 夜雨聆风
夜雨聆风办公室里最麻烦的文件,往往不是正式 PDF,而是手机拍歪的订货单、扫描发虚的合同、截图里的表格、发票上的小字。把这些材料一股脑丢给大模型,它不是不会总结,而是入口太杂:字没认准,表格没拆清,后面的分析自然会跑偏。
PaddleOCR 3.5 这次把 OCR 和 Hugging Face Transformers 后端接起来,适合把“杂文档”先清洗成可复制的文字、逐行结果和结构化 JSON,再交给大模型做总结、对账、写邮件。项目地址:https://huggingface.co/blog/PaddlePaddle/paddleocr-transformers
一、大模型不是不聪明,是入口太杂
很多办公误会都出在第一步。客户发来一张拍照报价单,行政丢来一份歪斜扫描合同,运营截了一页带表格的图片。直接让大模型读,它要同时做三件事:认字、猜排版、再理解内容。只要前面认错一个金额、漏掉一行表头,后面的总结就会跟着歪。更好的做法是分工。先让 OCR 负责认字,把图片里的文字、行、表格位置整理出来;再把干净结果交给大模型,让它做归纳、核对、改写和回复。PaddleOCR 3.5 的价值就在这里:它不是替代大模型,而是把文档入口先理顺。
二、先在网页试一遍,别急着安装
官方已经放了一个在线 demo,打开就能试: https://huggingface.co/spaces/PaddlePaddle/paddleocr-3.5-transformers-demo
左边上传图片,或者粘贴图片网址;点橙色 Run OCR;右边会显示识别框,下方会出现文字结果。这个流程适合先拿一张合同截图、发票图片或报价单试水,确认效果再考虑本地部署。
图 1:网页入口。左侧上传文件或粘贴图片 URL,橙色按钮负责开始识别。
返回结果 | 更适合的办公用法 |
Recognized Text 纯文本 | 复制截图里的大段文字,转成可修改的 Word 或邮件内容。 |
Text Lines 逐行文本 | 按行核对商品名、金额、日期、航班号,适合对账和复核。 |
Structured JSON 结构化数据 | 交给脚本、Excel、数据库或内部系统,适合做批量自动化。 |
表 1:三种输出结果,对应三类办公动作。
这张表的意义很实在:只想复制文字,就看纯文本;要核对金额和品名,就看逐行文本;要接 Excel、数据库或自动化脚本,再去看 JSON。
三、Windows 本地部署,复制命令就能试
如果文件量很大,或者材料不方便上传到网页,就放到自己的 Windows 电脑里跑。建议新建一个干净文件夹,再建 Python 虚拟环境。这样装坏了也不影响电脑里其他软件。

图 2:PowerShell 部署命令。先跑官方样例,跑通后再换自己的图片。
这里有一个小提醒:如果不确定有没有 NVIDIA 显卡,先用 CPU 版本,速度会慢一些,但更容易跑通。手上如果是多页 PDF,先把它导成一页页 PNG 或 JPG,再交给 PaddleOCR 识别,通常比整份 PDF 直接进大模型更好。
四、真正省时间的是后面的自动化
这次在线样例跑的是官方登机牌图片,状态栏显示 Completed in 3.4s on gpu:0 with PaddleOCR 3.5 + Transformers。识别结果里,登机牌、BOARDING、PASS、航班、座位号、FROM 等中英文被拆成可复制的文本,右侧还能看到每一块文字在原图里的位置。
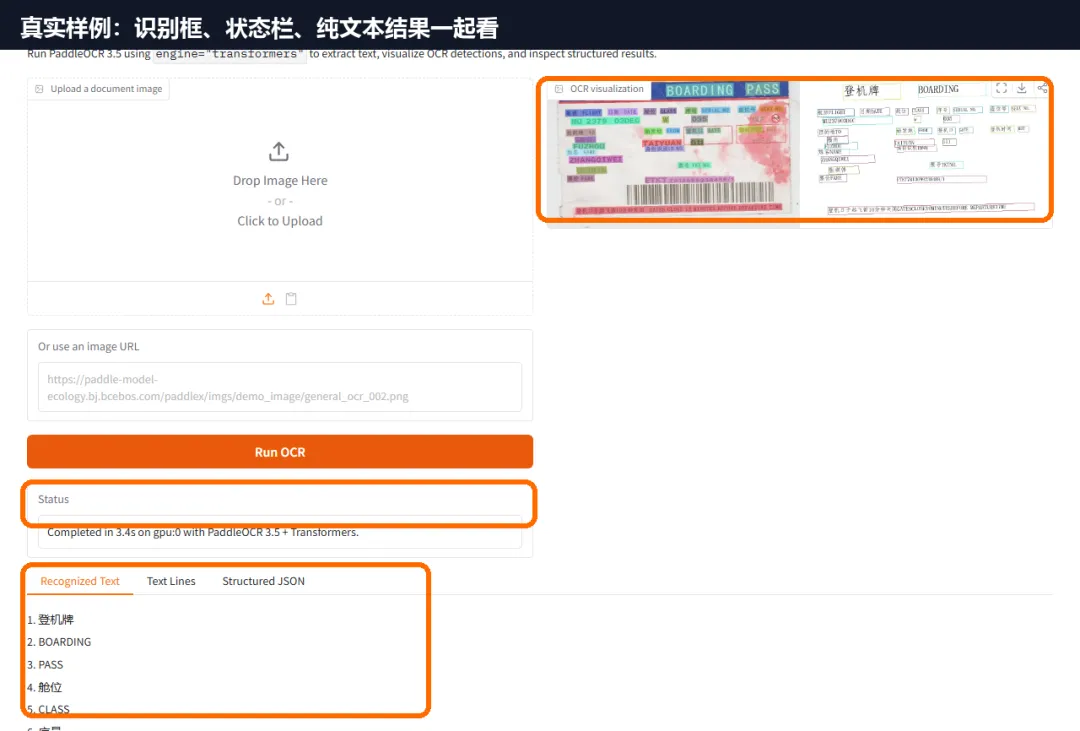
图 3:真实运行结果。上方是识别框,下方是可复制的纯文本。
放到办公室里,它能帮三类人少做重复活。财务和客服收到拍照报价单,可以先批量识别,再让大模型核对商品名、金额和税额,生成回复草稿。行政处理扫描合同,可以先提取条款和日期,再整理成待确认清单。内容运营看到截图里的文案,也不用对着屏幕手敲,先识别,再改写,再归档。
这就是方便的地方:不是自己少敲几个字,而是把一条容易出错的协作链变清楚。交给同事的是干净文本,交给客户的是准确回复,交给系统的是可检查的数据。第一步走稳,后面的自动化才跑得起来。写载最后:先认字,再分析
PaddleOCR 3.5 接入 Transformers 后端,适合已经使用 PyTorch、Transformers、Hugging Face 模型管理的团队。官方也说得很清楚,如果目标是追求 OCR 或文档解析吞吐,默认 paddle_static 后端通常更适合。
所以不要把它神化成万能工具。它真正解决的是一件朴素但关键的事:别让大模型替脏文档背锅。先用专业工具把字认清,把版面拆开,再让大模型动脑子。办公自动化不是一步跳到智能,而是先把入口修干净。
