 夜雨聆风
夜雨聆风编注:本期内容为少数派 Matrix 社区应用自荐文章合集。文章代表作者个人观点,作者与文中产品有直接的利益相关(开发者、自家产品等),少数派仅对标题和排版略作修改。
本期目录
📁SynoSync:让你的 Obsidian 文档库,在所有设备间无缝同步
📄 优派简历:打造一个足够干净、纯粹的工作台
🔍屏忆(ScreenMemo):本地运行的智能截屏备忘与检索工具

 一张图看懂整篇文章
一张图看懂整篇文章
▍开发背景:关于安全感与掌控感
一直以来,基于 Markdown 纯文本的 Obsidian 文档库给了我极强的安全感与掌控感。
在我的工作流中,NAS 承担着文档库托管与同步的核心角色。群晖 Drive 在 Windows、Mac、Linux 乃至 Android 平台上的体验都堪称出色,唯独在 iOS 端,这种连贯性戛然而止。
▍困境:iOS 上的群晖 Drive,为何不够「现代化」?
在 iOS 生态下,群晖 Drive 的同步范围被严格限制在自身的沙盒文件夹内(应该是考虑到旧版本 iOS 兼容性)。这意味着 Obsidian 无法直接调用 Drive 的同步能力来读取文档库。对于追求「全平台一致体验」的开发者来说,这成了最难受的断层。
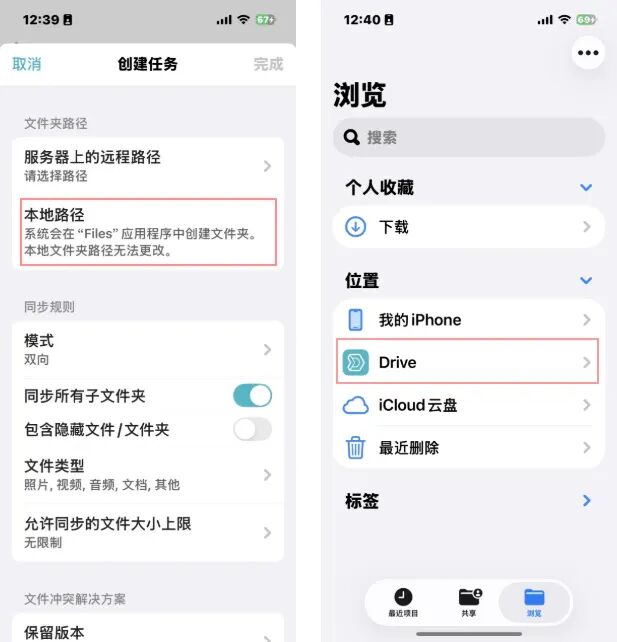 群晖在 iOS 平台的 Drive 应用不支持新版本的路径自定义
群晖在 iOS 平台的 Drive 应用不支持新版本的路径自定义
▍Obsidian 的多平台同步方案现状
如果你想自建 Obsidian 文档库同步,目前主流方案的优劣对比清晰可见:
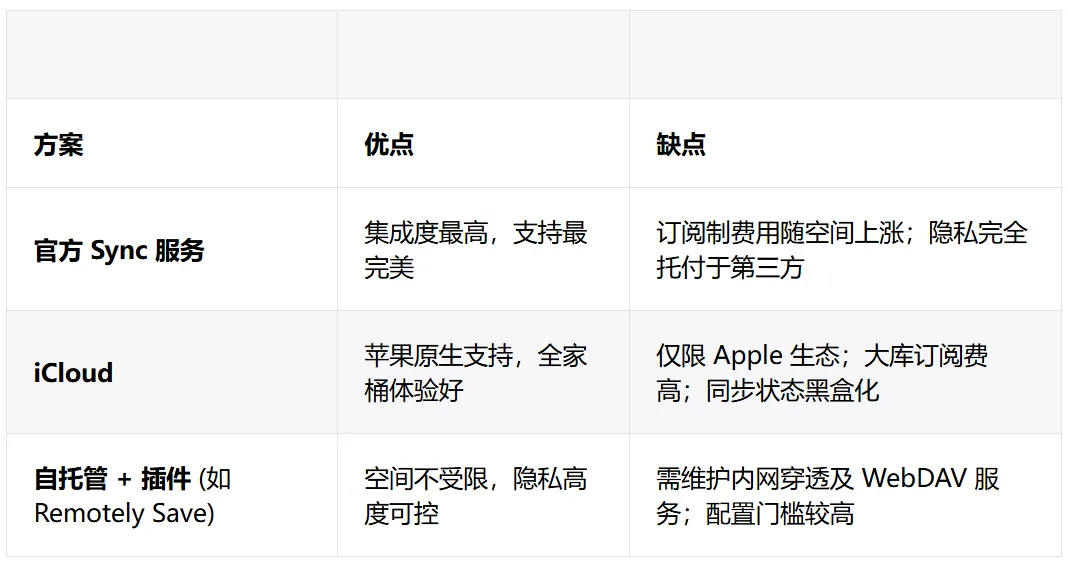
如果你和我一样,希望文档库具备更安全的托管方式,Remotely Save + WebDAV 依然是目前的权宜之计。但要获得稳定的体验,通常还需折腾 HTTPS、内网穿透、DDNS 或 Cloudflare。
▍我的「万级」文件同步噩梦
我的 Obsidian 文档库包含 26,000+ 个文件,总体积接近 10GB。
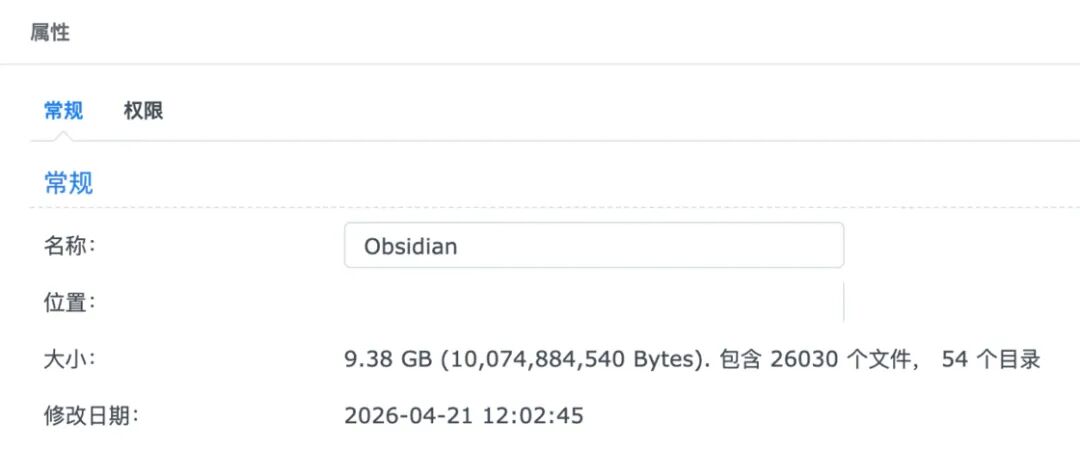 我的 Obsidian 文档库
我的 Obsidian 文档库
在这种规模下,单纯依赖 Obsidian 的前台插件同步,体验会呈断崖式下降。更棘手的是,常规插件方案很难像群晖官方 App 那样,根据网络环境(局域网 vs 公网)自动且智能地切换连接地址。
▍那么……
难道就没有一种方案,能让我们直接复用 QuickConnect 那种「开箱即用」的穿透能力与内外网自动切换逻辑,在免去繁琐穿透配置的同时,实现真正的文档库自动同步到任何地方?
为了解决这些切肤之痛,我开发了 SynoSync。它的目标非常明确:
彻底解决「群晖 + iOS」用户的文档库同步难题。
▍SynoSync 能为你做什么?
1. 多账号与多任务的灵活管理
支持配置多台 DSM: 完美适配拥有多套群晖环境的进阶用户。
支持多同步任务并行: 你可以针对不同的 App、不同的本地路径,创建多条上传、下载或双向同步任务,灵活构建你的同步方案。
2. 覆盖全场景的同步模式
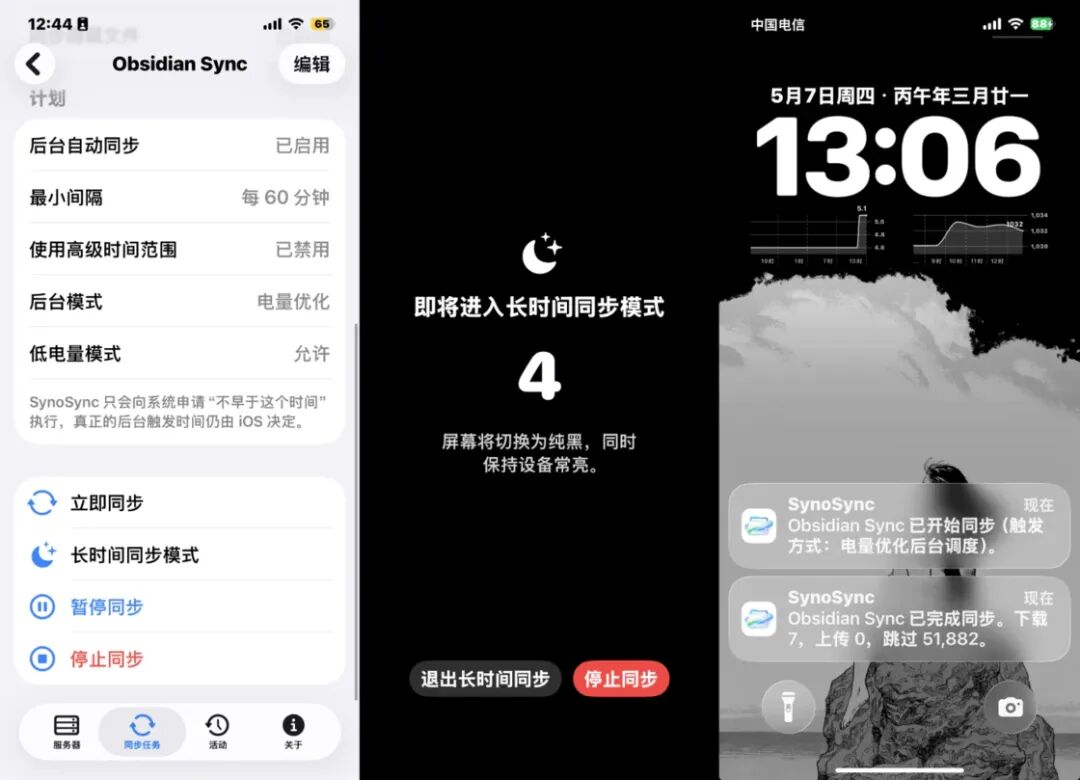 三种同步场景:App 内、长时间高效同步、后台同步
三种同步场景:App 内、长时间高效同步、后台同步
前台同步: 实时可见的极速同步。
大批量初始化: 针对首次同步或超大文件夹优化的传输模式。
后台静默同步: 无需干预,在系统允许的范围内自动对齐差异。
快捷指令触发: 联动 iOS 自动化,解锁更多高效玩法。
3. 直观的状态追踪
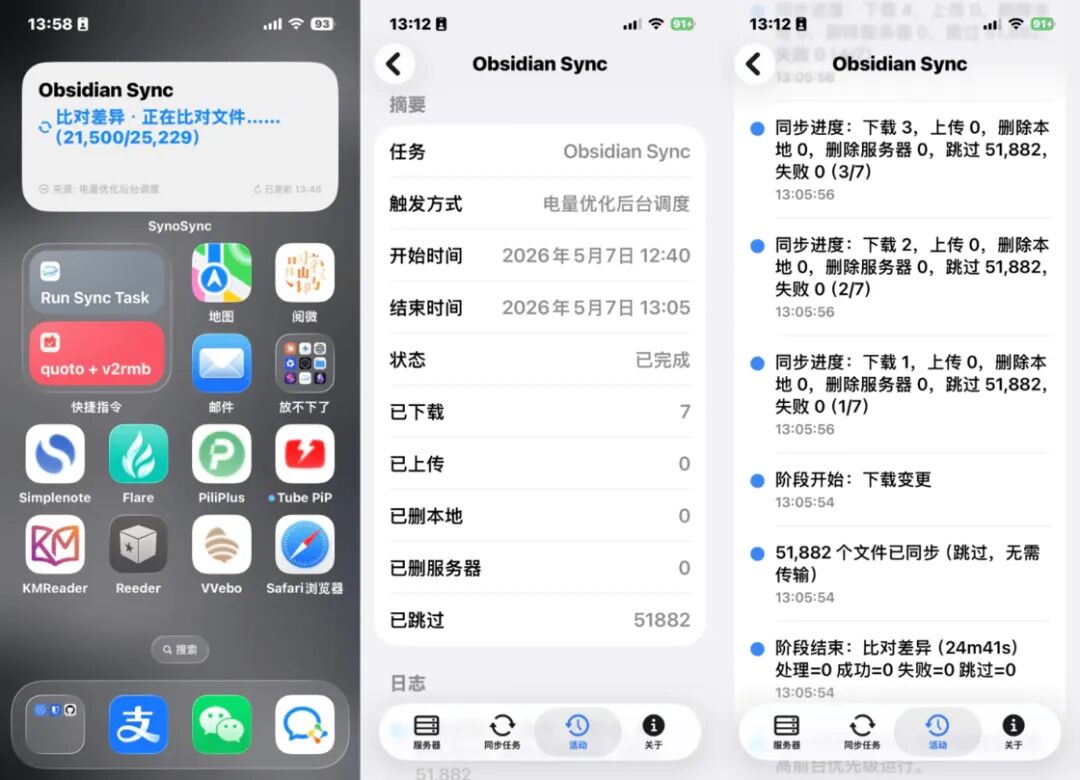 小组件刷新机制下信息更新较慢,你如果真的关心实时进度,还是打开 App 比较好
小组件刷新机制下信息更新较慢,你如果真的关心实时进度,还是打开 App 比较好
同步活动报告: 每一个文件的流转都清晰可查。
小组件支持: 无需打开 App,在桌面即可实时观察同步进度。
▍一些坦诚的局限性……
在开发 SynoSync 的这一个多月里,最让我抓狂的莫过于 iOS 严苛的后台机制。
众所周知,iOS 采用了近乎「墓碑式」的后台管理。对于 SynoSync 这种需要频繁进行网络请求、文件比对及高强度读写的 App 来说,后台环境极其不友好。为了实现优雅的「静默同步」,我尝试了各种姿势去突破限制,但必须承认:它的后台效果依然无法达到 Android 或 PC 端的随心所欲。
特别是在面对我那 2.6 万个文件的「巨型库」时,iOS 的后台限制会导致同步耗时拉长。
因此,SynoSync 提供的最终解法是:
先通过「前台大批量同步」完成沉重的初始化任务(批量上传|下载),后续的日常增量更新,则交给「后台比对」去静默完成。
如果你发现 SynoSync 发出了后台同步失败的通知,也不用惊慌,这只是 iOS 后台切断了 App 的后台网络权限(为了省电),SynoSync 会在下一个 iOS 允许的时间窗口重新尝试同步的。
🔗:https://apps.apple.com/cn/app/synosync/id6762731663

每年到了求职季或需要更新履历的时候,很多人的数字生活都会陷入一种隐秘的焦虑中。
面对市面上琳琅满目的在线简历生成器,你花了几个小时在网页上小心翼翼地填满了自己的教育背景、工作经历、项目细节,然而,当你排版完毕,满心欢喜地点击导出的那一刻,往往只会迎来一个令人崩溃的结局:屏幕上赫然弹出一个 “请扫码支付 9.9 元解锁 PDF 下载” 的二维码。
被 “绑架” 付费还只是表面的痛点。更让人后背发凉的是,就在你毫无防备地填写这些信息时,你的核心个人隐私和职业履历,早就悄无声息地变成了平台数据库里的大数据养料,随时准备被打包、分析,甚至出售给第三方机构。
作为一名对数据主权有着极度洁癖的开发者,我实在无法忍受这种将核心隐私拱手让人的体验。一份记录了我职业生涯全部心血的文档,它的最终归宿应该在我的本地硬盘里,而不是某个不知名公司的云端数据库中。
为了解决这个痛点,我决定为自己,也为所有在意数字隐私的人,打造一个足够干净、纯粹的工作台。这就是 优派简历(OpResume)。
▍真正的 Local-First:不妥协的数据主权
初次打开优派简历,你可能会觉得它 “少” 了点什么 —— 它没有注册按钮,也没有登录弹窗。
在这个万物皆需云同步的时代,优派简历选择了一条最老派却最让人安心的道路:100% 纯本地运行(Local-First)。
打开网页的瞬间,你的浏览器就是所有的后端。你在页面上敲下的每一个字,都只保存在当前设备的 LocalStorage 中。系统根本不存在用于存储用户简历的云端服务器,自然也就从根本上杜绝了隐私泄露的可能性。
这不仅仅是一个技术选型,更是一种数字生活态度:我的履历,只属于我自己。
那么,数据全在本地,换了电脑怎么办?
不用担心被平台绑架。在数据结构上,优派简历严格遵循了通用的 JSON Resume 开源标准。你随时可以把整份简历一键导出一份不到几十 KB 的 .json 文件备份到你的云盘。换了新设备,只需将这个文件拖拽导入,一切工作流即可无缝接力。
▍BYOK 模式:当 AI 遇上绝对隐私
不可否认,AI 已经是当下效率工具的标配。在写简历时,“如何用 STAR 法则提炼项目亮点” 或者 “如何润色这段工作经历”,是最让人头疼的环节。
但我面临一个巨大的逻辑冲突:既然承诺了没有后端,不碰用户数据,那我要怎么帮你调用大语言模型?如果我偷偷把你的经历传给云端 API,这无异于一种背叛。
最终,我选择将选择权完全交还给你 ——BYOK(Bring Your Own Key)模式。
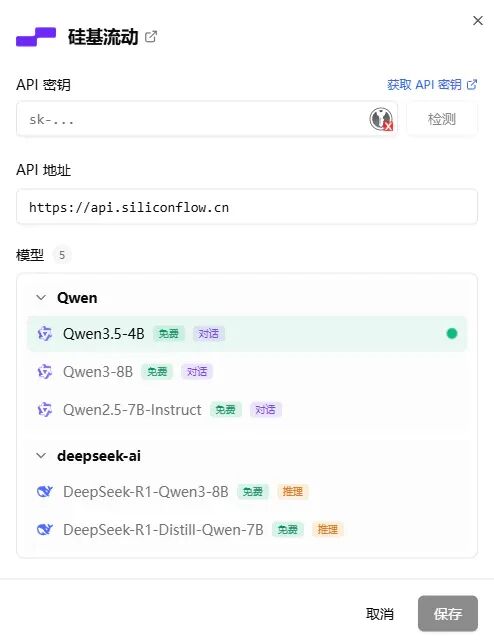
优派简历本身提供纯粹的客户端环境,如果你需要 AI 辅助,可以在设置中填入你自己申请的 API Key(目前我们已接入了「硅基流动 SiliconFlow」)。
只有当你主动划选一段苦思冥想的文本,并点击 “AI 润色” 时,这段特定的文字才会通过你自己的 Key 临时发送给大模型进行处理。
这是一种奇妙的体验:AI 依然在为你打工,但监工是你自己,而不是某个 SaaS 平台。 这种透明的机制,让我在处理敏感工作经历时感到前所未有的踏实。

▍拒绝折腾:所见即所得的极客美学
很多极客向的简历工具(比如基于 LaTeX 或 Markdown 的方案),虽然保障了隐私,但往往需要使用者与繁琐的语法和反人类的排版引擎作斗争。
我认为,写简历本该是一件顺滑、纯粹甚至有些享受的事情。在优派简历的交互设计上,我尽可能保留了现代化 Web 应用的轻盈感:
积木式拖拽排版: 哪里不对拖哪里,直观且符合直觉,让你把全部精力集中在内容的打磨上。
一键开启的隐私模式: 考虑到有时需要截图请教别人或在社区求职,应用内可以直接开启隐私模式,瞬间屏蔽掉姓名、电话、邮箱等敏感信息。
原生打印引擎,拒绝 “糊弄”: 很多平台为了防抓取,导出的 PDF 其实是由 Canvas 绘制的图片,不仅放大后文字边缘模糊,甚至无法被大厂的 ATS(招聘追踪系统)正确识别。优派简历直接调用浏览器原生的 Print 引擎,生成的 PDF 矢量清晰,文字可精准复制。
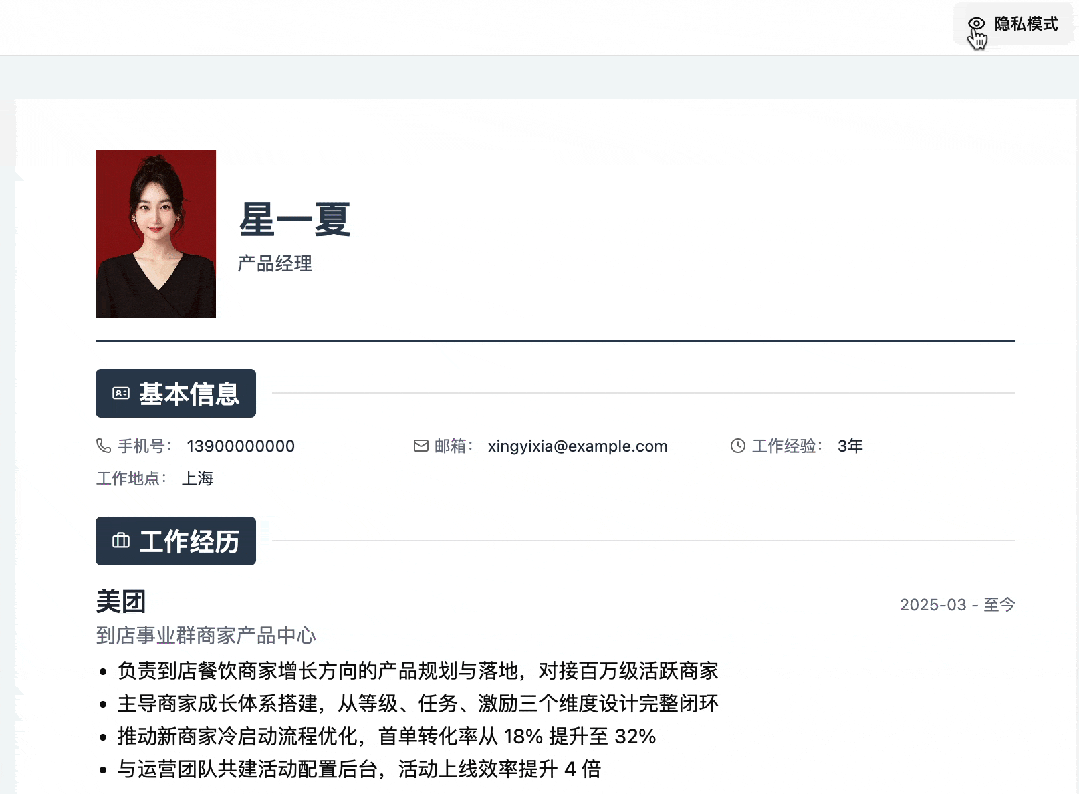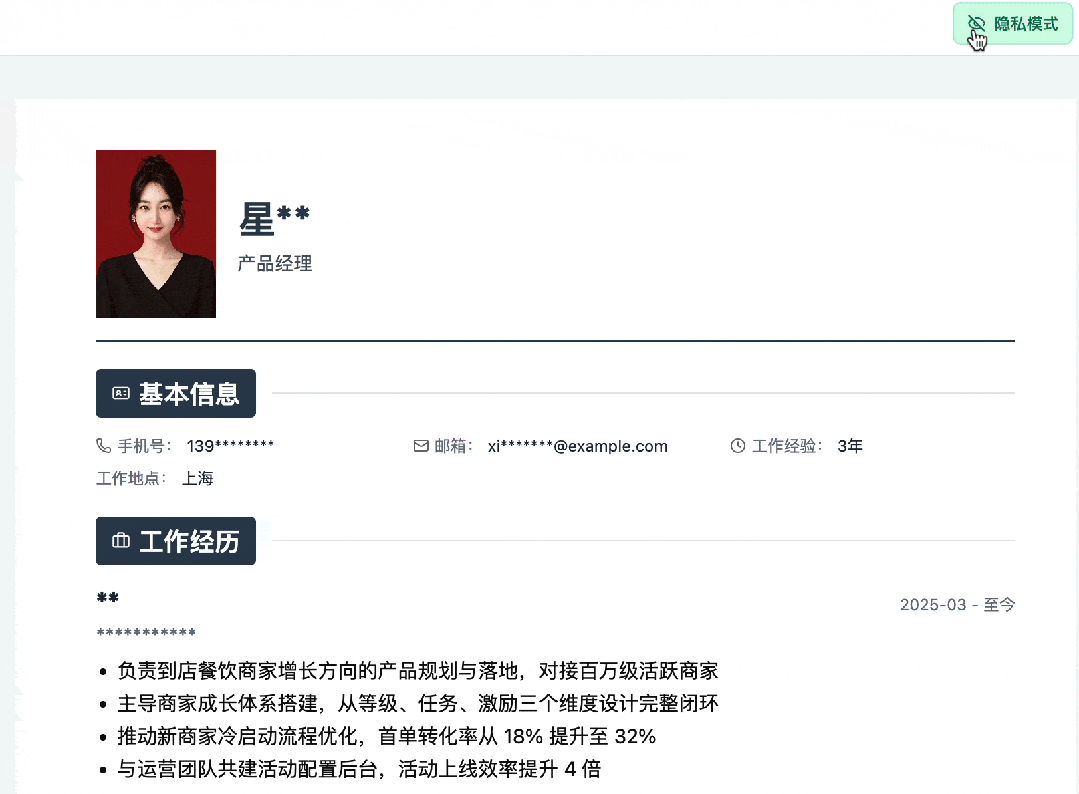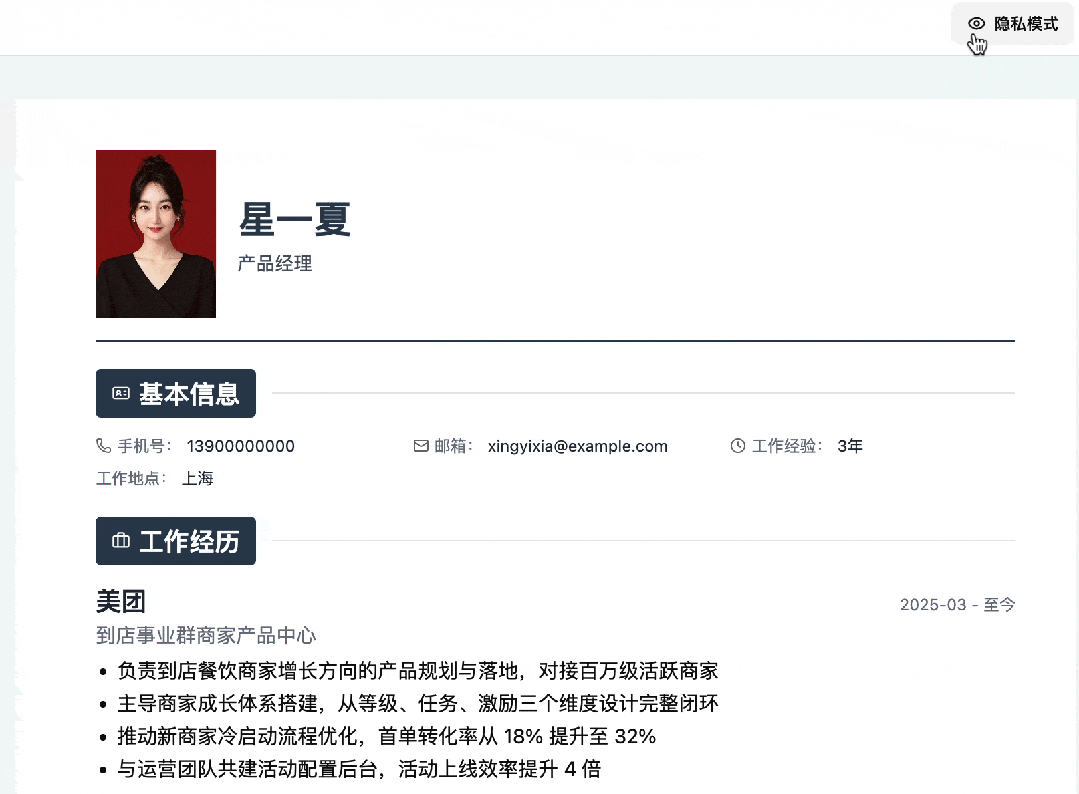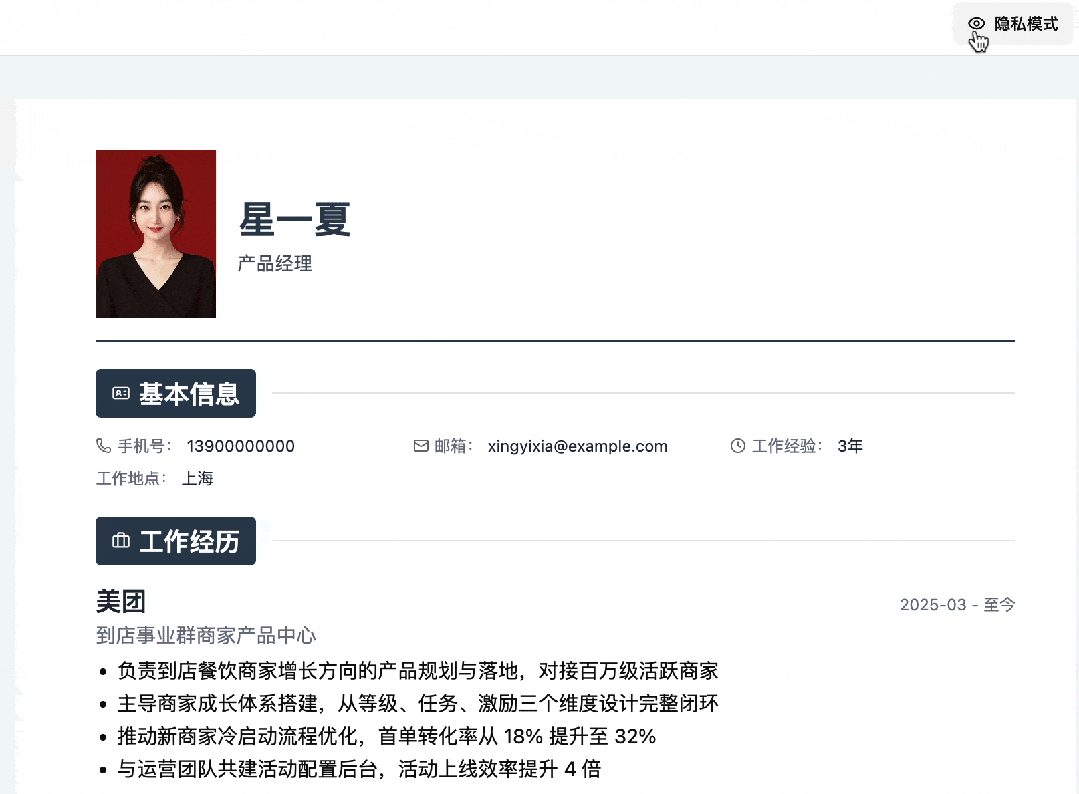
▍写在最后
优派简历从最初的想法,到现在 v1.3.0 版本的迭代,始终围绕着 “隐私” 与 “掌控感” 这两个关键词。它可能没有那些商业 SaaS 平台花哨的主题模板库,但它为你提供了一个绝对安全、不用担心被偷窥的角落,让你能够静下心来,认真审视自己过去几年的职业轨迹。
在这个 “隐私极其廉价” 的时代,如果你也苦于信息泄露,或者厌倦了那些层出不穷的付费套路,不妨来试试这个为你准备的专属工作台。
完全开源,纯粹免费。
👉 在线体验(点开即用,无需登录): 在线使用
💻 GitHub:仓库地址(如果你觉得这个项目不错,欢迎给个 Star 支持一下)
如果你在使用过程中遇到任何问题,或者对接入更多 AI 生态有好的想法,欢迎在评论区与我交流。希望优派简历能帮你拿下心仪的 Offer。
我经常遇到一种很具体的遗忘:明明知道自己之前在手机上看到过某个东西,却完全想不起它来自哪个 App、出现在哪一天、存在于哪个页面。更麻烦的是我通常没有截图来帮我回忆,那些内容只是当时恰好看到,没有收藏、没有转发、也没有写进笔记。
后来想找,连一个可以回去的入口都没有。
一开始我只是觉得烦,后来我慢慢意识到,这件事可能比「找不到截图」更大一点:如果将来每个人都能拥有自己的 AI 助手,它能不能理解你不只取决于模型有多强,也取决于你给它留下过多少真实的上下文。今天没有留下来的东西,明天很难补上。
所以我开始做屏忆(ScreenMemo),一个开源的本地屏幕记忆工具:自动记录屏幕内容,然后通过 OCR、搜索、时间线、每日总结和 AI 回顾,把那些原本滑走、然后遗忘的内容,变成可以找回的线索。
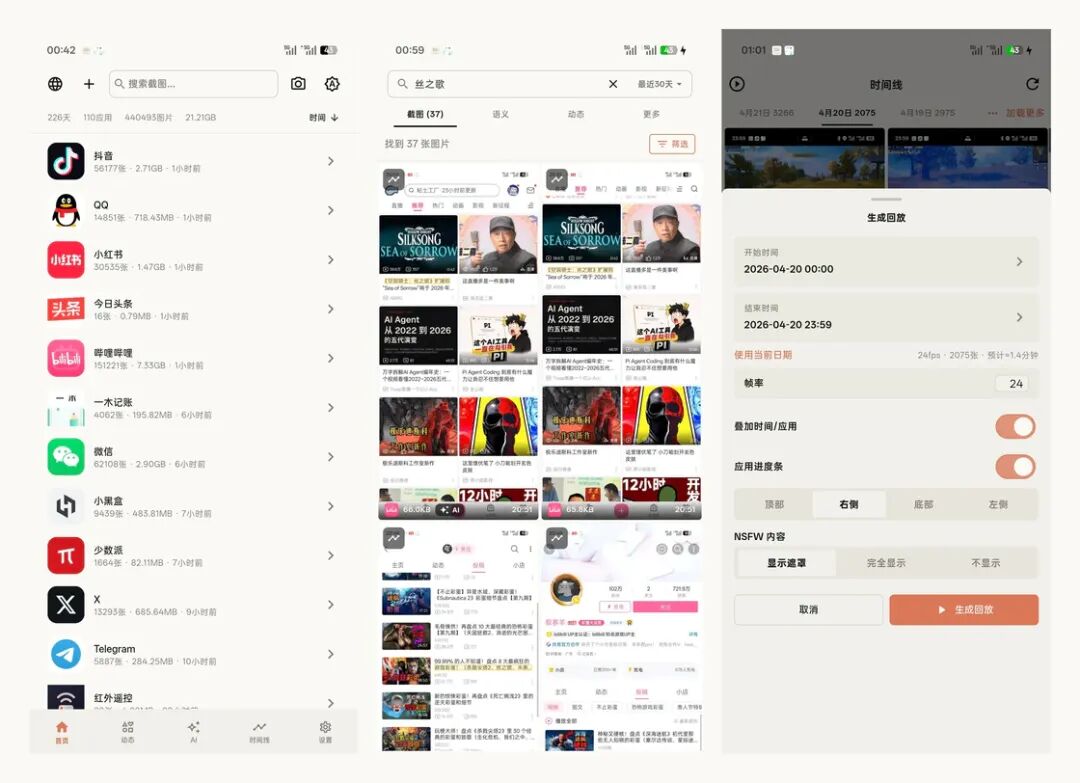 屏忆会按应用组织已经记录下来的屏幕内容。对我来说,先有一个能回到过去画面的入口,比一开始就追求复杂整理更重要。
屏忆会按应用组织已经记录下来的屏幕内容。对我来说,先有一个能回到过去画面的入口,比一开始就追求复杂整理更重要。
屏忆的基础工作流程并不神秘:通过无障碍服务定时截屏,然后把截图保存在本地,同时记录当前应用、时间和路径;对截图做 OCR 并建立本地索引后,在 App 里提供搜索、图库、收藏、时间线、动态总结、每日总结和 AI 回顾。
它最直接的场景,是找回那些你觉得「我明明看过」、但记忆相对模糊的内容。
比如昨天在信息流里刷到过一个有用的方法,隔天想再看时却发现没有收藏,想不起作者、也想不起标题。放在过去,我大概会翻浏览记录、重新搜关键词,或者干脆等它哪天再次被推荐。
屏忆的做法更粗暴一点:如果当时屏幕被记录下来,OCR 文本进入了本地索引,之后就可以搜索那几个模糊的关键词,再回到对应截图确认。
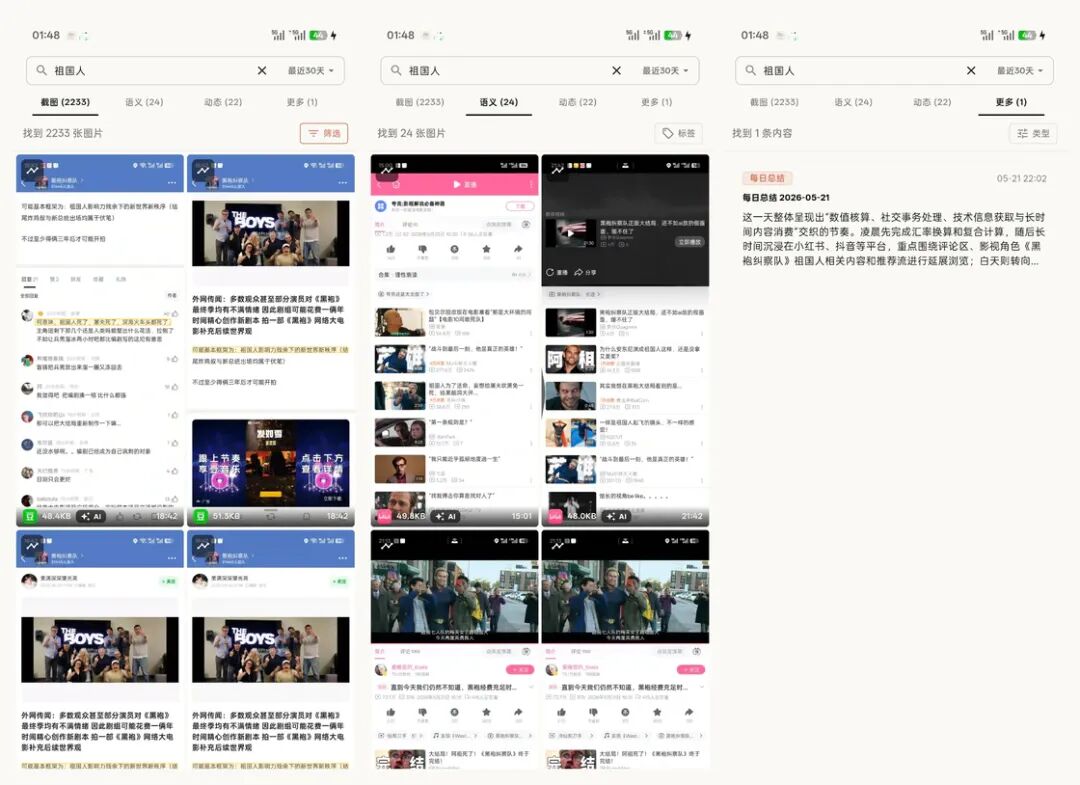
第二种情况是找回一段过程。
有些操作不是一张截图能说明白的。注册、登录、授权、付款、查询、客服沟通,都可能跨过好几个页面。单张截图只能告诉你某一刻屏幕上有什么,时间线能把前后关系补回来。屏忆支持按时间回看,也可以生成回放,用来还原一次操作路径。
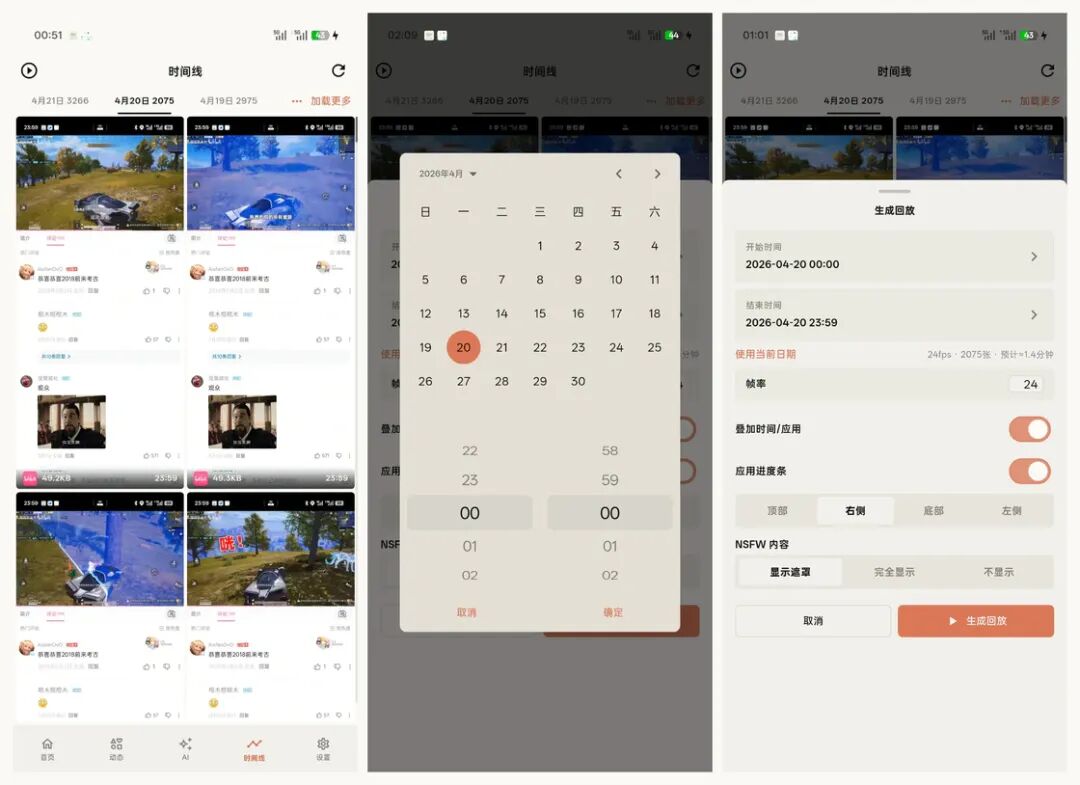 单张截图解决「那一刻有什么」,时间线和回放更接近「当时我是怎么走到这里的」。
单张截图解决「那一刻有什么」,时间线和回放更接近「当时我是怎么走到这里的」。
还有每天的回顾。
如果你一直在手机上查资料、沟通、处理事情,屏幕内容本身也会留下了不少线索。每日总结不是日记,只是先把一天里零散的记录整理成一份能读的摘要。它不一定深刻,但至少能回答一个朴素的问题:今天我大概看过什么、处理过什么。
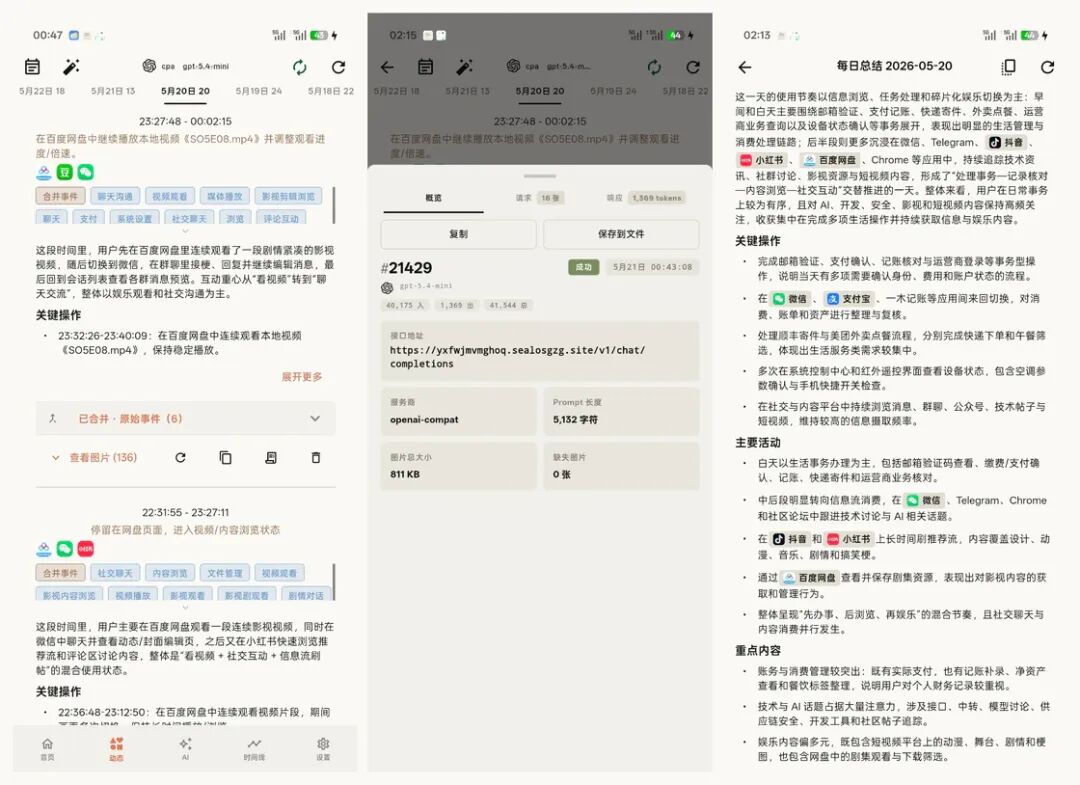
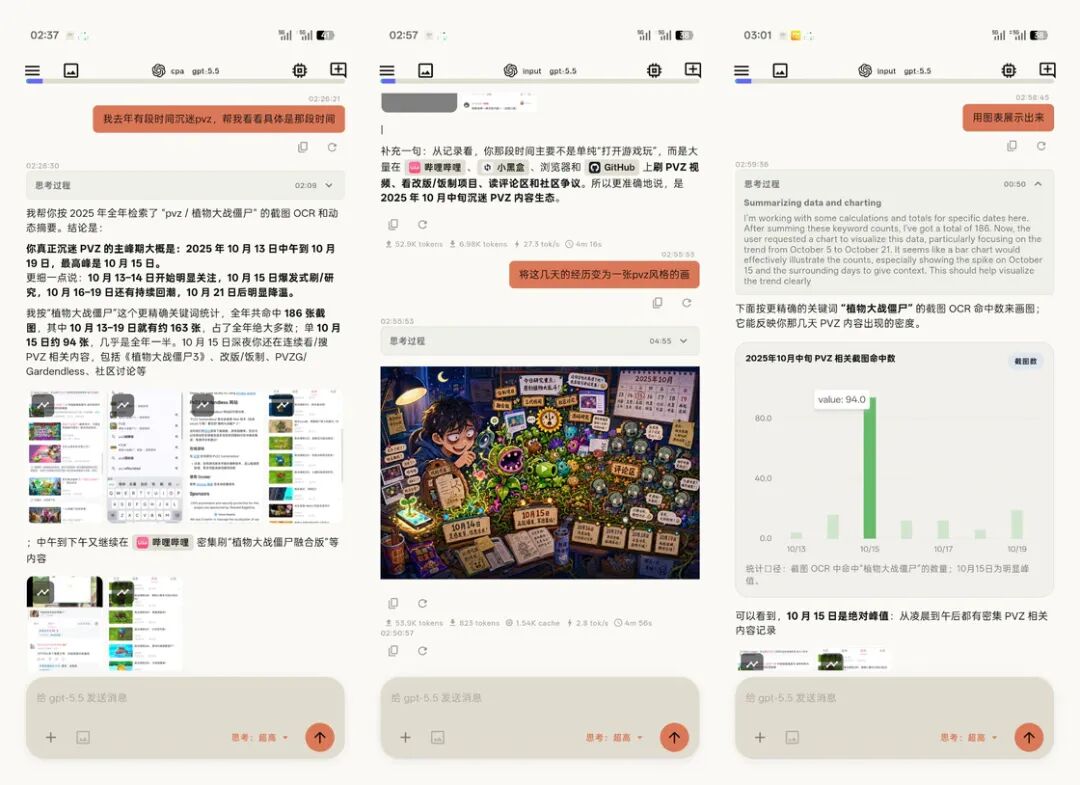
AI 回顾也是类似思路。
普通 AI 助手并不知道你昨天在手机上看过什么。屏忆在你配置 AI 提供商后,可以基于截图、动态总结、上下文片段和你明确选择的证据图片做回顾。你可以问它「下午那段流程大概在做什么」,也可以让它帮你从一组截图里整理出重点。这里的 AI 不是凭空聊天,它只会将你已经留下的屏幕线索作为上下文。
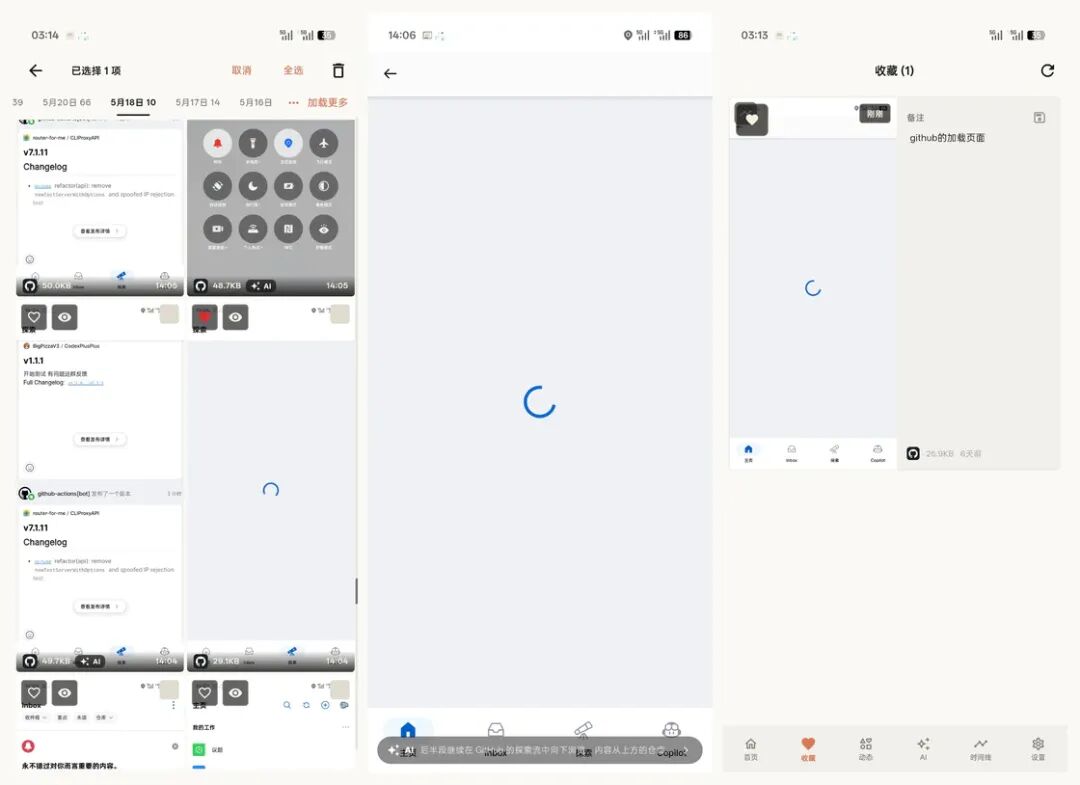
最后,屏忆也支持收藏和备注。自动记录负责兜底,但有些内容还是要人来标一下,看到值得留下的截图,你可以加一句自己的说明。这个功能小但必要,自动记录再多也替代不了人的判断。
如果要找一个参照物,屏忆和一些桌面端自动记录屏幕的工具有点像。比如我经常想到 Rewind,它早期的方向和屏忆很接近,记录 Mac 上看过、听过的内容,再用 OCR 和语音识别做搜索。这个想法很诱人,也确实说明桌面端早就有人在尝试「屏幕记忆」。只是后来的故事有点复杂:Rewind 在 2024 年转向 Limitless,开始做会议记录和录音吊坠;2025 年被 Meta 收购后,Limitless 官方说明写明 Rewind 应用会逐渐停止运营,最新版从 2025 年 12 月 19 日起已经禁用了屏幕和音频捕获。
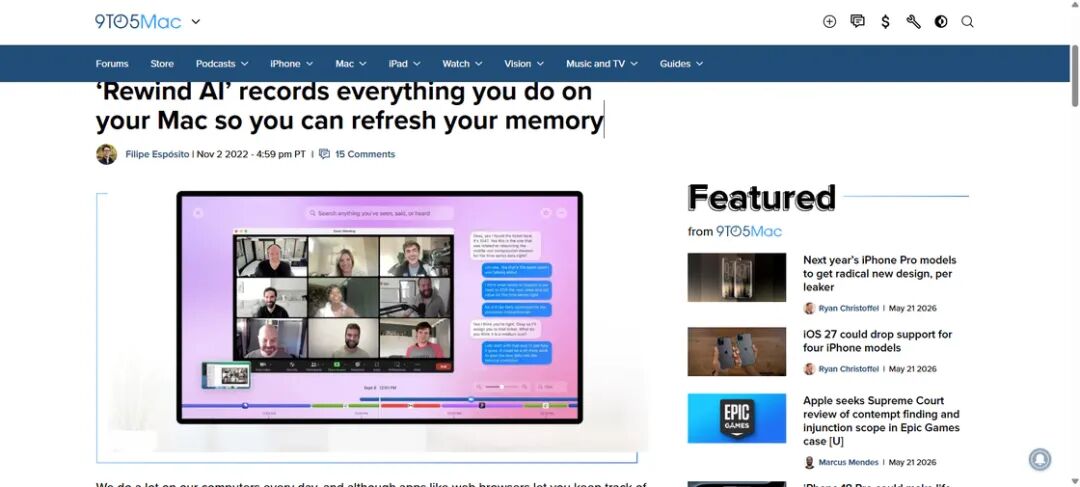 Rewind 早期主打「记录你在 Mac 上做过的一切」,这和屏幕记忆的方向很接近。
Rewind 早期主打「记录你在 Mac 上做过的一切」,这和屏幕记忆的方向很接近。
Rewind 的事不是一句「产品失败」就能概括的,商业产品会转向、会被收购、会砍掉特定功能,开发团队有自己的选择。但对个人记忆库来说,这些「意外」的影响会变得十分具体,它们的理想状态是长期记录,但这些产品本身未必长期存在。
后续微软的 Recall 则补上了另一层提醒:它同样想把电脑上出现过的内容做成可搜索的时间线;2024 年遇到隐私和安全方面的质疑后,微软在官方博客里说,Recall 会先进入 Windows Insider 计划,而不是直接随 Copilot+ PC 面向用户提供预览。大公司也绕不开这个问题:只要工具会持续记录屏幕,信任就会跑到功能前面。
 这张图提醒我:个人记忆工具如果完全依赖闭源产品,生命周期本身就是风险。
这张图提醒我:个人记忆工具如果完全依赖闭源产品,生命周期本身就是风险。
在手机上几乎没找到同类工具的前提下,偏偏很多最零碎、最容易丢的上下文又都发生在手机上:聊天、搜索、信息流、支付、设置、临时打开的网页。这便是屏忆开发的初心。你的屏幕里可能有聊天、订单、账号、位置、支付流程、工作资料和临时验证码,有了 Rewind、Recall 等功能的「前车之鉴」,屏忆在设计理念上强调本地保存和开源,截图、OCR、索引和大多数配置默认留在本地;代码、实现方式和隐私边界你也能直接在 GitHub 仓库里看到。本地优先也意味着用户必须能把数据带走,屏忆支持导出 ZIP 备份,导入时提供覆盖导入和合并导入。
 Recall 的官方说明里也把「快照」「本地保存」「权限控制」放在很前面。只要工具会记录屏幕,信任问题就不会是附属问题。
Recall 的官方说明里也把「快照」「本地保存」「权限控制」放在很前面。只要工具会记录屏幕,信任问题就不会是附属问题。
屏忆还提供隐私模式、敏感内容分析和 NSFW 相关能力。这不是猎奇功能,而是长期记录屏幕以后必须面对的问题。一个记忆工具不能只会保存,也要能遮挡、限制和删除。
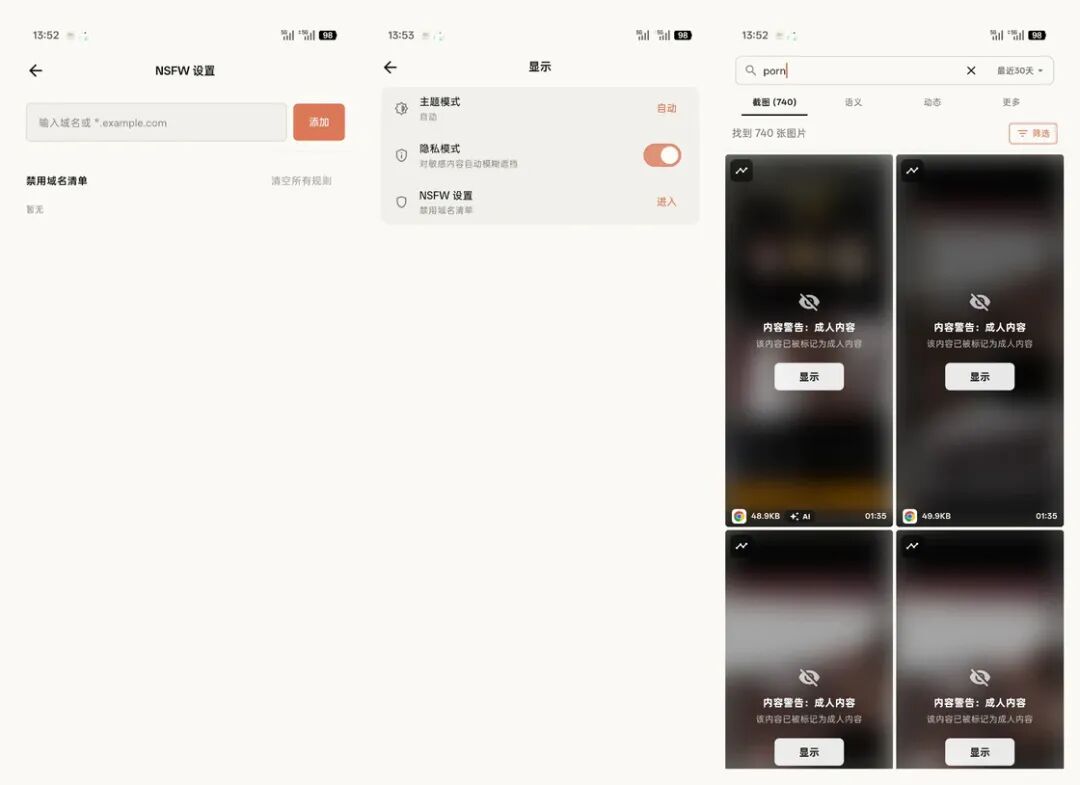
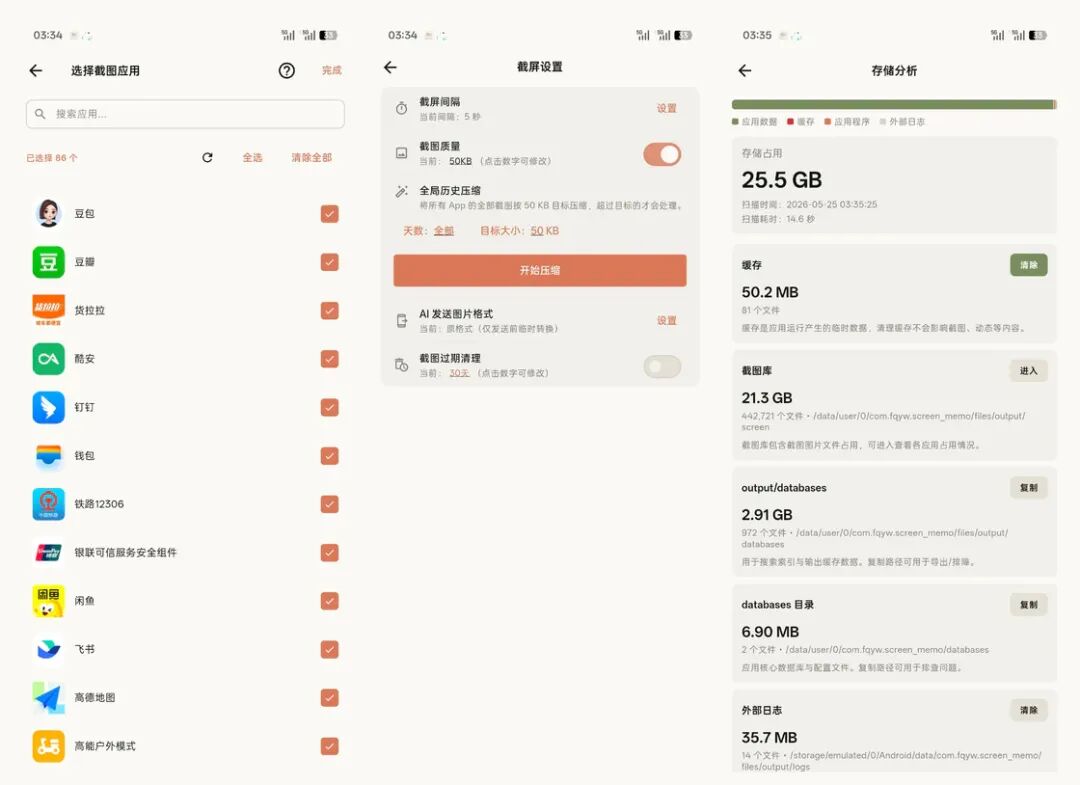
存储方面,自动截图的数据是长期增长的,按压缩后约 50 KB 一张、每分钟一张粗算,30 天大约是 43200 张截图,约 2.1 GB。这个数字不算夸张但会持续增长,所以屏忆不能只负责保存。它还要提供目标大小压缩、历史压缩、过期清理、存储分析和按应用策略。你可以只记录真正需要的 App,也可以定期清理不再需要的截图。
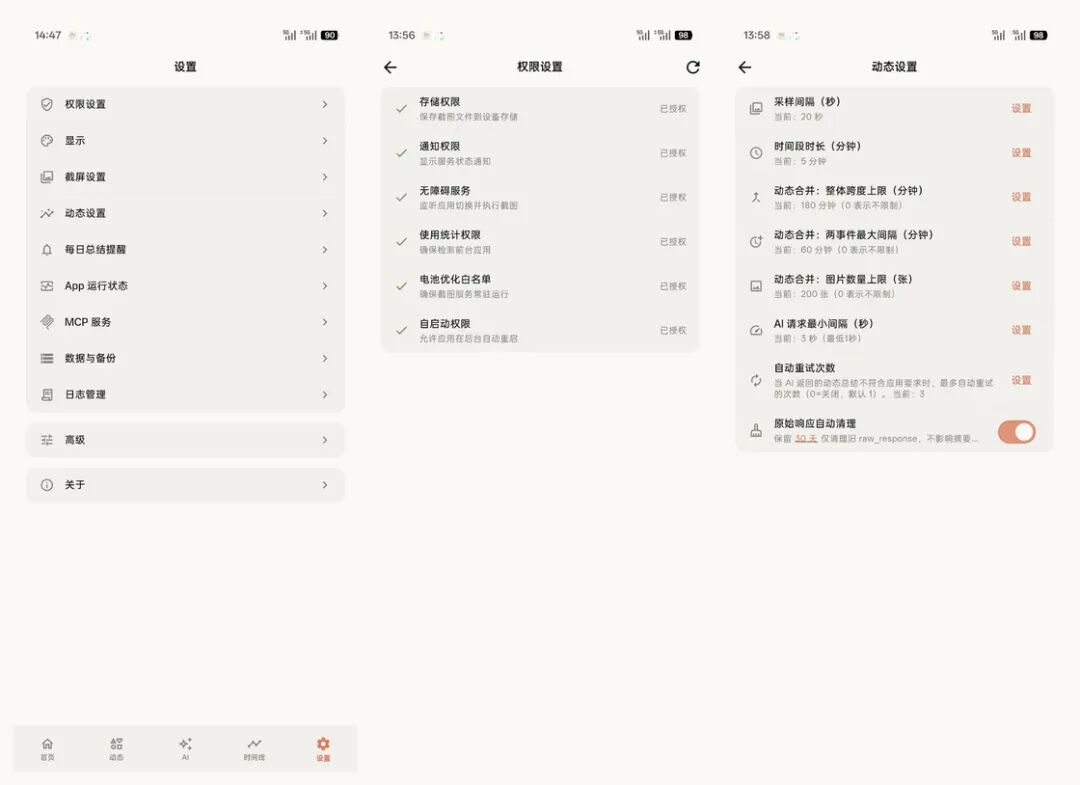
屏忆的设置页自上线以来变得越来越长,一开始我也有点犹豫:设置太多会不会显得复杂?但做了一段时间后,我觉得这些开关不能省。
因为屏忆记录的是屏幕,很多选择不应该由工具替用户决定:哪些 App 要进入记忆库、哪些内容需要自动遮挡、AI 请求发给哪个模型、提示词怎么写、请求日志要不要保留…… 甚至要不要把本地记忆通过 MCP 暴露给同一局域网里的 AI 客户端,这些都应该是明确的选择,而不应该藏在默认行为里。
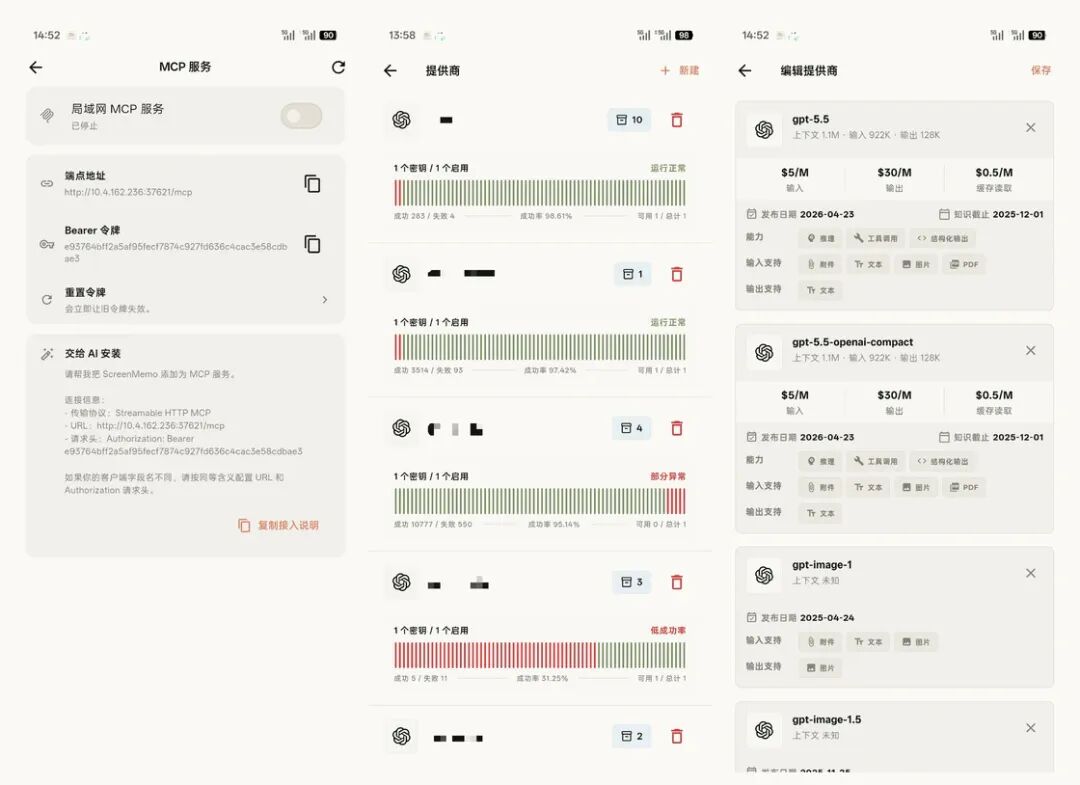
所以屏忆把 AI 能力被做成了可选项。只有在你启用 AI 并配置提供商后,相关总结或对话请求才会发往你配置的模型服务。这会增加配置门槛,但我更愿意把选择权留给用户,你可以配置 OpenAI、Claude、Gemini 或兼容接口的服务,也可以调整 Prompt,查看请求日志和工具调用报告。这样做不如「打开即用」顺滑,但出了问题时,你至少知道一次总结用了哪些图片、发给了哪个模型、返回了什么结果;MCP 服务也是同样的思路,它可以让桌面端 AI 客户端读取手机里的摘要、搜索结果和少量证据图片,但需要手动开启,只在局域网内工作,并且带 token。
做屏忆之后,我越来越觉得「记住」不是一个单点功能。只做自动截图,会变成图片堆;只做 AI 总结,会缺少证据;只强调本地保存,又必须面对备份和迁移;只强调找回,也要承认有些内容应该被清理。
屏忆现在做的这些功能,本质上都在围绕同一件事:让屏幕上发生过的事,在未来还能有线索可循。
所以它也不会只停在手机端。目前我正在做桌面端,一方面是为了处理更大的备份、合并和迁移任务,另一方面也是希望把手机里留下的记录带到更适合整理、检索和写作的环境里。手机负责捕获那些稍纵即逝的画面,桌面负责承接更长时间尺度上的整理和回看。
更远一点,我希望屏忆能逐步适配更多平台。不是为了把所有设备都塞进同一个 App,而是让记录、搜索、回顾、备份和迁移之间形成一条更完整的链路。你在不同设备上看到过的内容,不应该因为换了设备、换了系统、换了应用入口,就彻底断掉。
屏忆现在才刚刚起步。它还需要更好的兼容性、更稳定的后台、更清晰的隐私控制、更顺滑的搜索体验和更丰富的回顾方式。但从今天开始,把一部分屏幕记忆留在自己手里,我觉得已经是一件值得做的事。
如果未来真的会有更懂我们的个人 AI,它需要的不只是更强的模型,也需要足够真实、足够连续、并且仍然由自己掌握的上下文。屏忆想做的,就是先把这些上下文留下来。
🔗:https://github.com/2977094657/ScreenMemo?source
/ 欢迎投稿 /

/ 更多热门文章 /


/ 产品推荐 /


