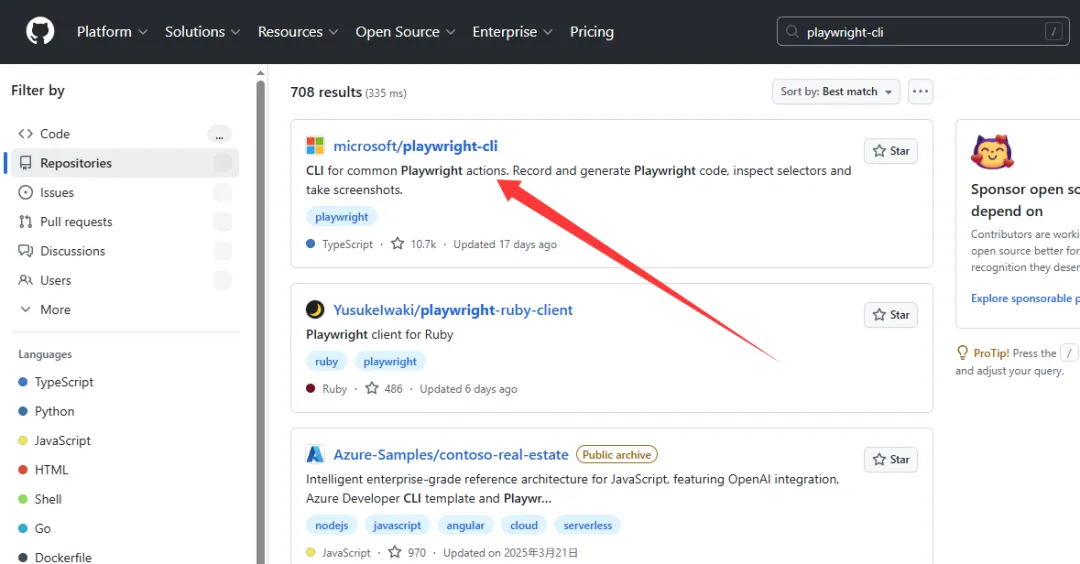
在本地安装好这个插件

(6)开始使用
通过直接输入你想要做的事情
例如:访问百度网址,搜索AI最新资讯注意这里要选择工具,再执行
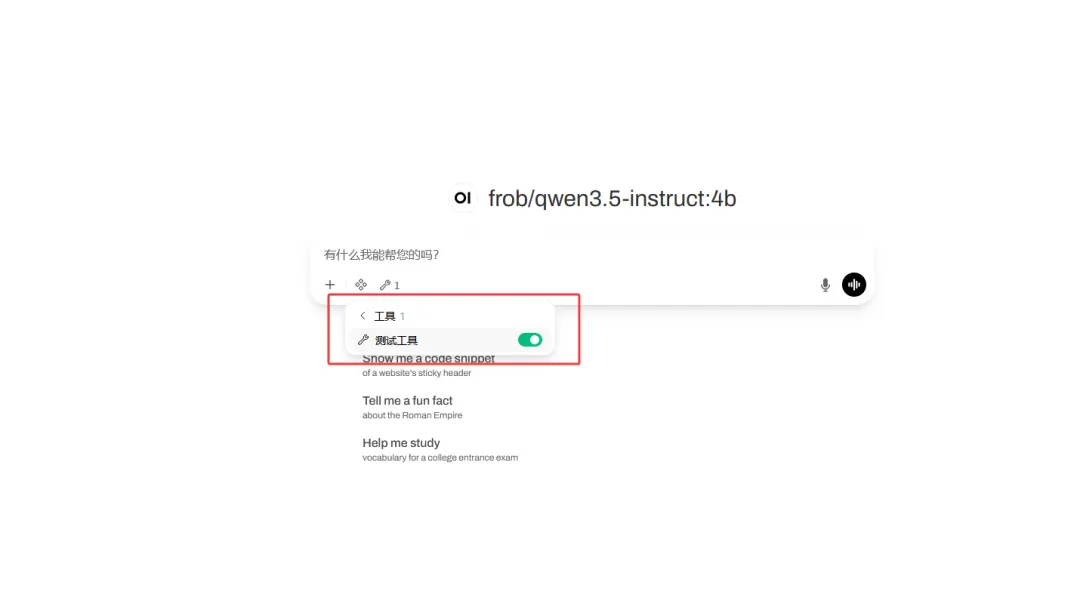
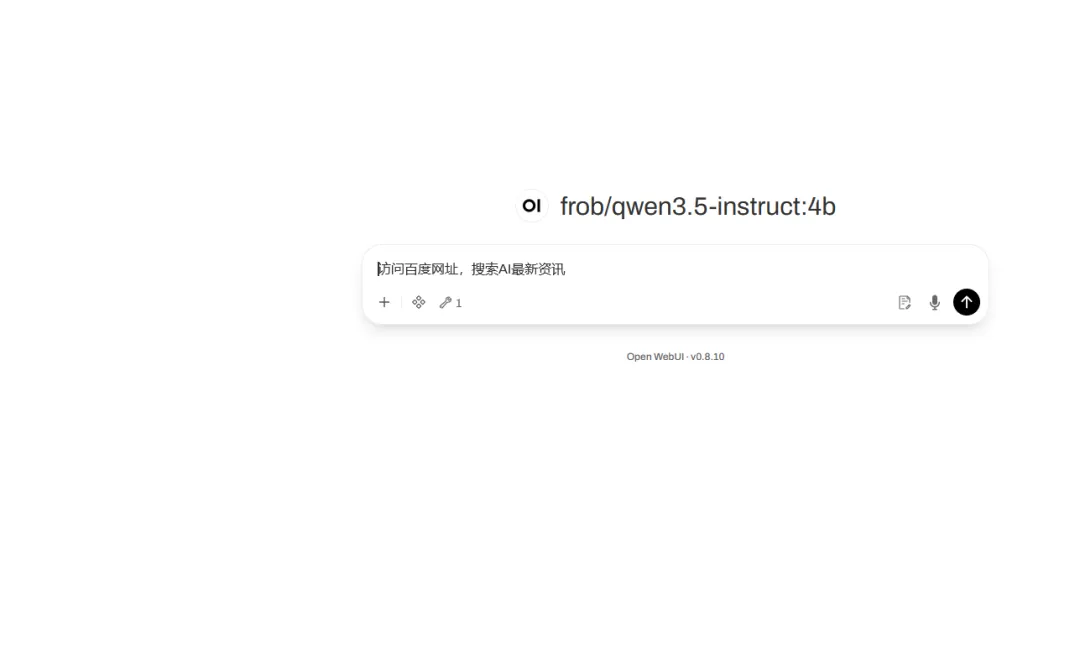
执行完成后,会看到如下执行过程
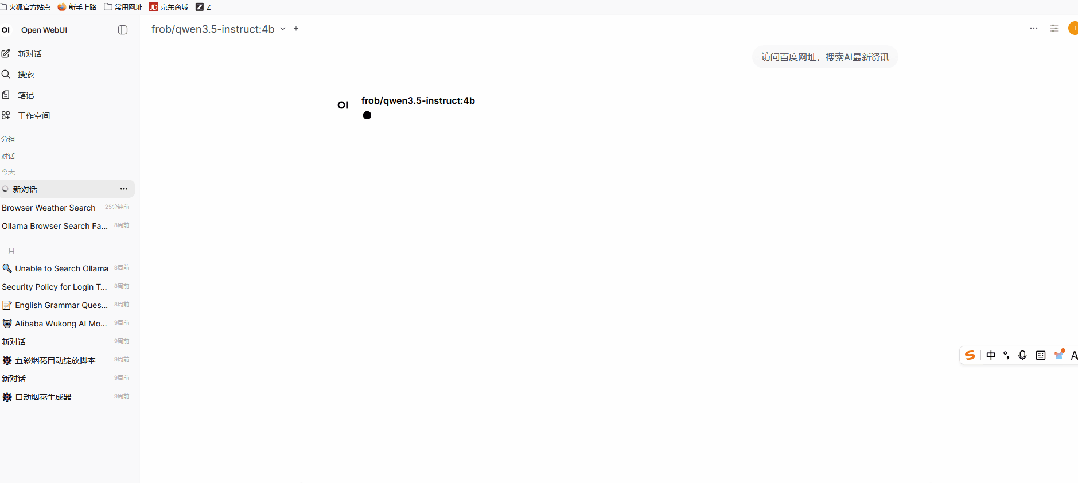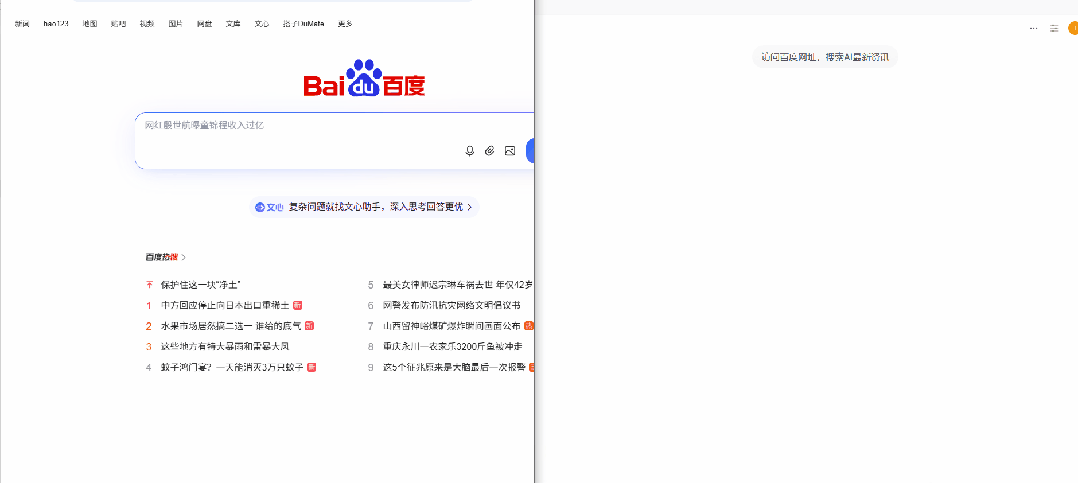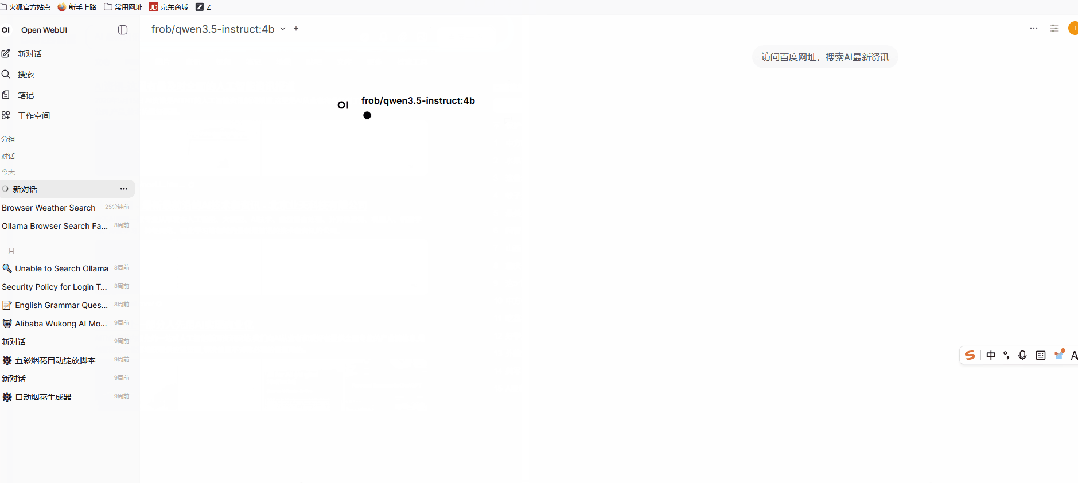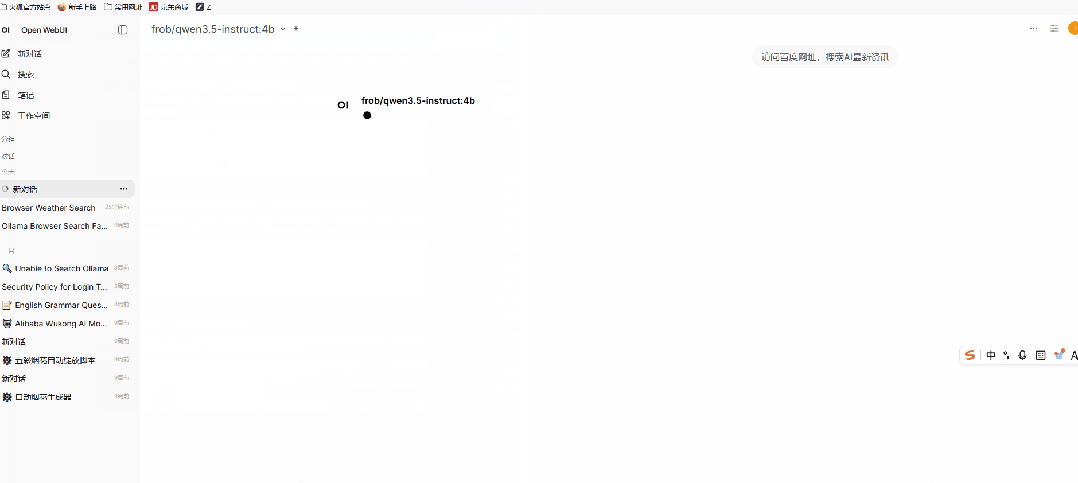
目前只是以打开百度搜索为例,也可以根据自己需要研究其他的skills
欢迎关注「技术分享交流」公众号 ,如果有建议或者疑问的话,欢迎大家评论留言,如果喜欢公众号文章的话可以点【在看】,您的鼓励就是我的动力哈!!!
请在微信客户端打开
