 夜雨聆风
夜雨聆风分享一下在一台Windows电脑上搭建HA的Hadoop集群的经历。
一、背景介绍:
宿主机:
环境:Windows10专业版
CPU:i7-8550U
内存:24G
二、主要部件:
VirtualBox:创建虚拟机的应用
Vagrant:通过配置文件方便批量创建虚拟机
Hadoop:官方版本3.3.6
Zookeeper:官方版本3.8.0
三、集群各节点角色:
一共规划了5个节点,各节点的角色包括:
hadoop-nn1:NameNode(active)、ResourceManager、JobHistoryServer、DFSZKFailoverController、QuorumPeerMain
hadoop-nn2:NameNode(standby)、DFSZKFailoverController、QuorumPeerMain
hadoop-dn1: DataNode、NodeManager、JournalNode、QuorumPeerMain
hadoop-dn2: DataNode、NodeManager、JournalNode
hadoop-dn3: DataNode、NodeManager、JournalNode
四、主要步骤:
下载并安装VirtualBox、Vagrant
通过配置文件Vagrantfile来自动创建5个虚拟机节点
①在宿主机集群目录(比如我的是D:/hadoop-cluster)下新建文件Vgrantfile(V大写,没有扩展名),具体内容如下:
# -*- mode: ruby -*- # 指定编辑器使用 Ruby 语法高亮# vi: set ft=ruby : # 指定 Vim 编辑器文件类型为 Ruby# 定义集群的私有网络网段,使用 VirtualBox 默认 Host-Only 网段CLUSTER_NETWORK = "192.168.56"# 初始化 Vagrant 配置,使用 API 版本 2Vagrant.configure("2") do |config|# =================== 全局配置(对所有虚拟机生效) ===================config.vm.box = "centos/7" # 使用 CentOS 7 作为基础操作系统镜像config.vm.synced_folder ".", "/vagrant", disabled: true # 禁用默认的/vagrant共享目录,避免权限问题# 所有虚拟机的公共初始化脚本config.vm.provision "shell", inline: <<-SHELL# 设置系统时区为上海(东八区)timedatectl set-timezone Asia/Shanghai# 停止并禁用防火墙(开发环境简化配置,生产环境应保持开启)systemctl stop firewalldsystemctl disable firewalld# 临时禁用 SELinux(Security-Enhanced Linux)setenforce 0# 永久禁用 SELinux(修改配置文件)sed -i 's/^SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config# 优化系统内核参数echo "net.ipv6.conf.all.disable_ipv6 = 1" >> /etc/sysctl.conf # 禁用 IPv6 以减少网络开销echo "net.ipv6.conf.default.disable_ipv6 = 1" >> /etc/sysctl.confecho "vm.swappiness = 10" >> /etc/sysctl.conf # 降低内存交换倾向,提升性能sysctl -p # 重新加载 sysctl 配置使其生效# 创建 Hadoop 生态组件所需的目录结构mkdir -p /opt/{hadoop,zookeeper} # 软件安装目录mkdir -p /data/{hadoop,hdfs,zookeeper,journalnode} # 数据存储目录SHELL# =================== 全局配置结束 ===================# =================== NameNode 1 节点(Active NameNode 候选) ===================config.vm.define "nn1" do |nn| # 定义虚拟机,内部标识为 "nn1"nn.vm.hostname = "hadoop-nn1" # 设置虚拟机主机名# 配置第一块网卡:Host-Only 网络,静态 IP,用于集群内部通信# nn.vm.network "private_network", type: "static", ip: "#{CLUSTER_NETWORK}.10"nn.vm.network "private_network", type: "static",ip: "#{CLUSTER_NETWORK}.10", netmask: "255.255.255.0"# 配置第二块网卡:NAT 网络,用于访问宿主机和互联网# nn.vm.network "public_network", use_dhcp_assigned_default_route: true# VirtualBox 虚拟机特定配置nn.vm.provider "virtualbox" do |vb|vb.name = "hadoop-nn1" # VirtualBox 管理器显示的虚拟机名称vb.memory = 2048 # 分配 1.5GB 内存(考虑到总内存 24GB 的合理分配)vb.cpus = 1 # 分配 1 个 CPU 核心(i7-8550U 为 4 核 8 线程,5 个节点各 1 核合理)vb.gui = false # 不显示图形界面,节省资源vb.customize ["modifyvm", :id, "--vram", "16"] # 设置显存为 16MB,避免图形驱动问题end# nn1 节点的专用配置脚本nn.vm.provision "shell", inline: <<-SHELL# 配置 /etc/hosts 文件,添加集群所有节点的主机名解析# 这样可以通过主机名而非 IP 地址访问其他节点echo "#{CLUSTER_NETWORK}.10 hadoop-nn1" >> /etc/hostsecho "#{CLUSTER_NETWORK}.11 hadoop-nn2" >> /etc/hostsecho "#{CLUSTER_NETWORK}.12 hadoop-dn1" >> /etc/hostsecho "#{CLUSTER_NETWORK}.13 hadoop-dn2" >> /etc/hostsecho "#{CLUSTER_NETWORK}.14 hadoop-dn3" >> /etc/hosts# 添加宿主机 Windows 的解析,方便从虚拟机访问宿主机echo "192.168.56.1 windows-host" >> /etc/hosts# 为 NameNode 创建专用数据目录mkdir -p /data/hdfs/namenodechmod 755 /data/hdfs/namenodeSHELLend# =================== NameNode 1 定义结束 ===================# =================== NameNode 2 节点(Standby NameNode 候选) ===================config.vm.define "nn2" do |nn| # 定义第二个 NameNodenn.vm.hostname = "hadoop-nn2" # 设置主机名nn.vm.network "private_network", type: "static", ip: "#{CLUSTER_NETWORK}.11" # Host-Only 网卡nn.vm.network "public_network", use_dhcp_assigned_default_route: true # NAT 网卡nn.vm.provider "virtualbox" do |vb|vb.name = "hadoop-nn2"vb.memory = 2048 # 同样分配 1.5GB 内存vb.cpus = 1vb.gui = falsevb.customize ["modifyvm", :id, "--vram", "16"]endnn.vm.provision "shell", inline: <<-SHELL# 配置 hosts 文件,确保双向解析echo "#{CLUSTER_NETWORK}.10 hadoop-nn1" >> /etc/hostsecho "#{CLUSTER_NETWORK}.11 hadoop-nn2" >> /etc/hostsecho "#{CLUSTER_NETWORK}.12 hadoop-dn1" >> /etc/hostsecho "#{CLUSTER_NETWORK}.13 hadoop-dn2" >> /etc/hostsecho "#{CLUSTER_NETWORK}.14 hadoop-dn3" >> /etc/hostsecho "192.168.56.1 windows-host" >> /etc/hosts# 为 Standby NameNode 创建检查点目录mkdir -p /data/hdfs/namesecondarychmod 755 /data/hdfs/namesecondarySHELLend# =================== NameNode 2 定义结束 ===================# =================== DataNode 1 节点(JournalNode + DataNode) ===================config.vm.define "dn1" do |dn| # 定义第一个 DataNodedn.vm.hostname = "hadoop-dn1" # 设置主机名为 hadoop-dn1dn.vm.network "private_network", type: "static", ip: "#{CLUSTER_NETWORK}.12" # Host-Only 网卡dn.vm.network "public_network", use_dhcp_assigned_default_route: true # NAT 网卡dn.vm.provider "virtualbox" do |vb|vb.name = "hadoop-dn1"vb.memory = 2048 # 分配 1GB 内存(DataNode 和 JournalNode 内存需求较低)vb.cpus = 1vb.gui = falseenddn.vm.provision "shell", inline: <<-SHELL# 配置 hosts 文件echo "#{CLUSTER_NETWORK}.10 hadoop-nn1" >> /etc/hostsecho "#{CLUSTER_NETWORK}.11 hadoop-nn2" >> /etc/hostsecho "#{CLUSTER_NETWORK}.12 hadoop-dn1" >> /etc/hostsecho "#{CLUSTER_NETWORK}.13 hadoop-dn2" >> /etc/hostsecho "#{CLUSTER_NETWORK}.14 hadoop-dn3" >> /etc/hostsecho "192.168.56.1 windows-host" >> /etc/hosts# 为 DataNode 创建数据块存储目录mkdir -p /data/hdfs/datanodechmod 755 /data/hdfs/datanode# 为 JournalNode 创建编辑日志存储目录mkdir -p /data/journalnode/dn1chmod 755 /data/journalnode/dn1SHELLend# =================== DataNode 1 定义结束 ===================# =================== DataNode 2 节点(JournalNode + DataNode) ===================config.vm.define "dn2" do |dn| # 定义第二个 DataNodedn.vm.hostname = "hadoop-dn2" # 设置主机名为 hadoop-dn2dn.vm.network "private_network", type: "static", ip: "#{CLUSTER_NETWORK}.13" # Host-Only 网卡dn.vm.network "public_network", use_dhcp_assigned_default_route: true # NAT 网卡dn.vm.provider "virtualbox" do |vb|vb.name = "hadoop-dn2"vb.memory = 2048 # 分配 1GB 内存vb.cpus = 1vb.gui = falseenddn.vm.provision "shell", inline: <<-SHELL# 配置 hosts 文件echo "#{CLUSTER_NETWORK}.10 hadoop-nn1" >> /etc/hostsecho "#{CLUSTER_NETWORK}.11 hadoop-nn2" >> /etc/hostsecho "#{CLUSTER_NETWORK}.12 hadoop-dn1" >> /etc/hostsecho "#{CLUSTER_NETWORK}.13 hadoop-dn2" >> /etc/hostsecho "#{CLUSTER_NETWORK}.14 hadoop-dn3" >> /etc/hostsecho "192.168.56.1 windows-host" >> /etc/hosts# 为 DataNode 和 JournalNode 创建目录mkdir -p /data/hdfs/datanodechmod 755 /data/hdfs/datanodemkdir -p /data/journalnode/dn2chmod 755 /data/journalnode/dn2SHELLend# =================== DataNode 2 定义结束 ===================# =================== DataNode 3 节点(JournalNode + DataNode) ===================config.vm.define "dn3" do |dn| # 定义第三个 DataNodedn.vm.hostname = "hadoop-dn3" # 设置主机名为 hadoop-dn3dn.vm.network "private_network", type: "static", ip: "#{CLUSTER_NETWORK}.14" # Host-Only 网卡dn.vm.network "public_network", use_dhcp_assigned_default_route: true # NAT 网卡dn.vm.provider "virtualbox" do |vb|vb.name = "hadoop-dn3"vb.memory = 2048 # 分配 1GB 内存vb.cpus = 1vb.gui = falseenddn.vm.provision "shell", inline: <<-SHELL# 配置 hosts 文件echo "#{CLUSTER_NETWORK}.10 hadoop-nn1" >> /etc/hostsecho "#{CLUSTER_NETWORK}.11 hadoop-nn2" >> /etc/hostsecho "#{CLUSTER_NETWORK}.12 hadoop-dn1" >> /etc/hostsecho "#{CLUSTER_NETWORK}.13 hadoop-dn2" >> /etc/hostsecho "#{CLUSTER_NETWORK}.14 hadoop-dn3" >> /etc/hostsecho "192.168.56.1 windows-host" >> /etc/hosts# 为 DataNode 和 JournalNode 创建目录mkdir -p /data/hdfs/datanodechmod 755 /data/hdfs/datanodemkdir -p /data/journalnode/dn3chmod 755 /data/journalnode/dn3SHELLend# =================== DataNode 3 定义结束 ===================end# Vagrant 配置块结束
② 打开CMD,在宿主机集群目录(D:/hadoop-cluste)执行命令:vagrant up,系统自动创建这5个虚拟机节点
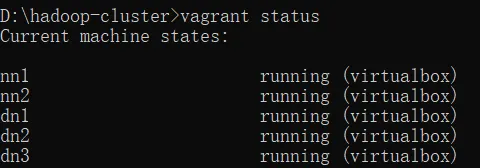
③ vagrant status验证虚拟机是否都已启动运行
④ 关闭宿主机的防火墙(必须),否则虚拟机无法访问宿主机,各种服务的web服务打不开。
⑤ 宿主机的hosts文件增加虚拟机的IP映射
192.168.56.10 hadoop-nn1192.168.56.11 hadoop-nn2192.168.56.12 hadoop-dn1192.168.56.13 hadoop-dn2192.168.56.14 hadoop-dn3
配置5个虚拟机节点的基础环境
① 安装JDK,配置相关环境变量
② 创建用户hadoop和用户组hadoop
③ 把/data目录的所有者修改为hadoop
④ 执行visudo,把hadoop加入到sudo权限列表,然后切换到hadoop用户
⑤ 删除/etc/hosts中的127.0.0.1 localhost这一行
⑥ 配置nn1到其他节点的免密登录,配置nn2到nn1的免密登录
下载安装Hadoop、zookeeper
配置重要文件,然后把安装目录分发到各节点
① hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk ② core-site.xml
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 制定hdfs的默认名称服务地址(逻辑名称) --><property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><!-- 指定Hadoop临时数据存储目录 --><property><name>hadoop.tmp.dir</name><value>/data/hadoop/tmp</value></property><!-- 禁用IP检查 --><property><name>dfs.namenode.datanode.registration.ip-hostname-check</name><value>false</value></property><property><name>ha.zookeeper.quorum</name><value>hadoop-nn1:2181,hadoop-nn2:2181,hadoop-dn1:2181</value></property></configuration>
③ hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定hdfs副本数量 --><property><name>dfs.replication</name><value>3</value></property><!-- =========HA配置========== --><!-- 逻辑集群名称,与core-site.xml中的fs.defaultFS对应 --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- 定义两个namenode --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><!-- nn1的RPC地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>hadoop-nn1:8020</value></property><!-- nn2的RPC地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>hadoop-nn2:8020</value></property><!-- nn1的http地址 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>hadoop-nn1:9870</value></property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>hadoop-nn2:9870</value></property><!-- JournalNode集群地址 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop-dn1:8485;hadoop-dn2:8485;hadoop-dn3:8485/mycluster</value></property><!-- HA故障转移的Java类 --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hadoop/.ssh/id_rsa</value></property><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property><!-- JournalNode编辑日志目录 --><property><name>dfs.journalnode.edits.dir</name><value>/data/journalnode</value></property><!-- NameNode元数据存储目录 --><property><name>dfs.namenode.name.dir</name><value>file:///data/hdfs/namenode</value></property><!-- DataNode数据块存储目录 --><property><name>dfs.datanode.data.dir</name><value>file:///data/hdfs/datanode</value></property></configuration>
④ yarn-site.xml
<?xml version="1.0"?><configuration><!-- Site specific YARN configuration properties --><property><name>yarn.resourcemanager.hostname</name><value>hadoop-nn1</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>hadoop-nn1:8088</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.local-dirs</name><value>/data/hadoop/yarn/local</value></property><property><name>yarn.nodemanager.log-dirs</name><value>/data/hadoop/yarn/logs</value></property><property><name>yarn.log-aggregation-enabled</name><value>true</value></property></configuration>
⑤ mapred-site.xml
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>hadoop-nn1:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop-nn1:19888</value></property><property><name>mapreduce.map.memory.mb</name><value>512</value></property><property><name>mapreduce.reduce.memory.mb</name><value>768</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value></property></configuration>
⑥ workers
hadoop-dn1hadoop-dn2hadoop-dn3
⑦ zookeeper的zoo.cfg
tickTime=2000initLimit=10syncLimit=5dataDir=/data/zookeeperclientPort=2181server.1=hadoop-nn1:2888:3888server.2=hadoop-nn2:2888:3888server.3=hadoop-dn1:2888:3888
⑧ 在nn1/nn2/dn1的/data/zookeeper目录下创建文件myid,内容分别是1/2/3
6. 启动集群
① 启动JournalNode
② 启动Zookeeper
③ 初始化NameNode
④ 启动NameNode
⑤ 启动DataNode
⑥ 启动ResourceManager
⑦ 启动NodeManager
7. 验证集群
① 验证zookeeper

三个节点分别执行zkServer.sh status,返回结果应该是1个leader,2个follower
② 验证NameNode

执行命令hdfs haadmin -getServiceState nn1或nn2,返回结果一个是active,一个是standby
③ 验证hdfs

能正常显示hdfs目录
④ 验证MapReduce
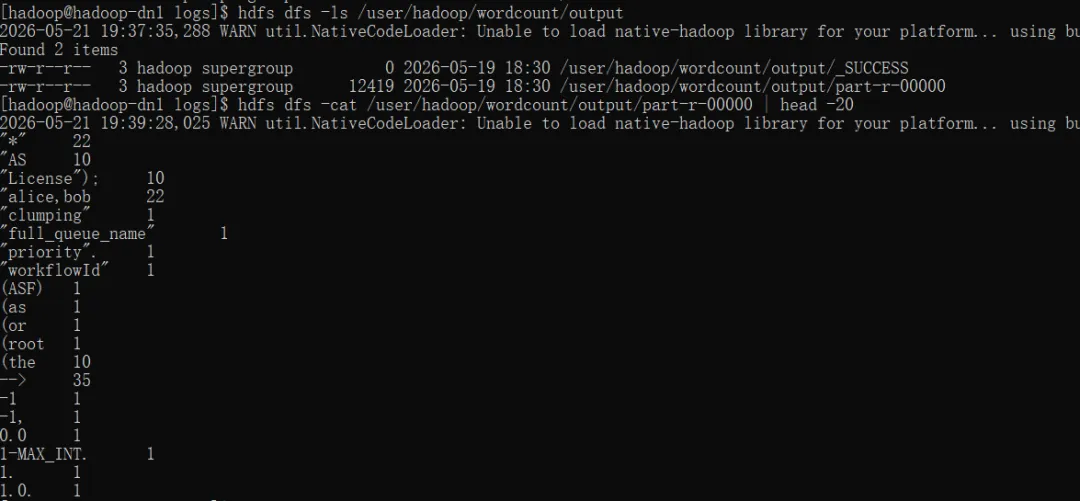
把hadoop配置文件目录下的所有xml文件上传到hdfs的/user/hadoop/wordcount/input目录下,然后执行以下命令:
hadoop jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar \wordcount \/user/hadoop/wordcount/input \/user/hadoop/wordcount/output
命令执行成功,且有输出结果

五、搭建过程中遇到的问题
如果是以学习和测试为目的搭建一个Hadoop集群,个人建议就从几个裸机的centos节点开始,这样能更好地理解一个组件需要有哪些最基本的配置,各配置属性的作用是什么,有任何问题也好处理。我最开始基于Docker镜像的方式搭建集群,过程中遇到了一些问题,大概总结一下:
① 从某种程度上来说,Docker镜像可以看做是黑盒,不管是用bde版本的hadoop镜像,还是官方的hadoop镜像,遇到问题之后不好定位和解决(比如Container启动就秒退)。
② 很多Docker镜像的地址无法直接访问,需要科学上网。
③ 一般来说,一个容器只运行一个进程,后续如果要加服务,就要加容器,非常吃资源,对于学习来说,一台宿主机很难应付
网络问题。
① 如果虚拟机ping不通宿主机,大概率是宿主机的防火墙没关
② 如果某些服务(比如zookeeper)启动就不成功,也有可能是虚拟机的防火墙没关,针对特定端口有拦截。
3. 如果配置ssh免密登录时出现Permission Denied的问题

,可以尝试通过这个命令解决:
① sudo sed -i 's/^PasswordAuthentication no/PasswordAuthentication yes/' /etc/ssh/sshd_config
② sudo systemctl restart sshd
启动JournalNode时报错,报错日志:

/data目录是创建虚拟机时由vagrant用户创建的,所以hadoop用户没有写入权限,需要把/data的所有者改为hadoop用户
在启动hdfs和zookeeper的过程中,都出现了进程启动起来,但实际无法生效的情况,提交MapReduce任务测试的时候,也出现了任务失败的情况。

最后发现都是在etc/hosts中,有这一行:127.0.0.1 localhost,导致各节点启动服务的时候,端口监听是在127.0.0.1的IP上,其他节点与其进行通话就会连接失败,所以在配置过程中,就最好删掉这行。
yarn跳转到某个log时打不开
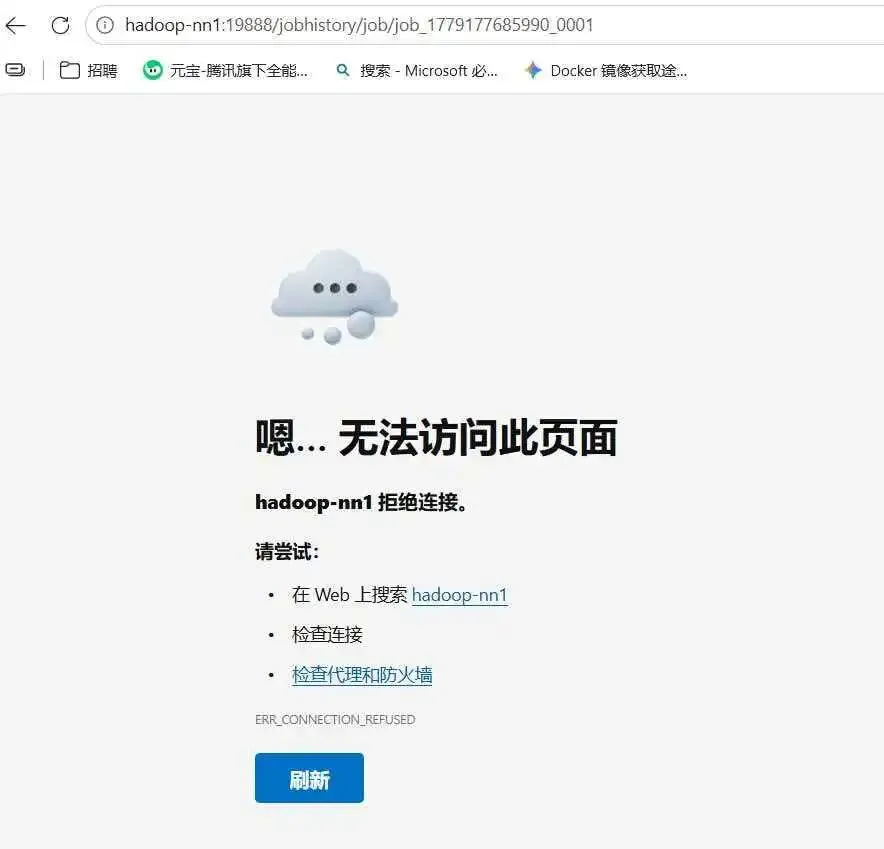
需要宿主机的hosts增加各虚拟机节点的IP映射
纸上得来终觉浅,搭一个集群,只看纸面步骤的话,会觉得很简单,但真正实操起来,会遇到各种问题,正是在解决问题的过程中,对知识有了更深的了解,也更有可能应用到实际工作中。执行过程中的具体问题可以问豆包、元宝或其他AI,当然AI给的答案不一定完全正确,可以互相印章参考。
