【ICSE'25 论文 | 软件供应链安全】npm 仓库里的恶意包,GPT-4 能比 CodeQL 检测得更准吗?开源包生态已是现代软件开发的基础设施,但它同时也是供应链攻击最集中的战场。用 LLM 来替代规则库做恶意包检测,效果究竟如何?
英文标题:Leveraging Large Language Models to Detect npm Malicious Packages 发表会议:IEEE/ACM ICSE 2025(第 47 届国际软件工程大会) 研究机构:North Carolina State University、Socket Inc. 等 npm 是全球最大的 JavaScript 包管理仓库,托管超过 200 万个开源包,每周下载量高达数百亿次。然而,其开放性使其成为软件供应链攻击的重要目标——攻击者通过发布恶意包,借助开发者的信任在其项目中植入数据窃取、后门或挖矿代码。现有的恶意包检测技术多依赖手工规则(如 CodeQL 自定义规则)或机器学习模型,但往往存在较高的误报率或规则维护成本高的问题。这篇 ICSE 2025 的工作首次系统地研究了 LLM(GPT-3 和 GPT-4)在 npm 恶意包检测中的有效性,并提出了一个名为 SocketAI 的检测工作流。一、研究背景与挑战
软件供应链攻击近年来呈快速增长态势。攻击者常用的手段包括:Typosquatting(利用拼写相近的包名欺骗开发者)、注入恶意的 install 脚本(在包安装时自动执行恶意代码)、隐藏的后门代码(混入大量正常代码中难以发现)等。现有防御工具面临的核心挑战在于:恶意代码的表现形式高度多样,且攻击者会持续演变技术手段以绕过规则检测。CodeQL 等工具依赖人工编写的查询规则,需要安全专家持续维护且规则集难以穷举;机器学习方法则依赖特征工程和标注数据,对新型攻击模式的泛化能力有限。LLM 在代码语义理解上的广泛能力,理论上可以捕捉那些难以用规则精确描述的可疑代码模式,这是本研究探索 LLM 在这一场景应用的核心动机。二、SocketAI 工作流:四步检测流程
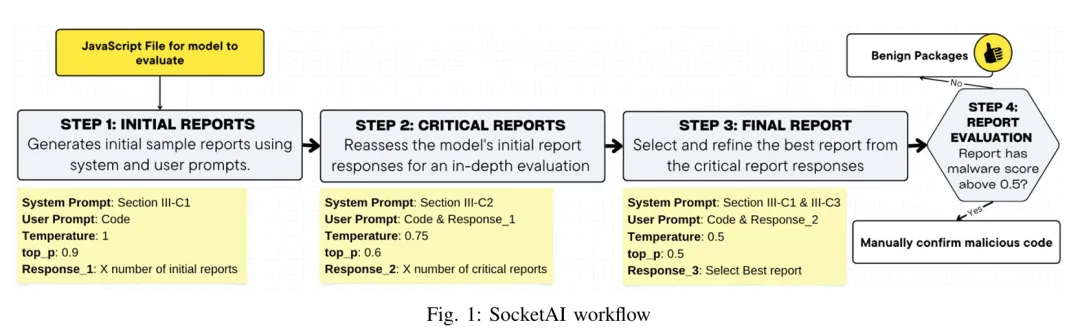
SocketAI 的设计围绕一个包含四个步骤的检测工作流展开,由论文 Figure 1 完整展示。步骤一是输入构建:将待检测包的 JavaScript 文件内容与预定义的系统角色提示(System Prompt)组合,提示中明确要求模型扮演安全分析师角色,对代码进行恶意性评估;步骤二和步骤三是迭代自我精炼(Iterative Self-Refinement):SocketAI 生成多个初始分析报告(利用 LLM 在不同采样下的多样性),然后引入 LLM-as-a-Judge 机制——让 LLM 作为评判者对其自身生成的多个报告进行评估,结合预定义的评分标准(如恶意可能性评分、证据质量评分等)输出综合分析结论;步骤四是人工审核环节(Human-in-the-Loop):SocketAI 将最终的 LLM 分析报告呈现给安全分析师进行人工确认,确保关键决策不完全依赖自动化结果。在实际部署中,还引入了 CodeQL 作为预筛选器(Pre-screener),先用静态规则快速过滤掉大量明显安全的文件,再将剩余文件交由 SocketAI 进行 LLM 分析,以降低 LLM 调用的文件数量和成本。三、实验结果:GPT-4 精确率 99%,预筛选节省 76% 成本
研究者基于包含 5,115 个 npm 包(其中 2,180 个含恶意代码)的基准数据集进行了系统评估,对比基线为使用 39 条自定义规则的 CodeQL。● GPT-4 达到99% 精确率和 97% F1 分数,相较于 CodeQL 分别提升了16% 和 9%,整体性能优势显著; ● GPT-3 达到 91% 精确率和 94% F1 分数,在精确率上仍领先 CodeQL,且调用成本远低于 GPT-4,提供了性价比更高的选择; ● 将 CodeQL 作为预筛选器后,需要提交给 LLM 分析的文件数量减少了77.9%,GPT-3 的成本降低了60.9%,GPT-4 的成本降低了76.1%——预筛选策略对于控制大规模扫描的 API 费用至关重要; ● 对 GPT-3 而言,幻觉(Hallucination)问题更为突出,导致部分误分类案例,而 GPT-4 在这方面表现更为稳健。四、定性分析:哪类恶意包最容易被检测,哪类最容易被漏掉
研究者对检测结果进行了系统的定性分析,识别出 SocketAI 检测效果最佳的三类恶意包:● 数据窃取类(Data Theft):窃取环境变量、系统信息或凭证的代码,语义上易于识别; ● 任意代码执行类(Execution of Arbitrary Code):通过 eval()、child_process.exec() 等执行外部命令的模式; ● 可疑域名连接类(Suspicious Domain Connection):向已知恶意域名发送 HTTP 请求的行为。相对难以检测的场景包括:高度混淆的恶意代码(绕过了语义理解)和高仿正常功能代码的恶意包(攻击逻辑被精心隐藏在正常逻辑流中)。五、总结与启示
这项工作是对 LLM 在软件供应链安全这一垂直场景中有效性的首次系统性评估,其结论对工业界的安全工具开发具有直接参考价值。●LLM 在 npm 恶意包检测中显著优于传统规则引擎,尤其 GPT-4 在精确率和 F1 上的优势十分突出,为将 LLM 引入供应链安全工具链提供了实证支持; ●预筛选 + LLM 精细分析的两阶段架构,是控制大规模扫描成本的有效工程策略,在工业化部署中应优先考虑这种分层设计; ● LLM 的幻觉问题在安全场景中影响不可忽视,GPT-3 与 GPT-4 之间的幻觉率差距提示:在对误报代价较高的安全场景中,模型选型应优先考虑可靠性而非成本; ● SocketAI 保留了"人工确认"环节,这一设计体现了对高风险决策场景的审慎态度——在安全领域,完全自动化的 LLM 决策链仍需配合合适的人工审核机制。论文 arXiv 版本:https://arxiv.org/abs/2403.12196;ICSE 2025 DOI:https://doi.ieeecomputersociety.org/10.1109/ICSE55347.2025.00146素材来自于网上公开开源内容,内容经LLM辅助,如有侵权,随时可删。 更多信息请关注本公众号。
喜欢就关注哦
 夜雨聆风
夜雨聆风