 夜雨聆风
夜雨聆风我要先坦白一件事。
上个月我的Claude Code月账单,翻了一倍。
一倍。
不是因为我写了三倍的代码,是因为Claude太礼貌了。
你用Claude Code你就知道,它回答一个Bug问题,能给你写篇小作文。先帮你分析可能的原因,再说三种可能性,然后推荐一个解决方案,最后还附上一句「希望这些信息对你有帮助」。我每次看到这句话就头大。
举个例子。我问它一个React组件为什么重复渲染。69个token就能说清楚的事,它非要用150个token给你上课。不是说不清楚,是太想给你讲清楚了。它觉得讲得越完整越负责任,但对我来说,大多数时候我只想知道一件事,Bug在哪,怎么改。
这个问题困扰了我很久,但我一直觉得这就是AI的「天性」,改不了。

上周三晚上,我盯着月度账单条形图看了两分钟,鬼使神差的打开了GitHub Trending。
第一条就把我看愣了。
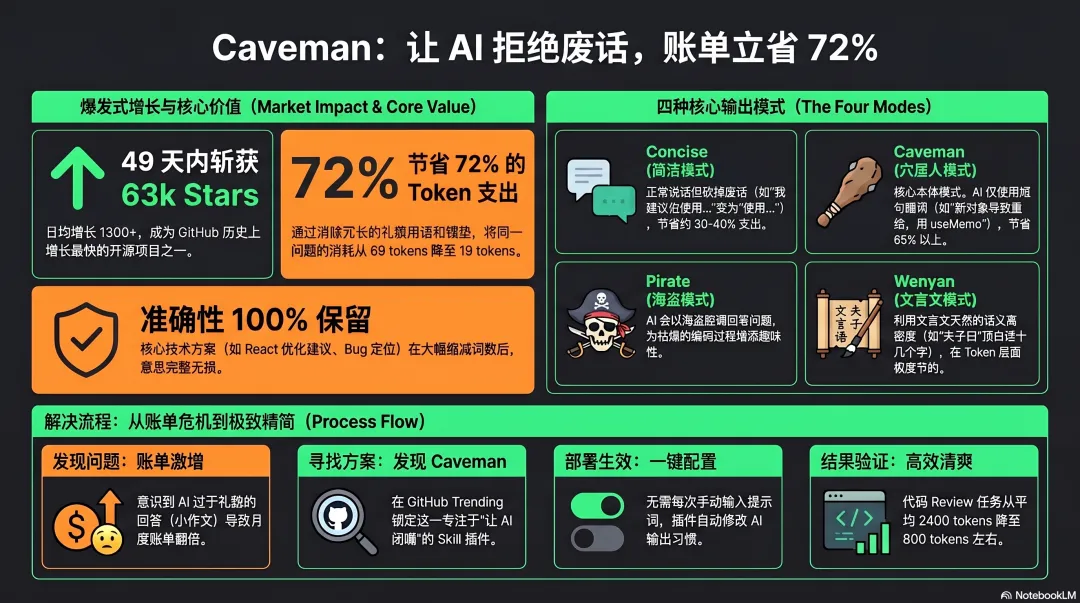
一个石头emoji图标的项目,名字叫Caveman。标语一行英文,「why use many token when few do trick」。翻译成人话就是,少说废话多干活。49天,63k stars。日均增长1300+,这个增速放在GitHub历史上能排进top级别的开源爆款。
我点进去看了十分钟,然后直接装了。
它的功能就一件事,让你的AI说话像穴居人。技术准确性完全不掉,但词全部砍到最短。README直接给了Before和After对比,我看完先笑了一下,然后认真了。
还是那个React组件重复渲染的Bug。
Normal Claude这么说:
你的React组件之所以会重新渲染,很可能是因为你在每一个渲染周期中都创建了一个新的对象引用。当你将一个内联对象作为props传递时,React的浅层比较机制会认为它在每一次渲染时都是一个不同的对象,从而触发重新渲染。我建议你使用useMemo来对该对象进行记忆化处理。
69个token。
Caveman Claude这么说:
每次渲染生成新对象引用。内联对象属性等于新引用等于重新渲染。用useMemo包裹。
19个token。
同一个Bug,同一个解决方案。准确性100%保留,token省了72%。

我后来又试了个中文场景。正常Claude会说「这个问题的根本原因可能在于你的认证中间件没有正确校验token的过期时间」,Caveman直接给你「auth中间件token过期判断错。改成小于等于」。
意思一点没丢。语气全部砍掉。
我当时心里咯噔了一下。不是因为省了多少钱,是因为我突然意识到,过去几个月我跟Claude的所有对话里,有多少token是花在「礼貌客套」「铺垫语气」「把话说完整漂亮」上面的?三成?可能不止。
说到这里你可能好奇,这个Caveman到底什么原理。
其实就是一个Claude Code的skill插件。装完之后不需要每次都在prompt里写「请简洁回答」,AI自动用穴居人语法说话。一次配置,永久生效。
它不是一刀切。作者给了四个档位,你自己选。
第一个叫concise,简洁模式。正常说话但砍掉废话。从「我建议您考虑使用useMemo来优化性能」变成「用useMemo优化」。省大概30-40%的token。适合日常使用,不会让人觉得奇怪。
然后是caveman模式。这才是本体。AI直接变成一个只会蹦短句的原始人。「新对象引用导致重新渲染。用useMemo。」到这一步已经能省65%左右了。日常代码review、Bug定位、配置修改,这种场景完全够用。
第三个叫pirate。对,海盗模式。AI会用海盗腔调回答问题。说真的我不太理解为什么有人需要这个,但它就是存在。可能作者自己觉得好玩就加上了。
但真正让我多看了两眼的,是最后一个。
Wenyan。文言文。

我第一次看到这个选项的时候,以为是个玩笑。
但我认真想了一下,发现这个作者下了真功夫。
中文的现代汉语本身就比英文费token。因为分词模型对中文不友好,一个中文字可能要拆成两三个token。但文言文不一样。「夫子曰」三个字顶白话十几个字。对tokenizer来说,文言文是天然省token的。
我试了一下。问Python里list和tuple的区别。正常Claude会说「list是可变的,可以增删改查,tuple是不可变的,一旦创建就不能修改……」一大段。Wenyan模式直接给我吐出来
list可变,tuple不可。前者增删改皆可,后者一经定,终身不易。
讲道理,这种风格用来回答技术问题,居然意外地清爽。
我后来用wenyan模式跑了两天,做了个粗略统计。同样的代码review任务,开caveman之前平均每次2400 tokens左右,开了之后800上下。降幅大概65%到75%。跟README里标的数字基本对得上。

但说到这里我想停下来聊点别的。
Caveman让我觉得有意思的地方,不是省了多少钱。
是这件事背后的逻辑。
正常人做prompt工程,路径是这样的。写更精准的指令,给更具体的范例,限制更明确的格式。这一套是在「告诉AI怎么理解」。你花了很多时间在教AI听懂你。
Caveman反过来。它直接改了AI的「输出习惯」。你不需要教AI怎么听懂你,你教它怎么说话就行。
这其实是个挺重要的转变。
我们一直在想怎么让AI更懂我们。Caveman提供了一个反方向。与其让AI更懂我们,不如让AI按我们能用的方式说话。
你想想看,现在AI最大的问题是什么。不是它不够聪明,是它太「礼貌」了。它总想给你一个完整的、漂亮的、面面俱到的回答。但绝大多数时候你要的不是一篇小作文,你要的就是一句话。Bug在哪,怎么改,完事。
Caveman这种工具,就是用户在用一种meme的方式告诉AI,别按你以为漂亮的方式说话,按我能用的方式说话。是用户在主导沟通规则,不是模型。
我觉得这才是它49天爆了63k stars的真正原因。不是因为它省token,省token的工具一抓一大把。是因为它说出了很多人心里的那句话,AI你能不能少说两句。
顺着这个再聊一点。同一天我还看到了另一个开源项目,叫skill-cleaner。OpenClaw那个龙虾之父Peter做的。干的活不一样但思路相似。Caveman是给AI的嘴减肥,skill-cleaner是给你的AI技能库减肥。它帮你审计每个skill的token预算,检测重复技能,精简描述。有用户说把技能描述从90多词砍到40词以内,AI选技能的准确率反而提升了。
一个管AI怎么说,一个管AI怎么选。两个方向,同一个目标,让你的AI少做那些没用的事。
当然了,丑话说在前面。
Caveman只省output token,input不省。你发给Claude的代码、文档、上下文,该多少token还是多少token。如果你的输入本身就大,省的那部分占比没有你想象的那么夸张。
然后复杂推理场景它hold不住。简单的Bug定位、概念解释、配置修改完全没问题。但碰到那种「帮我分析这段代码可能的并发问题,给出三种不同的修复思路」,穴居人语法就太单薄了。这种时候你还是得切回正常模式。
还有文言文模式。它吃文化背景。「list可变,tuple不可」这种半文半白的表达,对老开发者无所谓,对入门用户可能反而是阅读门槛。团队协作场景里我建议慎用,自用爽就行。
说真的,装上Caveman之后我想了很多。
我们花了很多时间在琢磨怎么写更好的prompt,怎么让AI更聪明,怎么让它更理解我们的意图。但也许我们忽略了一个更基本的问题。AI说的话,有多少是我们真正需要的?
如果一次对话里三成token是废话,那不是AI的错。是没有人从输出端去约束过它应该怎么说话。
Caveman用一种很meme的方式提醒了我们这件事。63k stars的爆火本身就说明,这个问题戳中了很多人。
工具越来越多,功能越来越强。但真正省时间的,从来不是让AI说更多话。是让它少说那些没必要的。
想装的话GitHub搜Caveman就行,一行命令搞定。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
/ 作者:夏尔AI
/ 邮箱:435452239@qq.com
