 夜雨聆风
夜雨聆风Institutional Research · Market Structure
AI 账单重估:别盯 token 价,真正的成本在工作流里
模型越来越便宜,不等于 AI 越来越省钱。企业真正要看的,是一条任务从触发到复核、记录和治理的完整账单。
Core Thesis
AI 成本不该按 token 单价读,而应该按完成一条工作流来读。
如果只看模型标价,AI 的故事会显得很简单:每百万 token 的价格不断下降,模型越来越多,客户似乎会自然受益。
但这只是账单的第一行,不是账单本身。
真正进入企业预算的,通常不是一次孤立调用,而是一条工作流:用户提出任务,系统检索上下文,调用模型,接入工具或搜索,必要时重试,再进入人工审核,最后还要留下日志、监控质量、处理错误和维护权限边界。
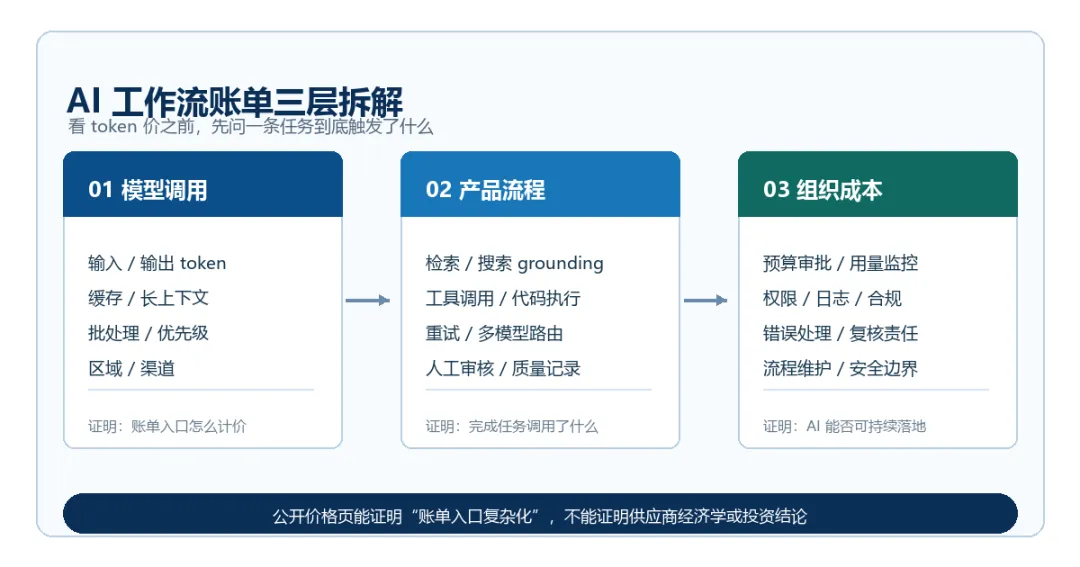
一、价格页说明了什么
公开价格页已经足够提醒我们,AI 账单不是单一维度。
OpenAI 的 API pricing 页面把输入、缓存输入、输出、批处理、工具调用、服务层级和企业容量入口拆开。
Anthropic 的 Claude pricing 页面把 base input、cache writes、cache hits、output tokens 和云平台渠道分开。
Google Cloud 的 Gemini/Agent Platform pricing 页面把模型、长上下文、grounding/search、批量或不同模态收费放在同一个复杂价格体系里。
AWS Bedrock pricing 页面则展示了 on-demand、batch、fine-tuning、custom model storage 和 provisioned throughput 这些不同计费层。
DeepSeek 和智谱的公开价格页把这个趋势推得更直观。DeepSeek 把
deepseek-v4-flash和deepseek-v4-pro拆成 cache hit、cache miss 和 output 三列;智谱则把 GLM-5.1、GLM-5、GLM-4.7 等模型拆成输入长度区间、输入单价、输出单价、缓存存储和缓存命中。
价格页样本:公开计费拆分
DeepSeek V4 Flash
cache hit $0.0028、cache miss $0.14、output $0.28,均为每百万 tokens。
读法:同一模型的账单已经分成命中缓存、未命中缓存和输出。
DeepSeek V4 Pro
当前折扣口径:cache hit $0.003625、cache miss $0.435、output $0.87,均为每百万 tokens。
读法:价格还可能受促销、折扣和期限影响。
智谱 GLM-5.1
输入长度 [0,32K):输入 6 元、输出 24 元、缓存命中 1.3 元;[32K+):输入 8 元、输出 28 元、缓存命中 2 元,均为每百万 tokens。
读法:长上下文不是一个单价,输入长度区间会改变账单。
智谱 GLM-4.7-FlashX
输入 0.5 元、输出 3 元、缓存命中 0.1 元,均为每百万 tokens。
读法:低价模型同样保留输入、输出、缓存命中的分层。
这些来源可以支持一个很窄但很重要的结论:客户侧 AI 账单结构正在复杂化。
它们不能支持另一些更刺激的结论:公开价格不能告诉我们供应商的真实服务成本,不能推出毛利率,不能证明哪家公司有护城河,也不能说明“小模型一定赢”或“开源一定赢”。价格页是客户侧可见的收费架构,不是供应商经济性的完整披露。
二、Source Lanes 具体化
这里的关键不是多列几个来源,而是把来源放回自己的车道。
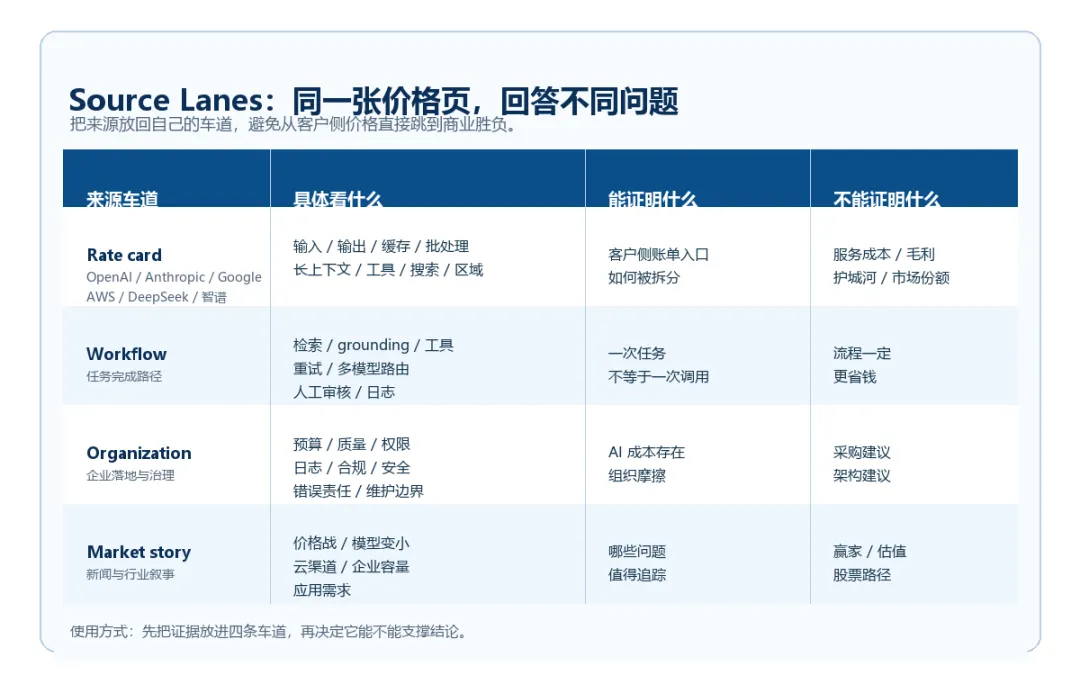
Rate card
看输入、输出、缓存、批处理、长上下文、工具/搜索、区域、服务层级、输入长度区间、促销/折扣口径。它能证明客户侧账单入口如何拆分,不能证明供应商毛利、真实服务成本、护城河或市场份额。
Workflow
看检索、grounding、工具调用、重试、多模型路由、人工审核和日志记录。它能证明一次任务不等于一次模型调用,不能证明流程一定更便宜,或某个架构一定更优。
Organization cost
看预算审批、权限、监控、质量、合规、安全边界和错误责任。它能证明 AI 落地有组织摩擦和治理成本,不能构成采购建议、成本优化方案、合规或安全结论。
Market story
看价格战、云渠道、容量包、模型大小、开源叙事和企业 adoption。它能提示哪些问题值得继续追踪,不能推出赢家输家、估值、股票路径或投资判断。
换句话说,rate card 能告诉你账单入口在哪里;workflow 能告诉你完成任务可能调用了哪些东西;organization cost 能告诉你为什么价格页没有覆盖全部落地成本;market story 只能告诉你哪些叙事值得追踪,不能替你下商业结论。
三、把 AI 成本拆成三层
第一层是模型调用。这里看输入、输出、缓存、上下文长度、延迟等级、批处理折扣。这一层能回答“单次调用表面上怎么计价”。
第二层是产品流程。一次任务可能需要几次调用,是否需要检索、搜索、代码执行、图像、语音或外部工具,失败后是否重跑,是否有人审查。这一层能回答“完成一件事到底调用了什么”。
第三层是组织成本。谁来批准预算,谁来监控质量,谁来处理错误,谁来维护提示词、权限、日志、合规和安全边界?这一层往往不会出现在模型价格表里,却会决定 AI 在企业里是不是可持续。
三层成本表
模型调用:输入/输出/缓存/批处理/服务层级能回答每次请求按什么计价,但仍缺实际折扣、利用率和服务成本。
产品流程:工具、搜索、容量、渠道和产品说明能提示完成任务用了几步,但仍缺真实调用次数、失败率和人工审核比例。
组织成本:治理框架、产品文档和预算口径能提示谁负责治理和错误,但仍缺内部流程摩擦、责任链和长期维护成本。
所以,如果要讲 AI 成本,最好不要从“某模型每百万 token 多少钱”直接跳到“谁将赢得 AI 商业化”。中间缺了太多桥:使用量、折扣、客户结构、硬件利用率、人工审核、工作流价值、错误成本和替代成本。
四、真正值得追踪的不是价格战
更好的不是“AI 价格战来了”,而是“AI 账单该按完成的工作流来读”。
因为 AI 真正卖给人的,最后不是 token,而是某个任务被完成、被检查、被记录、被纳入组织流程。token 价下降当然重要,但如果一条任务需要更多检索、更多工具、更多重试、更多审查和更多治理,最终账单未必会按同样比例下降。
对企业来说,关键问题也不是“哪个模型最便宜”,而是:
• 这个 AI 功能被放进哪条流程?
• 一次任务要触发多少次模型、工具或搜索?
• 输出错误以后谁负责检查和修正?
• 日志、权限、合规、安全边界谁维护?
• 成本看的是单次调用,还是完成一次可交付工作?
这些问题没有 rate card 那么好看,但更接近真实预算。
五、这篇文章不证明什么
这篇文章不证明任何供应商毛利、护城河、市场份额或股票路径。
它不证明某个模型、云平台、开源路线或小模型路线会赢。
它也不构成采购、投资、架构、成本优化或产品选择建议。
它只给出一个 source-literacy 结论:公开价格页能告诉你账单入口在哪里,但不能告诉你 AI 生意的全部经济学。真正的 AI 成本,要沿着工作流读完。
Source note
本文使用的公开来源:
OpenAI API Pricing:输入、缓存输入、输出、工具、批处理、服务层级。
Anthropic Claude Pricing:base input、cache writes、cache hits、output tokens、云平台渠道。
Google Cloud Gemini / Agent Platform Pricing:长上下文、grounding/search、不同模态与平台计费。
AWS Bedrock Pricing:on-demand、batch、fine-tuning、custom model storage、provisioned throughput。
DeepSeek Models & Pricing:v4-flash/v4-pro 的 cache hit、cache miss、output 分层,以及折扣期限。
智谱开放平台 Pricing:GLM-5.1/GLM-5/GLM-4.7 的输入长度区间、输入/输出、缓存命中、缓存存储。
边界提醒:这些来源能说明客户侧账单入口如何拆分,不能直接推出供应商毛利、真实服务成本、长期价格、赢家输家、估值或投资结论
