 夜雨聆风
夜雨聆风做AI漫剧试过不少组合,宫斗宅斗这类题材的嫡庶之争、姐妹反目、权谋算计,观众看得懂也吃这套。但这类剧情容易碎片化,只要一个角色脸崩、一件衣服颜色跳戏,前面的情绪积累就全白费。
研究了一段时间,用豆包+即梦+剪映这套组合跑顺了一条路。
豆包写剧本和分镜,即梦生成角色形象和场景,利用角色形象图固定长相、场景风格,改用豆包生成的视频完成后续制作。
第一步:豆包生成宫斗宅斗剧本和分镜
打开豆包,直接输入宫斗宅斗题材的剧本指令。我给的提示词是:
帮我写一个宫斗宅斗的短剧剧本,需要包含人物形象提示词、剧情、转折等描述
豆包很快就生成了一份完整的剧本大纲。宫斗宅斗的核心是冲突要密集,如果豆包初版剧本节奏太慢或者铺垫太长,在对话框里直接告诉它“把冲突提前到开头15秒”“台词改短,每句不超过15字”,符合短剧快节奏调性,直到改满意为止。

剧本确认后,让豆包继续拆分成详细的分镜脚本,这里也可以给指令一次性生成,把每个镜头的画面描述、景别、台词、时长都列清楚,后续生成视频会更省事。
第二步:即梦生成角色形象和场景
角色形象是漫剧的“脸面”。先处理主角——在宫斗宅斗中,女主必须有一套辨识度极高的“标准像”,才能在复杂的后宫环境中被观众一眼认出来。
打开即梦,将豆包生成的角色提示词(包括女主、反派的形象描述)复制进去,选择9:16的比例和合适的模型。

确定女主的基础图像后,尝试使用即梦的角色固定功能:将这张满意的图像上传为参考图,并锁定。在后续生成所有分镜时,在生成参数中填入,AI便基于相同的视觉锚点继续创作,反复翻车的变脸问题会大幅缓解,依次生成所有形象。

第三步:用豆包Seedance 2.0生成视频
即梦的Seedance 2.0虽然画质和角色一致性表现优异,但一到高峰期就陷入漫长的排队,一排就是几个小时。
我是改用豆包中的Seedance 2.0生成视频,之前也介绍过。虽然操作逻辑与即梦略有出入,但基本不需要排队,1到3分钟就能出一条15秒片段,这点对效率的提升是决定性的。
唯一的差异在于角色绑定方式:在豆包中无法使用即梦中便捷的@关联功能,取而代之的是在描述文字中手动标注。例如,在输入“[图1]缓缓走出宫殿,眼神凌厉”前,需确认已将女主的形象图上传,并在描述中明确图1特指的角色。
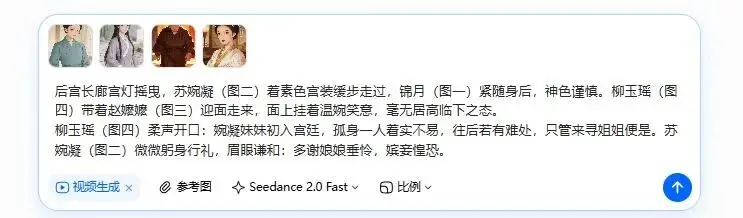
生成时不可避免地会遇到物理逻辑错误,例如角色动作变形或口型偏差。同一个镜头多试两三个版本,选效果最好的那条保存。
第四步:剪映剪辑收尾
把所有视频片段导入剪映,按分镜表顺序拖入时间轴。Seedance 2.0自带的配音和音效基本可用。
如果AI自带的配音情绪不够贴合角色,可以使用剪映的“文本朗读”功能重新生成,系统提供多种声音风格。此外,检查镜头衔接时发现前后景突变的穿帮片段,直接分割删除,确保逻辑连贯。

整套流程走下来,从剧本到剪辑基本控制在30到40分钟。做AI生成的漫剧,核心是“角色稳住”,角色一致性给观众基本信任感,冲突密度决定观众会不会点下一集。
踩过的坑和总结的经验都写在这里了,剩下的就看你自己的故事和创意了。
