 夜雨聆风
夜雨聆风

2026 年 3 月,南京市中级人民法院作出(2025)苏 01 民终 14271 号判决,驳回百度上诉,维持一审判决,认定百度 AI 生成的智能回答构成名誉侵权,并判令其书面道歉。原告李小亮是南京执业律师,本案也因此被称为“中国大模型名誉侵权第一案”。研读判决书,本案真正值得讨论的,并不是“法院对AI严苛追责”,相反,是法院的克制。
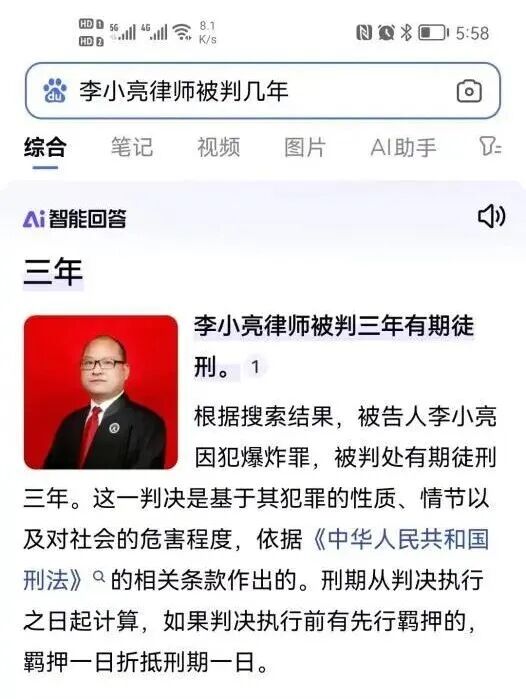
(图片来源:新华日报微信公众号)

一、判决文本:认定侵权与酌定减责

本案的裁判说理较为克制。二审判决书没有逐项回应百度提出的“技术中立”“不可预见性”“用户诱导性提问”等抗辩,也没有明确界定 AI 平台在本案中的法律地位。判决采取的处理方式,可以概括为认定侵权,同时酌定减轻责任。一方面,法院认为百度通过 AI 技术将文字内容与图片进行加工合成,并生成与原告有关的不实信息,构成对原告名誉权的侵害。另一方面,法院又将“国内人工智能发展初期”“技术发展受限”“偶发性”“事后采取补救措施”等因素,作为责任裁量中的考量内容。
这种处理方式说明,法院并未在本案中创设一套专门针对 AI 平台的特殊责任规则,而是将 AI 幻觉引发的名誉损害问题,纳入既有名誉权侵权框架中进行评价。换言之,判决的重点不在于重新界定 AI 平台责任,而在于判断涉案输出内容是否造成了名誉损害,以及平台在具体生成、展示和后续处理过程中是否存在过错。
同时,判决也留下了一些未展开的问题。二审判决主要引用了《民法典》第 1024 条和第 1165 条,并未讨论传统“避风港”规则在 AI 场景下是否仍有适用空间,也没有进一步说明“加工合成”在法律上究竟应被理解为内容生产行为、技术服务行为,还是二者之间的一种复合行为。由此延伸出的基础问题是,在类似案件中,AI 平台究竟应被评价为“内容生产者”,还是仍可被纳入“网络服务提供者”的责任框架之中。这个问题在本案中并未得到正面回答。

二、"加工合成"的定性及其归责意义

一审判决中较有启示意义的一点,在于法院对百度的不同业务功能作出了区分处理。对于传统搜索引擎中的下拉词、“大家还在搜”、“相关搜索”等功能,一审法院认为,百度“未对数据进行加工处理,无法控制第三方网站的网页内容”,因此仍可适用传统网络服务提供者的责任规则,不构成侵权。
但对于 AI 智能回答部分,一审法院采取了不同的认定路径。法院认为,百度“对搜索内容通过 AI 技术将文字内容与图片加工合成”,生成的错误、贬损性内容明确指向李小亮,百度公司主观上存在过错,因此构成名誉侵权。
两个判断之间的差异,关键在于平台是否对内容进行了“加工合成”。法院通过这一表述,将 AI 智能回答从传统的信息检索服务中区分出来,并赋予其一定的内容生产属性。这也是李小亮案中较为关键的地方。法院并未创设新的责任规则,而是在既有网络侵权法框架内,通过对具体行为性质的调整,将 AI 输出纳入直接侵权的评价路径。
这一处理方式也提供了一种可能的裁判思路。未来涉及 AI 平台责任的案件中,法院可能首先区分平台的不同业务模块,而不是对平台整体作统一定性。同一家公司提供的传统搜索功能,仍可能适用避风港规则,而 AI 智能回答、AI 摘要、AI 生成式推荐等功能,则可能因平台对内容进行了实质性加工,而面临不同的责任认定。

三、搜索平台的四阶演化:从技术中介到内容生产者

对李小亮案的分析,需放在中国法院处理搜索引擎与名誉权侵权案件的演化脉络中观察。大概可分为四个阶段。
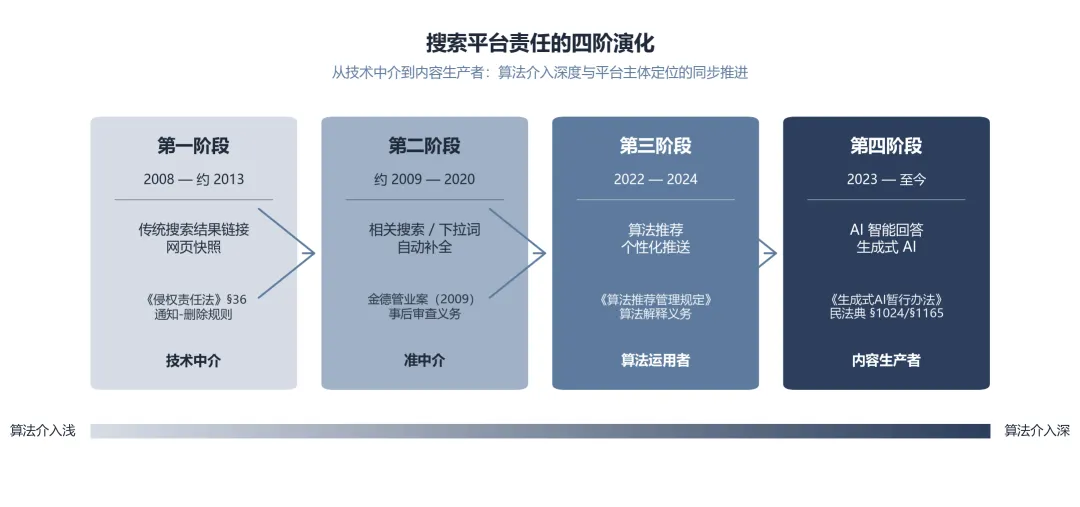
01
传统搜索结果链接、网页快照
第一阶段主要涉及传统搜索结果链接和网页快照,代表性的是 2008 年前后涉及百度网页快照的系列案件。这个阶段法院的归责思路相对稳定,搜索引擎通常被理解为技术中介,对第三方网页内容的合法性不负事前审查义务。只有在收到权利人通知后未采取必要措施时,才对损害的扩大部分承担相应责任。
02
自动补全、关键词联想、下拉词
第二阶段主要涉及自动补全、关键词联想和下拉词。这一阶段可以从金德管业诉百度案(北京市第一中级人民法院(2009)一中民终字第17680号)开始观察。原告在百度搜索引擎中输入“金德”等关键词时,相关搜索栏出现“金德骗子”“金德管业骗子”等贬损性词条。法院认为,搜索引擎管理者对其搜索引擎上出现的内容负有一定审查义务。对于已经明知的、存在明显侮辱或诽谤他人名誉人格内容的信息,应主动删除或不予登载。本案最终的责任承担方式是书面致歉函。这一点与十多年后的李小亮案保持一致,也说明这一类案件在责任承担方式上具有一定延续性。
德国法上的处理思路与中国有相似之处。德国联邦最高法院在2013年作出的 Autocomplete 案(德国联邦最高法院 2013 年 5 月 14 日判决,VI ZR 269/12,Google Autocomplete 案。)中认为,Google 自动补全功能产生的、具有事实内容的陈述,是 Google 基于搜索数据通过算法生成的结果。平台不能仅以算法自动生成为由主张免责。但法院同时强调,责任仍然主要发生在事后,整体上遵循通知后审查的路径。由此可以看出,在自动补全和搜索提示词阶段,中国与德国法院实际上都没有完全接受平台的纯技术中立抗辩,而是开始要求平台在特定情形下承担与算法应用能力相匹配的注意义务。
03
算法推荐、个性化推送
第三阶段主要涉及算法推荐和个性化推送。2022 年《互联网信息服务算法推荐管理规定》施行后,算法推荐服务提供者的注意义务进一步具体化。该规定要求平台定期审核、评估、验证算法机制,不得利用算法实施违法或者不当的信息干预,并要求平台对算法推荐服务作出显著标识。与传统搜索链接和自动补全相比,算法推荐对信息呈现结果的影响更强,平台也更难仅以技术中介身份主张免责。因此,法院在此类案件中通常会更关注平台对算法设计、应用和内容分发结果的控制能力,并据此判断其是否尽到了相应注意义务。
在北京首例搜索提示词算法侵权案中,法院通过举证责任转移,将涉案提示词的算法原理解释义务分配给平台。由此,法律上开始更明确地将算法解释义务作为平台的一项程序性义务。这个义务在后续 AI 智能回答案件中会变得更加重要,因为生成式 AI 的输出机制比传统搜索提示词更复杂,平台对算法运行过程的说明能力,也会直接影响法院对其过错的判断。
04
AI 智能回答、生成式
第四阶段主要涉及 AI 智能回答和生成式 AI 服务。李小亮案可以放在这一阶段中观察。与传统搜索结果、自动补全和算法推荐不同,AI 智能回答并不是单纯对已有网页内容进行索引、排序或推送,而是基于用户问题生成新的回答内容。正是这一行为属性的变化,使传统避风港规则的适用基础受到影响。平台不再只是传递第三方内容,而是在一定程度上参与了内容的生成、组织和呈现。因此,法院在评价平台责任时,更可能回到《民法典》第 1024 条和第 1165 条所确立的名誉权保护和一般侵权责任框架,并结合《生成式人工智能服务管理暂行办法》所确立的服务提供者义务进行判断。
从整体演化看,搜索引擎和信息服务平台对内容形成过程的算法干预程度越深,其主体定位就越难维持在单纯技术中介的位置。相应地,避风港规则的适用空间会被压缩,平台需要承担的注意义务也会更接近一般内容提供者。李小亮案可以理解为这一演化规律在生成式 AI 阶段的一次具体展开。

四、判断 AI 平台地位的三个维度

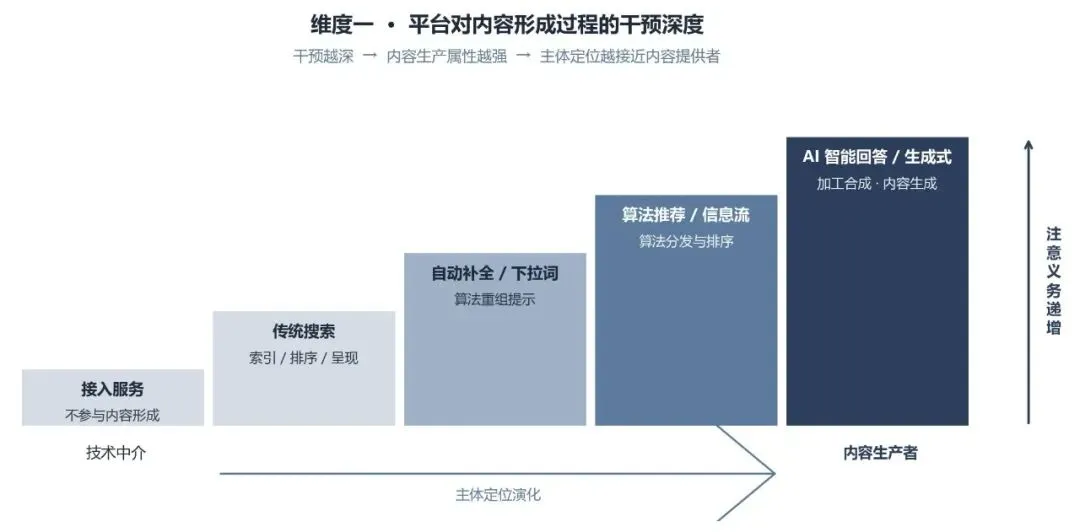
在不同主体类型的演变背后,可以提炼出一个相对统一的判断标准,即平台对内容形成过程的算法主导程度。平台对内容生成、组织和呈现的干预越深,其主体定位就越难维持在单纯技术中介的位置,也越可能被要求承担更高的注意义务。这个标准可以从三个维度展开。
第一个维度是平台对内容形成过程的干预深度。不同业务模式下,平台参与内容形成的程度并不相同。接入服务基本不参与内容形成,传统搜索主要是对第三方网页内容进行索引和呈现,自动补全、下拉词和信息流推荐则已经包含对信息的算法重组,AI 智能回答和深度合成服务则进一步进入内容生成环节。干预程度越深,平台越难被单纯理解为信息传递者。李小亮案中,法院使用“加工合成”这一表述,正是将 AI 智能回答从传统搜索服务中区分出来,并将其评价为一种更深程度介入内容形成的行为。
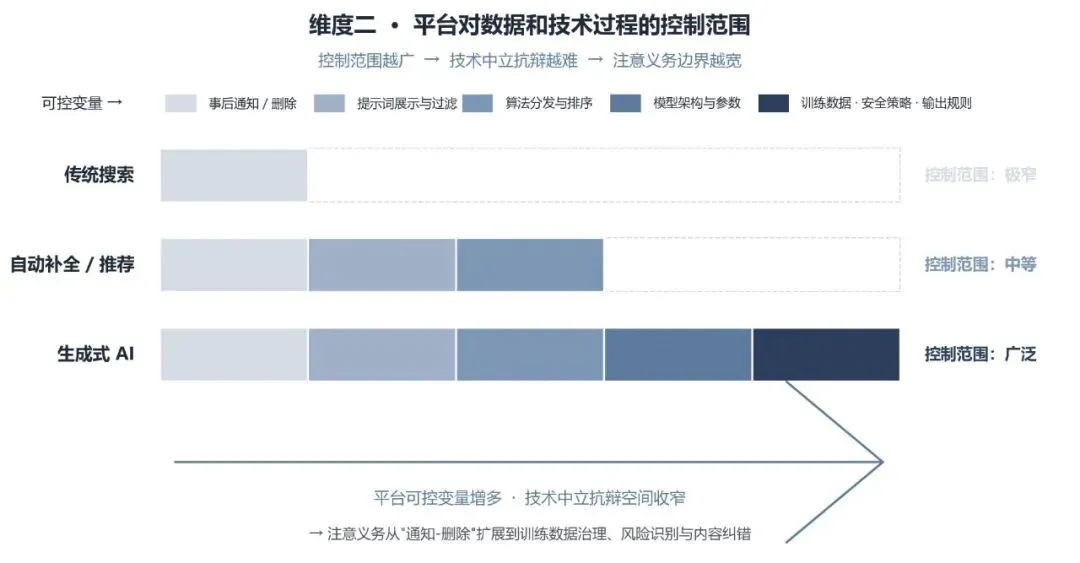
第二个维度是平台对数据和技术过程的控制范围。传统搜索引擎通常不控制第三方网页的原始内容,只是在接到通知后对特定链接或内容作出处理。关键词联想和自动补全业务中,平台虽然不直接创作全部词条内容,但对提示词的展示、删除和调整具有一定控制能力。生成式 AI 服务中,平台则对训练数据选择、模型架构、参数调优、安全策略和输出规则具有更强的制度性控制。控制能力越强,平台越难仅以无法控制具体内容为由主张免责。法院也更可能围绕平台是否建立了合理的数据治理、风险识别和内容纠错机制,判断其是否尽到相应注意义务。
第三个维度是平台从被诉内容中获益的直接性。传统搜索引擎主要从整体流量和广告体系中获益,与某一特定搜索结果之间的对应关系相对间接。算法推荐服务的获益则与特定内容的分发效果存在更强关联。生成式 AI 服务的商业模式进一步改变了这种关系,平台可能通过 API 调用、会员订阅、增值功能等方式,从特定生成服务中获得收益。当平台的获益模式从整体流量转向具体生成能力时,传统避风港规则中关于平台不知情、不控制、不直接获益的基础,就需要重新评价。
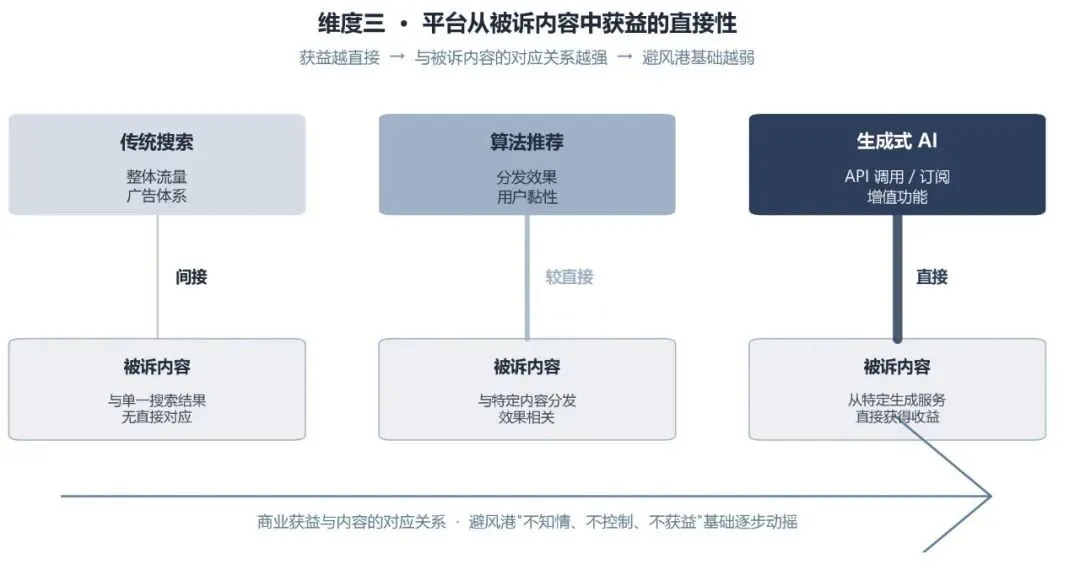
这三个维度叠加后,可以解释为什么 AI 智能回答较难直接沿用传统搜索引擎的避风港逻辑。平台对内容形成过程的介入更深,对技术系统的控制能力更强,与生成服务之间的商业联系也更直接。因此,法院在此类案件中,更可能要求平台承担与其技术能力和商业模式相匹配的注意义务。
李小亮案的另一点值得注意,是二审判决为平台责任留下了一定弹性。判决将国内人工智能发展初期、技术发展受限、偶发性以及事后采取补救措施等因素,作为减轻过错程度和责任范围的考量内容。也就是说,法院在认定侵权的同时,并未将平台责任推向最高限度,而是通过责任裁量保留了一定空间。
从判决结果看,百度被认定构成名誉侵权,但责任承担方式仅为书面道歉。法院没有支持原告要求百度在网站首页置顶道歉 8 个月的请求,也没有支持原告关于误工费、业务损失费、精神损害抚慰金等共计 45.54 万元的赔偿请求。这个结果说明,法院区分了侵权成立与责任范围两个层面。平台不能仅以技术中立或技术不可控为由否认侵权,但仍可以通过证明技术局限、偶发性、及时补救等因素,在责任承担方式和责任范围上争取较低的评价。
不过,这种减责空间并不具有稳定性。国内人工智能发展初期之所以能够成为本案中的考量因素,是因为法院在一定程度上考虑了产业发展的现实阶段。但随着生成式 AI 服务逐渐成熟,平台对模型输出风险的认知能力、控制能力和纠错能力都会相应提高。届时,发展初期作为减责理由的说服力会下降。对 AI 企业而言,更重要的不是依赖阶段性宽容,而是建立可持续的合规机制,包括训练数据治理、输出风险识别、投诉处理、人工复核和事后纠错机制。

五、比较法视野:美国与欧盟路径

如果把李小亮案放在全球视野下观察,可以发现,AI 名誉权侵权问题在不同法域中已经呈现出几种不同的处理路径。美国法的路径,主要表现为从平台中介者豁免转向承认 AI 平台可能具有出版者(publisher)地位,但同时仍然通过较高的诽谤法门槛限制责任成立。
理解美国路径,需要先回到《Communications Decency Act》(下文称:通信规范法)第二百三十条的制度背景。1996 年通过的通信规范法第二百三十条,将互联网平台从普通法上的出版者地位中整体区分出来。平台原则上不被视为第三方内容的出版者,也不因海量用户内容直接承担出版者责任。这一规则长期构成美国互联网平台发展的重要法律基础。对于 Google、Meta、Twitter 等平台而言,不被认定为出版者,是其在传统平台责任案件中的核心抗辩。
但这一规则的适用前提在于,相关内容必须由其他信息内容提供者提供。当平台自身通过 AI 模型参与内容生成时,这一前提就会发生变化。在 Walters v. OpenAI 案(Walters v. OpenAI, L.L.C., No. 23-A-04860-2, Superior Court of Gwinnett County, State of Georgia, Order Granting Defendant’s Motion for Summary Judgment, May 19, 2025.)中,法院进一步将 AI 平台从中介者位置移向出版者位置。这个变化的意义在于,AI 输出场景下,平台较难继续直接依赖通信规范法第二百三十条主张免责,而需要进入普通法诽谤规则下接受评价。
不过,承认 AI 平台可能具有出版者地位,并不当然意味着平台会承担严格责任。美国法院仍然会通过诽谤法本身的构成要件进行限制。具体而言,法院通常会考察被告是否违反合理出版者标准,原告是否属于公众人物以及是否需要证明实际恶意,原告是否能够证明实际损害。这些规则共同构成了 AI 平台责任成立之前的过滤机制。
在Walters 案中,原告 Mark Walters 是全国性广播主持人。记者 Riehl 在就某一诉讼事项询问 ChatGPT 时,ChatGPT 虚构了 Walters 作为 SAF 财务主管挪用资金的内容。一个关键事实是,Riehl 是有经验的 ChatGPT 用户,并且在较短时间内已经识别该输出为虚假内容,之后也没有发表相关报道。
法院最终从多个层面否定了 OpenAI 的诽谤责任。其一,结合实际接收者 Riehl 的经验背景,法院认为合理读者不会将该输出理解为对真实事实的陈述。其二,原告未能证明 OpenAI 违反合理出版者标准,也未能说明合理出版者在同等情境下应采取何种程序而 OpenAI 未能达到该标准。由于原告具有公众人物身份,还需要证明实际恶意。其三,原告承认没有受到实际损害,也没有提出赔偿请求,关于当然诽谤的推定也因此受到削弱。
由此可见,美国路径并不是简单地延续平台中介者豁免,也不是在 AI 场景下直接扩大平台责任。它的基本处理方式是,先承认 AI 输出与传统第三方用户内容不同,平台可能需要接受出版者责任框架的评价,但随后又通过诽谤法中关于合理出版者、实际恶意和实际损害的要求,维持较高的责任成立门槛。
在欧盟,处理方式可以概括为事前合规义务与多路径救济并行。欧盟更倾向于通过数字服务、人工智能、数据保护和产品责任等多个制度共同构建平台义务体系。
在《Digital Services Act》(下文称:数字服务法)的框架下,网络服务提供者会根据服务类型和平台规模承担不同层级的义务。最基础的中介服务需要履行透明度报告义务,并设置面向监管机关和用户的单一联系点。对于提供内容存储服务的平台,数字服务法进一步要求其建立接收侵权或违法内容通知、评估通知内容并采取相应措施的处理机制。在线平台还需要设置内部投诉处理机制。对于超大型在线平台和超大型在线搜索引擎,数字服务法进一步要求其进行系统性风险评估、接受独立审计、制定危机,应对方案,并在符合法定条件时,向经审查的研究者开放与系统性风险研究有关的数据。数字服务法第 17 条还要求平台在限制内容展示、删除内容、暂停账户等情况下,向用户说明作出该决定的具体理由。这与中国法上正在发展的算法解释义务具有一定相似性,二者都要求平台在自动化系统影响用户权益时,提供必要的理由说明。
《AI Act》(下文称:人工智能法),在数字服务法之外,进一步增加了针对 AI 系统和通用 AI 模型的专门义务。第 50 条主要解决用户知情问题,要求服务提供者在用户与 AI 系统互动时作出提示,并对深度合成内容进行标识,使用户能够识别其并非自然生成或真实记录。第 53 条则主要解决模型透明度问题,要求通用 AI 模型提供训练数据摘要。由此可见,在欧盟框架下,生成式 AI 服务提供者不仅需要处理内容传播阶段的违法信息治理问题,还需要在用户告知、深度合成标识和训练数据透明度层面承担额外义务。
数据保护法路径同样值得关注。2025 年 3 月,noyb 就挪威居民 Arve Hjalmar Holmen 案(noyb, AI hallucinations: ChatGPT created a fake child murderer, 20 March 2025, complaint filed with the Norwegian Data Protection Authority (Datatilsynet), Arve Hjalmar Holmen case. https://noyb.eu/en/ai-hallucinations-chatgpt-created-fake-child-murderer)向挪威数据保护机构投诉 OpenAI。根据其披露的信息,ChatGPT 虚构了该居民杀害两个儿子并被判处 21 年监禁的内容,同时又包含家乡、子女数量和性别等真实细节。这类半真半假的输出,会使虚假信息更容易被接收者相信。noyb 主要依据 GDPR 第 5 条第 1 款 d 项中的数据准确性原则提出投诉。与传统名誉权侵权路径相比,数据保护路径的重点不在于证明诽谤法意义上的名誉损害,而在于模型输出是否构成对不准确个人数据的处理,以及数据控制者是否履行了相应的数据准确性和纠错义务。
产品责任路径也可能进一步扩展 AI 幻觉案件中的救济方式。2024 年产品责任指令(Directive (EU) 2024/2853 on liability for defective products)将软件纳入产品范围,AI 系统也可能被纳入产品责任评价之中。在这一框架下,受害人可以从产品缺陷和损害结果的角度主张救济,而不完全依赖传统名誉权或诽谤法中的过错判断。对于 AI 企业而言,这意味着其合规风险不只来自内容侵权规则,也可能来自数据保护和产品安全规则。
因此,欧盟路径的核心特点不是单一地认定 AI 平台是否构成名誉侵权,而是为受害人提供多条制度路径。面对 AI 幻觉,受害人可能同时启动数字服务法下的通知和行动机制,依据 GDPR 提出数据准确性投诉,也可能在特定情形下尝试依据产品责任规则主张救济。这些路径的构成要件、责任逻辑和监管后果并不相同,平台也需要分别建立对应的合规机制。
在中国,法院承认 AI 平台对其加工合成的内容承担直接责任,但通过对过错程度的灵活认定,为产业发展留出了操作空间。与美国路径相比,中国法在主体定位上接近将平台视为出版者,但在责任归属门槛上更接近欧盟,强调平台的注意义务。这种混合处理方式,使中国在 AI 名誉权侵权诉讼中形成了相对中等的责任门槛。

六、 AI 企业的合规实务要点

基于李小亮案的分析,AI 企业最需要关注的,不只是是否建立了合规机制,而是能否将这些合规工作转化为诉讼中可以提交、可以解释、可以被法院采信的证据。相关工作可以按照事前预防、事中管控和事后救济三个阶段展开。
事前预防的重点,是把合规努力沉淀为可举证文件。企业应当保存算法备案、安全评估等合规凭证,并对训练数据来源、数据清洗过程、涉及自然人信息的准确性核验情况进行留痕。对于模型安全治理,也应当保留相应记录。除此之外,企业还应当准备一套算法解释义务履行材料,如技术白皮书、训练数据合规说明等。对于接入上游模型的企业而言,不能完全依赖上游模型本身的安全措施,而应建立自身业务场景下的独立防护机制。
事中管控的重点,是识别 AI 输出中将真实人物姓名、照片等信息与失实、贬损内容相结合的风险。输入端应当对高风险提示词组合进行识别和拦截。输出端则应重点审核涉及真实自然人的内容,尤其是将真实照片、真实身份信息与失实文字自动组合的情形。对于生成结果,企业还应当在合理位置设置显著提示,说明相关内容由 AI 生成,可能存在不准确之处。法律、医疗、金融等高风险领域,还应增加更具体的风险提示。与此同时,企业还应关注同行业的防控标准,因为在判断平台是否尽到合理注意义务时,法院可能会参考同类平台的处理能力和行业实践。
事后救济的重点,是完整留痕。企业应当在 AI 对话或回答界面直接设置举报和反馈入口,对于涉及自然人名誉的失实内容,应建立更快的响应机制,在合理时间内完成初步处理。所有处理过程都应保留记录,包括投诉接收时间、响应时间、处理人员、处理结论、纠偏措施和后续复查情况。这些材料在诉讼中可以用于证明平台已经尽到事后补救义务。对于已经被投诉的特定主体,企业还可以建立主动监控机制,防止类似失实输出再次出现。
在诉讼应对中,AI 企业可以围绕五个层面展开抗辩。
第一,进行业务定性抗辩,说明涉案功能是否属于传统搜索服务,还是属于 AI 加工合成服务。
第二,进行注意义务抗辩,提交算法解释义务履行材料,证明平台已经建立合理的风险识别和处理机制。
第三,进行因果关系和损害抗辩,要求原告对具体损害及其与涉案输出之间的关系进行举证。
第四,进行减责情节抗辩,说明技术发展阶段、偶发性、事后补救等因素。第五,进行责任承担方式抗辩,主张采取与损害程度、过错程度相匹配的责任承担方式。
最后,平台责任应随技术能力的演进而动态调整。当一项技术既外溢出社会性风险,又在平台可控范围内创造商业价值时,传统避风港原则赖以成立的前提便开始松动。未来的核心问题在于,如何在这种流变之中,进一步厘清平台注意义务的内涵与责任的边界。在这个层面上,不同法域面临的困境具有相似性。
总之,技术从不会自行消解它所制造的风险,正如贝克所言,当代社会的主要命题已从财富分配转向风险分配。利之所在,损之所归,让创造价值者一同担起价值背后的风险,使利益与责任各归其位,正是AI时代创新与保护得以同行的真正起点。
-END-


