 夜雨聆风
夜雨聆风投稿前,先让AI把你的论文批到60分以下
本文是「ARS学术写作系列」第③篇。前两篇讲了文献研究和写作流水线,这篇讲投稿前最后一道关——用ARS的 academic-paper-reviewer 技能模拟同行评审。
我见过最让人崩溃的一封邮件,是一个公卫领域做慢病管理的同学转发给我的审稿意见截图。
第三条写道:
"The statistical model used is inappropriate for the correlated data structure. The conclusions drawn are not supported by the presented analysis."
她准备了将近半年。数据是真的,是她辖区2018到2023年糖尿病管理登记的实际数据。分析自己跑的,英文找人改了两遍。
然后等了三个月,等来了这一条。
她当时问我:这个意思是说我统计方法用错了?
对。就是这个意思。

审稿人有时候很挑剔,有时候很专业,有时候专门来让你难受。但他们做的事本质上很简单:拿着你的论文,一条一条找问题。
ARS的 academic-paper-reviewer 技能做的,也是这件事——只不过是在你投稿之前做,给你还来得及改的时间。
一、不是帮你夸一遍:5份独立报告,5个不同角度
很多人对AI审稿有一个预期:AI会给你写几条鼓励性反馈,然后说"整体不错,小修一下就可以投了"。
ARS的审稿不是这样工作的。
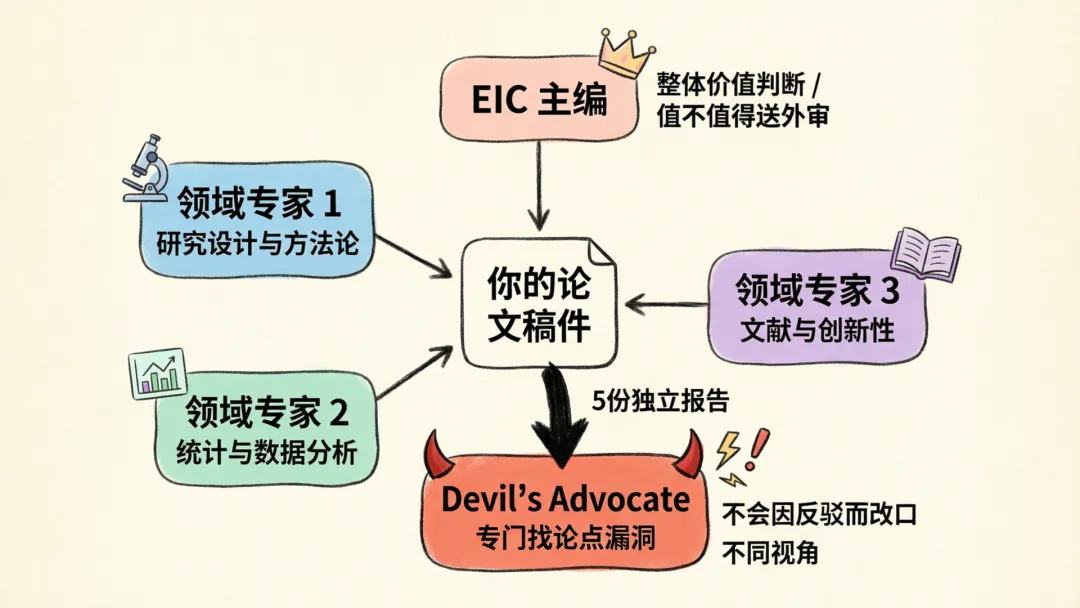
触发 full 模式之后,后台7个Agent协同运行,对外输出5份独立评审报告。每份报告来自不同角色,关注不同维度。
EIC(主编)评估的是整体价值判断:这篇文章有没有期刊发表的价值?方法论框架是否完整?结论有没有超出数据支撑的边界?EIC给的是"值不值得送外审"的判断,也是最接近编辑第一轮筛选时看的东西。
3个动态领域审稿人是根据你论文的实际内容自动选择的。
你写的是流行病学观察研究,审稿人会侧重研究设计和混杂因素控制;你写的是卫生政策评估,审稿人会关注政策可行性和利益相关方分析;你写的是系统综述,审稿人会挑文献检索策略和异质性处理。你不需要告诉它你写的是什么类型,它自己判断。
Devil's Advocate 是整套机制里最特别的角色,单独拎出来讲。
5份报告,意味着同一篇稿子从5个不同角度被看过。这不是同一个AI换几种语气说同一件事,是5份真正独立的评估。
二、Devil's Advocate:那个专门来怼你的AI
Devil's Advocate,字面意思是"魔鬼代言人"。
在学术语境里,这个角色有一个明确的任务:专门找你论点里的漏洞,然后构建最强的反方论证。
不是找错别字,不是挑格式问题。是攻击你的核心论点本身。
举个具体的例子。
你写了一篇关于"家庭医生签约制度降低了基层糖尿病患者住院率"的研究,结论是干预有效。
Devil's Advocate会提这样的问题:
你的对照组怎么选的?签约率高的地区,是不是本来就是健康意识更强的人群?选择偏倚有没有处理? 干预前后住院率的变化,有没有可能是同期医保报销政策调整导致的?你控制了吗? 随访时间够不够?住院率降低是真实的健康改善,还是暂时的就医行为变化?
公卫领域还有几类高频被攻击的角度:
生态学谬误:用群体数据推导个体因果(比如说"高血压患病率高的社区,心血管事件也多",但这不能直接证明个人血压和个体事件之间的因果) 混杂因素遗漏:年龄、性别、社会经济地位这些常见混杂因素,你有没有在多因素模型里控制? 时间依赖偏倚:如果用的是既接受干预又进展更快的患者数据,结论可能完全反过来
这三个问题,真实的审稿人可能提,也可能不提。Devil's Advocate一定提。
让步阈值协定(Concession Threshold Protocol)是这个角色的核心机制。
通俗地说:它不会因为你反驳它就改口。
很多AI工具有一个让人又爱又恨的特点——你说"你理解错了",它立刻回应"哦你说得对,这个问题确实不大,我收回这条批评"。
Devil's Advocate不这样工作。它有一个内置的"让步阈值":你的反驳必须提供具体的方法论依据,达到一定的论证质量,它才接受并调整立场。
你如果只是说"这个问题我在方法部分已经解释过了",它的回应是:具体在哪一段,怎么解释的,解释是否充分?然后继续保持批评。
这很烦,但这是对的。
你的论文投给真实期刊之后,审稿人不会因为你在回复信里多写几行就改变结论。Devil's Advocate在提前训练你面对这种处境的能力——你在这里练过怎么回应,到时候写回复信的时候就不会手足无措。
一个好的导师不会只说"写得不错"。Devil's Advocate是那种导师的AI版。

三、0到100分:你的论文现在在哪个档位
评分不是最终目的,但评分可以告诉你问题有多严重。
ARS使用0-100分的评分体系:
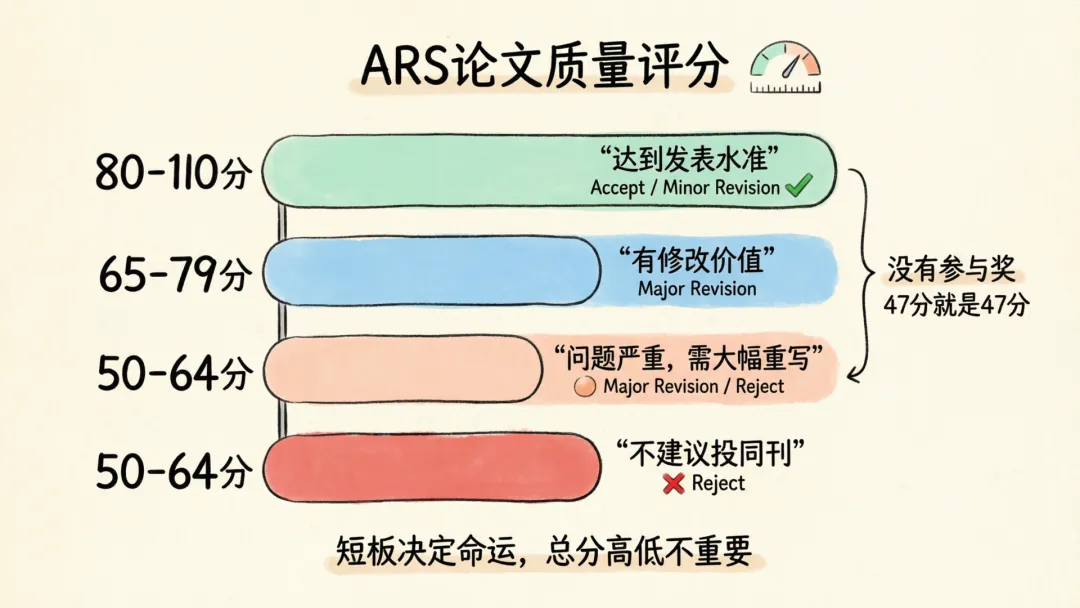
没有参与奖。你的论文如果得了47分,它会告诉你47分。
评分覆盖多个维度:研究设计与方法论、数据与统计、论证逻辑、文献覆盖完整性、写作质量、研究创新性。每个维度单独给分,不只看总分。
评分结果怎么用?
一个关键原则:总分高低不重要,短板决定命运。
比如一篇论文总分68分,看起来还行——但如果方法论维度只有40分,说明统计方法是核心硬伤。这种情况,文献综述写得再好、讨论部分再精彩都没用。真实的审稿人看到方法论问题会直接建议大修或拒稿,不会因为其他部分出色就网开一面。
反过来,有些论文总分不高,但每个维度都均衡地差,没有某一项特别差——这种情况下反而比"总分高但某项瘸腿"的论文更容易通过,因为没有明显的致命伤。
找到得分最低的维度,集中改那里,比均匀地"打磨"全文效率高很多。
四、6种审稿模式,按你现在的情况选
不是所有情况都需要跑完整的 full 模式。根据你现在的实际需求:
full | ||
quick | ||
re-review | ||
methodology-focus | ||
guided | ||
calibration |
calibration 模式比较特殊——它是对审稿工具本身的质量测试,输出误报率(FPR)、漏报率(FNR)和AUC指标。如果你对AI审稿的可信度有疑虑,跑一遍 calibration,看它在已知案例上的判断准确率,然后再决定多大程度上参考它的意见。
触发方式:
帮我对这篇稿件做完整的同行评审,使用 full 模式快速评估一下这篇文章值不值得投这个期刊,用 quick 模式上传格式支持直接粘贴文本、Markdown或Word文档。
五、已经收到真实审稿意见了,怎么用
投出去之后收到审稿意见,不知道怎么处理——这个场景同样可以用ARS。
revision-coach 模式不是帮你改稿,是帮你读懂审稿意见。
审稿人有时候写得很含糊。"The methodology section needs substantial improvement" 这种话,你不知道具体要改什么。revision-coach 会:
逐条解析审稿意见,把含糊的批评翻译成具体的修改任务 判断每条意见的优先级(必须处理 / 建议处理 / 可以礼貌反驳) 生成回复信框架,对每条意见给出有针对性的回应模板
比如审稿人写:"The authors should consider including more recent literature."
revision-coach 的解析可能是:
这条意见指向文献时效性不足。优先级:必须处理。
建议:补充2023-2025年发表的相关研究,重点关注你核心暴露因素的最新证据。如果你已经纳入了近期文献,检查是否在综述中给予了足够的讨论。
回复信模板:We thank Reviewer X for this suggestion. We have now included [N] additional studies published in 2023-2025, which are incorporated into the Introduction and Discussion sections...
你不需要从零开始写回复信,也不需要猜审稿人的真实意图。
re-review 模式是改完之后用的。
把修改后的稿子和原始审稿意见一起交给 re-review,它会逐条核查:每条意见是否已经有效回应?修改有没有引入新的问题?修改后的稿子和之前的版本相比,整体得分变化是多少?
在你提交修改稿之前,先自己跑一遍 re-review。确认修改确实解决了问题,再按提交按钮。
六、补充一个功能:跨模型独立验证
v3.9 之后新增了 cross-model DA(跨模型独立验证)。
使用场景是这样的:你用 Claude 跑了 full 模式,Devil's Advocate 提了一批批评。但你不确定这些批评是否有普遍性,还是只反映了 Claude 这个模型的特定偏好。
cross-model DA 允许你用另一个配置好的模型(比如 DeepSeek 或 GPT-5)独立运行 Devil's Advocate 角色,然后对比两组批评的异同。
如果两个模型提了同样的问题,这个问题几乎肯定是真实存在的。如果只有一个模型提,这条批评的参考价值就要打折扣。
对公卫领域的研究者来说,有些方法论问题(比如生态学谬误、分层分析遗漏、混杂因素处理不当)是领域通识,两个模型都会提到;而有些写作风格上的批评带有模型倾向。跨模型对比帮你区分这两类,判断哪些问题值得重点处理。
使用前提:在 Claude Code 里已经配置了至少2个不同LLM服务商的模型。
结语
投稿前跑一遍审稿,得到一个60分的报告,会让人沮丧。
但这个分数是在你还来得及改的时候出现的。
真实的审稿是盲审,等三个月,打开邮件是 "We regret to inform you"。那个时候你才知道哪里有问题。
ARS的审稿不会让你的论文自动变好——那是你自己的事。它做的是:在你按下投稿按钮之前,把能发现的问题都让你发现一遍。
剩下的,交给运气。
收藏卡一:6种审稿模式速查
full | ||
quick | ||
re-review | ||
methodology-focus | ||
guided | ||
calibration |
收藏卡二:投稿前自查清单
methodology-focus | ||
full | quick 代替 | |
re-review | ||
disclosure | ||
format-convert |
本文是「ARS学术写作系列」第③篇。第④篇:用了三个月,我来告诉你这个工具做不到的事。
如果你现在正在等审稿意见,或者刚刚收到"Major Revision",把这篇转给你身边同样在熬的同门——你们需要在下一次投稿前看到这个工具。
