 夜雨聆风
夜雨聆风【导读】今天早上我在 AI HOT 日报里刷到一条:腾讯混元开源翻译模型 Hy-MT2。
今天早上我在 AI HOT 日报里刷到一条:腾讯混元开源翻译模型 Hy-MT2。
我一直觉得,AI 圈最容易被低估的能力不是写代码、不是画图,而是翻译。
翻译这件事太“基础设施”了:你平时感觉不到它的存在,但一旦没有,你才发现自己每天要多绕多少路——看论文、刷 GitHub issue、做海外产品、追剧字幕、甚至跟海外客户对齐一个词到底该怎么译。
所以我看到腾讯混元把一套专用翻译模型 Hy-MT2 直接开源出来的时候,第一反应不是“又一个大模型”,而是:
终于有人把翻译从“按次计费的 API”往“能装进本地的工具”方向,认真推了一步。
(我这篇只写我查到的事实和我自己的判断;没有我亲测跑通的地方,我会明确说“我没跑”。)
IT之家报道截图:腾讯混元 Hy-MT2 开源与端侧部署相关介绍
---
01
一句话:Hy-MT2 能帮你干什么?
你给它一段文本(甚至带格式、带术语约束、带风格要求),它给你一段更“工程可控”的译文——而且这套能力不是只能买 API,它是 开源、可本地部署 的。
下面我再把关键信息说清楚。
02
先把关键信息摊开:Hy-MT2 到底开源了什么?
Hy-MT2 是一组“专用翻译模型”,不是那种“啥都能聊两句”的通用聊天模型。
它们的几个关键点,我觉得值得普通人也知道:
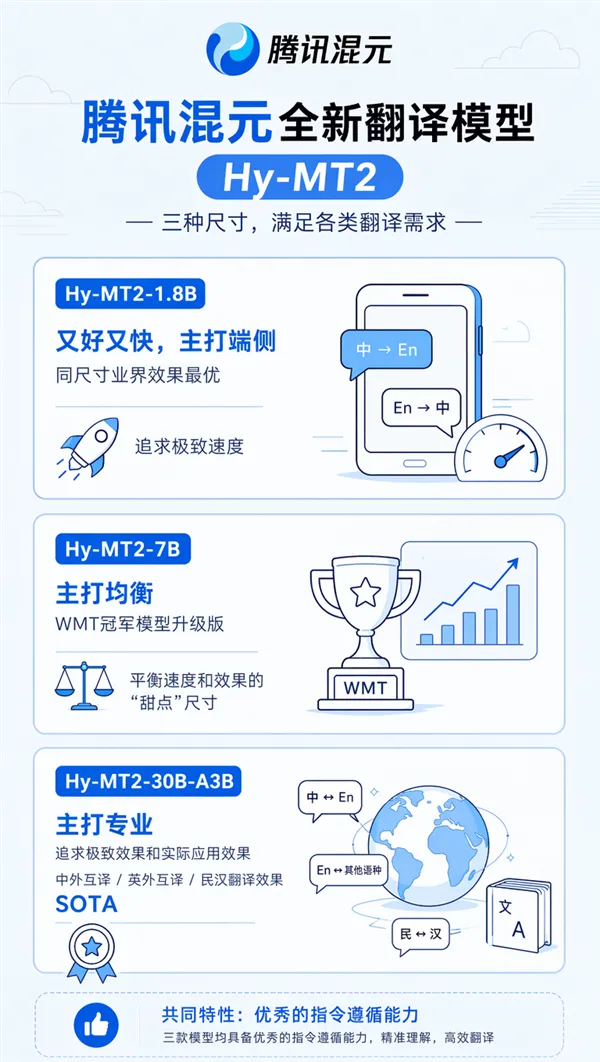
1. 什么时候开源:他们在 2026 年 5 月 21 日宣布开源(模型与 IFMTBench),arXiv 论文同日提交。 2. 三个尺寸:1.8B、7B、30B-A3B(MoE)。 3. 支持 33 种语言互译,并且强调“翻译指令遵循”(比如术语表、格式保留、风格要求这种)。 4. 最戳我的是 1.8B 的极限量化:官方说配合 1.25-bit 量化后,模型体积能到 440MB,并且推理速度还能提升 1.5×。 5. 许可证:Hugging Face 的模型卡显示为 Apache-2.0。 6. 除了模型,他们还顺带开源了一个用来评测“翻译指令遵循能力”的基准 IFMTBench。
如果你只记一句话: 这是一次把“翻译能力”从黑盒 API 拉回开源生态的动作,而且它是可部署、可本地化、可量化的那种。
---
03
我为什么说“翻译模型”值得单独写一篇?
很多人会下意识觉得:现在大模型都能翻译了,还需要专门的翻译模型吗?
我理解这个疑问,因为你在 ChatGPT / Claude / 任何大模型里输一句“翻译一下”,体验都不错。
但真正痛点通常出现在三个场景:
1)你要“保持格式”,而不是“把意思说对”
比如:
- 你在翻 SRT 字幕,时间戳和标记不能乱。
- 你在翻 产品文案,变量
{xxx}不能丢。 - 你在翻 表格/JSON,结构不能动。
这种时候,通用模型经常会“好心帮你改格式”,然后你就开始补锅。
Hy-MT2 这类专用模型把“翻译指令遵循”当成卖点,本质上就是盯着这些真实工程场景在做。
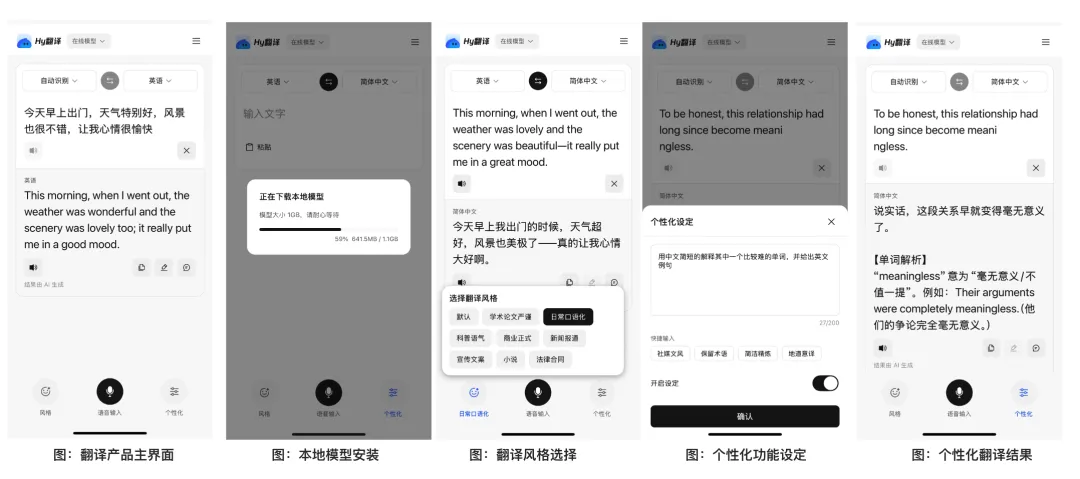
IT之家示例截图:通过“风格/长度”等约束让翻译更像工程输出
2)你要“术语统一”,而不是“每句都像人话”
做过出海的人都懂:你最怕的不是翻得烂,是同一个词在不同页面翻成三种写法。
Hy-MT2 的 README 里直接给了“术语干预”的提示词模板(中英两版),这点很实用。
3)你要“离线/私有”,而不是“随便翻翻”
如果你翻的是客户合同、公司内部文档、隐私数据,你就会开始纠结:
- 我到底要不要把这段内容丢进外部 API?
- 我能不能在本地跑一个可用的翻译系统?
这时候,“440MB 的离线翻译模型”这件事就很有意义了。

IT之家截图:腾讯 Hy 翻译小程序/端侧离线翻译相关展示(示意)
---
04
一张图:它的成绩单(我看完这张图才决定写它)
我最喜欢这种“官方自己把对比图放出来”的开源项目——你可以质疑它的设定,但至少它给你一个明确的对照坐标系。
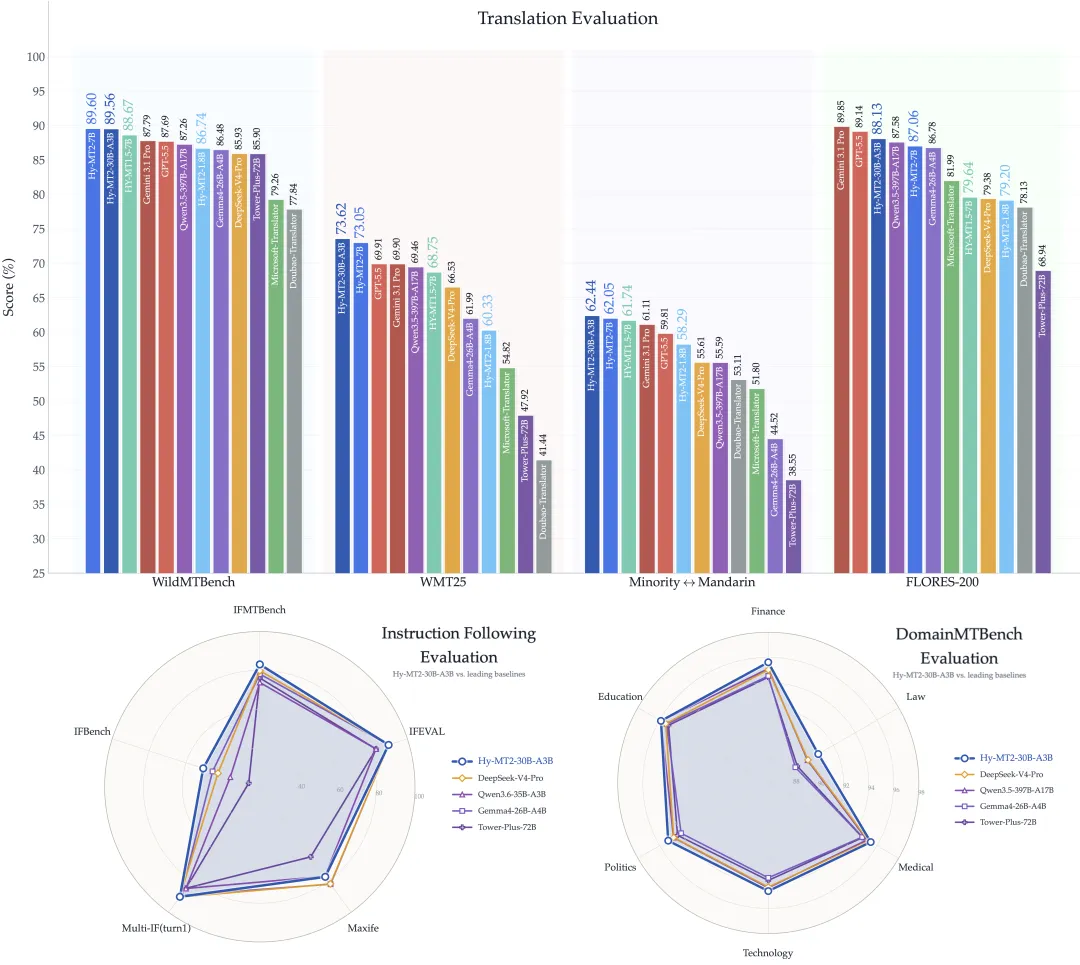
Hy-MT2 官方对比图(来自 Tencent-Hunyuan/Hy-MT2 仓库)
这张图本身不代表你实际使用一定会怎样,但它给了我两个信号:
- 他们把“翻译”当成一个可以正经卷 benchmark 的方向,不是顺手做做。
- 他们非常强调“指令遵循/真实业务/领域翻译”这种更难的评估维度,而不是只比“日常句子翻得顺不顺”。
---
05
如果你想用:我建议你从 1.8B 开始(而不是上来就追 30B)
我没在本机亲测跑通 Hy-MT2(因为我这边命令行环境 DNS 有问题,拉不下模型文件),但从官方给的信息看,入门路径很清晰:
- 1.8B:更像“能装进工具箱”的版本,重点是量化和端侧。
- 7B / 30B-A3B:更像“公司/团队要做翻译系统”的版本,追求上限。
官方在 Hugging Face 的模型卡里也给了 Transformers 的加载示例(我原样贴在这里,方便你少走一步弯路):
python from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("tencent/Hy-MT2-1.8B") model = AutoModelForCausalLM.from_pretrained("tencent/Hy-MT2-1.8B")
另外一个很现实的小坑:Hugging Face 的页面提醒,transformers v5 里 pipeline("translation") 不再支持,得么直接加载模型,要么降回 v4。
---
06
一个最小闭环:先把“术语 + 格式不乱”跑通
如果你想把它真正变成自己的基础设施,我建议不要一上来就追“翻得像母语”。
先跑一个更实用的闭环:
1. 找一段你最常翻的材料(比如英文产品更新、技术文档、SRT 片段)。 2. 写一个“术语表”(5–20 个就够),强制它按你习惯的译法来。 3. 加一条“格式规则”(比如分隔符、占位符必须保留)。 4. 连续翻 20 次,看看它会不会在第 3 次开始手滑、改格式、漏符号。
这套闭环如果能稳定跑住,你再去考虑更复杂的“长文一致性”“风格迁移”“多轮上下文”等问题。
---
07
我更关心的不是“翻得准不准”,而是它会把什么事情变得更便宜
翻译模型如果只是“更强一点”,其实很难激起我的写作欲望。
我更在意的是:它能不能让一些原本昂贵的动作变得便宜,甚至变成“默认动作”。
我脑子里现在已经冒出了三类玩法:
1. 字幕本地化流水线:ASR → SRT → 翻译 → 回灌剪辑软件。 2. 跨语种资料搜集:把日语/西语/俄语论坛资料批量翻成中文,再做二次筛选。 3. 私有文档翻译:公司内部知识库、合同、客户材料,在内网/本地完成,减少合规焦虑。
这些东西过去当然也能做,但成本高、链条长、出错多,所以大部分人不会把它变成“默认工作流”。
而一旦“翻译”变成你能本地跑、能术语控制、能格式稳定的能力,它就会变成很多工作流的胶水。
---
08
说点冷水:这类开源翻译模型真正会卡在哪?
我觉得至少有三件事要提前想清楚:
1. 你到底需要什么质量:日常阅读理解、正式文书、还是出版级?这三件事对模型和流程的要求完全不同。 2. 你能不能把“术语表”变成资产:术语表如果维护不起来,翻译质量会飘。 3. 离线不等于无成本:端侧跑得起来是一回事,速度、耗电、内存、集成体验又是另一回事。
Hy-MT2 这次给的信号很强,但我不会把它写成“从此天下无敌”。
我更愿意把它看成:翻译正在成为一种“可部署能力”,而不是“买 API 服务”。
---
09
我最后的判断:Hy-MT2 这种东西,会先在“内容/产品/出海”的人群里爆发
如果你是做内容的、做出海产品的、做跨境电商的,或者你就是那种每天要读一堆英文资料的人——
你会很快理解“翻译模型开源”这件事真正的价值:
它不是给你一个更强的玩具;
它是在告诉你:翻译这件事可以被你自己控制,可以被你自己接进工作流,可以变成你的个人基础设施。
我接下来会做的一件小事,是整理一份“我自己的术语表”,先把它当成资产养起来。
如果你也有兴趣,建议你先从 1.8B 那个版本开始,跑通最小闭环: “一段文本 → 有术语约束的翻译 → 格式不乱 → 可批量”。
能做到这一步,你就会知道它是不是你的菜。
