当前时间: 2026-05-29 14:01:14
分类:办公文件
评论(0)
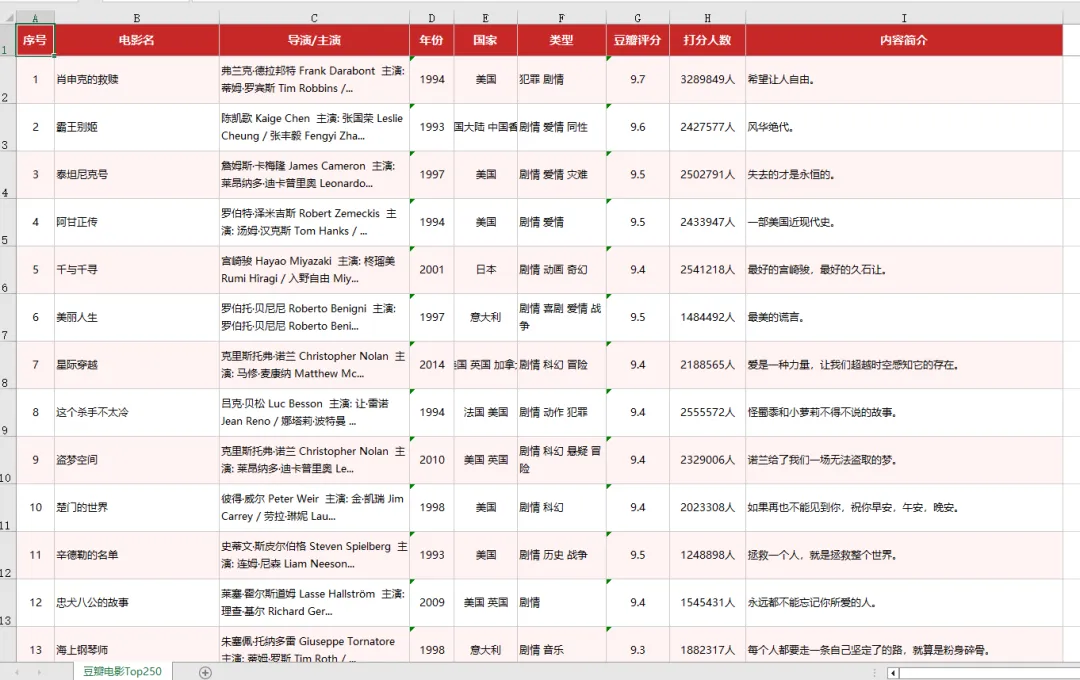
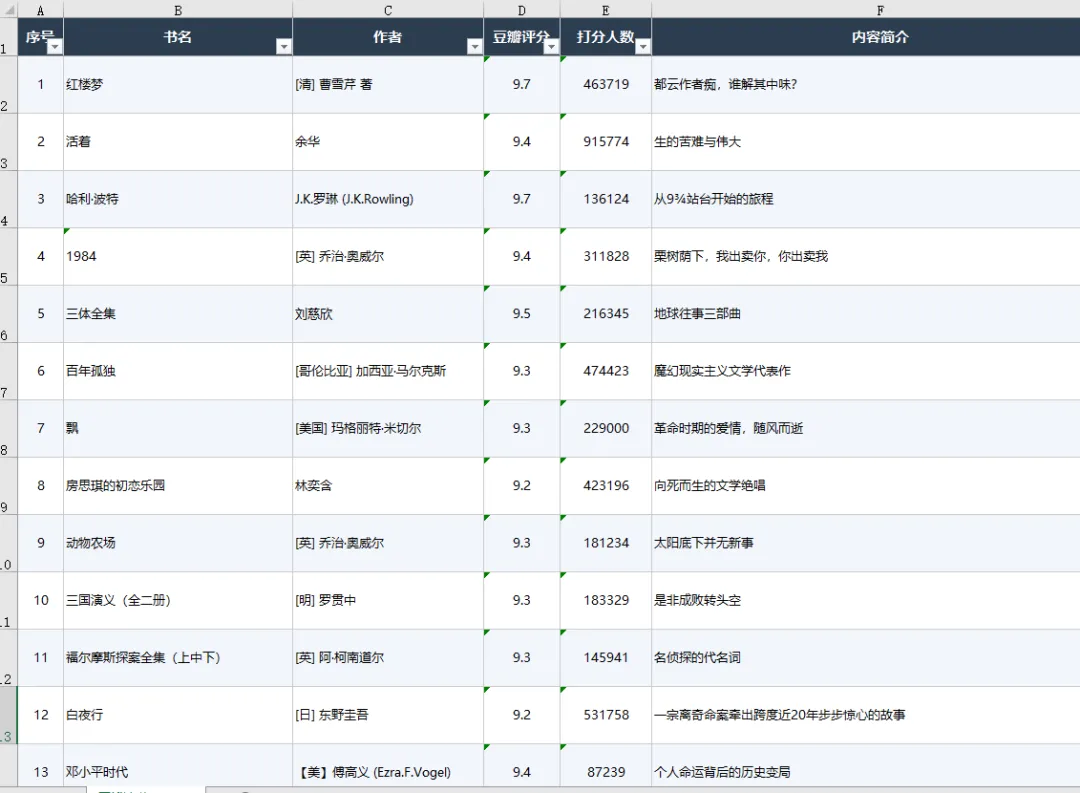
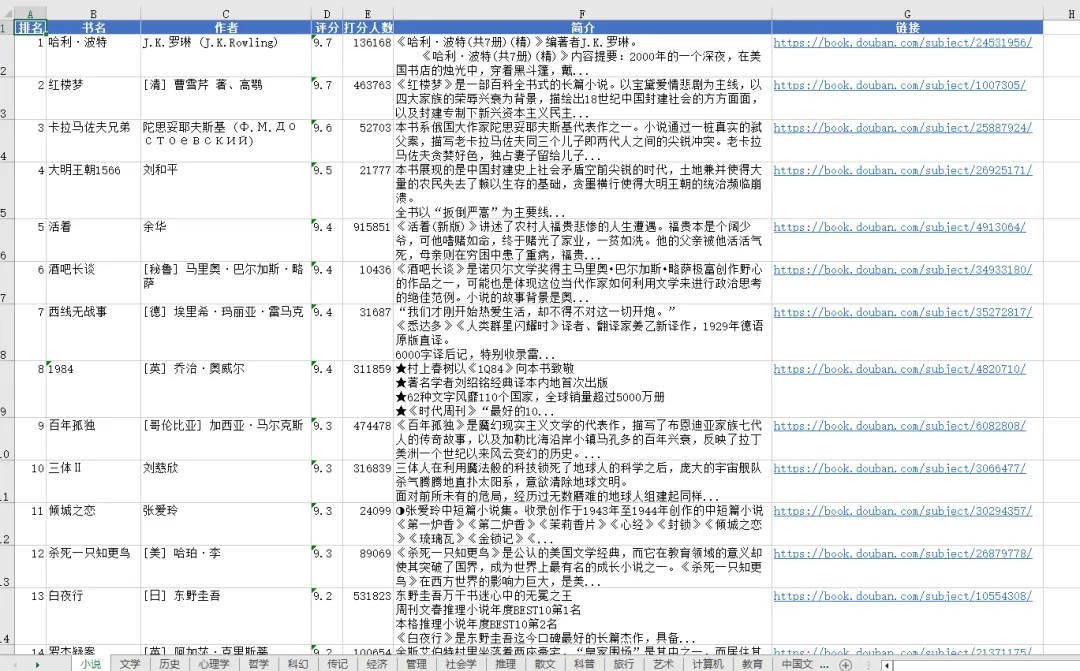
让AI爬了豆瓣这是我一直想做的事情,之前买了python的书,想学爬虫,从第一页开始装系统开始,报错报错,连python程序都运行不起来。现在用workbuddy,花了30分钟,让它把豆瓣top250电影、书籍,还有书籍按照分类和评分人数大于2000的书按照评分排列,整理成excel给我。然后我就可以根据这个快速筛选出我还没有看过的内容。太easy了,以至于进入贤者时间,ai什么都能干,关键是我还有什么想干的?升级了点难度,平时我检索一些生活类知识,会去小红书上检索相关经验,现在我打算给个关键词,让ai去爬小红书上的知识,这就不需要自己一条条看了,毕竟很多重复的、无效的笔记。这就难了,它搞了1小时只收集到了18条笔记的内容。还花了我500积分。我再试试吧。。还有,能不能把这种ai能力开发一个产品,然后放在市场上去货币化。寻找到一个需求,然后用ai程序开发。
基本
文件
流程
错误
SQL
调试
- 请求信息 : 2026-05-29 17:32:30 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/678745.html
- 运行时间 : 0.140682s [ 吞吐率:7.11req/s ] 内存消耗:4,565.45kb 文件加载:145
- 缓存信息 : 0 reads,0 writes
- 会话信息 : SESSION_ID=0b8b512e435a2bfd3eaa9a6a5decd83c
- CONNECT:[ UseTime:0.000782s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4
- SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.001449s ]
- SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000766s ]
- SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.000625s ]
- SHOW FULL COLUMNS FROM `set` [ RunTime:0.001315s ]
- SELECT * FROM `set` [ RunTime:0.000620s ]
- SHOW FULL COLUMNS FROM `article` [ RunTime:0.001448s ]
- SELECT * FROM `article` WHERE `id` = 678745 LIMIT 1 [ RunTime:0.002454s ]
- UPDATE `article` SET `lasttime` = 1780047150 WHERE `id` = 678745 [ RunTime:0.013653s ]
- SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.000380s ]
- SELECT * FROM `article` WHERE `id` < 678745 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.000605s ]
- SELECT * FROM `article` WHERE `id` > 678745 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.000453s ]
- SELECT * FROM `article` WHERE `id` < 678745 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.003570s ]
- SELECT * FROM `article` WHERE `id` < 678745 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.004635s ]
- SELECT * FROM `article` WHERE `id` < 678745 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.003810s ]

0.143358s

 夜雨聆风
夜雨聆风